AI 圣经《深度学习》作者斩获 2018 年图灵奖,100 万奖励!| 码书


2019 年 3 月 27 日,ACM 宣布,深度学习之父 Yoshua Bengio、Yann LeCun 以及 Geoffrey Hinton 获得了 2018 年的图灵奖,被称为“计算机领域的诺贝尔奖”。其中,Yoshua Bengio 是《深度学习》作者之一。
今天,深度学习已经成为了人工智能技术领域最重要的技术之一。在最近数年中,计算机视觉、语音识别、自然语言处理和机器人取得的爆炸性进展都离不开深度学习。
三人在人工智能领域的成就数不胜数,但是ACM依然列数了三位大咖最值得被记住的成就,我们也在此重新回顾他们的故事,简直就是一部人工智能/深度学习的发家史。
图灵奖(Turing Award),全称“A.M. 图灵奖(A.M Turing Award)” ,由美国计算机协会(ACM)于1966年设立,专门奖励那些对计算机事业作出重要贡献的个人 。其名称取自计算机科学的先驱、英国科学家艾伦·麦席森·图灵(Alan M. Turing) 。它是计算机界最负盛名、最崇高的一个奖项,有“计算机界的诺贝尔奖”之称 。
图灵奖设奖初期为20万美元,1989年起增到25万美元,奖金通常由计算机界的一些大企业提供(通过与ACM签订协议)。目前图灵奖由Google公司赞助,奖金为1,000,000美元。

三位作者在深度学习领域贡献
Yoshua Bengio
《深度学习》作者

序列的概率模型:在 20 世纪 90 年代,Bengio 将神经网络与序列的概率模型相结合,例如隐马尔可夫模型。这些想法被纳入 AT&T / NCR 用于阅读手写支票中,被认为是 20 世纪 90 年代神经网络研究的巅峰之作。现代深度学习语音识别系统也是这些概念的扩展。
高维词汇嵌入和关注:2000 年,Bengio 撰写了具有里程碑意义的论文“A Neural Probabilistic Language Model”,它引入了高维词向量作为词义的表示。Bengio 的见解对自然语言处理任务产生了巨大而持久的影响,包括语言翻译、问答和视觉问答。他的团队还引入了注意力机制,这种机制促使了机器翻译的突破,并构成了深度学习的序列处理的关键组成部分。
生成性对抗网络:自 2010 年以来,Bengio 关于生成性深度学习的论文,特别是与 Ian Goodfellow 共同开发的生成性对抗网络(GAN),引发了计算机视觉和计算机图形学的革命。
Geoffrey Hinton

反向传播:在 1986 年与 David Rumelhart 和 Ronald Williams 共同撰写的 “Learning Internal Representations by Error Propagation” 一文中,Hinton 证明了反向传播算法允许神经网络发现自己的数据内部表示,这使得使用神经网络成为可能网络解决以前被认为超出其范围的问题。如今,反向传播算法是大多数神经网络的标准。
玻尔兹曼机(Boltzmann Machines):1983 年,Hinton 与 Terrence Sejnowski 一起发明了玻尔兹曼机,这是第一个能够学习不属于输入或输出的神经元内部表示的神经网络之一。
卷积神经网络的改进:2012 年,Hinton 和他的学生 Alex Krizhevsky 以及 Ilya Sutskever 通过 Rectified Linear Neurons 和 Dropout Regularization 改进了卷积神经网络,并在著名的 ImageNet 评测中将对象识别的错误率减半,在计算机视觉领域掀起一场革命。
Yann LeCun

卷积神经网络:在 20 世纪 80 年代,LeCun 研发了卷积神经网络,现已成为该领域的基本理论基础。其让深度学习更有效。在 20 世纪 80 年代后期,多伦多大学和贝尔实验室工作期间,LeCun 是第一个在手写数字图像上训练卷积神经网络系统的人。如今,卷积神经网络是计算机视觉以及语音识别、语音合成、图像合成和自然语言处理的行业标准。它们用于各种应用,包括自动驾驶、医学图像分析、语音激活助手和信息过滤。
改进反向传播算法:LeCun 提出了一个早期的反向传播算法 backprop,并根据变分原理对其进行了简洁的推导。他的工作让加快了反向传播算,包括描述两种加速学习时间的简单方法。
拓宽神经网络的视野:LeCun 还将神经网络作为可以完成更为广泛任务的计算模型,其早期工作现已成为 AI 的基础概念。例如,在图像识别领域,他研究了如何在神经网络中学习分层特征表示,这个理念现在通常用于许多识别任务中。与 LéonBottou 一起,他还提出了学习系统可以构建为复杂的模块网络,其中通过自动区分来执行反向传播,目前在每个现代深度学习软件中得到使用。他们还提出了可以操作结构化数据的深度学习架构,例如图形。

《深度学习》讲了什么?
深度学习这个术语自 2006 年被正式提出后,在最近 10 年得到了巨大发展。它使人工智能 (AI) 产生了革命性的突破,让我们切实地领略到人工智能给人类生活带来改变的潜力。2016 年 12 月,MIT 出版社出版了 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 三位学者撰写的《Deep Learning》一书。三位作者一直耕耘于机器学习领域的前沿,引领了深度学习的发展潮流,是深度学习众多方法的主要贡献者。该书正应其时,一经出版就风靡全球。

该书包括 3 个部分,第 1 部分介绍基本的数学工具和机器学习的概念,它们是深度学习 的预备知识。第 2 部分系统深入地讲解现今已成熟的深度学习方法和技术。第 3 部分讨论某 些具有前瞻性的方向和想法,它们被公认为是深度学习未来的研究重点。因此,该书适用于 不同层次的读者。我本人在阅读该书时受到启发良多,大有裨益,并采用该书作为教材在北 京大学讲授深度学习课程。
这是一本涵盖深度学习技术细节的教科书,它告诉我们深度学习集技术、科学与艺术于 一体,牵涉统计、优化、矩阵、算法、编程、分布式计算等多个领域。书中同时也蕴含了作者 对深度学习的理解和思考,处处闪烁着深刻的思想,耐人回味。第1 章关于深度学习的思想、 历史发展等论述尤为透彻而精辟。
作者在书中写到:“人工智能的真正挑战在于解决那些对人来说很容易执行、但很难形式 化描述的任务,比如识别人们所说的话或图像中的脸。对于这些问题,我们人类往往可以凭 直觉轻易地解决”。为了应对这些挑战,他们提出让计算机从经验中学习,并根据层次化的概 念体系来理解世界,而每个概念通过与某些相对简单的概念之间的关系来定义。由此,作者 给出了深度学习的定义:“层次化的概念让计算机构建较简单的概念来学习复杂概念。如果绘 制出表示这些概念如何建立在彼此之上的一幅图,我们将得到一张`深'(层次很多) 的图。由 此,我们称这种方法为AI 深度学习(deep learning)”。
《深度学习》中文版从引进版权到正式出版历经三年,中文版的推出填补了目前国内缺乏深度学习综合性教科书的空白。该书从浅入深介绍了基础数学知识、机器学习经验以及现阶段深度学习的理论和发展,它能帮助人工智能技术爱好者和从业人员在三位专家学者的思维带领下全方位了解深度学习。该书一经推出变横扫畅销榜。
这是一本教科书,又不只是一本教科书,任何对深度学习感兴趣的读者,阅读本书都会受益。除了学习机器学习的大学生,没有机器学习或统计背景的软件工程师也可以通过本书快速补充相关知识,并在他们的产品或平台中使用。
本书最大的一个特点是介绍深度学习算法的本质,脱离具体代码实现给出算法背后的逻辑,不写代码的人也完全可以看。本书的另一个特点是,为了方便读者阅读,作者特别绘制了本书的内容组织结构图,指出了全书20章内容之间的相关关系,如图所示。读者可以根据自己的背景或需要,随意挑选阅读。
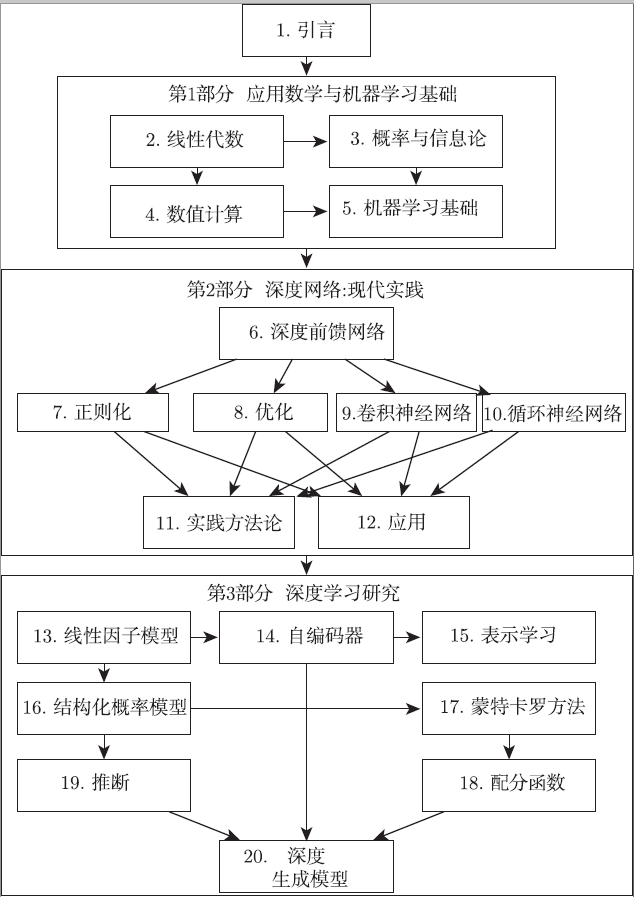
图1 《深度学习》中文版内容组织结构图。从一章到另一章的箭头表示前一章是理解后一章的必备内容。

《深度学习》的历史趋势
通过历史背景了解深度学习是最简单的方式。这里我们仅指出深度学习的几个关键趋势,而不是提供其详细的历史:
深度学习有着悠久而丰富的历史,但随着许多不同哲学观点的渐渐消逝,与之对应的名称也渐渐尘封。
随着可用的训练数据量不断增加,深度学习变得更加有用。
随着时间的推移,针对深度学习的计算机软硬件基础设施都有所改善,深度学习模型的规模也随之增长。
随着时间的推移,深度学习已经解决日益复杂的应用,并且精度不断提高。
神经网络的众多名称和命运变迁
神经网络的众多名称和命运变迁
事实上,深度学习的历史可以追溯到20世纪40年代。深度学习看似是一个全新的领域,只不过因为在目前流行的前几年它还是相对冷门的,同时也因为它被赋予了许多不同的名称(其中大部分已经不再使用),最近才成为众所周知的“深度学习”。这个领域已经更换了很多名称,它反映了不同的研究人员和不同观点的影响。
迄今为止深度学习已经经历了3次发展浪潮:20世纪40年代到60年代,深度学习的雏形出现在控制论(cybernetics)中;20世纪 80年代到 90年代,深度学习表现为联结主义(connectionism);直到 2006 年,才真正以深度学习之名复兴。图1给出了定量的展示。
我们今天知道的一些最早的学习算法,旨在模拟生物学习的计算模型,即大脑怎样学习或为什么能学习的模型。其结果是深度学习以人工神经网络(artificial neural network,ANN)之名而淡去。彼时,深度学习模型被认为是受生物大脑(无论人类大脑或其他动物的大脑)所启发而设计出来的系统。尽管有些机器学习的神经网络有时被用来理解大脑功能(Hinton and Shallice,1991),但它们一般都没有设计成生物功能的真实模型。深度学习的神经观点受两个主要思想启发:一个想法是,大脑作为例子证明智能行为是可能的,因此,概念上,建立智能的直接途径是逆向大脑背后的计算原理,并复制其功能;另一种看法是,理解大脑和人类智能背后的原理也非常有趣,因此机器学习模型除了解决工程应用的能力,如果能让人类对这些基本的科学问题有进一步的认识,也将会很有用。
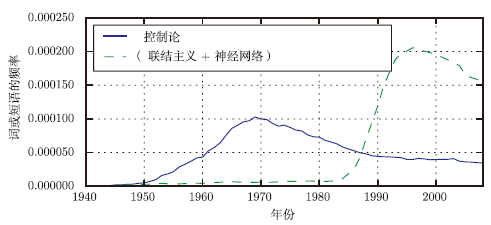
图2 根据Google图书中短语“控制论”“联结主义”或“神经网络”频率衡量的人工神经网络研究的历史浪潮(图中展示了3次浪潮的前两次,第3次最近才出现)。第1次浪潮开始于20世纪40年代到20世纪60年代的控制论,随着生物学习理论的发展(Mc Culloch and Pitts,1943;Hebb,1949)和第一个模型的实现(如感知机(Rosenblatt,1958)),能实现单个神经元的训练。第2次浪潮开始于1980—1995年间的联结主义方法,可以使用反向传播(Rumelhart et al.,1986a)训练具有一两个隐藏层的神经网络。当前第3次浪潮,也就是深度学习,大约始于2006年(Hinton et al.,2006a;Bengio et al.,2007a;Ranzato et al.,2007a),并且于2016年以图书的形式出现。另外,前两次浪潮类似地出现在书中的时间比相应的科学活动晚得多
现代术语“深度学习”超越了目前机器学习模型的神经科学观点。它诉诸于学习多层次组合这一更普遍的原理,这一原理也可以应用于那些并非受神经科学启发的机器学习框架。
现代深度学习最早的前身是从神经科学的角度出发的简单线性模型。这些模型设计为使用一组n个输入x1,…,xn,并将它们与一个输出y相关联。这些模型希望学习一组权重w1,…,wn,并计算它们的输出f(x,w)=x1w1+…+xnwn。如图1.7所示,第一次神经网络研究浪潮称为控制论。
McCulloch-Pitts 神经元(McCulloch and Pitts,1943)是脑功能的早期模型。该线性模型通过检验函数 f(x,w)的正负来识别两种不同类别的输入。显然,模型的权重需要正确设置后才能使模型的输出对应于期望的类别。这些权重可以由操作人员设定。20 世纪 50 年代,感知机(Rosenblatt,1956,1958)成为第一个能根据每个类别的输入样本来学习权重的模型。大约在同一时期,自适应线性单元(adaptive linear element,ADALINE)简单地返回函数f(x)本身的值来预测一个实数,并且它还可以学习从数据预测这些数。
这些简单的学习算法大大影响了机器学习的现代景象。用于调节ADALINE权重的训练算法是被称为随机梯度下降(stochastic gradient descent)的一种特例。稍加改进后的随机梯度下降算法仍然是当今深度学习的主要训练算法。
基于感知机和 ADALINE中使用的函数 f(x,w)的模型称为线性模型(linear model)。尽管在许多情况下,这些模型以不同于原始模型的方式进行训练,但仍是目前最广泛使用的机器学习模型。
线性模型有很多局限性。最著名的是,它们无法学习异或(XOR)函数,即f([0,1],w)=1和f([1,0],w)=1,但f([1,1],w)=0和f([0,0],w)=0。观察到线性模型这个缺陷的批评者对受生物学启发的学习普遍地产生了抵触(Minsky and Papert,1969)。这导致了神经网络热潮的第一次大衰退。
现在,神经科学被视为深度学习研究的一个重要灵感来源,但它已不再是该领域的主要指导。
如今神经科学在深度学习研究中的作用被削弱,主要原因是我们根本没有足够的关于大脑的信息来作为指导去使用它。要获得对被大脑实际使用算法的深刻理解,我们需要有能力同时监测(至少是)数千相连神经元的活动。我们不能够做到这一点,所以我们甚至连大脑最简单、最深入研究的部分都还远远没有理解(Olshausen and Field,2005)。
神经科学已经给了我们依靠单一深度学习算法解决许多不同任务的理由。神经学家们发现,如果将雪貂的大脑重新连接,使视觉信号传送到听觉区域,它们可以学会用大脑的听觉处理区域去“看”(Von Melchner et al.,2000)。这暗示着大多数哺乳动物的大脑使用单一的算法就可以解决其大脑可以解决的大部分不同任务。在这个假设之前,机器学习研究是比较分散的,研究人员在不同的社群研究自然语言处理、计算机视觉、运动规划和语音识别。如今,这些应用社群仍然是独立的,但是对于深度学习研究团体来说,同时研究许多甚至所有这些应用领域是很常见的。
我们能够从神经科学得到一些粗略的指南。仅通过计算单元之间的相互作用而变得智能的基本思想是受大脑启发的。新认知机(Fukushima,1980)受哺乳动物视觉系统的结构启发,引入了一个处理图片的强大模型架构,它后来成为了现代卷积网络的基础(LeCun et al.,1998c)(参见第 9.10 节)。目前大多数神经网络是基于一个称为整流线性单元(rectified linear unit)的神经单元模型。原始认知机(Fukushima,1975)受我们关于大脑功能知识的启发,引入了一个更复杂的版本。简化的现代版通过吸收来自不同观点的思想而形成,Nair and Hinton(2010b)和 Glorot et al.(2011a)援引神经科学作为影响,Jarrett et al.(2009a)援引更多面向工程的影响。虽然神经科学是灵感的重要来源,但它不需要被视为刚性指导。我们知道,真实的神经元计算着与现代整流线性单元非常不同的函数,但更接近真实神经网络的系统并没有导致机器学习性能的提升。此外,虽然神经科学已经成功地启发了一些神经网络架构,但我们对用于神经科学的生物学习还没有足够多的了解,因此也就不能为训练这些架构用的学习算法提供太多的借鉴。
媒体报道经常强调深度学习与大脑的相似性。的确,深度学习研究者比其他机器学习领域(如核方法或贝叶斯统计)的研究者更可能地引用大脑作为影响,但是大家不应该认为深度学习在尝试模拟大脑。现代深度学习从许多领域获取灵感,特别是应用数学的基本内容,如线性代数、概率论、信息论和数值优化。尽管一些深度学习的研究人员引用神经科学作为灵感的重要来源,然而其他学者完全不关心神经科学。
值得注意的是,了解大脑是如何在算法层面上工作的尝试确实存在且发展良好。这项尝试主要被称为“计算神经科学”,并且是独立于深度学习的领域。研究人员在两个领域之间来回研究是很常见的。深度学习领域主要关注如何构建计算机系统,从而成功解决需要智能才能解决的任务,而计算神经科学领域主要关注构建大脑如何真实工作的、比较精确的模型。
20 世纪 80 年代,神经网络研究的第二次浪潮在很大程度上是伴随一个被称为联结主义(connectionism)或并行分布处理(parallel distributed processing)潮流而出现的(Rumelhart et al.,1986d;McClelland et al.,1995)。联结主义是在认知科学的背景下出现的。认知科学是理解思维的跨学科途径,即它融合多个不同的分析层次。20世纪80年代初期,大多数认知科学家研究符号推理模型。尽管这很流行,但符号模型很难解释大脑如何真正使用神经元实现推理功能。联结主义者开始研究真正基于神经系统实现的认知模型(Touretzky and Minton,1985),其中很多复苏的想法可以追溯到心理学家Donald Hebb在20世纪40年代的工作(Hebb,1949)。
联结主义的中心思想是,当网络将大量简单的计算单元连接在一起时可以实现智能行为。这种见解同样适用于生物神经系统中的神经元,因为它和计算模型中隐藏单元起着类似的作用。
在20世纪80年代的联结主义期间形成的几个关键概念在今天的深度学习中仍然是非常重要的。
其中一个概念是分布式表示(distributed representation)(Hinton et al.,1986)。其思想是:系统的每一个输入都应该由多个特征表示,并且每一个特征都应该参与到多个可能输入的表示。例如,假设我们有一个能够识别红色、绿色或蓝色的汽车、卡车和鸟类的视觉系统,表示这些输入的其中一个方法是将 9个可能的组合:红卡车、红汽车、红鸟、绿卡车等使用单独的神经元或隐藏单元激活。这需要9个不同的神经元,并且每个神经必须独立地学习颜色和对象身份的概念。改善这种情况的方法之一是使用分布式表示,即用3个神经元描述颜色,3个神经元描述对象身份。这仅仅需要6个神经元而不是9个,并且描述红色的神经元能够从汽车、卡车和鸟类的图像中学习红色,而不仅仅是从一个特定类别的图像中学习。分布式表示的概念是本书的核心,我们将在第15章中更加详细地描述。
联结主义潮流的另一个重要成就是反向传播在训练具有内部表示的深度神经网络中的成功使用以及反向传播算法的普及(Rumelhart et al.,1986c;Le Cun,1987)。这个算法虽然曾黯然失色且不再流行,但截至写书之时,它仍是训练深度模型的主导方法。
20 世纪 90 年代,研究人员在使用神经网络进行序列建模的方面取得了重要进展。Hochreiter(1991b)和 Bengio et al.(1994b)指出了对长序列进行建模的一些根本性数学难题,这将在第 10.7 节中描述。Hochreiter 和 Schmidhuber(1997)引入长短期记忆(long shortterm memory,LSTM)网络来解决这些难题。如今,LSTM在许多序列建模任务中广泛应用,包括Google的许多自然语言处理任务。
神经网络研究的第二次浪潮一直持续到20世纪90年代中期。基于神经网络和其他AI技术的创业公司开始寻求投资,其做法野心勃勃但不切实际。当AI研究不能实现这些不合理的期望时,投资者感到失望。同时,机器学习的其他领域取得了进步。比如,核方法(Boseret al.,1992;Cortes and Vapnik,1995;Schölkopf et al.,1999)和图模型(Jordan,1998)都在很多重要任务上实现了很好的效果。这两个因素导致了神经网络热潮的第二次衰退,并一直持续到2007年。
在此期间,神经网络继续在某些任务上获得令人印象深刻的表现(Le Cun et al.,1998c;Bengio et al.,2001a)。加拿大高级研究所(CIFAR)通过其神经计算和自适应感知(NCAP)研究计划帮助维持神经网络研究。该计划联合了分别由Geoffrey Hinton、Yoshua Bengio和Yann Le Cun领导的多伦多大学、蒙特利尔大学和纽约大学的机器学习研究小组。这个多学科的CIFARNCAP研究计划还包括了神经科学家、人类和计算机视觉专家。
在那个时候,人们普遍认为深度网络是难以训练的。现在我们知道,20世纪80年代就存在的算法能工作得非常好,但是直到2006年前后都没有体现出来。这可能仅仅由于其计算代价太高,而以当时可用的硬件难以进行足够的实验。
神经网络研究的第三次浪潮始于2006年的突破。Geoffrey Hinton表明名为“深度信念网络”的神经网络可以使用一种称为“贪婪逐层预训练”的策略来有效地训练(Hinton et al.,2006a),我们将在第15.1节中更详细地描述。其他CIFAR附属研究小组很快表明,同样的策略可以被用来训练许多其他类型的深度网络(Bengio and Le Cun,2007a;Ranzato et al.,2007b),并能系统地帮助提高在测试样例上的泛化能力。神经网络研究的这一次浪潮普及了“深度学习”这一术语,强调研究者现在有能力训练以前不可能训练的比较深的神经网络,并着力于深度的理论重要性上(Bengioand Le Cun,2007b;Delalleau and Bengio,2011;Pascanu et al., 2014a; Montufar et al., 2014)。此时,深度神经网络已经优于与之竞争的基于其他机器学习技术以及手工设计功能的AI系统。在写这本书的时候,神经网络的第三次发展浪潮仍在继续,尽管深度学习的研究重点在这一段时间内发生了巨大变化。第三次浪潮已开始着眼于新的无监督学习技术和深度模型在小数据集的泛化能力,但目前更多的兴趣点仍是比较传统的监督学习算法和深度模型充分利用大型标注数据集的能力。
与日俱增的数据量
与日俱增的数据量
人们可能想问,既然人工神经网络的第一个实验在20世纪50年代就完成了,但为什么深度学习直到最近才被认为是关键技术?自20世纪90年代以来,深度学习就已经成功用于商业应用,但通常被视为一种只有专家才可以使用的艺术而不是一种技术,这种观点一直持续到最近。确实,要从一个深度学习算法获得良好的性能需要一些技巧。幸运的是,随着训练数据的增加,所需的技巧正在减少。目前在复杂的任务中达到人类水平的学习算法,与20世纪80年代努力解决玩具问题(toy problem)的学习算法几乎是一样的,尽管我们使用这些算法训练的模型经历了变革,即简化了极深架构的训练。最重要的新进展是,现在我们有了这些算法得以成功训练所需的资源。图1.8展示了基准数据集的大小如何随着时间的推移而显著增加。这种趋势是由社会日益数字化驱动的。由于我们的活动越来越多地发生在计算机上,我们做什么也越来越多地被记录。由于计算机越来越多地联网在一起,这些记录变得更容易集中管理,并更容易将它们整理成适于机器学习应用的数据集。因为统计估计的主要负担(观察少量数据以在新数据上泛化)已经减轻,“大数据”时代使机器学习更加容易。截至2016年,一个粗略的经验法则是,监督深度学习算法在每类给定约5000个标注样本情况下一般将达到可以接受的性能,当至少有1000万个标注样本的数据集用于训练时,它将达到或超过人类表现。此外,在更小的数据集上获得成功是一个重要的研究领域,为此我们应特别侧重于如何通过无监督或半监督学习充分利用大量的未标注样本。
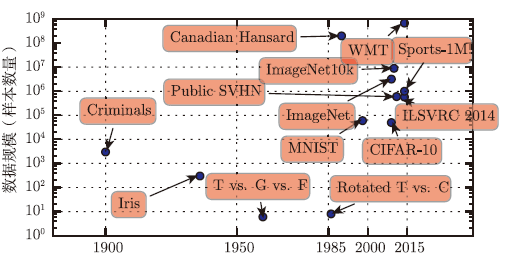
图3 与日俱增的数据量。20世纪初,统计学家使用数百或数千的手动制作的度量来研究数据集(Garson,1900;Gosset,1908;Anderson,1935;Fisher,1936)。20世纪50年代到80年代,受生物启发的机器学习开拓者通常使用小的合成数据集,如低分辨率的字母位图,设计为在低计算成本下表明神经网络能够学习特定功能(Widrow and Hoff,1960;Rumelhart et al.,1986b)。20世纪80年代和90年代,机器学习变得更偏统计,并开始利用包含成千上万个样本的更大数据集,如手写扫描数字的MNIST数据集(如图1.9所示)(Le Cun et al.,1998c)。在21世纪的第一个10年里,相同大小更复杂的数据集持续出现,如CIFAR-10数据集(Krizhevsky and Hinton,2009)。在这10年结束和接下来的5年,明显更大的数据集(包含数万到数千万的样例)完全改变了深度学习可能实现的事。这些数据集包括公共Street View House Numbers数据集(Netzer et al.,2011)、各种版本的Image Net数据集(Deng et al.,2009,2010a;Russakovsky et al.,2014a)以及Sports-1M数据集(Karpathy et al.,2014)。在图顶部,我们看到翻译句子的数据集通常远大于其他数据集,如根据Canadian Hansard制作的IBM数据集(Brown et al.,1990)和WMT2014英法数据集(Schwenk,2014)

图4 MNIST数据集的输入样例。“NIST”代表国家标准和技术研究所(National Institute of Standards and Technology),是最初收集这些数据的机构。“M”代表“修改的(Modified)”,为更容易地与机器学习算法一起使用,数据已经过预处理。MNIST数据集包括手写数字的扫描和相关标签(描述每个图像中包含0~9中哪个数字)。这个简单的分类问题是深度学习研究中最简单和最广泛使用的测试之一。尽管现代技术很容易解决这个问题,它仍然很受欢迎。Geoffrey Hinton将其描述为“机器学习的果蝇”,这意味着机器学习研究人员可以在受控的实验室条件下研究他们的算法,就像生物学家经常研究果蝇一样
与日俱增的模型规模
与日俱增的模型规模
20世纪80年代,神经网络只能取得相对较小的成功,而现在神经网络非常成功的另一个重要原因是我们现在拥有的计算资源可以运行更大的模型。联结主义的主要见解之一是,当动物的许多神经元一起工作时会变得聪明。单独神经元或小集合的神经元不是特别有用。
生物神经元不是特别稠密地连接在一起。如图1.10所示,几十年来,我们的机器学习模型中每个神经元的连接数量已经与哺乳动物的大脑在同一数量级上。
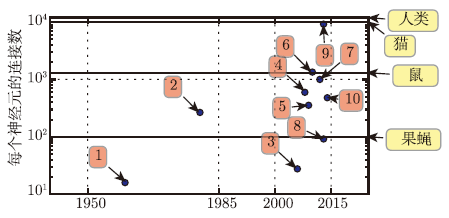
图5 与日俱增的每个神经元的连接数。最初,人工神经网络中神经元之间的连接数受限于硬件能力。而现在,神经元之间的连接数大多是出于设计考虑。一些人工神经网络中每个神经元的连接数与猫一样多,并且对于其他神经网络来说,每个神经元的连接数与较小哺乳动物(如小鼠)一样多,这种情况是非常普遍的。甚至人类大脑每个神经元的连接数也没有过高的数量。生物神经网络规模来自Wikipedia(2015)
1.自适应线性单元(Widrow and Hoff,1960);2.神经认知机(Fukushima,1980);3.GPU-加速卷积网络(Chellapilla et al.,2006);4.深度玻尔兹曼机(Salakhutdinov and Hinton,2009a);5.无监督卷积网络(Jarrett et al.,2009b);6.GPU- 加速多层感知机(Ciresan et al.,2010);7.分布式自编码器(Le et al.,2012);8.Multi-GPU 卷积网络(Krizhevsky et al.,2012a);9.COTSHPC无监督卷积网络(Coates et al.,2013);10.Goog Le Net(Szegedy et al.,2014a)
如图1.11所示,就神经元的总数目而言,直到最近神经网络都是惊人的小。自从隐藏单元引入以来,人工神经网络的规模大约每2.4年扩大一倍。这种增长是由更大内存、更快的计算机和更大的可用数据集驱动的。更大的网络能够在更复杂的任务中实现更高的精度。这种趋势看起来将持续数十年。除非有能力迅速扩展新技术,否则至少要到21世纪50年代,人工神经网络才能具备与人脑相同数量级的神经元。生物神经元表示的功能可能比目前的人工神经元所表示的更复杂,因此生物神经网络可能比图中描绘的甚至要更大。

图6 与日俱增的神经网络规模。自从引入隐藏单元,人工神经网络的规模大约每2.4年翻一倍。生物神经网络规模来自Wikipedia(2015)
1.感知机(Rosenblatt,1958,1962);2.自适应线性单元(Widrow and Hoff,1960);3.神经认知机(Fukushima,1980);4.早期后向传播网络(Rumelhart et al.,1986b);5.用于语音识别的循环神经网络(Robinson and Fallside,1991);6.用于语音识别的多层感知机(Bengio et al.,1991);7.均匀场sigmoid信念网络(Saul et al.,1996);8.Le Net-5(Le Cun et al.,1998c);9.回声状态网络(Jaeger and Haas,2004);10.深度信念网络(Hinton et al.,2006a);11.GPU-加速卷积网络(Chellapilla et al.,2006);12.深度玻尔兹曼机(Salakhutdinov and Hinton,2009a);13.GPU-加速深度信念网络(Raina et al.,2009a);14.无监督卷积网络(Jarrett et al.,2009b);15.GPU-加速多层感知机(Ciresan et al.,2010);16.OMP-1网络(Coates and Ng,2011);17.分布式自编码器(Le et al.,2012);18.Multi-GPU卷积网络(Krizhevsky et al.,2012a);19.COTSHPC无监督卷积网络(Coates et al.,2013);20.Goog Le Net(Szegedy et al.,2014a)
现在看来,神经元数量比一个水蛭还少的神经网络不能解决复杂的人工智能问题,这是不足为奇的。即使现在的网络,从计算系统角度来看它可能相当大,但实际上它比相对原始的脊椎动物(如青蛙)的神经系统还要小。
由于更快的CPU、通用GPU的出现(在第12.1.2节中讨论)、更快的网络连接和更好的分布式计算的软件基础设施,模型规模随着时间的推移不断增加是深度学习历史中最重要的趋势之一。人们普遍预计这种趋势将很好地持续到未来。
与日俱增的精度、复杂度和对现实世界的冲击
与日俱增的精度、复杂度和对现实世界的冲击
20世纪80年代以来,深度学习提供精确识别和预测的能力一直在提高。而且,深度学习持续成功地应用于越来越广泛的实际问题中。
最早的深度模型被用来识别裁剪紧凑且非常小的图像中的单个对象(Rumelhart et al.,1986d)。此后,神经网络可以处理的图像尺寸逐渐增加。现代对象识别网络能处理丰富的高分辨率照片,并且不需要在被识别的对象附近进行裁剪(Krizhevsky et al.,2012b)。类似地,最早的网络只能识别两种对象(或在某些情况下,单类对象的存在与否),而这些现代网络通常能够识别至少1000个不同类别的对象。对象识别中最大的比赛是每年举行的Image Net大型视觉识别挑战(ILSVRC)。深度学习迅速崛起的激动人心的一幕是卷积网络第一次大幅赢得这一挑战,它将最高水准的前5错误率从26.1%降到15.3%(Krizhevsky et al.,2012b),这意味着该卷积网络针对每个图像的可能类别生成一个顺序列表,除了15.3%的测试样本,其他测试样本的正确类标都出现在此列表中的前5项里。此后,深度卷积网络连续地赢得这些比赛,截至写作本书时,深度学习的最新结果将这个比赛中的前5错误率降到了3.6%,如图1.12所示。
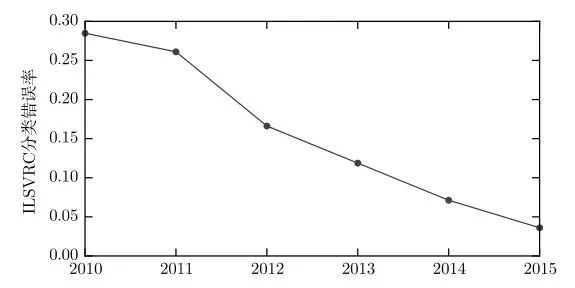
图7 日益降低的错误率。由于深度网络达到了在ImageNet大规模视觉识别挑战中竞争所必需的规模,它们每年都能赢得胜利,并且产生越来越低的错误率。数据来源于Russakovsky et al.(2014b)和He et al.(2015)
深度学习也对语音识别产生了巨大影响。语音识别在20世纪90年代得到提高后,直到约2000年都停滞不前。深度学习的引入(Dahl et al.,2010;Deng et al.,2010b;Seide et al.,2011;Hinton et al.,2012a)使得语音识别错误率陡然下降,有些错误率甚至降低了一半。我们将在第12.3节更详细地探讨这个历史。
深度网络在行人检测和图像分割中也取得了引人注目的成功(Sermanet et al.,2013;Farabet et al.,2013;Couprie et al.,2013),并且在交通标志分类上取得了超越人类的表现(Ciresan et al.,2012)。
在深度网络的规模和精度有所提高的同时,它们可以解决的任务也日益复杂。Goodfellow et al.(2014d)表明,神经网络可以学习输出描述图像的整个字符序列,而不是仅仅识别单个对象。此前,人们普遍认为,这种学习需要对序列中的单个元素进行标注(Gulcehre and Bengio,2013)。循环神经网络,如之前提到的LSTM序列模型,现在用于对序列和其他序列之间的关系进行建模,而不是仅仅固定输入之间的关系。这种序列到序列的学习似乎引领着另一个应用的颠覆性发展,即机器翻译(Sutskever et al.,2014;Bahdanau et al.,2015)。
这种复杂性日益增加的趋势已将其推向逻辑结论,即神经图灵机(Graves et al.,2014)的引入,它能学习读取存储单元和向存储单元写入任意内容。这样的神经网络可以从期望行为的样本中学习简单的程序。例如,从杂乱和排好序的样本中学习对一系列数进行排序。这种自我编程技术正处于起步阶段,但原则上未来可以适用于几乎所有的任务。
深度学习的另一个最大的成就是其在强化学习(reinforcement learning)领域的扩展。在强化学习中,一个自主的智能体必须在没有人类操作者指导的情况下,通过试错来学习执行任务。DeepMind表明,基于深度学习的强化学习系统能够学会玩Atari视频游戏,并在多种任务中可与人类匹敌(Mnih et al.,2015)。深度学习也显著改善了机器人强化学习的性能(Finn et al.,2015)。
许多深度学习应用都是高利润的。现在深度学习被许多顶级的技术公司使用,包括Google、Microsoft、Facebook、IBM、Baidu、Apple、Adobe、Netflix、NVIDIA和NEC等。
深度学习的进步也严重依赖于软件基础架构的进展。软件库如Theano(Bergstra et al.,2010a;Bastien et al.,2012a)、PyLearn2(Goodfellow et al.,2013e)、Torch(Collobert et al.,2011b)、Dist Belief(Dean et al.,2012)、Caffe(Jia,2013)、MXNet(Chen et al.,2015)和Tensor-Flow(Abadi et al.,2015)都能支持重要的研究项目或商业产品。
深度学习也为其他科学做出了贡献。用于对象识别的现代卷积网络为神经科学家们提供了可以研究的视觉处理模型(DiCarlo,2013)。深度学习也为处理海量数据以及在科学领域做出有效的预测提供了非常有用的工具。它已成功地用于预测分子如何相互作用、从而帮助制药公司设计新的药物(Dahl et al.,2014),搜索亚原子粒子(Baldi et al.,2014),以及自动解析用于构建人脑三维图的显微镜图像(Knowles-Barley et al.,2014)等多个场合。我们期待深度学习未来能够出现在越来越多的科学领域中。
总之,深度学习是机器学习的一种方法。在过去几十年的发展中,它大量借鉴了我们关于人脑、统计学和应用数学的知识。近年来,得益于更强大的计算机、更大的数据集和能够训练更深网络的技术,深度学习的普及性和实用性都有了极大的发展。未来几年,深度学习更是充满了进一步提高并应用到新领域的挑战和机遇。

ISBN:9787115461476
定价:168元
★ “花书”《深度学习》AI圣经!
★ 全球知名专家Ian Goodfellow、Yoshua Bengio和Aaron Courville撰写。
★ 美亚人工智能和机器学习领域排名第一的经典畅销书。
★ 深度学习领域奠基性的图书产品!
★ 全彩印刷。
内容简介
《深度学习》由全球知名的三位专家Ian Goodfellow、Yoshua Bengio 和Aaron Courville撰写,是深度学习领域奠基性的经典教材。全书的内容包括 3 个部分:第 1 部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第 2 部分系统深入地讲解现今已成熟的深度学习方法和技术;第 3 部分讨论某些具有前瞻性的方向和想法,它们被公认为是深度学习未来的研究重点。
喜欢这本书吗?
CSDN联合异步图书,
针对CSDN用户推出
限时7.5折包邮的优惠价。
扫描下方二维码就可购买哦!

点击阅读原文,也可秒购《深度学习》↓↓↓