目标检测中的Consistent Optimization
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
昨天分享了一篇:FoveaBox,超越Anchor-Based的检测器,今天带来FoveaBox作者的另一个工作Consistent Optimization for Single-Shot Object Detection,简洁有效。
作者 | 孔涛
来源 | https://zhuanlan.zhihu.com/p/59915784

论文链接:arxiv.org/abs/1901.0656
我的合作者和我都非常喜欢这个工作!在这个工作中,我们发现了Single-Stage Detector中普遍存在的训练和测试不一致的问题,然后用一个简单、有效、不改变原有结构的Consistent Optimization策略来解决它,加入Consistent Optimization的RetinaNet在COCO上用ResNet-101达到了40+AP,这是目前single-stage已知的在ResNet-101下最高的单模型单尺度的预测结果。代码会尽快release到github上。(不过因为方法非常简单直接,复现应该不难)。
目前,大多数的Detector模型改进方法都集中在了two-stage阵营中,比如Cascade R-CNN、IoU-Net,One-Stage自从RetinaNet之后的工作就比较少了。相对于Two-Stage而言,One-Stage其实更难一些,因为它依赖于全卷积结构来对feature map上进行均匀采样的anchor进行分类和位置调整。怎样才能对现有的one-stage方法进行改进呢?在本文中我们对RetinaNet的结果进行了分析,并发现训练和测试的不一致是其中一个重要的原因。
1. 观察和分析
我们首先可视化了RetinaNet的regression分支的结果,发现anchor在regression之前和之后的定位性能的差别是非常大的。一个本身与ground-truth的IoU较小的anchor在回归之后依然可以与ground-truth的IoU变得较大。
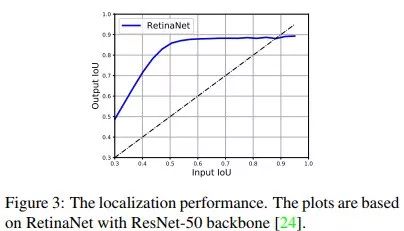
从另一个方面讲,classification分支是基于原始的anchor进行训练的,在标准的设置中,会将IoU>0.5的样本算作是正样本,IoU<0.4的设置为负样本,然后用focal loss训练。在测试中将原始anchor训练的得分赋给调整之后的anchor。因为anchor的定位性能在回归前和回归后是不同的,这必然导致classification分支得到的得分与回归后的anchor的定位能力表现不一致。为了进一步验证这个假设,我们可视化了anchor得分的分布
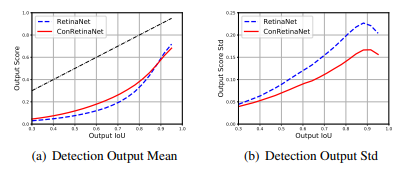
我们发现,分类得分的方差随着IoU的增长会不断变大(大于0.9的样本的统计其实不具备可信度,因为样本数太少)。我们认为,正是因为基于原始anchor训练的得分赋予了回归后的anchor,导致了目标anchor的分类的方差较大(方差大表示不鲁棒,置信度不高)。另外,我们对部分COCO的detection的结果进行验证分析发现了如下两个问题:(a)不同类别的物体之前存在遮挡导致的inter-class confusion,和(b)foreground-background classification error。(详细见原文)
2. 解决方法
基于上边的观察和分析,一种非常直观的解决办法就是将回归之后的anchor进行训练。这种策略马上就会联想到Cascade R-CNN,是否可以用类似于Cascade的方式呢?具体实现上我们比较了几种比较典型的实现方法:
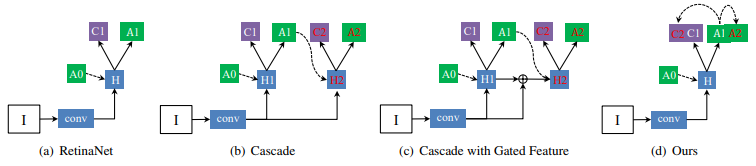
(b)实现方式其实就是Cascade直接在one-stage上的扩展:在原有的regression/classification head基础上,加入跟原来结构一样的head,用于训练regress之后的anchor,参数与原来的不共享;(c)添加了更多的context信息,这些feature来源于前一个阶段的feature,(d)是最终我们发现更有效的方法。这种方法只是在优化目标上加入了回归后的anchor,而不改变原来的网络结构,因此在测试的时候可以保持跟原来one-stage的做法一致。
从优化目标上,classification分支从原来的一项变成了两项,一项是原始的anchor,另一项是回归后的anchor,其网络的输出 
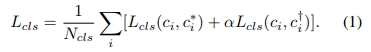
在实验验证中我们发现,只用回归后的anchor进行监督训练已经比原始的anchor的性能好。加入原始的anchor训练过程更稳定,不影响最终的结果。
为了保持跟classification一致,regression也添加了一项,相当于把每一个Anchor回归两次。
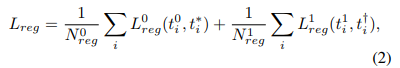
3. 实验验证
3.1我们对几种典型的实现方法进行对比,发现最后一种是最为有效的,更重要的是它几乎不需要额外的参数,计算更快,训练更稳定。
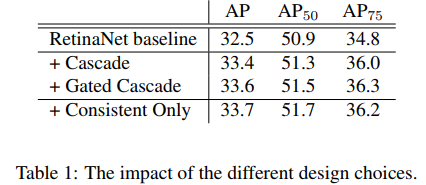
3.2 在训练的时候采用consistent classification和localization进行训练,加入在测试的时候只做一次回归会怎样呢?答案是即使是只回归一次,也会相对于不训练的版本效果变好。这说明consistent localization本身就有帮助原始anchor向更正确的方向回归的效果。
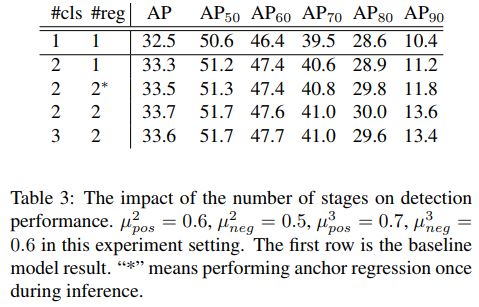
3.3在RetinaNet上进行了详尽的实验,包括模型大小和输入图片大小。我们发现,Consistent Optimization独立于这些因素,提升原有baseline的性能大约+1.0 AP
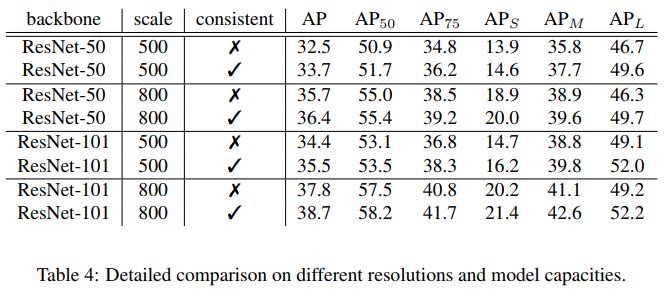
3.4我们也在SSD上验证了方法的有效性,虽然分析是基于RetinaNet的,但是在SSD上同样适用~+1.5 AP。
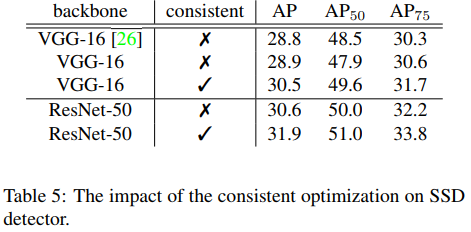
3.5最终的结果对比,注意到在one-stage方法中的CornerNet虽然取得了40+AP,但是它在测试的时候用了flip等测试的trick,并且Hourglass需要更多的训练/测试时间及参数。
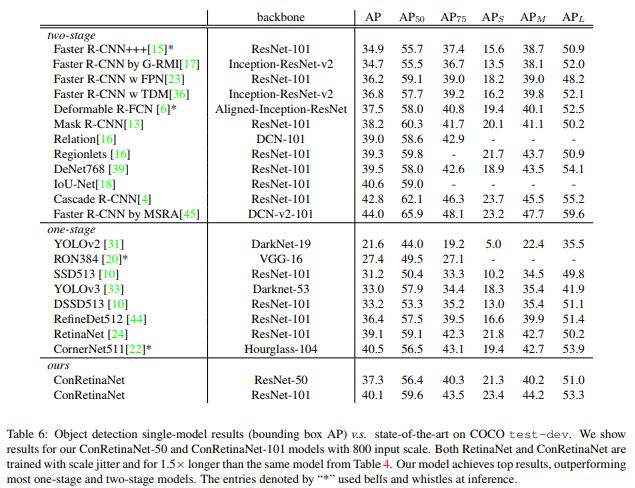
原文中还有更多必要的ablation study和一些有意思的讨论和实验对比(比如如何将Cascade的思想用到one-stage中),就不多提了,感兴趣的小伙伴看下原文。
欢迎提意见、评论!
*延伸阅读
普林斯顿大学提出:CornerNet-Lite,基于关键点的实时且精度高的目标检测算法,已开源!
中科院牛津华为诺亚提出:CenterNet,One-stage目标检测最强算法!可达47mAP,已开源!
目标检测:Anchor-Free时代
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~



