一文纵览 Vision-and-Language 领域最新研究与进展

AI 科技评论按:本文作者为阿德莱德大学助理教授吴琦,去年,他在为 AI 科技评论投递的独家稿件中回顾了他从跨领域图像识别到 vision-to-language 相关的研究思路,今年,他又一次介绍了 vision-and-language 任务的最新进展。正文如下。
前言:
去年写过一篇《万字漫谈 vision-language-action》,主要介绍总结了我们组围绕 vision-language 的一些思路和工作。这次去 VALSE 参会,很多同学和老师都提起那篇文章,说受到很多启发。同时这次刚好有幸在 VALSE 上做关于 vision-and-language 2.0 的年度进展报告,于是就有了把报告变成文字的想法,供各位阅读参考。这篇文章主要介绍了一些 2018 年的这个领域比较受关注的文章,之所以叫 vision-and-language 2.0, 是因为这些文章都是在围绕一些新的 vision-and-language 的任务展开的。
正文:
首先先做一些背景介绍,什么是 vision-and-language?我们知道 Computer Vision(计算机视觉)和 Natural Language Processing (自然语言处理)一直是两个独立的研究方向。计算机视觉是一门研究如何使机器 “看”的科学,而自然语言处理是人工智能和语言学领域的分支学科,主要探索的是如何使机器”读”和“写”的科学。他们相通的地方是,都需要用到很多机器学习,模式识别等技术,同时,他们也都受益于近几年的深度神经网络的进步,可以说这两个领域目前的 state-of-art,都是基于神经网络的,而且很多任务,比如 CV 里的物体识别检测,NLP 里的机器翻译,都已经达到了可以实用的程度。于是从 2015 年开始,有一个趋势就是将视觉与语言进行一定程度的结合,从而产生出一些新的应用与挑战。比如 image captioning,visual question answering 等比较经典的 vision-and-language 任务。
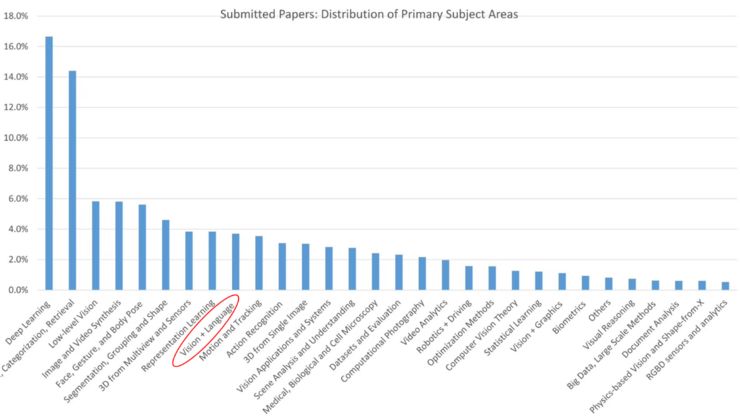
随着这些工作的提出,vision-and-language 也变成了一个越来越热门和主流的研究领域。这张图显示的是 2019 年 CVPR paper submission 的统计,我们可以看到 vision-language 占了所有 submission 的 4%,甚至比比较传统的 tracking,action recognition 都要高。说明越来越多的人在关注并且研究这个方向。
围绕 image captioning 和 VQA,有很多经典的方法被提出,比如从 machine translation 借鉴来的 sequence-to-sequence model,也就是 cnn-rnn 模型,再到引入 attention(注意力机制),以及我们提出的以 attributes 作为中间层去生成更准确的 caption 和答案,再到后来的 MCB,modular network 以及 CVPR 18 年的 bottom-up attention,都是非常经典并且有效的方法。但是我们也发现,尽管方法越来越多,模型越来越复杂,带来的 improvement 却非常有限。比如在 MS COCO image captioning 的 leader board 上,基本上在 bottom-up attention 之后,就没有什么大的提升。再看 VQA,每年都有 VQA-challenge,我们可以看到对比 17 年和 18 年的结果,排在第一的队伍相差也几乎不到两个点。当然抛开这两个数据本身存在的问题不谈(VQA 数据 bias 比较大,captioning 准确的 evaluation 比较难),很多研究者开始意识到 vision-language 不仅仅是只围绕 caption 和 VQA 的,由于任务和数据的限制,可挖掘的空间已经变得越来越小。
从 17 年开始,我们就陆续看到一些新的 vision-language 的任务被提了出来,比如被研究比较多的 referring expression comprehension,也叫做 visual grounding,虽然 14 年就有类似的概念被提出,但基本上从 17 年开始相关的方法才多了起来。在这个任务当中,给出一副图像以及一段 expression,也就是自然语言的描述,我们期望得到一个区域,这个区域能够准确地对应到这个描述。

还有 visual dialog,视觉对话,需要机器能够围绕一张图片展开问答形式的对话。还有像 text to image/video generation,是把 image caption 反过来做,通过语言去生成对应的图像和视频。虽然这些任务看起来都很‘fancy’,但是其实也都是 image captioning 和 VQA 的变体。比如 referring expression,就是 image region – sentence matching。Visual dialog 就是一个 multi-round VQA。从本质上来讲变化并不大,所以我们看到,在 image captioning 和 VQA 上能 work 的方法,在这些任务上也都表现很好。
但是从 18 年开始,vision-language 领域出现一些不一样的任务,使我们在方法上能有进一步的突破。我把这些新的任务称为 vision-and-language 2.0。这些新的任务大致可以分成三个方面。第一个任务主要是围绕 image captioning 方面展开的。过去的 image captioning 基本是直来直去的,给一副图像,生成一个 caption,至于生成的这个 caption 是关注图像当中哪个物体,是什么风格的 caption,是由训练数据的样式来决定的,无法自由的控制。现在我们希望能够生成 diverse 甚至是 controllable 的 caption。所谓 diverse,就是我们希望生成不受训练数据约束的 caption,比如最近受关注的 novel object captioning,就是被描述的物体在训练集当中从未出现过的情况。而所谓 controllable,就是我们希望我们能够控制生成的 caption,比如 style (幽默/正式/口语等等)以及被描述的重点物体与区域,比如我们可以决定生成的 caption 是描述图像背景还是描述前景中某个物体的,也可以决定其描述的详细程度。

另外一个方向是 reasoning,也就是视觉推理。我们知道在 VQA 里面,最常见的做法还是通过 feature embedding(比如cnn-rnn),end-to-end 的方式训练一个神经网络,这就导致中间的过程是一个黑箱,我们并不知道具体的推理过程是什么。即使我们有了 attention (注意力机制),也只是使得部分过程有了一定程度的可解释性,比如 attention 可以反映出模型在回答问题时聚焦在图像中哪些物体上。但是对于 VQA 这样的应用,推理的过程是至关重要的。所以针对这个方向,近期就有了一些新的数据和任务,比如 CLEVR 数据集,Visual Commonsense Reasoning 数据,以及最近 Chris Manning 提出的一个新的 GQA 的数据集。
第三个方向我把它总结为 ‘embodied‘,也就是将 vision-language 具体化到一些场景当中,不再是基于静态的图片或者无法交互的视频,而是一些可以交互的真实或者虚拟的场景。比如,在 18 年提出的 embodied QA 和 interactive QA,就是把 VQA 的问题放在了某一个场景下,回答问题需要 agent 在场景中移动甚至是交互。同时,我们组在 18 年提出了一个基于视觉-语言的导航任务 (Vision-and-Language Navigation),以及最近刚刚提出的一个 Remote Embodied Referring Expression 的任务,都是将 vision-language 放在了一个具体的场景当中去。
接下来我们就从这三个方面对一些去年的具有代表性的工作进行介绍,来看看这些任务和方法与过去有什么不同。
1. Novel Object Captioning
这里想给大家介绍的第一个工作来自于 Georgia Tech,他们提出了一个新的数据以及任务,叫做 novel object captioning。与传统的 image captioning 不同的是,他这里做了一个限制,就是限制在测试集当中出现的物体,在训练集当中从没有被描述过。这个概念其实类似于 zero-shot learning 的理念。在这个工作中,他们把数据分成了三个部分,分别是 in-domain,near-domain 和 out-of-domain,能够方便的对 image captioning 模型进行比较全面的测试。In domain 就是物体在训练集当中已经出现过,即经典的 image captioning 问题。Near-domain 是指图片中最显著的物体是 novel object,即没有在训练集中出现过,而其他物体则有可能在训练数据中被描述过。Out-of-domain 是最难的,图片中的所有物体都没有在训练集当中出现过。其实之前也有过类似的 setting,但是大部分都是从 coco image captioning 数据中分出不同的 split。而这个数据提供了新的标注,同时提供了不同的测试 domain,能够更全面的分析一个 image captioning 模型。

针对这个任务,也有一些新的方法被提出,其中,neural baby talk 就是比较好的一个工作。这个工作同样来自于 Georgia Tech,是由 Jiasen Lu 提出的,是 CVPR 2018 年的一篇 paper。在这个工作当中,受到之前 Babytalk 当中模板+填空的 captioning 生成方式的启发,他们把 novel-object image captioning 分成了两个步骤:第一个步骤是模板生成。但是与早期 Babytalk 中使用提前定义好的模板不同,这里的模板是根据图像自动生成的。就是在每生成一个词的时候,他做了一个判断,判断这个词应该是来自于文本还是来自于图像。来自于文本的词就组成了模板,比如下面这张图中,生成模板就是 A <region−17> is sitting at a <region−123> with a <region−3>. 这里的 region-17 其实就是图像里面的一个 region proposal。
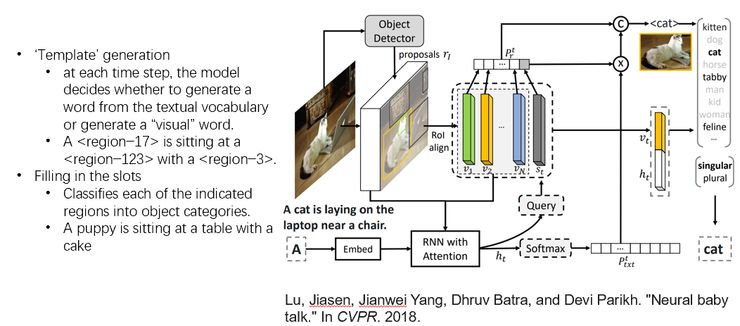
然后他的第二步叫做 Filling in the slots,也就是填空。他用一个外部训练的分类器去对上面的那些区域进行分类识别,然后将识别的结果填到上一步生成的 template 里面。所以这个时候,caption 的生成其实是不依赖于目标物体是否被描述过,而是依赖于一个外部训练的分类器,也就是只要这个分类器见过足够多的物体就可以,不需要有对应的 caption 数据。比如上面这个 region-17 识别的结果是 puppy,最后生成的 caption 就是 A puppy is sitting at a table with a cake。
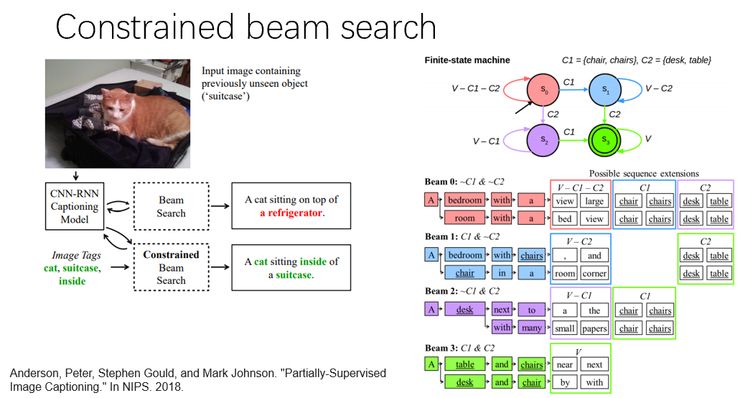
另外一个思路是由 ANU 的 Peter Anderson 提出的,叫做 constrained beam search。在 image captioning 里面常用的一个 trick 就是 beam search。就是说我们在选择下一个生成词的时候,不是只选择概率最大的那一个,而是选择概率最大的 b 个作为候选,b 就是 beam 的大小,然后再沿着这 b 个 candidate,继续寻找接下来的 b 个最佳的候选词。这里这个工作提出了一个 constrained beam search,就是在做 beam search 之前,他会先从图像当中提取一些 tag 出来。这个 tag 当然是可以外部训练的,可以是一些在 image captioning 训练集当中没有出现过的 tag。然后他利用这些标签建立了一个有限状态机(Finite-state machine),然后按照有限状态机的路线进行 beam search,使得生成的 caption,既能符合合适的语法结构,又能够包含所需的 tag。
2. Visual Reasoning
介绍完关于 novel object captioning 的工作,我们这里再介绍几个与 visual reasoning 相关的工作。说到 visual reasoning,就不得不提到 17 年的 CLEVR (Compositional Language and Elementary Visual Reasoning),这是第一个专门针对视觉推理任务建立的数据集。这个数据中的图片主要由是一些不同大小、颜色、形状、材质的几何体组成,虽然图像成分简单,但是问题本身却比较复杂,需要做比较复杂的推理。比如这里图中的第一个问题就是 ‘大物体和金属球的数量是一样的吗?’,为了能回答这个问题,我们首先需要找出大的物体还有金属球(通过视觉),然后要分别计算各自的数量,最后判断两者的数量是不是相等,也就是为了回答这么一个问题,我们需要三步的推理。
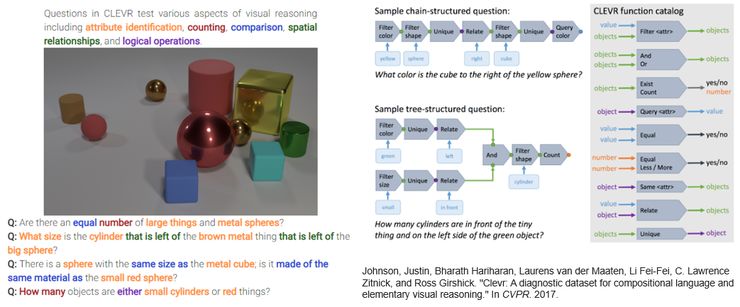
CLEVR 数据除了提供图片-问题-答案这样的标注之外,也提过了逻辑推理过程(叫做 function)的标注,比如上面这个问题需要三步的推理过程,就会有一个标注是将三个 function 连接成一个推理链。也就是提供了推理的 ground-truth,我们不仅能够检验模型是否回答对问题,还能够真正的评价一个模型是否具有足够强的推理能力。这篇文章也发现在传统 VQA 数据上表现很好的模型(比如 MCB)在 CLEVR 上表现并不好,说明传统的 VQA 结构并没有办法通过 End-to-End 的训练来具备推理能力,需要有新的模型能够完成相应的推理。
这个数据提出以后,也有很多新的方法被提出来,比如像 Modular Network 在这项任务上表现就很好。我们这里挑选其中比较有名一个叫做 MAC(Memory,Attention and Composition)的方法进行介绍。MAC 是由 NLP 领域里的巨擘 Chris Manning 提出的,是 ICLR18 的一篇文章。
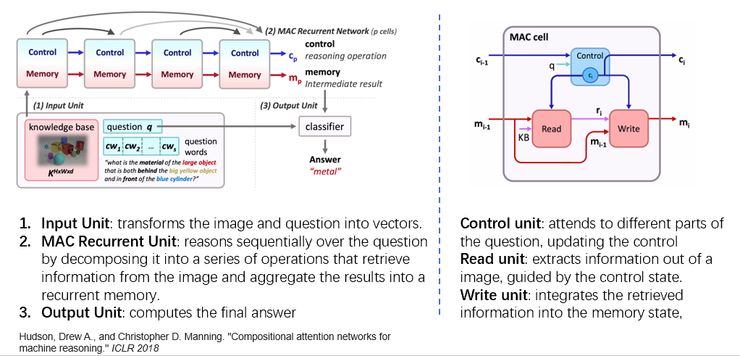
MAC 提供了一种全可微的模块式的推理结构。一个 MAC 网络主要分成了三个部分,输入部分主要负责把图像和问题进行编码。MAC recurrent unit 部分主要是通过对 MAC 基本单元的堆叠以及排列进行多次的推理。最后的输出部分是结合推理后的特征得出答案。这里的关键部分就是一个所谓的 MAC 神经元。MAC 神经元又由三个运算元串联运行组成:控制单元更新控制状态,以便在每次迭代中参与待解答问题的一些部分; 读取单元在控制状态和记忆状态的引导下,提取信息; 写入单元将这些检索得到的信息整合进记忆状态,迭代计算答案。这个模型的好处是整个‘推理’过程利用了 soft attention 机制对图像信息进行多轮的提取,整个过程全可微,坏处就是整个过程还是‘黑箱’,无法提供 explicit reasoning 的过程。
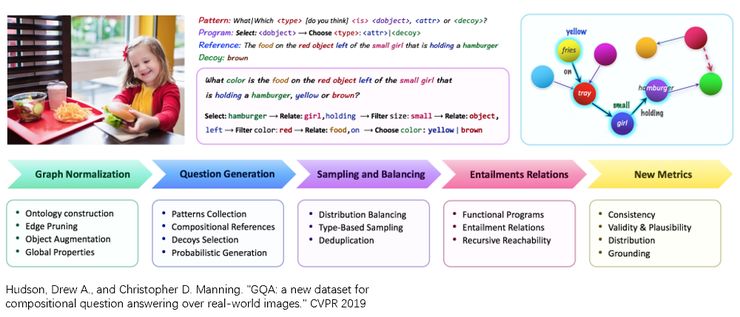
在最近的 CVPR19 上,Chris Manning 组又提出了一个新的数据叫做 GQA,可以看作是 CLEVR 的一个真实图像的版本。因为 CLEVR 当中的物体都是一些简单的几何体,形式比较单一。GQA 使用了真实的常见图像作为输入,问题的类型和 CLEVR 很类似,都需要很强的视觉推理能力才能够完成。比如这里这个问题是:‘拿汉堡的那个小女孩儿的左边的红色物体上的食物是什么颜色的,黄色还是棕色?’。 回答这个问题,需要很强的空间以及逻辑推理能力。同样的,类似于 CLEVR,这个数据也提供了所需逻辑推理链的标注。
另外一个和 reasoning 相关的工作,也是将出现在 CVPR19 上的最新的工作,叫做 VCR,Visual Commonsense Reasoning。
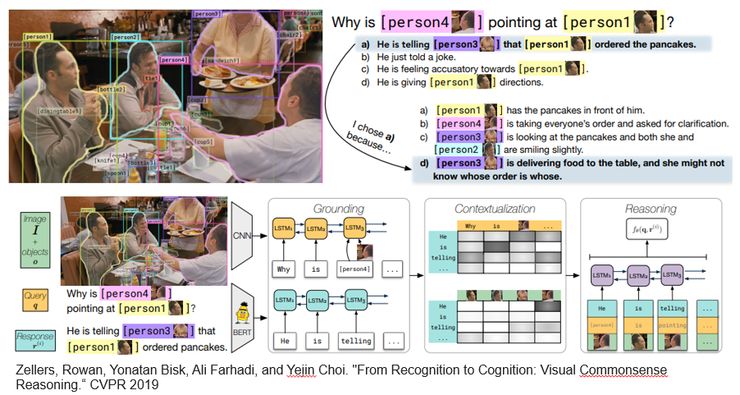
这个工作很有意思,它会给图片、给区域、给问题,模型必须在选择题中选出一项正确答案。但是在选择正确答案的同时,还需要选择出给出这个答案的原因。他们把这种能力称之为 Cognition,就是认知能力。比如这副图当中,问题是,为什么 person 4 指着 person 1。正确答案是,他正告诉 person 3 是 person 1 点了 pancake。而选择这个答案的原因是,Person 3 正在给这张桌子上餐,她可能不知道这个是谁点的。我们可以看到,回答这个问题不仅仅需要视觉的感知能力,还需要常识,以及推理等认知能力。是非常有挑战性的。这篇文章也提供一个简单的 baseline。整个模型分为三个步骤,(1)grounding,理解问题和答案的意思;(2)contextualizing,结合图像、问题、答案进行进一步理解,如弄清楚指代对象;(3)reasoning,推理视觉区域之间的内在联系。我们组其实一直都在关注如何将 common sense 引入到 vision-language 里面来,比如 17 年提出的 FVQA。这个工作很有前瞻性,但是我个人认为这个任务对于目前的 vision-language 还是太难了,因为我们目前并没有一个非常完整的 common sense 的知识库,而这个数据的规模也不足以让我们学习到所需的 common sense,即使学习到,也是一种 overfitting。我认为目前的推理,应该是最好抛开 common sense 甚至是 domain knowledge,只在 visual 上去做,类似于CLEVR和GQA。
3. Embodied Vision-and-Language
在上一篇《万字漫谈vision-language-action》里我们就提到过,将 vision-language 和 action 结合起来是一个非常热门并且 promising 的方向,包括我们组在内,很多大组都在这个方向上有所动作。
首先我们介绍一下 embodied VQA。 这个任务是融合多模态信息,通过向放置在一个虚拟环境中的 agent 提出基于文本的问题,需要其在虚拟的空间环境中进行路径规划(Navigation)和探索,以到达目标位置并回答问题。比如这里的一个问题是,汽车是什么颜色的?但是这个 agent 在当前位置并看不到汽车,他就要先进行路径规划,到达汽车所在的位置,从而进一步的给出答案。这就需要 agent 能够理解他们所处的环境,具有一定的路径规划和探索能力,同时又能够回答问题。然后在 CVPR19 的一篇文章,是 Licheng Yu 他们提出的,是基于 Embodied VQA,把问题又提高了一个难度,叫做 MT-EQA。 在这个任务当中,问题不是关于单一的物体,而是涉及到不同房间的不同物体,比如这里这个问题是卧室里的梳妆台和卫生间的盥洗台是一个颜色么?
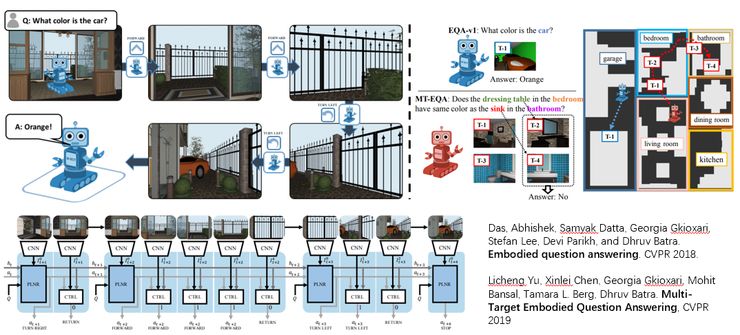
另外一个非常值得关注的方向就是我们在 18 年 CVPR 上提出的 Vision-and-Language Navigation (https://bringmeaspoon.org/)。在这个任务当中,我们提供一个基于真实拍摄室内场景的虚拟环境,这些环境里面包含不同的房间(比如厨房,卧室,客厅)和物品。将一个 agent 放置在这个环境当中后,我们会给出一段基于自然语言的详细的导航指令,比如离开某个房间,去到某个房间,遇到什么物体向哪个方向拐,停在哪里等等。然后我们需要这个 agent 能够跟随这个指令,按照指令所描述的路径,到达对应的目的地。这就需要模型对语言和图像同时进行理解,把语言当中描述的位置以及关键点,定位到真实场景图像当中,然后执行相对应的动作。这个数据在发布之后也受到很大的关注,我们也举办了相应的 challenge。
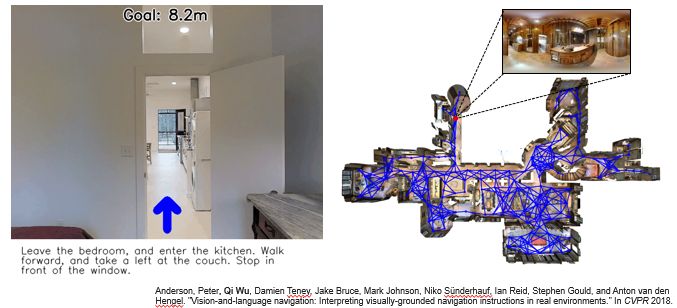
我们知道人工智能的一个长期目标就是建立一个能够观察理解周围环境,并且与人类交流,执行相关命令的智能机器人。Computer vision 主要是教会机器人去感知,去看周围的环境,而 NLP 赋予了机器人理解以及产生语言的能力。Referring expression 可以当作是一种最简单的 vision-language-action 模式,vision 是静态的图片,language 就是输入的 query,action 就是一个简单的 pointing 或者 detecting 的操作。而 vision-language navigation 会稍微复杂一些,视觉的输入变成了动态的环境,language 变成了一个很长的导航指令,动作也变成了一系列的前后左右移动的动作。但是这个任务其实仔细想的话并不是特别符合实际,就是我们为什么要给机器人一个这么复杂的指令帮助他去规划路径呢。而 referring expression 也并不是很切合实际,就是为什么我们明明可以看到图片中的这个物体,还需要机器人帮我们指出来呢?在现实当中,我们其实想要的是一个简单的带有目的性的指令,比如让机器人去某个目的地去找某个他现在还观察不到的物体,也就是 remote objects。比如,Bring me a cushion from the living room 就非常能够切入到实际场景当中去。
于是今年,基于上面提出的关于 navigation 的任务, 我们又提出了一个将 navigation 和 referring expression 相结合的一个任务,叫做 RERERE: Remote Embodied Referring Expressions in Real indoor Environments。在这个任务当中,同样我们会将 agent 放置于场景中的一个起始点,与上一篇中给一个很长的 navigation guidance 不同的是,我们这里指令更加精炼,并且同时包含了两个任务,一个是导航到目的地,一个找到所描述的对应的物品。比如,图中这个例子 ‘Go to the stairs on level one and bring me the bottom picture that is next to the top of stairs.’, 我们只给出了物品所在的目的地,而没有给出具体的路径,这个更加符合我们人类的习惯。而对于目的地的物体,我们也会以自然语言的形式,给出描述,从而能够使其区别于其他物体。
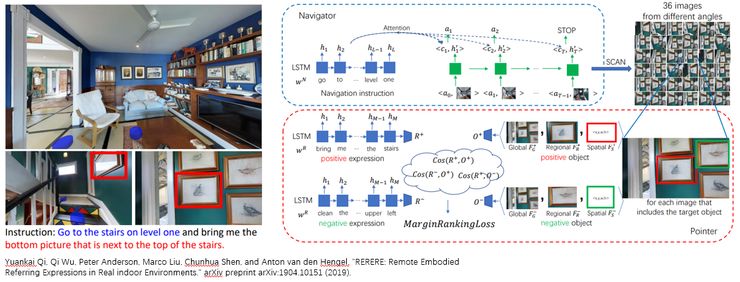
同时,在这个工作当中,我们也提出了一个将 navigation 与 referring expression 结合的 navigator-pointer 模型。当然,与人的 performance 相比,还有一定的差距。
总结:
最后总结一下,首先我们看到在经典的 vision-language 任务上,比如 image captioning 和 VQA,能够增长的空间已经很小,已经过了暴力的通过数据去学习的阶段。真正的挑战其实是一些细分的领域,比如多样性、可控性、推理以及如何将 vision-language 应用在真实的场景当中。18 年我们提出了很多有趣的、有挑战性的新的任务,相信接下来几年会有很多新的方法被提出,来解决这些新的挑战。也欢迎大家能够关注我们的 embodied visual-navigation + referring expression 任务,在这些新数据和任务上提出并研究新的算法。
最后,打个广告,我们组有两个 vision-and-language 方向的全奖 PhD 名额,如果对这个方向感兴趣,可以与我联系(Dr. Qi Wu, qi.wu01@adelaide.edu.au)。
作者简介:
吴琦博士现任澳大利亚阿德莱德大学(University of Adelaide)高级讲师(助理教授),澳大利亚机器视觉研究中心(Australia Centre for Robotic Vision)Associate Investigator(副课题组长),澳大利亚国家杰出青年基金项目获得者 (Australian Research Council DECRA Fellow),澳大利亚科学院罗素奖(JG Russell Award)获得者, 2018 NVIDIA Pioneering Research Award 获得者。吴琦博士于 2015 年在英国巴斯大学获得博士学位,致力于计算机视觉领域研究,尤其关注于 Vision-Language 相关领域的研究,包括 image captioning,visual question answering,visual dialog 等。目前已在 CVPR,ICCV,ECCV,AAAI,TPAMI 等会议与刊物上发表论文三十余篇。担任 CVPR,ICCV,ECCV,NIPS,TPAMI,IJCV,TIP,TNN 等会议与期刊审稿人。

点击阅读原文,加入 CVPR 顶会交流小组




