LeCun推荐:最新PyTorch图神经网络库,速度快15倍(GitHub+论文)

新智元报道
来源:GitHub、arXiv
编辑:肖琴
【新智元导读】德国研究者提出最新几何深度学习扩展库 PyTorch Geometric (PyG),具有快速、易用的优势,使得实现图神经网络变得非常容易。作者开源了他们的方法,并提供教程和实例。
过去十年来,深度学习方法(例如卷积神经网络和递归神经网络)在许多领域取得了前所未有的成就,例如计算机视觉和语音识别。
研究者主要将深度学习方法应用于欧氏结构数据 (Euclidean domains),但在许多重要的应用领域,如生物学、物理学、网络科学、推荐系统和计算机图形学,可能不得不处理非欧式结构的数据,比如图和流形。
直到最近,深度学习在这些特定领域的采用一直很滞后,主要是因为数据的非欧氏结构性质使得基本操作(例如卷积)的定义相当困难。在这个意义上,几何深度学习将深度学习技术扩展到了图/流形结构数据。
图神经网络 (GNN)是近年发展起来的一个很有前景的深度学习方向,也是一种强大的图、点云和流形表示学习方法。
然而,实现 GNN 具有挑战性,因为需要在高度稀疏且不规则、不同大小的数据上实现高 GPU 吞吐量。
近日,德国多特蒙德工业大学的研究者两位 Matthias Fey 和 Jan E. Lenssen,提出了一个基于 PyTorch 的几何深度学习扩展库 PyTorch Geometric (PyG),为 GNN 的研究和应用再添利器。

论文:
https://arxiv.org/pdf/1903.02428.pdf
Yann Lecun 也热情推荐了这个工作,称赞它是一个快速、美观的 PyTorch 库,用于几何深度学习 (图和其他不规则结构的神经网络)。
作者声称,PyG 甚至比几个月前 NYU、AWS 联合开发的图神经网络库 DGL(Deep Graph Library) 快了 15 倍!
作者在论文中写道:“这是一个 PyTorch 的几何深度学习扩展库,它利用专用的 CUDA 内核实现了高性能。它遵循一个简单的消息传递 API,将最近提出的大多数卷积和池化层捆绑到一个统一的框架中。所有实现的方法都支持 CPU 和 GPU 计算,并遵循一个不可变的数据流范式,该范式支持图结构随时间的动态变化。”
PyG 已经在 MIT 许可下发布,可以在 GitHub 上获取。里面有完整的文档说明,并提供了作为起点的教程和示例。
地址:
https://github.com/rusty1s/pytorch_geometric

PyTorch Geometry 是一个基于 PyTorch 的几何深度学习扩展库,用于不规则结构输入数据,例如图 (graphs)、点云 (point clouds) 和流形 (manifolds)。
PyTorch Geometry 包含了各种针对图形和其他不规则结构的深度学习方法,也称为几何深度学习,来自于许多已发表的论文。
此外,它还包含一个易于使用的 mini-batch 加载器、多 GPU 支持、大量通用基准数据集和有用的转换,既可以学习任意图形,也可以学习 3D 网格或点云。
在 PyG 中 , 我们用一个节点特征矩阵

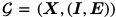
其中


所有面向用户的 API,据加载例程、多 GPU 支持、数据增强或模型实例化都很大程度上受到 PyTorch 的启发,以便使它们尽可能保持熟悉。
Neighborhood Aggregation:将卷积算子推广到不规则域通常表示为一个邻域聚合(neighborhood aggregation),或 message passing scheme (Gilmer et al., 2017)。
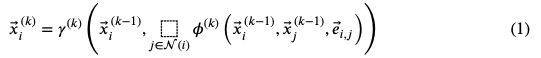
其中,


在实践中,这可以通过收集和散布节点特性并利用 broadcasting 进行

图 1
几乎所有最近提出的邻域聚合函数可以利用这个接口,已经集成到 PyG 的方法包括 (但不限于):
对于任意图形学习,我们已经实现了:
GCN (Kipf & Welling, 2017) 和它的简化版本 SGC (Wu et al., 2019)
spectral chebyshev 和 ARMA filter convolutionss (Defferrard et al., 2016; Bianchi et al., 2019)
GraphSAGE (Hamilton et al., 2017)
attention-based operators GAT (Veličković et al., 2018) 及 AGNN (Thekumparampil et al., 2018),
Graph Isomorphism Network (GIN) from Xu et al. (2019)
Approximate Personalized Propagation of Neural Predictions (APPNP) operator (Klicpera et al., 2019)
对于学习具有多维边缘特征的点云,流形和图,我们提供了:
Schlichtkrull et al. (2018) 的 relational GCN operator
PointNet++ (Qi et al., 2017)
PointCNN (Li et al., 2018)
kernel-based methods MPNN (Gilmer et al., 2017),
MoNet (Monti et al., 2017)
SplineCNN (Fey et al., 2018)
以及边缘卷积算子 EdgeCNN (Wang et al., 2018b).
我们通过对同类评估场景进行综合比较研究,评估了利用 PyG 所实现方法的正确性。所有使用过的数据集的描述和统计可以在论文附录中找到。
对于所有的实验,我们都尽可能地遵循各自原始论文的超参数设置,GitHub 存储库中提供了复制所有实验的代码。
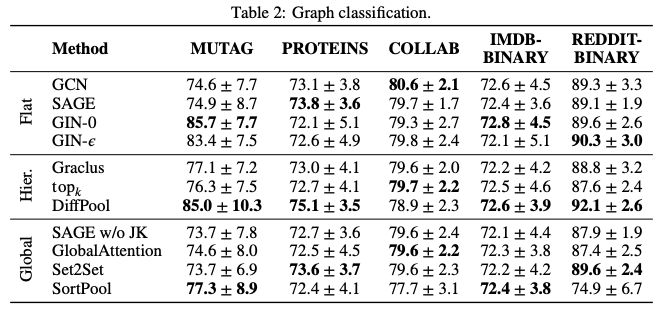
表 2:图分类的结果
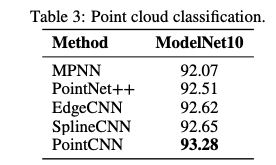
表 3:点云分类的结果
我们对多个数据模型对进行了多次实验,并报告了在单个 NVIDIA GTX 1080 Ti 上获得的整个训练过程的运行情况 (表 4)。与 Deep Graph Library (DGL)(Wang et al., 2018a) 相比,PyG 训练模型的速度快了 15 倍。
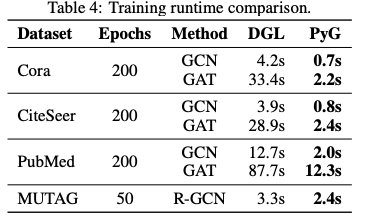
表 4:训练 runtime 比较
PyTorch Geometric 使实现图卷积网络变得非常容易 (请参阅 GitHub 上的教程)。
例如,这就是实现一个边缘卷积层 (edge convolution layer) 所需的全部代码:
import torchfrom torch.nn import Sequential as Seq, Linear as Lin, ReLUfrom torch_geometric.nn import MessagePassingclass EdgeConv(MessagePassing):def __init__(self, F_in, F_out):super(EdgeConv, self).__init__()self.mlp = Seq(Lin(2 * F_in, F_out), ReLU(), Lin(F_out, F_out))def forward(self, x, edge_index):# x has shape [N, F_in]# edge_index has shape [2, E]return self.propagate(aggr='max', edge_index=edge_index, x=x) # shape [N, F_out]def message(self, x_i, x_j):# x_i has shape [E, F_in]# x_j has shape [E, F_in]edge_features = torch.cat([x_i, x_j - x_i], dim=1) # shape [E, 2 * F_in]return self.mlp(edge_features) # shape [E, F_out]
此外,与其他深度图神经网络库相比,PyTorch Geometric 的速度更快:
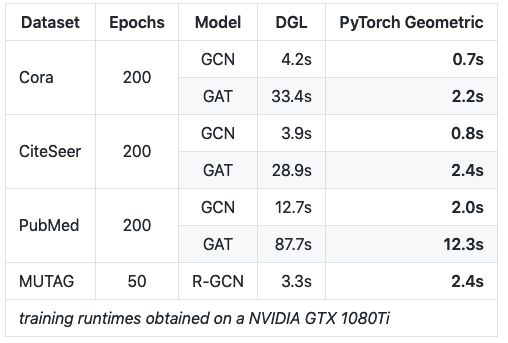
表:在一块 NVIDIA GTX 1080Ti 上的训练 runtime
安装
确保至少安装了 PyTorch 1.0.0,并验证 cuda/bin 和 cuda/include 分别位于 $PATH 和 $cpathrespecific,例如:
$ python -c "import torch; print(torch.__version__)"> 1.0.0$ echo $PATH> /usr/local/cuda/bin:...$ echo $CPATH> /usr/local/cuda/include:...
然后运行:
$ pip install --upgrade torch-scatter$ pip install --upgrade torch-sparse$ pip install --upgrade torch-cluster$ pip install --upgrade torch-spline-conv (optional)$ pip install torch-geometric
运行示例
cd examplespython cora.py
paper:
https://arxiv.org/pdf/1903.02428.pdf
GitHub:
https://github.com/rusty1s/pytorch_geometric
更多阅读
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)





