干货|老司机:用GAN去除(爱情)动作片中的马赛克和衣服!

文章来源:知乎专栏 作者:達聞西(已授权)

作为一名久经片场的老司机,早就想写一些探讨驾驶技术的文章。这篇就介绍利用生成式对抗网络(GAN)的两个基本驾驶技能:
去除(爱情)动作片中的马赛克
给(爱情)动作片中的女孩穿(tuo)衣服
生成式模型
上一篇《用GAN生成二维样本的小例子》中已经简单介绍了GAN,这篇再简要回顾一下生成式模型,算是补全一个来龙去脉。
生成模型就是能够产生指定分布数据的模型,常见的生成式模型一般都会有一个用于产生样本的简单分布。例如一个均匀分布,根据要生成分布的概率密度函数,进行建模,让均匀分布中的样本经过变换得到指定分布的样本,这就可以算是最简单的生成式模型。比如下面例子:
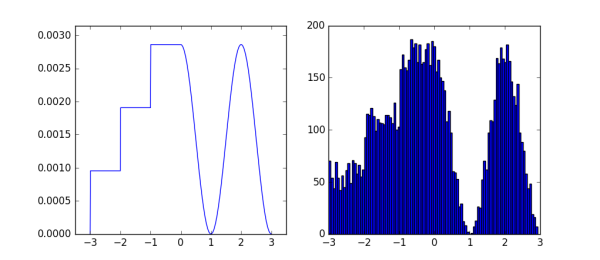
图中左边是一个自定义的概率密度函数,右边是相应的1w个样本的直方图,自定义分布和生成这些样本的代码如下:
from functools
import partialimport numpy
from matplotlib import pyplot
# Define a PDF
x_samples = numpy.arange(-3, 3.01, 0.01)
PDF = numpy.empty(x_samples.shape)
PDF[x_samples < 0] = numpy.round(x_samples[x_samples < 0] + 3.5) / 3
PDF[x_samples >= 0] = 0.5 * numpy.cos(numpy.pi * x_samples[x_samples >= 0]) + 0.5
PDF /= numpy.sum(PDF)
# Calculate approximated CDF
CDF = numpy.empty(PDF.shape)
cumulated = 0
for i in range(CDF.shape[0]):
cumulated += PDF[i]
CDF[i] = cumulated
# Generate samples
generate = partial(numpy.interp, xp=CDF, fp=x_samples)
u_rv = numpy.random.random(10000)
x = generate(u_rv)
# Visualization
fig, (ax0, ax1) = pyplot.subplots(ncols=2, figsize=(9, 4))
ax0.plot(x_samples, PDF)
ax0.axis([-3.5, 3.5, 0, numpy.max(PDF)*1.1])
ax1.hist(x, 100)
pyplot.show()对于一些简单的情况,我们会假设已知有模型可以很好的对分布进行建模,缺少的只是合适的参数。这时候很自然只要根据观测到的样本,学习参数让当前观测到的样本下的似然函数最大,这就是最大似然估计(Maximum Likelihood Estimation):
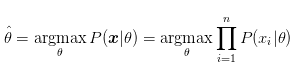
MLE是一个最基本的思路,实践中用得很多的还有KL散度(Kullback–Leibler divergence),假设真实分布是P,采样分布是Q,则KL散度为:
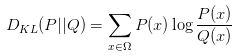
从公式也能看出来,KL散度描述的是两个分布的差异程度。换个角度来看,让产生的样本和原始分布接近,也就是要让这俩的差异减小,所以最小化KL散度就等同于MLE。从公式上来看的话,我们考虑把公式具体展开一下:
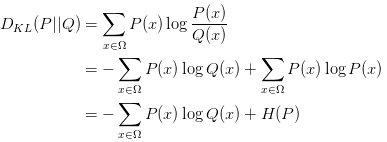
公式的第二项就是熵,先不管这项,用H(P)表示。接下来考虑一个小trick:从Q中抽样n个样本,来估算P(x)的经验值(empirical density function):
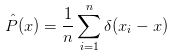
其中是狄拉克 函数,把这项替换到上面公式的P(x):
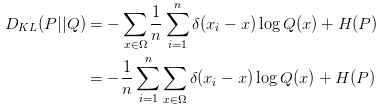
因为是离散的采样值,所以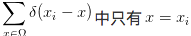
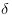
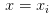
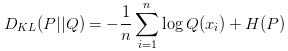
第一项正是似然的负对数形式。
说了些公式似乎跑得有点远了,其实要表达还是那个简单的意思:通过减小两个分布的差异可以让一个分布逼近另一个分布。仔细想想,这正是GAN里面adversarial loss的做法。
很多情况下我们面临的是更为复杂的分布,比如上篇文章中的例子,又或是实际场景中更复杂的情况,比如生成不同人脸的图像。这时候,作为具有universal approximation性质的神经网络是一个看上去不错的选择[1]:
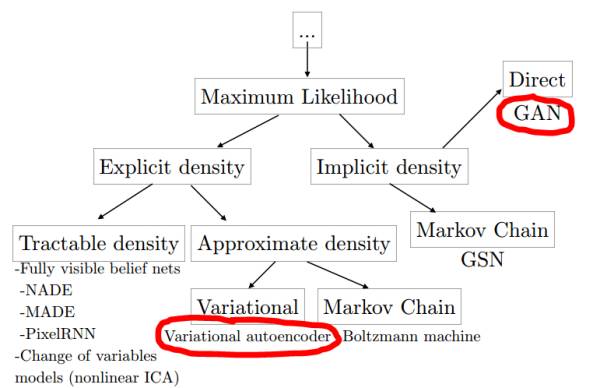
所以虽然GAN里面同时包含了生成网络和判别网络,但本质来说GAN的目的还是生成模型。从生成式模型的角度,Ian Goodfellow总结过一个和神经网络相关生成式方法的“家谱”[1]:
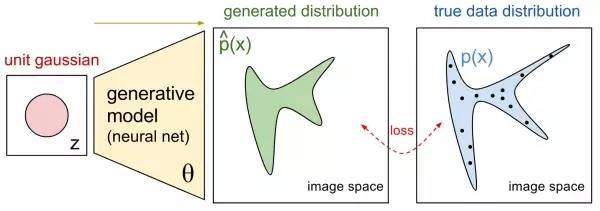
在这其中,当下最流行的就是GAN和Variational AutoEncoder(VAE),两种方法的一个简明示意如下[3]:
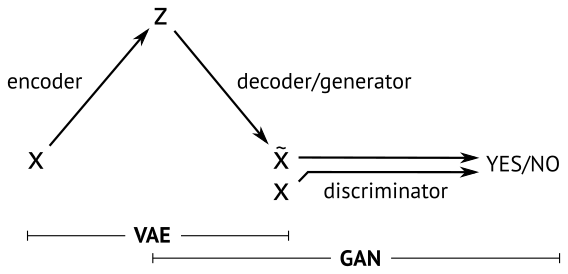
本篇不打算展开讲什么是VAE,不过通过这个图,和名字中的autoencoder也大概能知道,VAE中生成的loss是基于重建误差的。而只基于重建误差的图像生成,都或多或少会有图像模糊的缺点,因为误差通常都是针对全局。比如基于MSE(Mean Squared Error)的方法用来生成超分辨率图像,容易出现下面的情况[4]:
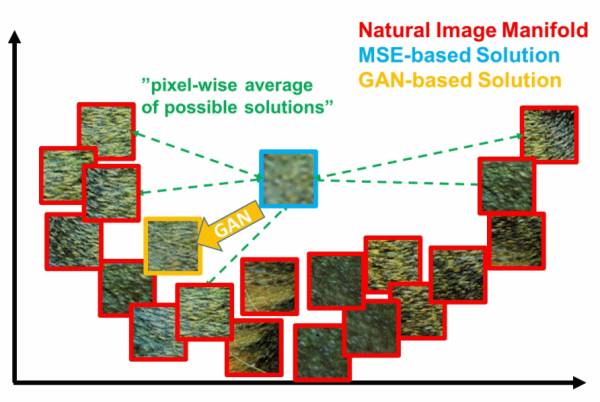
在这个二维示意中,真实数据分布在一个U形的流形上,而MSE系的方法因为loss的形式往往会得到一个接近平均值所在的位置(蓝色框)。
GAN在这方面则完爆其他方法,因为目标分布在流形上。所以只要大概收敛了,就算生成的图像都看不出是个啥,清晰度常常是有保证的,而这正是去除女优身上马赛克的理想特性!
马赛克->清晰画面:超分辨率(Super Resolution)问题
说了好些铺垫,终于要进入正题了。首先明确,去马赛克其实是个图像超分辨率问题,也就是如何在低分辨率图像基础上得到更高分辨率的图像:

视频中超分辨率实现的一个套路是通过不同帧的低分辨率画面猜测超分辨率的画面,有兴趣了解这个思想的朋友可以参考我之前的一个答案:如何通过多帧影像进行超分辨率重构?
不过基于多帧影像的方法对于女优身上的马赛克并不是很适用,所以这篇要讲的是基于单帧图像的超分辨率方法。
SRGAN
说到基于GAN的超分辨率的方法,就不能不提到SRGAN[4]:《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》。这个工作的思路是:基于像素的MSE loss往往会得到大体正确,但是高频成分模糊的结果。所以只要重建低频成分的图像内容,然后靠GAN来补全高频的细节内容,就可以了:
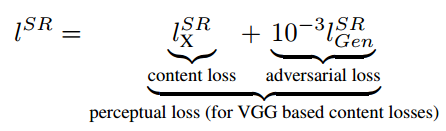
这个思路其实和最早基于深度网络的风格迁移的思路很像(有兴趣的读者可以参考我之前文章瞎谈CNN:通过优化求解输入图像的最后一部分),其中重建内容的content loss是原始图像和低分辨率图像在VGG网络中的各个ReLU层的激活值的差异:
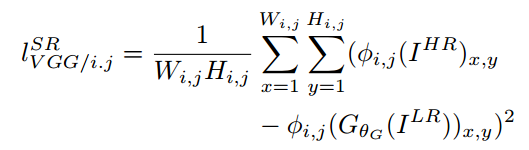
生成细节adversarial loss就是GAN用来判别是原始图还是生成图的loss:
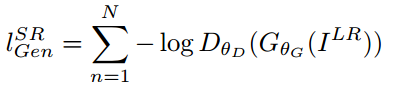
把这两种loss放一起,取个名叫perceptual loss。训练的网络结构如下:
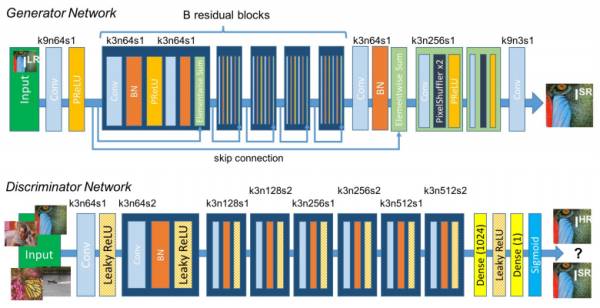
正是上篇文章中讲过的C-GAN,条件C就是低分辨率的图片。SRGAN生成的超分辨率图像虽然PSNR等和原图直接比较的传统量化指标并不是最好,但就视觉效果,尤其是细节上,胜过其他方法很多。比如下面是作者对比bicubic插值和基于ResNet特征重建的超分辨率的结果:

可以看到虽然很多细节都和原始图片不一样,不过看上去很和谐,并且细节的丰富程度远胜于SRResNet。这些栩栩如生的细节,可以看作是GAN根据学习到的分布信息“联想”出来的。
对于更看重“看上去好看”的超分辨率应用,SRGAN显然是很合适的。当然对于一些更看重重建指标的应用,比如超分辨率恢复嫌疑犯面部细节,SRGAN就不可以了。
pix2pix
虽然专门用了一节讲SRGAN,但本文用的方法其实是pix2pix[5]。这项工作刚在arxiv上发布就引起了不小的关注,它巧妙的利用GAN的框架解决了通用的Image-to-Image translation的问题。举例来说,在不改变分辨率的情况下:把照片变成油画风格;把白天的照片变成晚上;用色块对图片进行分割或者倒过来;为黑白照片上色;…每个任务都有专门针对性的方法和相关研究,但其实总体来看,都是像素到像素的一种映射啊,其实可以看作是一个问题。这篇文章的巧妙,就在于提出了pix2pix的方法,一个框架,解决所有这些问题。方法的示意图如下:
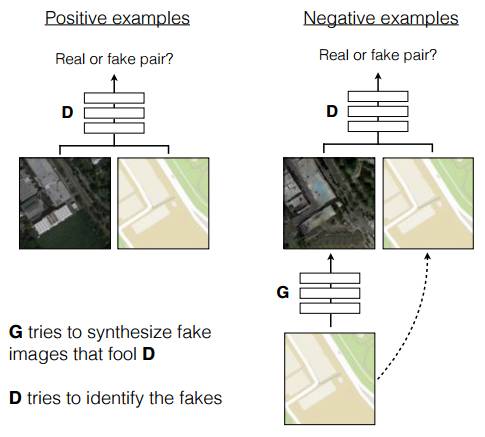
就是一个Conditional GAN,条件C是输入的图片。除了直接用C-GAN,这项工作还有两个改进:
1)利用U-Net结构生成细节更好的图片[6]
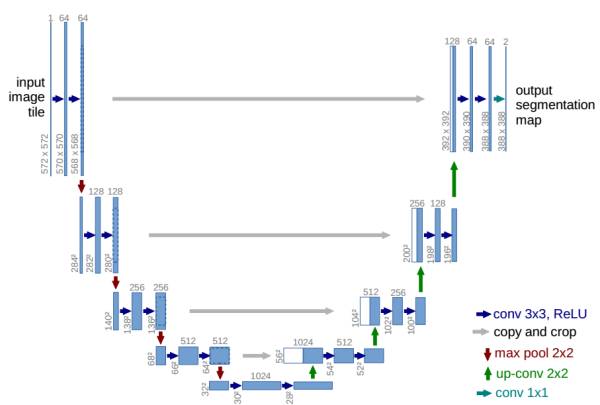
U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显,下面是pix2pix文中给出的一个效果对比:

可以看到,各种不同尺度的信息都得到了很大程度的保留。
2)利用马尔科夫性的判别器(PatchGAN)
pix2pix和SRGAN的一个异曲同工的地方是都有用重建解决低频成分,用GAN解决高频成分的想法。在pix2pix中,这个思想主要体现在两个地方。一个是loss函数,加入了L1 loss用来让生成的图片和训练的目标图片尽量相似,而图像中高频的细节部分则交由GAN来处理:
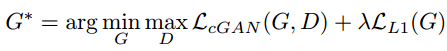
还有一个就是PatchGAN,也就是具体的GAN中用来判别是否生成图的方法。PatchGAN的思想是,既然GAN只负责处理低频成分,那么判别器就没必要以一整张图作为输入,只需要对NxN的一个图像patch去进行判别就可以了。这也是为什么叫Markovian discriminator,因为在patch以外的部分认为和本patch互相独立。
具体实现的时候,作者使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。作者对比了不同大小patch的结果,对于256x256的输入,patch大小在70x70的时候,从视觉上看结果就和直接把整张图片作为判别器输入没什么区别了:

生成带局部马赛克的训练数据
利用pix2pix,只要准备好无码和相应的有码图片就可以训练去马赛克的模型了,就是这么简单。那么问题是,如何生成有马赛克的图片?
有毅力的话,可以手动加马赛克,这样最为精准。这节介绍一个不那么准,但是比随机强的方法:利用分类模型的激活区域进行自动马赛克标注。
基本思想是利用一个可以识别需要打码图像的分类模型,提取出这个模型中对应类的CAM(Class Activation Map)[7],然后用马赛克遮住响应最高的区域即可。这里简单说一下什么是CAM,对于最后一层是全局池化(平均或最大都可以)的CNN结构,池化后的feature map相当于是做了个加权相加来计算最终的每个类别进入softmax之前的激活值。CAM的思路是,把这个权重在池化前的feature map上按像素加权相加,最后得到的单张的激活图就可以携带激活当前类别的一些位置信息,这相当于一种弱监督(classification-->localization):
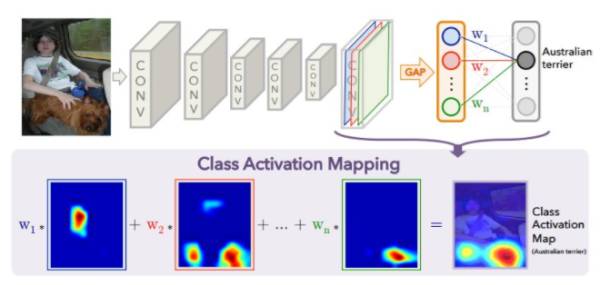
上图是一个CAM的示意,用澳洲梗类别的CAM,放大到原图大小,可以看到小狗所在的区域大致是激活响应最高的区域。
那么就缺一个可以识别XXX图片的模型了,网上还恰好就有个现成的,yahoo于2016年发布的开源色情图片识别模型Open NSFW(Not Safe For Work):
yahoo/open_nsfw:https://github.com/yahoo/open_nsfw
CAM的实现并不难,结合Open NSFW自动打码的代码和使用放在了这里:
给XX图片生成马赛克 :https://github.com/frombeijingwithlove/dlcv_for_beginners/tree/master/random_bonus/generate_mosaic_for_porno_images
(成功打码的)效果差不多是下面这样子:

去除(爱情)动作片中的马赛克
这没什么好说的了,一行代码都不用改,只需要按照前面的步骤把数据准备好,然后按照pix2pix官方的使用方法训练就可以了:
Torch版pix2pix:https://github.com/phillipi/pix2pix
pyTorch版pix2pix(Cycle-GAN二合一版):https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
从D盘里随随便便找了几千张图片,用来执行了一下自动打码和pix2pix训练(默认参数),效果是下面这样:

什么?你问说好给女优去马赛克呢?女优照片呢?

还是要说一下,在真人照片上的效果比蘑菇和花强。
对偶学习(Dual Learning)
去马赛克已经讲完了,接下来就是给女孩穿(tuo)衣服了,动手之前,还是先讲一下铺垫:对偶学习和Cycle-GAN。
对偶学习是MSRA于2016年提出的一种用于机器翻译的增强学习方法[8],目的是解决海量数据配对标注的难题,个人觉得算是一种弱监督方法(不过看到大多数文献算作无监督)。以机器翻译为例,对偶学习基本思想如下图[9]:
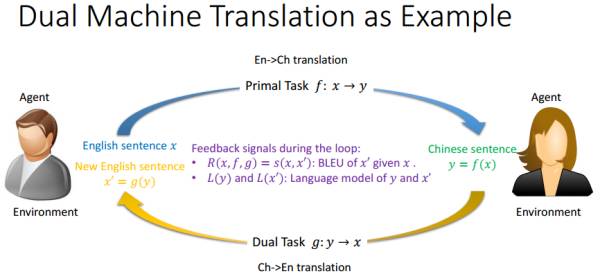
左边的灰衣男只懂英语,右边的黑衣女只懂中文,现在的任务就是,要学习如何翻译英语到中文。对偶学习解决这个问题的思路是:给定一个模型 一上来无法知道f翻译得是否正确,但是如果考虑上 的对偶问题 ,那么我可以尝试翻译一个英文句子到中文,再翻译回来。这种转了一圈的结果 ,灰衣男是可以用一个标准(BLEU)判断x'和x是否一个意思,并且把结果的一致性反馈给这两个模型进行改进。同样的,从中文取个句子,这样循环翻译一遍,两个模型又能从黑衣女那里获取反馈并改进模型。其实这就是强化学习的过程,每次翻译就是一个action,每个action会从环境(灰衣男或黑衣女)中获取reward,对模型进行改进,直至收敛。
也许有的人看到这里会觉得和上世纪提出的Co-training很像,这个在知乎上也有讨论:
如何理解刘铁岩老师团队在NIPS 2016上提出的对偶学习(Dual Learning)?
个人觉得还是不一样的,Co-Training是一种multi-view方法,比如一个输入x,如果看作是两个拼一起的特征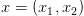

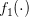
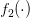
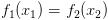


CycleGAN和未配对图像翻译(Unpaired Image-to-Image Translation)
CycleGAN,翻译过来就是:轮着干,是结合了对偶学习和GAN一个很直接而巧妙的想法[10],示意图如下:
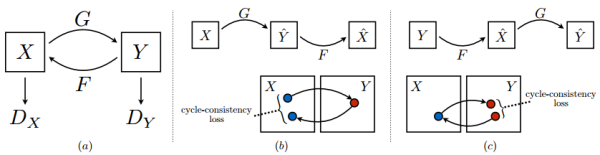
X和Y分别是两种不同类型图的集合,比如穿衣服的女优和没穿衣服的女优。所以给定一张穿了衣服的女优,要变成没穿衣服的样子,就是个图片翻译问题。CycleGAN示意图中(b)和(c)就是Dual Learning:
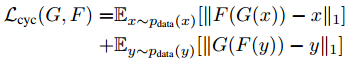
在Dual Learning基础上,又加入了两个判别器 和 用来进行对抗训练,让翻译过来的图片尽量逼近当前集合中的图片:
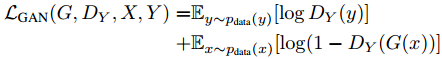
全考虑一起,最终的loss是:
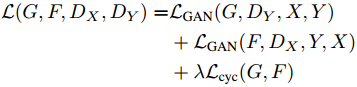
也许有人会问,那不加cycle-consistency,直接用GAN学习一个 的映射,让生成的Y的样本尽量毕竟Y里本身的样本可不可以呢?这个作者在文中也讨论了,会产生GAN训练中容易发生的mode collapse问题。mode collapse问题的一个简单示意如下[11]:

上边的是真实分布,下边的是学习到的分布,可以看到学习到的分布只是完整分布的一部分,这个叫做partial mode collapse,是训练不收敛情况中常见的一种。如果是完全的mode collapse,就是说生成模型得到的都是几乎一样的输出。而加入Cycle-consistency会让一个domain里不同的样本都尽量映射到另一个domain里不同的地方,理想情况就是双射(bijection)。直观来理解,如果通过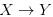
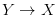
有一点值得注意的是,虽然名字叫CycleGAN,并且套路也和C-GAN很像,但是其实只有adversarial,并没有generative。因为严格来说只是学习了
另外上节中提到了Co-Training,感觉这里也应该提一下CoGAN[14],因为名字有些相似,并且也可以用于未配对的图像翻译。CoGAN的大体思想是:如果两个Domain之间可以互相映射,那么一定有一些特征是共有的。比如男人和女人,虽然普遍可以从长相区分,但不变的是都有两个眼睛一个鼻子一张嘴等等。所以可以在生成的时候,把生成共有特征和各自特征的部分分开,示意图如下:
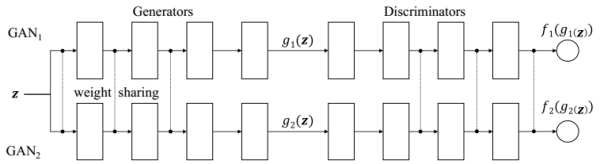
其实就是两个GAN结构,其中生成网络和判别网络中比较高层的部分都采用了权值共享(虚线相连的部分),没有全职共享的部分分别处理不同的domain。这样每次就可以根据训练的domain生成一个样本在两个domain中不同的对应,比如戴眼镜和没戴眼镜:

分别有了共有特征和各自domain特征,那么做mapping的思路也就很直接了[15]:
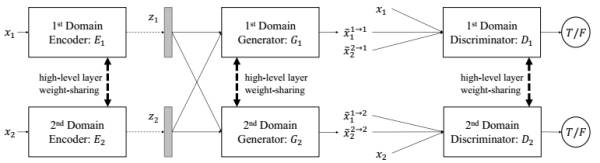
在GAN前边加了个domain encoder,然后对每个domain能得到三种样本给判别器区分:直接采样,重建采样,从另一个domain中transfer后的重建采样。训练好之后,用一个domain的encoder+另一个domain的generator就很自然的实现了不同domain的转换。用在图像翻译上的效果如下:

还有个巧妙的思路,是把CoGAN拆开,不同domain作为C-GAN条件的更加显式的做法[16]:
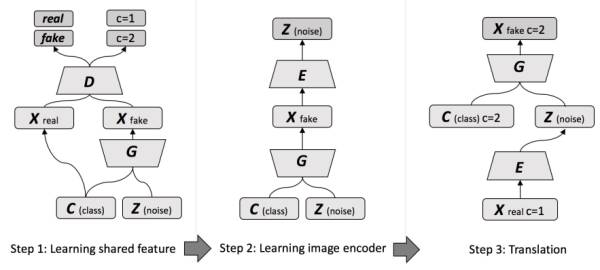
第一步用噪声Z作为和domain无关的共享表征对应的latent noise,domain信息作为条件C训练一个C-GAN。第二步,训练一个encoder,利用和常见的encode-decode结构相反的decode(generate)-encode结构。学习好的encoder可以结合domain信息,把输入图像中和domain无关的共享特征提取出来。第三步,把前两步训练好的encoder和decoder(generator)连一起,就可以根据domain进行图像翻译了。
CoGAN一系的方法虽然结构看起来更复杂,但个人感觉理解起来要比dual系的方法更直接,并且有latent space,可解释性和属性对应也好一些。
又扯远了,还是回到正题:
给女优穿上衣服
其实同样没什么好说的,Cycle-GAN和pix2pix的作者是一拨人,文档都写得非常棒,准备好数据,分成穿衣服的和没穿衣服的两组,按照文档的步骤训练就可以:
Torch版Cycle-GAN:https://github.com/junyanz/CycleGAN
pyTorch版Cycle-GAN(pix2pix二合一版):https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
Cycle-GAN收敛不易,我用了128x128分辨率训练了各穿衣服和没穿衣服的女优各一千多张,同样是默认参数训练了120个epoch,最后小部分成功“穿衣服”的结果如下:


虽然都有些突兀,但好歹是穿上衣服了。注意马赛克不是图片里就有的,是我后来加上去的。
那么,脱衣服的例子在哪里?
参考文献
[1] I. Goodfellow. Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016.
[2] A. B. L. Larsen, S. K. Sønderby, Generating Faces with Torch. Torch | Generating Faces with Torch
[3] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. In ICML, pages 1558–1566, 2016.
[4] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi. Photo-realistic single image super-resolution using a generative adversarial network. arXiv:1609.04802, 2016.
[5] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arxiv, 2016.
[6] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015.
[7] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. arXiv preprint arXiv:1512.04150, 2015.
[8] He, D., Xia, Y., Qin, T., Wang, L., Yu, N., Liu, T.-Y., and Ma, W.-Y. (2016a). Dual learning for machine translation. In the Annual Conference on Neural Information Processing Systems (NIPS), 2016.
[9] Tie-Yan Liu, Dual Learning: Pushing the New Frontier of Artificial Intelligence, MIFS 2016
[10] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networkss. arXiv preprint arXiv:1703.10593, 2017.
[11] Ian Goodfellow, NIPS 2016 Tutorial: Generative Adversarial Networks, NIPS, 2016.
[12] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. ArXiv e-prints, Mar. 2017.
[13] Z. Yi, H. Zhang, P. T. Gong, et al. DualGAN: Unsupervised dual learning for image-to-image translation. arXiv preprint arXiv:1704.02510, 2017.
[14] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems (NIPS), 2016.
[15] M.-Y. Liu, T. Breuel, and J. Kautz. Unsupervised image-to-image translation networks. arXiv preprint arXiv:1703.00848, 2017.
[16] Dong, H., Neekhara, P., Wu, C., Guo, Y.: Unsupervised image-to-image translation with generative adversarial networks. arXiv preprint arXiv:1701.02676, 2017




