使用 Google 照片捕捉特殊视频时刻
文 / Sudheendra Vijayanarasimhan 和 David Ross
将难忘时刻录制成视频并与亲朋好友分享已是十分常见的事。但是,任何拥有庞大视频库的人士都会告诉您,查看所有原始素材,并在其中搜寻要与家人和朋友一起重温或分享的完美片段是一项非常耗时的工作。通过自动查找您视频中的美妙时刻(例如您的孩子吹灭蜡烛,或者朋友跳入泳池),并从中创建您可以轻松与亲朋好友分享的动图,Google 照片可以减轻此项负担。
在《重新思考 Faster R-CNN 架构以实现时序动作定位》(Rethinking the Faster R-CNN Architecture for Temporal Action Localization) 一文中,我们解决了自动处理此任务背后的一些挑战,这些挑战起因于从高度可变的输入数据数组中对动作进行识别和分类十分复杂,而我们的解决方法则是引入一种经过改进的方法,在出现给定动作的视频中找到确切的位置。我们的时序动作定位网络 (TALNet) 正是从 Faster R-CNN 网络等基于区域的物体检测方法进展中汲取灵感。与其他方法相比,TALNet 可以识别持续时间变化很大的时刻,实现最佳性能,它还支持 Google 照片向您推荐视频的最佳片段,方便您与亲朋好友分享。

动作检测示例:“吹灭蜡烛”
识别用于模型训练的动作
在识别视频美妙时刻的过程中,第一步是将用户希望重点展示的动作汇总为一个列表。一些动作示例包括 “吹灭生日蜡烛”、“全倒(保龄球)”、“猫摇尾巴” 等。随后,我们以众包方式标注出现这些特定动作的公开视频集内的片段,以创建一个大型训练数据集。考虑到某些视频可能包含多个动作片段,我们要求评估者找到并标记所有时刻。然后,我们使用此最终标注版数据集训练模型,以使模型能够在陌生的新视频中识别出目标动作。
与物体检测进行比较
这项动作识别挑战属于计算机视觉领域,我们称之为时序动作定位,其与人们更加熟悉的物体检测一样,也属于视觉检测问题的范畴。给定一个未经剪辑的长视频作为输入内容,时序动作定位的目的是确定完整视频中每个动作实例的开始和结束时间,以及动作标签(例如 “吹灭蜡烛”)。物体检测旨在围绕 2D 图像中的物体生成空间边界框,而时序动作定位的目的却是对 1D 视频帧序列生成包含动作的时序片段。
我们的 TALNet 方法受到 Faster R-CNN 2D 图像物体检测框架的启发。因此,在了解 TALNet 之前,先了解 Faster R-CNN 会非常有用。下图展示了如何将 Faster R-CNN 架构用于物体检测。第一步是生成一组候选目标 (Object Proposal),即可以用于分类的图像区域。为此,卷积神经网络 (CNN) 先将输入图像转换为 2D 特征图。然后,候选区域网络 (Region Proposal Network) 围绕候选区域内的物体生成边界框。这些框以多个比例生成,用于捕捉自然图像中物体大小的显著变化。现在已经定义了候选目标,接下来深度神经网络 (DNN) 会将边界框中的对象归类为特定物体,例如 “人”、“自行车” 等。
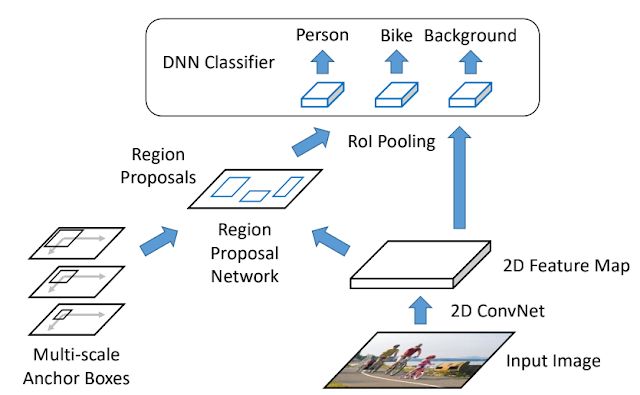
用于物体检测的 Faster R-CNN 架构
时序动作定位
时序动作定位的实现方式与区域卷积神经网络 (R-CNN) 所用的方法类似。该方法首先是将视频的输入帧序列转换为对场景上下文进行编码的 1D 特征图序列。此图会传送给候选片段网络 (Segment Proposal Network),用于生成均由开始和结束时间定义的候选片段。然后,DNN 运用从训练数据集中学到的表征,对候选视频片段中的动作进行分类(例如 “扣篮”、“传球” 等)。根据其学到的表征,从每个片段中识别出的动作会获得相应权重,得分最高的时刻会被挑选出来,以分享给用户。

时序动作定位架构
时序动作定位特别注意事项
虽然可以将时序动作定位视作物体检测问题的 1D 翻版,但我们仍须着重解决动作定位特有的诸多问题。我们尤其需要解决以下三个问题,以便将 Faster R-CNN 方法应用于动作定位领域,并重新设计架构来专门解决这类问题。
动作的持续时间变化更大
动作的时间范围差异巨大,从零点几秒到几分钟不等。对于耗时很长的动作,我们没有太大必要去理解动作的每一帧。相反,我们可以使用扩张时序卷积,通过快速浏览视频来更好地处理动作。TALNet 可以通过此方法搜索视频中的时序模式,同时根据给定的扩张率跳过交替帧。若以基于锚段 (anchor segment) 长度自动选择的多个不同速率分析视频,此举既可高效识别与整个视频时长等长的动作,又可识别短至一秒的动作。动作前后的上下文很重要
动作实例前后的时刻包含用于定位和分类的关键信息,可以说比物体的空间上下文更重要。因此,在候选片段的生成和分类阶段,我们分别按固定的长度比例将候选片段扩展至左右两侧,以此对时序上下文进行显式编码。动作需要多模式输入
动作由外观、运动,有时甚至还由音频信息定义。因此,为获得最佳结果,考虑多种形式的特征非常重要。我们对候选生成网络和分类网络使用后期融合方案,其中每种形式都有一个单独的候选生成网络,这些网络的输出会组合到一起,形成最终的候选集。之后,使用每种形式适用的单独分类网络对这些候选进行分类,然后取其平均值,以得出最终的预测结果。
TALNet 在动作中的出色应用
继取得这些改进后,TALNet 在 THUMOS'14 检测基准的动作提名 (Action Proposal) 和动作定位任务中实现了最佳性能,而且在 ActivityNet 挑战赛上亦有不俗表现。现在,每当人们将视频保存到 Google 照片时,我们的模型都会识别出这些时刻,同时创建用以分享的动图。下面是我们初始测试人员分享的一些示例。

动作检测示例:“滑下滑梯”

动作检测示例:“跳入泳池”(左)、“穿着裙子转圈”(中)和 “喂宝宝一勺食物”(右)
后续步骤
我们将继续使用更多数据、特征和模型,努力提升动作定位的查准率和查全率。时序动作定位的改进可以推动诸多重要功能的进展,范围涵盖视频集锦、视频摘要、搜索等方面。我们希望继续改进这一领域的尖端技术,同时为人们提供更多方式来重温大大小小的回忆。
致谢
特别感谢 Tim Novikoff 和 Yu-Wei Chao,以及 Bryan Seybold、Lily Kharevych、Siyu Gu、Tracy Gu、Tracy Utley、Yael Marzan、Jingyu Cui、Balakrishnan Varadarajan、Paul Natsev 对此项目做出的重要贡献。
更多 AI 相关阅读:



