【机器学习】一文读完GitHub30+篇顶级机器学习论文
新智元编译
作者:常佩琦 弗格森
【新智元导读】 今天介绍Github上的开源项目,专门用于更新最新的研究突破,具体说来,就是什么算法在哪一个数据集上取得了state-of-the-art 的成果,包括语音、计算机视觉和NLP、迁移学习、强化学习。在这里,你可以读懂2017机器学习领域究竟在哪些方向上取得了突破,各大前沿机构和学术大牛们在哪些方向上发力。比如,Hinton掀起深度学习革命的Capsule 网络、再到谷歌的“一个模型学习所有”“Attention is all you need”以及Facebook在机器翻译上的屡次突破,以及让大家兴奋的AlphaGo Zero等等。
学术领域,最新的机器学习技术都做到了什么水平?Github上有一个开源项目,专门用于更新最新的研究突破,具体说来,就是什么算法在哪一个数据集上取得了state-of-the-art 的成果。大类包括:监督学习、半监督学习和无监督学习、迁移学习、强化学习,小类包括语音、计算机视觉和NLP。
这一份列表几乎囊括了2017年机器学习领域所有最重大的突破,从微软对话语音识别错误率将至5.1%、到Hinton掀起深度学习革命的Capsule 网络、再到谷歌的“一个模型学习所有”“Attention is all you need”以及Facebook在机器翻译上的屡次突破,以及让大家兴奋的AlphaGo Zero。
这不仅仅是一份论文和代码资源的列表,更是2017年机器学习和人工智能里程碑的表单,在这里,你可以读懂2017机器学习领域究竟在哪些方向上取得了突破,各大前沿机构和学术大牛们在哪些方向上发力。
作者说:“本库为所有机器学习问题提供了当前最优结果,并尽最大努力使库保持随时更新状态”,我们也同样期待这一列表不断更新,出现更多让人拍案叫绝的最新研究成果,将人工智能不断往前推进。
最新更新时间:2017年11月17日
本库的分类如下:
监督学习
1. Speech
2. 计算机视觉
3. NLP
半监督学习:计算机视觉
无监督学习
1. Speech
2. 计算机视觉
3. NLP
迁移学习
强化学习
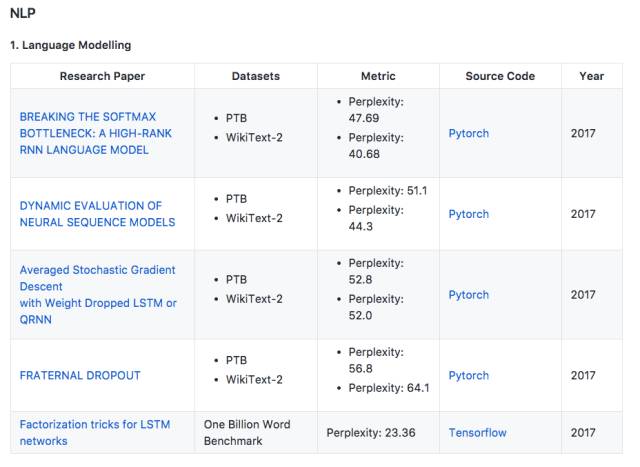
NLP
1. 语言建模
论文:BREAKING THE SOFTMAX BOTTLENECK: A HIGH-RANK RNN LANGUAGE MODEL
地址:https://arxiv.org/pdf/1711.03953.pdf
本文将语言建模作为一个矩阵分解问题,并表明基于Softmax的模型(包括大多数神经语言模型)的表达受到Softmax瓶颈的限制。 鉴于自然语言高度依赖于上下文,这意味着在实践中Softmax与分布式词嵌入没有足够的能力来建模自然语言。 本文提出了一个简单有效的解决方法,并且将Penn Treebank和WikiText-2中的perplexities分别提高到47.69和40.68。
论文:DYNAMIC EVALUATION OF NEURAL SEQUENCE MODELS
地址:https://arxiv.org/pdf/1709.07432.pdf
本文提出使用动态评估来改进神经序列模型的性能。 模型通过基于梯度下降的机制适应最近的历史,将以更高概率分配给重新出现的连续模式。动态评估将Penn Treebank和WikiText-2数据集上的perplexities分别提高到51.1和44.3。
论文:Averaged Stochastic Gradient Descent with Weight Dropped LSTM or QRNN
地址:https://arxiv.org/pdf/1708.02182.pdf
提出了使用DropConnect作为经常正则化形式的权重下降的LSTM。此外,本文引入NT-ASGD,平均随机梯度方法的变体,其中平均触发是使用非单调条件确定的,而不是由用户调整。使用这些和其他正则化策略,本文在两个数据集上实现了state-of-the-art word level perplexities:Penn Treebank上的57.3和WikiText-2上的65.8。在结合我们提出的模型探索神经缓存的有效性时,在Penn Treebank上实现了更低的52.8的state-of-the-art word level perplexities,而在WikiText-2上达到了52.0。
论文:FRATERNAL DROPOUT
地址:https://arxiv.org/pdf/1711.00066.pdf
提出一个叫做fraternal dropout的技术。首先用不同的dropout mask训练两个同样的RNN,并最小化预测差异。本文评估了提出的模型,并在Penn Treebank和Wikitext-2上达到了当前最优结果。
论文:Factorization tricks for LSTM networks
地址:https://arxiv.org/pdf/1703.10722.pdf
提出了两个带映射的LSTM修正单元,来减少参数数量和加快训练速度。
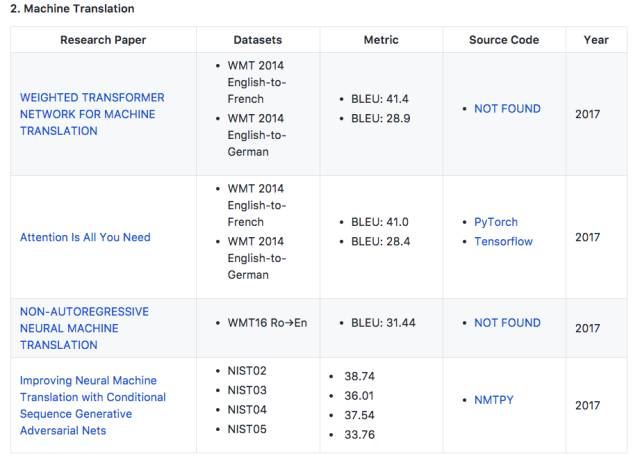
2. 机器翻译
论文:WEIGHTED TRANSFORMER NETWORK FOR MACHINE TRANSLATION
地址:https://arxiv.org/pdf/1711.02132.pdf
在WMT 2014英德翻译任务和英法翻译任务中,模型的性能分别提高了0.5 BLEU points和0.4。
论文:Attention Is All You Need
地址:https://arxiv.org/abs/1706.03762
在WMT 2014英德翻译任务和英法翻译任务中,模型的性能分别提高到28.4 BLEU points和41.0 BLEU points。
论文:NON-AUTOREGRESSIVE NEURAL MACHINE TRANSLATION
地址:https://einstein.ai/static/images/pages/research/non-autoregressive-neural-mt.pdf
论文:Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets
地址:https://arxiv.org/abs/1703.04887
3. 文本分类
论文:Learning Structured Text Representations
地址:https://arxiv.org/abs/1705.09207
提出了学习结构化的文本表征,关注在没有语篇分析和额外标注资源下学习结构化的文本表征。在Yelp数据集的准确率达到68.6。
论文:Attentive Convolution
地址:https://arxiv.org/pdf/1710.00519.pdf
本文提出了AttentiveConvNet,通过卷积操作,拓展文本处理的范围。从本地上下文和非本地上下文提取出的信息来得到单词更高级别的特征。在Yelp数据集的准确率达到67.36。
4. 自然语言推理
论文:NATURAL LANGUAGE INFERENCE OVER INTERACTION SPACE
地址:https://arxiv.org/pdf/1709.04348.pdf
介绍了交互式推理网络(IIN),这是一种新型的神经网络架构,能够实现对句子的高层次的理解。我们证明了一个交互张量包含了语义信息以解决自然语言推理。准确率达88.9。
5. 问题回答
论文:Interactive AoA Reader+ (ensemble)
地址:https://rajpurkar.github.io/SQuAD-explorer/
斯坦福问答数据集(SQuAD)是一个新兴阅读理解数据集,其问答基于维基百科,由众包方式完成。
6. 命名实体识别
论文:Named Entity Recognition in Twitter using Images and Text
地址:https://arxiv.org/pdf/1710.11027.pdf
论文提出了一种新型的多层级架构,该架构并不依赖于具体语言学的资源和解码规则。模型在Ritter数据集上F-measure的表现为0.59。
7. 依存关系句法分析
论文:Globally Normalized Transition-Based Neural Networks
地址:https://arxiv.org/pdf/1603.06042.pdf
本文提出了以全球标准化的基于转换的神经网络模型,实现了语音标记、依存关系句法分析和句子压缩的当前最优结果。UAS准确度为94.08%,LAS准确度为92.15%。
计算机视觉
分类
论文:Dynamic Routing Between Capsules
地址:https://arxiv.org/pdf/1710.09829.pdf
Capsule 是一组神经元,其输入输出向量表示特定实体类型的实例化参数我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的 capsule 通过变换矩阵对更高级别的 capsule 的实例化参数进行预测。
论文:High-Performance Neural Networks for Visual Object Classification
地址:https://arxiv.org/pdf/1102.0183.pdf
摘要:论文中提出了一种卷积神经网络变体的快速全可参数化的 GPU 实现。在 NORB 数据集上效果不错,测试误差在2.53 ± 0.40。
论文:ShakeDrop regularization
地址:https://openreview.net/pdf?id=S1NHaMW0b
论文:Aggregated Residual Transformations for Deep Neural Networks
地址:https://arxiv.org/pdf/1611.05431.pdf
论文:Random Erasing Data Augmentation
地址:https://arxiv.org/abs/1708.04896
论文:Learning Transferable Architectures for Scalable Image Recognition
地址:https://arxiv.org/pdf/1707.07012.pdf
论文:Squeeze-and-Excitation Networks
地址:https://arxiv.org/pdf/1709.01507.pdf
论文:Aggregated Residual Transformations for Deep Neural Networks
地址:https://arxiv.org/pdf/1611.05431.pdf
2. 实例分割
论文:Mask R-CNN
地址:https://arxiv.org/pdf/1703.06870.pdf
论文提出一个概念上简单灵活通用的物体分割框架。这种叫做Mask R-CNN的方法,拓展了Faster RNN。在COCO数据集上的平均精准度达到37.1%。
3. 视觉问题回答
论文:Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
地址:https://arxiv.org/abs/1708.02711
提出了视觉问答的最新模型,在2017VOA挑战中获得冠军。整体分数达到69。
语音
ASR (语音识别)
论文:微软2017年发布的对话语音识别系统
数据集: Switchboard Hub5'00
错误率:5.1%
论文地址:https://arxiv.org/pdf/1708.06073.pdf
微软在官方的介绍是:改进语音模型引入了 CNN-BLSTM(convolutional neural network combined with bidirectional long-short-term memory)。另外,在 frame/senone 和词语层面都使用了结合多个声学模型的预测的方法。 通过使用整个对话过程来加强识别器的语言模型,以预测接下来可能发生的事情,使得模型有效地适应了对话的话题和语境。
论文:使用虚拟对抗训练实现分布式顺滑 (2016年)
数据集:SVHN NORB
错误率:24.63(SVHN )9.88 (NORB)
论文地址:https://arxiv.org/pdf/1507.00677.pdf
作者提出了一个局部分布顺滑的概念,作为一个正则化的项目,来提升模型分布的顺滑。
论文: 虚拟对抗训练: 一个面向监督和半监督的正则化方法 (2017年)
数据集:MNIST
错误率:1.27
论文地址:https://arxiv.org/pdf/1704.03976.pdf
论文: 用GAN生成非标签样本 (2017年)
数据集&准确率:
Market-1501 (Rank-1: 83.97 mAP: 66.07)
CUHK-03 (Rank-1: 84.6 mAP: 87.4)
DukeMTMC-reID( Rank-1: 67.68 mAP: 47.13)
CUB-200-2011(Test Accuracy: 84.4)
论文地址: https://arxiv.org/pdf/1701.07717.pdf
计算机视觉 :生成模型
论文:PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION (2017年)
数据集: Unsupervised CIFAR 10
得分:8.80
论文地址:https://arxiv.org/pdf/1704.03976.pdf
Progressive Growing of GANs for Improved Quality, Stability, and Variation”。其中“Progressive Growing”指的是先训练4x4的网络,然后训练8x8,不断增大,最终达到1024x1024。作者使用的数据集以CelebA为基础,还进行了额外的处理,包括超分辨率、模糊背景、对齐。
机器翻译
论文: 无监督机器翻译:是使用单语语料(2017年)
数据集:WMT16 (en-fr fr-en de-en en-de) ;Multi30k-Task1(en-fr fr-en de-en en-de)
得分: BLEU:(32.76 32.07 26.26 22.74);BLEU:(15.05 14.31 13.33 9.64)
论文地址 :https://arxiv.org/pdf/1711.00043.pdf
作者提出了一种新的神经机器翻译方法,其中翻译模型仅使用单语言数据集学习,句子或文档之间没有任何对齐。这个方法的原理是从一个简单的无监督逐字翻译模型开始,并基于重构损失迭代地改进这个模型,并且使用鉴别器来对齐源语言和目标语言的潜在分布。
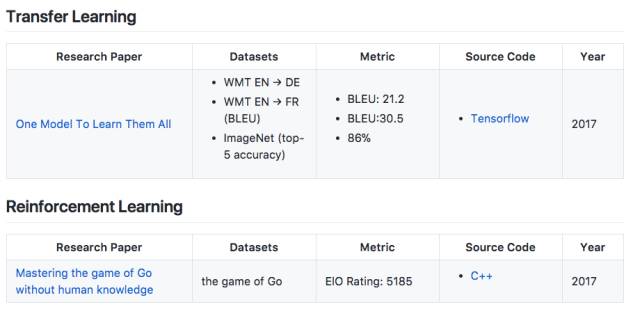
论文:一个模型学习一切(2017年)
数据集:WMT EN → DE ;WMT EN → FR (BLEU);ImageNet (top-5 accuracy)
得分&准确率:BLEU: 21.2;BLEU:30.5;86%
论文地址 : https://arxiv.org/pdf/1706.05137.pdf
作者提出了一个多模型适用的架构 MultiModel,用单一的一个深度学习模型,学会各个不同领域的多种不同任务。
论文:无需人类知识掌握围棋
数据集:the game of Go
ElO Rating: 5185
代码:https://github.com/gcp/leela-zero
论文地址 :http://www.gwern.net/docs/rl/2017-silver.pdf
迄今最强最新的版本AlphaGo Zero,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo
作者的说明:本库为所有机器学习问题提供了当前最优结果,并尽最大努力使库保持随时更新状态。 如果用户发现某个问题的当前最优结果结果已过时或缺失,请提出此问题,并附带以下信息:研究论文名称、数据集、度量标准,源代码和年份)。 我们会立即解决。
我们试图让所有类型的机器学习问题有最新结果。 我无法单独做这件事,因此需要大家的帮助。 如果读者发现数据集的当前最优结果,请提交Google表单或提出问题。 请在Twitter,Facebook和其他社交媒体上分享。
原文链接:https://github.com/RedditSota/state-of-the-art-result-for-machine-learning-problems
一篇关于机器学习理解的文章
来源作者:李航博士
算算时间,从开始到现在,做机器学习算法也将近八个月了。虽然还没有达到融会贯通的地步,但至少在熟悉了算法的流程后,我在算法的选择和创造能力上有了不小的提升。实话说,机器学习很难,非常难,要做到完全了解算法的流程、特点、实现方法,并在正确的数据面前选择正确的方法再进行优化得到最优效果,我觉得没有个八年十年的刻苦钻研是不可能的事情。其实整个人工智能范畴都属于科研难题,包括模式识别、机器学习、搜索、规划等问题,都是可以作为独立科目存在的。我不认为有谁可以把人工智能的各个方面都做到极致,但如果能掌握其中的任一方向,至少在目前的类人尖端领域,都是不小的成就。
这篇日志,作为我2014年的学业总结,详细阐述目前我对机器学习的理解,希望各位看官批评指正,多多交流!
机器学习(Machine Learning),在我看来就是让机器学习人思维的过程。机器学习的宗旨就是让机器学会“人识别事物的方法”,我们希望人从事物中了解到的东西和机器从事物中了解到的东西一样,这就是机器学习的过程。在机器学习中有一个很经典的问题:
“假设有一张色彩丰富的油画,画中画了一片茂密的森林,在森林远处的一棵歪脖树上,有一只猴子坐在树上吃东西。如果我们让一个人找出猴子的位置,正常情况下不到一秒钟就可以指出猴子,甚至有的人第一眼就能看到那只猴子。”
那么问题就来了,为什么人能在上千种颜色混合而成的图像中一下就能识别出猴子呢?在我们的生活中,各种事物随处可见,我们是如何识别出各种不同的内容呢?也许你可能想到了——经验。没错,就是经验。经验理论告诉我们认识的所有东西都是通过学习得到的。比如,提起猴子,我们脑海里立刻就会浮现出我们见过的各种猴子,只要画中的猴子的特征与我们意识中的猴子雷同,我们就可能会认定画中画的是猴子。极端情况下,当画中猴子的特征与我们所认识某一类猴子的特征完全相同,我们就会认定画中的猴子是哪一类。
另一种情况是我们认错的时候。其实人识别事物的错误率有的时候也是很高的。比如,当我们遇见不认识的字的时候会潜意识的念字中我们认识的部分。比如,“如火如荼”这个词,是不是有朋友也跟我一样曾经念过“如火如茶(chá)”?我们之所以犯错,就是因为在我们没有见过这个字的前提下,我们会潜意识的使用经验来解释未知。
目前科技如此发达,就有牛人考虑可不可以让机器模仿人的这种识别方法来达到机器识别的效果,机器学习也就应运而生了。
从根本上说,识别,是一个分类的结果。看到四条腿的生物,我们可能会立即把该生物归为动物一类,因为我们常常见到的四条腿的、活的东西,九成以上是动物。这里,就牵扯出了概率的问题。我们对身边的事物往往识别率很高,是因为人的潜意识几乎记录了肉眼看到的事物的所有特征。比如,我们进入一个新的集体,刚开始大家都不认识,有的时候人和名字都对不上号,主要原因就是我们对事物的特征把握不够,还不能通过现有特征对身边的人进行分类。这个时候,我们常常会有这种意识:哎,你好像叫张三来着?哦,不对,你好像是李四。这就是分类中的概率问题,有可能是A结果,有可能是B结果,甚至是更多结果,主要原因就是我们的大脑收集的特征不够多,还无法进行准确分类。当大家都彼此熟悉了之后,一眼就能识别出谁是谁来,甚至极端情况下,只听声音不见人都能进行识别,这说明我们已经对该事物的特征把握相当精确。
所以,我认为,人识别事物有四个基本步骤:学习、提取特征、识别、分类。
那么机器可不可以模仿这个过程来实现识别呢?
答案是肯定的,但是没有那么容易。难题有三:
第一,人的大脑有无数神经元进行数据交换和处理,在目前的机器中还达不到同等的处理条件;
第二,人对事物特征的提取是潜意识的,提取无意识情况下的信息,误差很大;
第三,也是最重要的一点,人的经验来自于人每时每刻的生活中,也就是人无时无刻都处在学习中,如何让机器进行各个方面的自主学习?
因此,目前在人工智能领域始终还没达到类人的水平,我认为主要原因就是机器没有潜意识。人的潜意识其实并不完全受人的意识支配,但却可以提高人类识别事物的概率。我们无法给机器加载潜意识,因为主动加载的意识就是主观意识,在机器里无法完成人类潜意识的功能。所以,以目前的发展情况来看,要达到完全类人,还有不短的时间。但即便如此,与人的思维差别很大的机器依然可以为我们的生活带来帮助。比如,我们常用的在线翻译、搜索系统、专家系统等,都是机器学习的产物。
那么,如何实现机器学习呢?
整体上看,机器学习就是模仿人识别事物的过程,即:学习、提取特征、识别、分类。
由于机器不能跟人类思维一样根据事物特征自然而然的选择分类方法,所以机器学习方法的选择依然还需要人工选择。
目前,机器学习的方法主要有三种:监督学习、半监督学习和无监督学习。
监督学习是利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。白话一点,就是根据已知的,推断未知的。
代表方法有:Nave Bayes、SVM、决策树、KNN、神经网络以及Logistic分析等;
半监督方法主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,也就是根据少量已知的和大量未知的内容进行分类。代表方法有:最大期望、生成模型和图算法等。
无监督学习是利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。也就是及其自个儿学。
代表方法有:Apriori、FP树、K-means以及目前比较火的Deep Learning。
从这三方面看,无监督学习是最智能的,有能实现机器主动意识的潜质,但发展还比较缓慢;监督学习是不太靠谱的,从已知的推断未知的,就必须要把事物所有可能性全都学到,这在现实中是不可能的,人也做不到;半监督学习是“没办法中的办法”,既然无监督学习很难,监督学习不靠谱,就取个折中,各取所长。目前的发展是,监督学习技术已然成熟,无监督学习还在起步,所以对监督学习方法进行修改实现半监督学习是目前的主流。但这些方法基本只能提取信息,还不能进行有效的预测(人们就想,既然没法得到更多,就先看看手里有什么,于是数据挖掘出现了)。
机器学习方法非常多,也很成熟。下面我挑几个说。
首先是SVM。因为我做的文本处理比较多,所以比较熟悉SVM。SVM也叫支持向量机,其把数据映射到多维空间中以点的形式存在,然后找到能够分类的最优超平面,最后根据这个平面来分类。SVM能对训练集之外的数据做很好的预测、泛化错误率低、计算开销小、结果易解释,但其对参数调节和核函数的参数过于敏感。个人感觉SVM是二分类的最好的方法,但也仅限于二分类。如果要使用SVM进行多分类,也是在向量空间中实现多次二分类。
SVM有一个核心函数SMO,也就是序列最小最优化算法。SMO基本是最快的二次规划优化算法,其核心就是找到最优参数α,计算超平面后进行分类。SMO方法可以将大优化问题分解为多个小优化问题求解,大大简化求解过程。
SVM还有一个重要函数是核函数。核函数的主要作用是将数据从低位空间映射到高维空间。详细的内容我就不说了,因为内容实在太多了。总之,核函数可以很好的解决数据的非线性问题,而无需考虑映射过程。
第二个是KNN。KNN将测试集的数据特征与训练集的数据进行特征比较,然后算法提取样本集中特征最近邻数据的分类标签,即KNN算法采用测量不同特征值之间的距离的方法进行分类。KNN的思路很简单,就是计算测试数据与类别中心的距离。KNN具有精度高、对异常值不敏感、无数据输入假定、简单有效的特点,但其缺点也很明显,计算复杂度太高。要分类一个数据,却要计算所有数据,这在大数据的环境下是很可怕的事情。而且,当类别存在范围重叠时,KNN分类的精度也不太高。所以,KNN比较适合小量数据且精度要求不高的数据。
KNN有两个影响分类结果较大的函数,一个是数据归一化,一个是距离计算。如果数据不进行归一化,当多个特征的值域差别很大的时候,最终结果就会受到较大影响;第二个是距离计算。这应该算是KNN的核心了。目前用的最多的距离计算公式是欧几里得距离,也就是我们常用的向量距离计算方法。
个人感觉,KNN最大的作用是可以随时间序列计算,即样本不能一次性获取只能随着时间一个一个得到的时候,KNN能发挥它的价值。至于其他的特点,它能做的,很多方法都能做;其他能做的它却做不了。
第三个就是Naive Bayes了。Naive Bayes简称NB(牛X),为啥它牛X呢,因为它是基于Bayes概率的一种分类方法。贝叶斯方法可以追溯到几百年前,具有深厚的概率学基础,可信度非常高。Naive Baye中文名叫朴素贝叶斯,为啥叫“朴素”呢?因为其基于一个给定假设:给定目标值时属性之间相互条件独立。比如我说“我喜欢你”,该假设就会假定“我”、“喜欢”、“你”三者之间毫无关联。仔细想想,这几乎是不可能的。马克思告诉我们:事物之间是有联系的。同一个事物的属性之间就更有联系了。所以,单纯的使用NB算法效率并不高,大都是对该方法进行了一定的改进,以便适应数据的需求。
NB算法在文本分类中用的非常多,因为文本类别主要取决于关键词,基于词频的文本分类正中NB的下怀。但由于前面提到的假设,该方法对中文的分类效果不好,因为中文顾左右而言他的情况太多,但对直来直去的老美的语言,效果良好。至于核心算法嘛,主要思想全在贝叶斯里面了,没啥可说的。
第四个是回归。回归有很多,Logistic回归啊、岭回归啊什么的,根据不同的需求可以分出很多种。这里我主要说说Logistic回归。为啥呢?因为Logistic回归主要是用来分类的,而非预测。回归就是将一些数据点用一条直线对这些点进行拟合。而Logistic回归是指根据现有数据对分类边界线建立回归公式,以此进行分类。该方法计算代价不高,易于理解和实现,而且大部分时间用于训练,训练完成后分类很快;但它容易欠拟合,分类精度也不高。主要原因就是Logistic主要是线性拟合,但现实中很多事物都不满足线性的。即便有二次拟合、三次拟合等曲线拟合,也只能满足小部分数据,而无法适应绝大多数数据,所以回归方法本身就具有局限性。但为什么还要在这里提出来呢?因为回归方法虽然大多数都不合适,但一旦合适,效果就非常好。
Logistic回归其实是基于一种曲线的,“线”这种连续的表示方法有一个很大的问题,就是在表示跳变数据时会产生“阶跃”的现象,说白了就是很难表示数据的突然转折。所以用Logistic回归必须使用一个称为“海维塞德阶跃函数”的Sigmoid函数来表示跳变。通过Sigmoid就可以得到分类的结果。
为了优化Logistic回归参数,需要使用一种“梯度上升法”的优化方法。该方法的核心是,只要沿着函数的梯度方向搜寻,就可以找到函数的最佳参数。但该方法在每次更新回归系数时都需要遍历整个数据集,对于大数据效果还不理想。所以还需要一个“随机梯度上升算法”对其进行改进。该方法一次仅用一个样本点来更新回归系数,所以效率要高得多。
第五个是决策树。据我了解,决策树是最简单,也是曾经最常用的分类方法了。决策树基于树理论实现数据分类,个人感觉就是数据结构中的B+树。决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。决策树计算复杂度不高、输出结果易于理解、对中间值缺失不敏感、可以处理不相关特征数据。其比KNN好的是可以了解数据的内在含义。但其缺点是容易产生过度匹配的问题,且构建很耗时。决策树还有一个问题就是,如果不绘制树结构,分类细节很难明白。所以,生成决策树,然后再绘制决策树,最后再分类,才能更好的了解数据的分类过程。
决策树的核心树的分裂。到底该选择什么来决定树的分叉是决策树构建的基础。最好的方法是利用信息熵实现。熵这个概念很头疼,很容易让人迷糊,简单来说就是信息的复杂程度。信息越多,熵越高。所以决策树的核心是通过计算信息熵划分数据集。
我还得说一个比较特殊的分类方法:AdaBoost。AdaBoost是boosting算法的代表分类器。boosting基于元算法(集成算法)。即考虑其他方法的结果作为参考意见,也就是对其他算法进行组合的一种方式。说白了,就是在一个数据集上的随机数据使用一个分类训练多次,每次对分类正确的数据赋权值较小,同时增大分类错误的数据的权重,如此反复迭代,直到达到所需的要求。AdaBoost泛化错误率低、易编码、可以应用在大部分分类器上、无参数调整,但对离群点敏感。该方法其实并不是一个独立的方法,而是必须基于元方法进行效率提升。个人认为,所谓的“AdaBoost是最好的分类方法”这句话是错误的,应该是“AdaBoost是比较好的优化方法”才对。
好了,说了这么多了,我有点晕了,还有一些方法过几天再写。总的来说,机器学习方法是利用现有数据作为经验让机器学习,以便指导以后再次碰到的决策。目前来说,对于大数据分类,还是要借助分布式处理技术和云技术才有可能完成,但一旦训练成功,分类的效率还是很可观的,这就好比人年龄越大看待问题越精准的道理是一样的。这八个月里,从最初的理解到一步步实现;从需求的逻辑推断到实现的方法选择,每天都是辛苦的,但每天也都是紧张刺激的。我每天都在想学了这个以后可以实现什么样的分类,其实想想都是让人兴奋的。当初,我逃避做程序员,主要原因就是我不喜欢做已经知道结果的事情,因为那样的工作没有什么期盼感;而现在,我可以利用数据分析得到我想象不到的事情,这不仅满足了我的好奇感,也让我能在工作中乐在其中。也许,我距离社会的技术需求还有很远的距离,但我对自己充满信心,因为,我不感到枯燥,不感到彷徨,虽然有些力不从心,但态度坚定。
2014的学习很艰难,我挺过来了;2015年,可能会更艰难,但我更加期待!
最后,希望各位能人、牛人、同道中人给予点评,多多交流,一个人做算法是吃力的,希望各位踊跃评价,共同进步!


人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



