构建AI知识体系-专知主题知识树简介
【导读】主题知识树是专知的核心结构之一,为构建结构化、体系化、链路化的知识内容库提供基础设施,以及进一步支持个性化主题定制、主题链路知识学习、智能搜索、探索发现等智能应用提供保障。今天为大家简单介绍主题知识树的定义、构建方法和应用,希望大家喜欢,也请多多探讨。
背景
在前面的文章《专知,一个新的认知方式》,我们解释了做专知的思考。面向移动互联时代,我们做两点事情:
一是如何有效生产筛选出专业、可信、优质的内容知识,直达用户需求,解决“专”的问题;
二是如何从自由机制产生的碎片化、乱序、非结构化的内容数据中提取挖掘出结构化、体系化、链路化的知识,便于体系性认知,解决“知”问题。
提出“主题知识树”,目的是探索如何可扩展性地解决内容的结构化、体系化、链路化以构建知识库,并支撑上层智能应用。需要多种技术与方法来综合实现,包括知识图谱、机器学习、自然语言处理、多媒体内容分析等技术以及更重要的社会化人工众包协作机制的引入。
主题知识树的定义
主题知识树旨在描述真实世界中存在的各种概念或实体及其之间的层次类属关系,整体上呈现树状结构,节点表示概念或实体,边则由关系构成,图一展示了一个简单的例子。具体解释如下:
节点:表示的是知识概念或实体。实体是具有可区别性且独立存在的具体某种事物, 比如具体做AI领域某一研究者(如 Andrew Ng)、某一个公司(如 阿里巴巴)、某一个机构(如中科院自动化所)等等; 概念指的是具有同种特性的实体构成的集合或抽象性知识术语,如研究者、公司、机构以及人工智能、机器学习、知识图谱等。
关系:描述的是节点之间的层次类属关系,具体包括实体概念之间的并列、上下位(类属)关系, 比如机器学习是人工智能的一个子分支,计算机视觉与语音处理在感知层面是一种并列关系。主题知识树的关系在数学上形式化为一个函数,把k个点映射一个布尔值。
在专知中,主题知识树的效能就是为了能够准确描述表达知识体系中的概念实体以及之间的层次上下位关系。与知识图谱的区别在于,主题知识树更强调的实体概念之间的层次上下位与并列关系,展现出体系性,呈现出树状特点;而知识图谱呈现的是一张巨大的语义网络图,呈现图状特点。与本体库的区别在于,本体库指的是概念术语之间的关系,其定义更为严格,约束性较强,而主题知识树更加多样性,适应于社会化内容协作机制的产生需求。
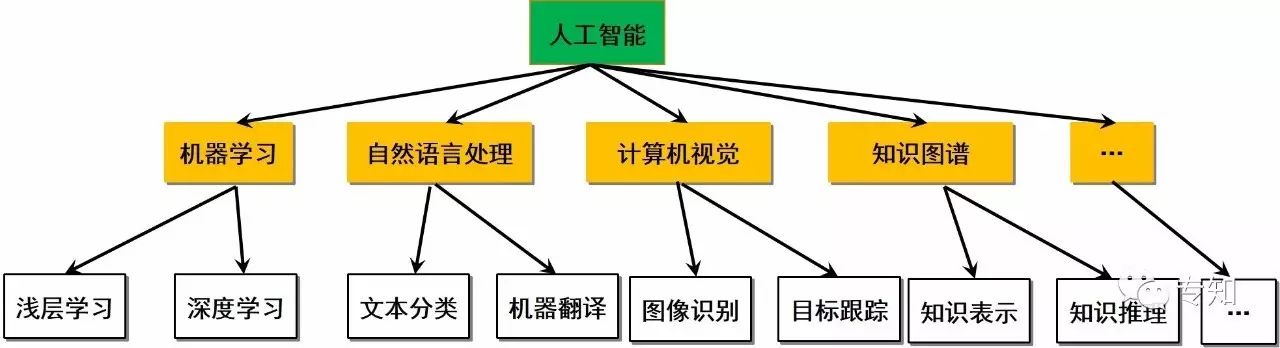
图1 主题知识树的简单示例
主题知识树的构建
参照知识图谱构建的方法,我们提出一种实用的构建主题知识树的方法,并研发配套的构建支撑系统。构建的方法采用网络采集聚合抽取、众包机制贡献、先验知识融合的三种知识来源方式进行融合构建完成初步主题知识树,最后由专家人工审核构建完成。整体的流程框架图如下:
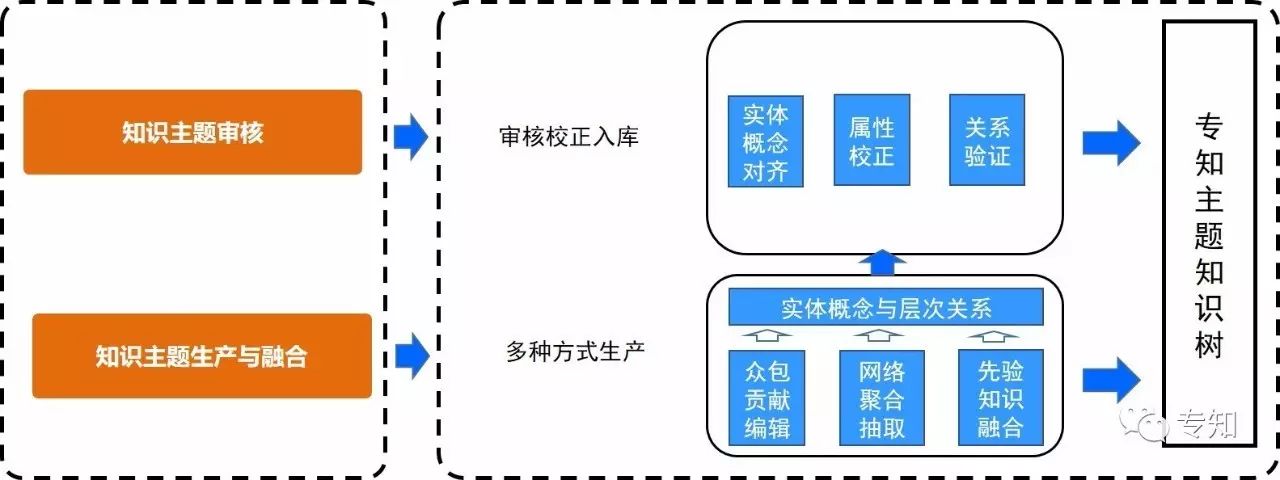
图2 主题知识树的构建框架流程
简单描述下关键步骤:
众包贡献编辑。基于专知产品,通过设计有效的知识生产功能和激励机制来使得大众用户可以来贡献自己在特定领域方面特有的知识。通过众包机制可以有效地利用群体智慧来产生知识特别是新的存在人们头脑中尚未被互联网在线化的知识。
网络聚合抽取。我们从网络公开数据采集,基于实用的算法来,来有效提取实体概念、属性、以及其间的关系,产生主题知识实例。
先验知识融合。基于现有的知识库和第三方结构化知识,提取有效的主题知识实例。
最后,我们邀请特定领域专家审核来进行人工审核,包括实体概念对齐、属性校正、关系验证,最后产生高质量专业可信的主题知识树。
上述流程,是一个长期性需要持续性建设的技术体系工程,我们在不断完善,融合最新的算法模型、工程技术、产品机制来进行,构建出更专业、更可信、更符合用户需求的主题知识树。
人工智能领域主题知识树
专知现在初步构建完成了初步较为完整的人工智能主题知识树,包含了5000多个主题及其之间的上下位层次关系。广义上,我们主体以人工智能、大数据、编程语言、系统架构四方面来建设主题知识树,请在专知PC网页版(www.zhuanzhi.ai) 查看。
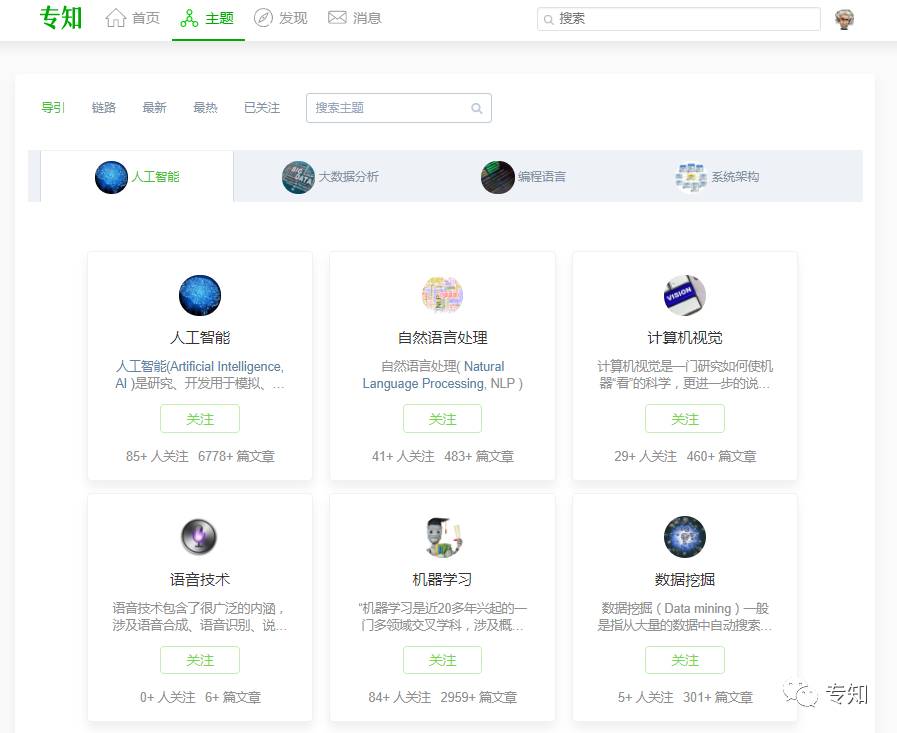
对于单个主题,我们完整性构建了其详细的属性和与其他主题的层次上下位关系。属性包括定义描述、图标、动态消息、精华、知识链路以及之间的父子上下位关系。
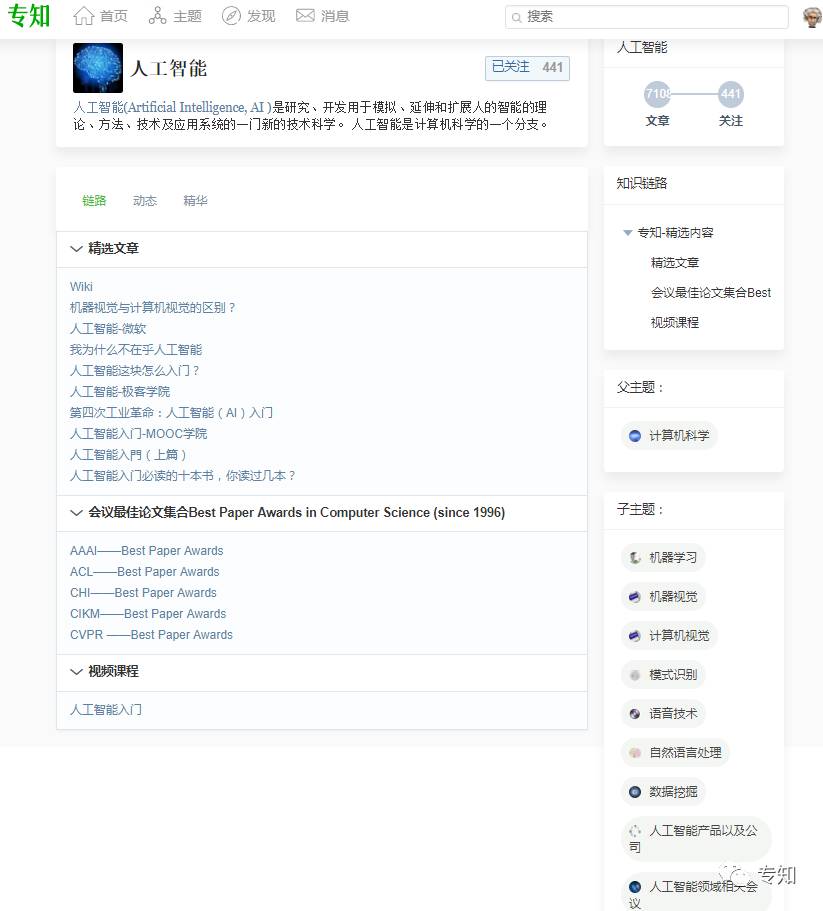
图4、人工智能主题展示
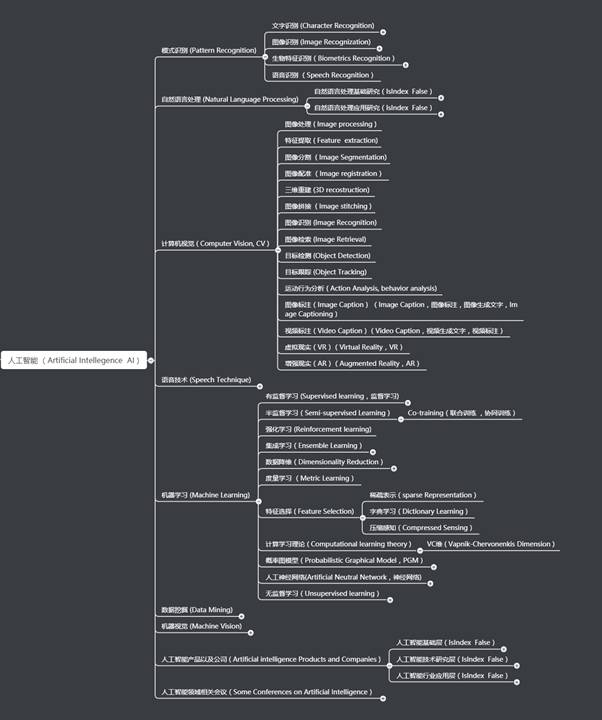
图5、人工智能主题的结构层次
通过主题知识树,你可以循着层次结构进行内容阅读和知识获取。并基于人工智能、大数据、系统架构、编程语言等主类目来一站式的了解学习AI。
主题知识树在专知的应用
基于主题知识树,我们现阶段在专知产品,进行了主题定制个性化推送、主题链路知识学习、搜索发现的应用。
主题定制:基于构建的“主题知识树”,你可以定制感兴趣的主题,便捷获取个性化的最新优质资讯内容。
主题链路:基于构建的主题链路知识库,你可以便捷获取特定主题系统性的专业可信知识,从而进行学习和解决问题。
搜索发现:基于ElasticSearch构建了专知搜索发现,加入对主题索引,可以让你快速、精准触达专知沉淀的关于人工智能的资讯内容、主题、链路知识等资源。
主题知识树作为我们专知的核心结构之一,会一直不断建设和进化,并创造面向用户更多实用的产品功能,解决问题,
欢迎大家使用专知!点击阅读原文即可访问。
同时请,关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法等内容。扫一扫下方关注。





