【泡泡点云时空】基于选择性传感器融合的神经网络视觉里程计
泡泡点云时空,带你精读点云领域顶级会议文章
标题:Selective Sensor Fusion for Neural Visual-Inertial Odometry
作者:Changhao Chen, Stefano Rosa, Yishu Miao, Chris Xiaoxuan Lu, Wei Wu, Andrew Markham, Niki Trigoni
来源:arxiv 2019
编译:程淏
审核:徐二帅,吕佳俊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

近来深度学习方法应用于视觉惯性里程计(VIO)中取得了成功,但却很少关注如何通过鲁棒融合策略处理输入网络时存在缺陷的传感器数据。本文提出了一种新颖的单目VIO端到端选择性传感器融合网络框架,该框架通过融合单目图像及惯性测量数据估计运动轨迹,同时提高对于存在缺陷问题(如数据丢失、损坏或传感器不同步)的现实场景中的鲁棒性。具体实现中,我们提出了两种基于不同掩膜策略的融合模式:确定性软融合、随机性硬融合,并且与过去直接融合的效果进行了比较。在测试过程中,该网络能够选择有效的传感器数据,生成运动轨迹。文中深入研究了该框架在三种公开的无人驾驶、无人机、手持VIO数据集上的性能。结果表明,该融合策略是有效的,其性能优于直接融合,尤其是当数据中存在缺陷数据时。此外,文中研究了该融合网络的可解释性,通过将不同场景及不同缺陷情况下的掩膜层可视化,揭示了该融合网络与缺陷数据间的关联性。
主要贡献
本文主要贡献如下:
提出了一种通用的框架,该框架能够选择有效的传感器数据,更鲁棒、更准确的对现实场景中的自身运动进行估计;
对该框架中的掩膜层进行可视化,并研究了其可解释性,对每个流的相对强度深入研究,为进一步的工作做了引导;
在公开的VIO数据集上,通过7种不同的数据退化方式,构造了具有挑战性的数据集,并对存在缺陷数据情况下深度传感器融合的准确性及鲁棒性进行了全新的、完整的研究。
算法流程
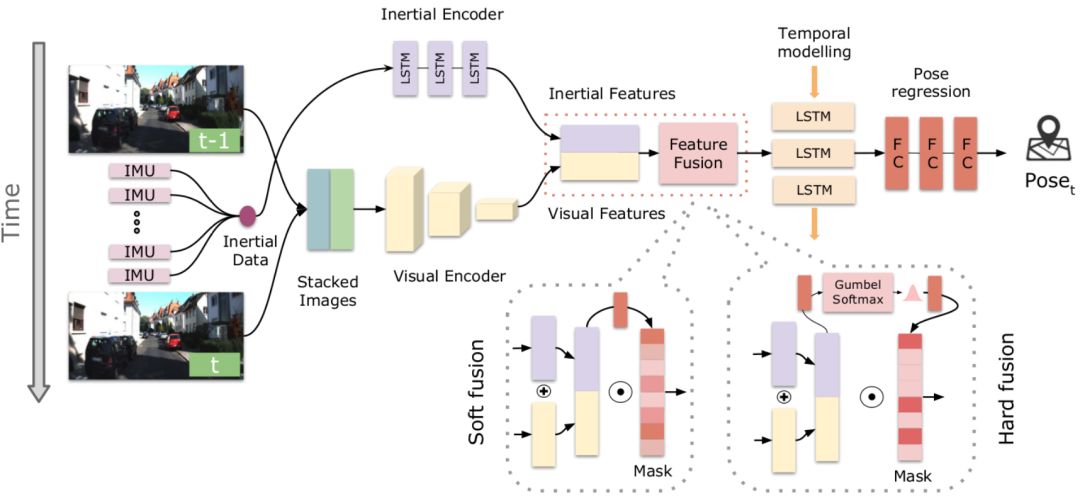
图1 本文提出的基于选择性传感器融合的神经网络VIO框架,其中包括视觉、惯性传感器、特征融合、时间建模及姿态回归。在特征融合部分,文中提出了软融合与硬融合两种策略,并与直接融合进行比较。
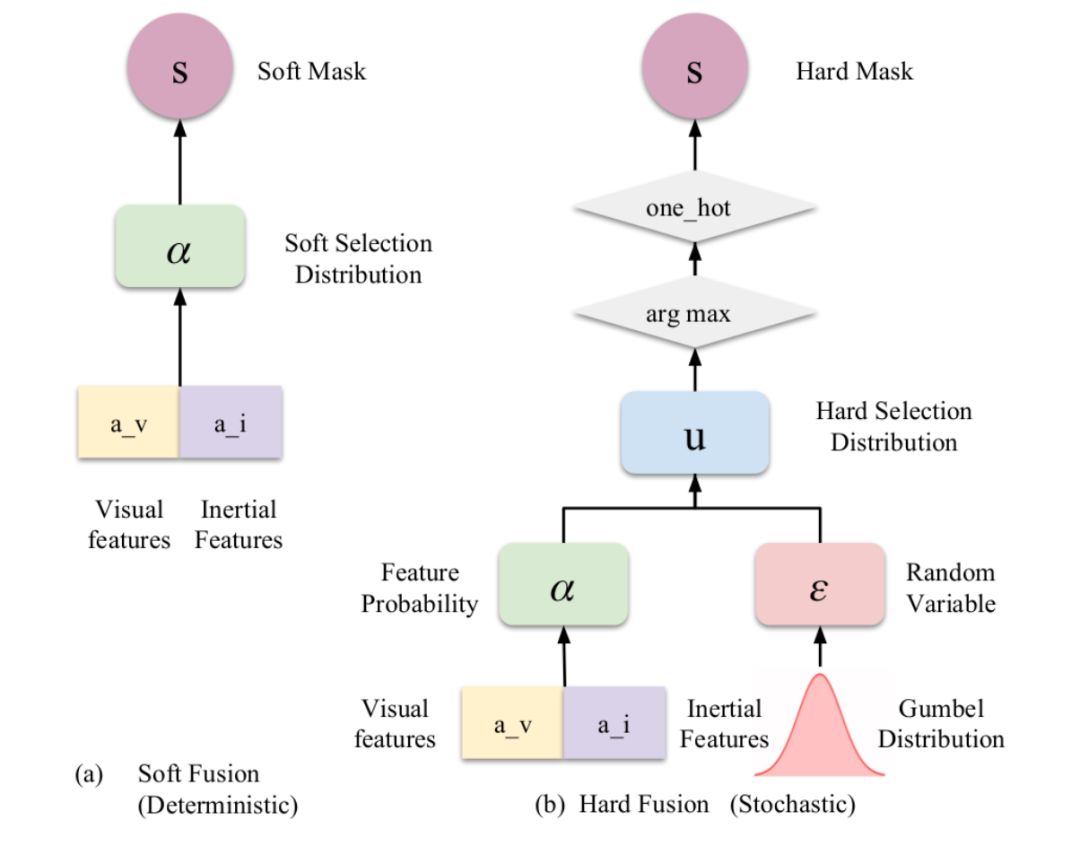
图2 本文提出的软(确定性)和硬(随机性)融合特征选择过程的说明。
主要结果
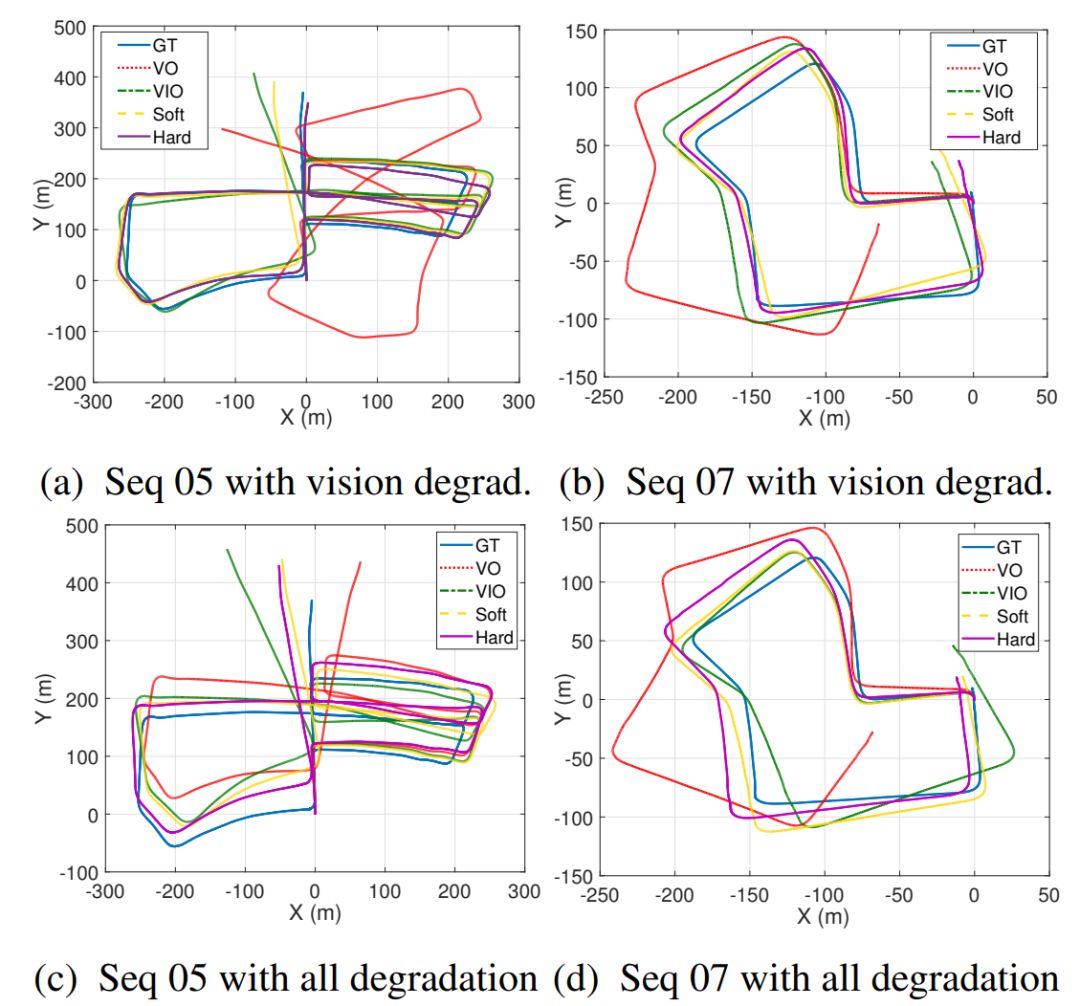
图3 为在构造缺陷后的KITTI数据集上的轨迹估计结果。(a)(b)含视觉退化(10%遮挡,10%模糊,10%缺失数据),(c)(d)含有所有退化(视觉退化、惯性传感器退化均占5%)。GT、VO、VIO、Soft和Hard分别为真实值、纯视觉里程计、神经网络视觉惯性里程计(直接融合)、软融合、硬融合。
对于相关实验效果,作者提供了示例视频:https://changhaoc.github.io/selective_sensor_fusion/

表1 不同的融合策略对于不同类型数据缺陷情况下的有效性。对于每种情况,记录为绝对平移误差(m)和旋转误差(度)。
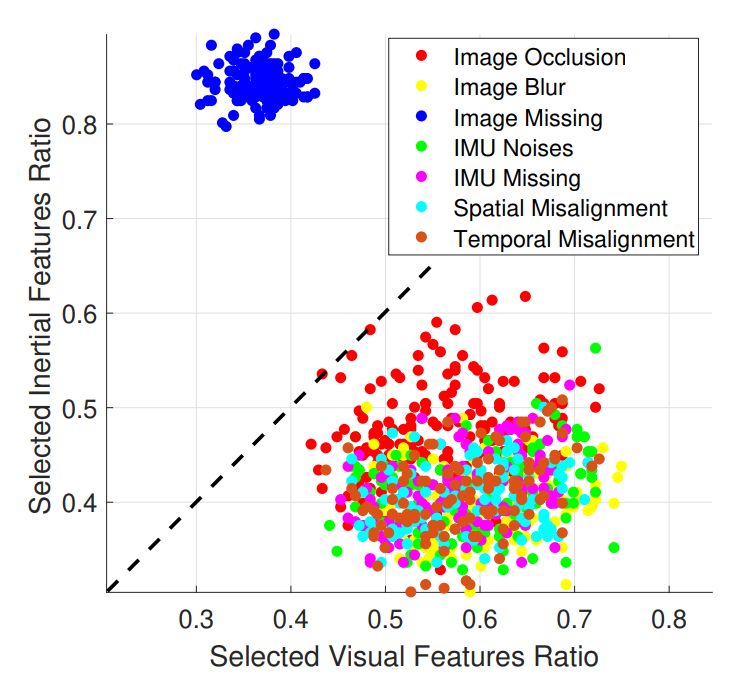
图4 7种数据退化场景下视觉和惯性特征选择率的比较。
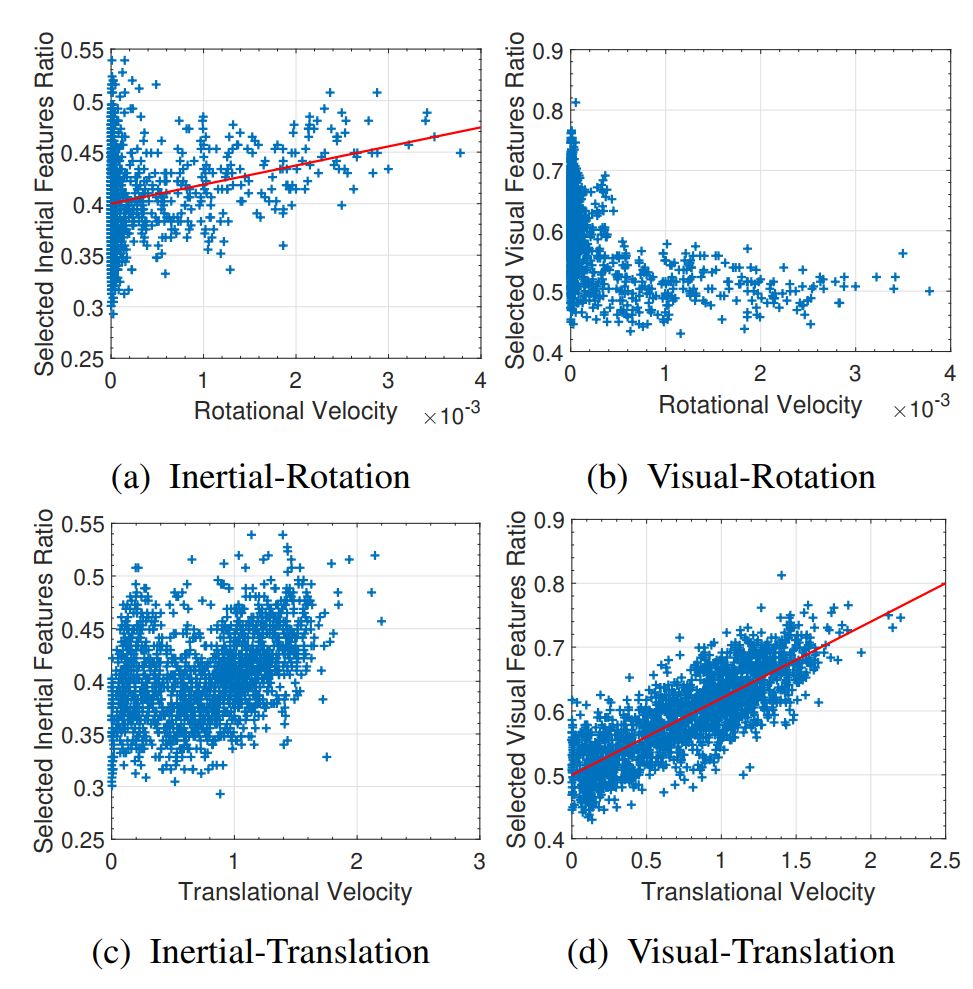
文中还分析了惯性/视觉特征的数量与旋转/平移量之间的相关关系,并得出结论:如转弯时,惯性数据对旋转速度的贡献更大;而当线速度增加时,视觉数据选择率提高。

Abstract
Deep learning approaches for Visual-Inertial Odometry (VIO) have proven successful, but they rarely focus on incorporating robust fusion strategies for dealing with imperfect input sensory data. We propose a novel end-to-end selective sensor fusion framework for monocular VIO, which fuses monocular images and inertial measurements in order to estimate the trajectory whilst improving robustness to real-life issues, such as missing and corrupted data or bad sensor synchronization. In particular, we propose two fusion modalities based on different masking strategies: deterministic soft fusion and stochastic hard fusion, and we compare with previously proposed direct fusion baselines. During testing, the network is able to selectively process the features of the available sensor modalities and produce a trajectory at scale. We present a thorough investigation on the performances on three public autonomous driving, Micro Aerial Vehicle (MAV) and hand-held VIO datasets. The results demonstrate the effectiveness of the fusion strategies, which offer better performances compared to direct fusion, particularly in presence of corrupted data. In addition, we study the interpretability of the fusion networks by visualising the masking layers in different scenarios and with varying data corruption, revealing interesting correlations between the fusion networks and imperfect sensory input data.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



