Hey Siri,帮我把这个boss打一下:基于音频的游戏代理探索 | 一周AI最火论文

大数据文摘专栏作品
作者:Christopher Dossman
编译:笪洁琼、fuma、云舟
呜啦啦啦啦啦啦啦大家好,本周的AIScholar Weekly栏目又和大家见面啦!
AI ScholarWeekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
每周更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:音频生成模型、端到端的音视频语音识别、张量计算
本周热门学术研究
地表最强语音活动检测(rVAD)
为了开发用于语音活动检测的强大算法,研究人员设计了rVAD。新方法先使用了两个去噪通道,然后再添加语音活动检测(VAD)算法。
第一遍检测涉及语音信号中的高能段,其通过使用后验信噪比(SNR)加权能量差来检测。如果在段内没有检测到音调,则将其视为高能噪声段并设置为零。
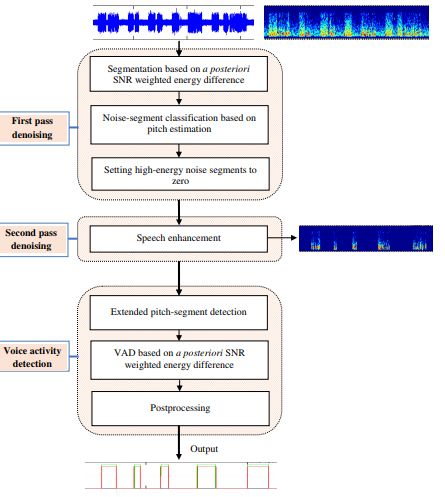
在第二遍检测中,该方法通过语音增强对语音信号进行去噪。该方法进一步评估了RedDots 2016挑战数据库中的数据以验证性能。结果证明了rVAD相比传统方法具有竞争力。
我们都需要更好、更有效的AI算法。更精确的VAD方法有助于AI社区实现性能更好的语音通信系统。谈话语音识别,语音编码,说话人识别,回声消除,音频会议,免提电话等应用均可从中获益。
这一研究还提出了rVAD方法的修改版本(rVAD-fast),它显著降低了计算复杂性,并给予了算法在处理大量数据和运行于资源受限设备上时的优势。
原文:
https://arxiv.org/abs/1906.03588
学习从音频提示中玩电子游戏
Game AI Research Group已经在现有代理(和基于视觉的游戏)的现有框架内开发了一个音频游戏API。该研究是聚焦于训练游戏代理仅通过音频线索玩电子游戏的初步实验。
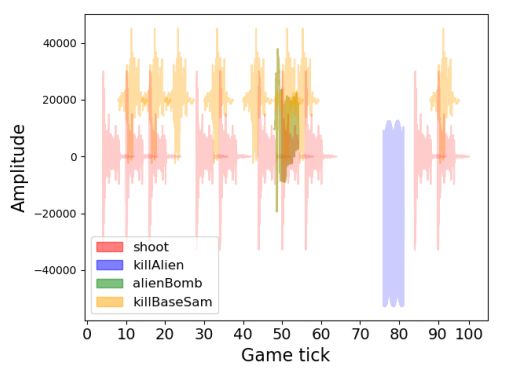
研究人员扩展了视频游戏描述语言,引入了音频的描述规范,并且使用通用视频游戏AI框架(General Video Game AI Framework)提供新的音频游戏和API,以训练代理利用音频进行观察。他们分析了游戏和音频游戏的设计过程,并使用简单的QLearning代理得到了初始结果。
这一研究提供了游戏中的背景音频分析。研究的结果可以与其他方法结合使用,以最大化传感器使用,并获得卓越的游戏音频性能。这项工作提出了许多新的研究方向。人工智能社区可以在该领域做进一步的研究。
例如,可以进一步分析声音以创建适当的响应。它们也可以帮助确定特定声音的含义。此外,通过观察某些特定的声音如何影响代理性能以及如何被删除,可以提高工作质量。
原文:
https://arxiv.org/abs/1906.04027
组会又睡过去了? BERT帮你提取讲座的文本摘要
最近,通过深度学习方法的机器学习已经证明通过聚类输出嵌入可以有效地进行提取总结。这项研究工作主要使用深度学习技术和基于python的RESTful讲座摘要服务。该服务利用BERT模型进行文本嵌入和KMeans聚类,从而能够识别关闭到质心的句子并进行摘要选择。
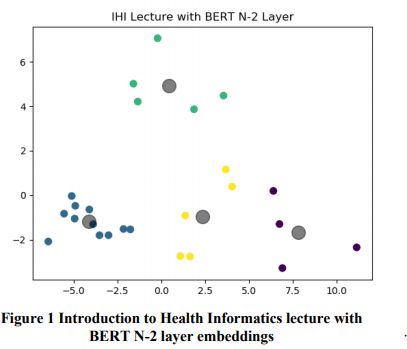
这一工作的目的是为学生提供一种服务,可以根据他们想要的句子数量来总结讲座内容。该服务还包括讲座和摘要管理,可以在云上存储和协作。
除文档摘要外,该技术还可广泛应用于搜索引擎,图像和视频集等领域。研究结果非常有希望实现动态提取讲座摘要,但仍有改进的余地。
代码:
https://github.com/dmmiller612/lecture-summarizer
原文:
https://arxiv.org/abs/1906.04165
基于动态词汇表的词级语音识别
Facebook人工智能研究(小组)提出了一种带有动态词汇表的直接到词的词序列模型。该模型从字符标记中动态构建单词嵌入,可以与任意序列模型无缝集成,包括连接型时间分类模型和注意力编码-解码模型。
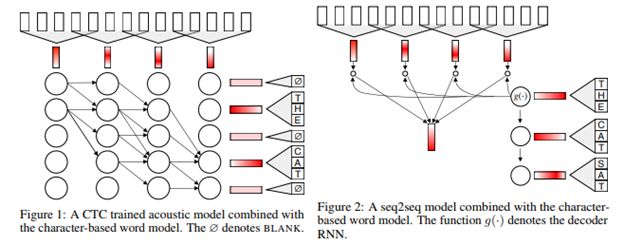
该算法还可以在语音识别子词级模型的基础上实现单词错误率的降低。此外,研究人员还证实,我们所学习的词级嵌入包含重要的声学信息,这使得它们更适合用于语音识别。这种新的直接对单词的方法,具有预测训练时没有出现的单词的能力,并且不需要重新训练。
直接预测单词的能力对于实现更简单、更鲁棒的端到端自动语音识别(ASR)系统并同时实现超高的准确性和效率将具有重要的意义。
原文:
https://arxiv.org/abs/1906.04323
基于自注意力的音乐标签深层序列模型
卷积递归神经网络(CRNN)目前在文档分类、图像分类、音乐转录以及自动音乐标签等方面都非常成功。研究人员现在提出了一个基于自注意力的音乐标签深层序列模型。
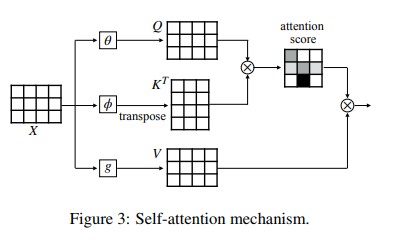
该模型由浅卷积层和堆叠迁移编码器组成。与使用完全卷积或递归神经网络的传统方法相比,新的体系结构更具解释性。使用MagnaTagATune和Million Song数据集(自动音乐标记研究数据集)对模型进行评估,可以得到具有竞争力的结果。该模型还演示了标签贡献可视化热图的可解释性。
这一模型获得了更好的可解释性,从而获得更好的直觉以进行模型设计。而且,由于提出的架构不是特定于任务的,因此可以扩展到其他MIR任务,包括节拍检测、节奏分类或音乐转录等。
详细代码请见:
https://github.com/minzwon/self-attention-music-tagging
原文:
https://arxiv.org/abs/1906.04972
其他爆款论文
新的姿态估计方法,可以帮助设计机器人系统,具有与不属于预先定义类别的野外新对象交互的能力:
https://arxiv.org/abs/1906.05105
可区分的射影算子,可用于PrGAN学习更好的三维生成模型:
https://arxiv.org/abs/1906.04910
社会人工智能数据集发布,通过计算的方法帮助理解人类社会互动:
https://arxiv.org/abs/1906.04158
生成模型如何能够捕获多个样本上的分布,并使用采样生成各种样本:
https://arxiv.org/pdf/1906.04233.pdf
研究人员利用可变嵌入容量进行鲁棒语音合成:
https://arxiv.org/abs/1906.03402
AI新闻
人工智能可否帮助人们更清楚地了解社会以及如何影响自然世界?
https://www.forbes.com/

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们