中文知识图谱构建思路是什么?

知识图谱构建是知识图谱得以应用发展的前提,涉及实体抽取和实体及实体之间关系的建立,同时还需要很好地组织和存储抽取的实体与关系信息,使其能够被迅速的访问和操作。知识图谱构建过程通常可以分成两步:知识图谱本体层构建和实体层的学习。本体层构建通常包含术语抽取、同义词抽取、概念抽取、分类关系抽取、公理和规则学习;实体层学习则包含实体学习、实体数据填充、实体对齐和实体链接等。
知识图谱的构建方法通常有自顶向下和自底向上两种。所谓自顶向下的方法是指先构建知识图谱的本体,即从行业领域、百科类网站及其它等高质量的数据源中,提取本体和模式信息,添加到知识库中;而自底向上的方法是指从实体层开始,借助于一定的技术手段,对实体进行归纳组织、实体对齐和实体链接等,并提取出具有较高置信度的新模式,经人工审核后,加入到知识图谱中。然而,在实际的构建过程中,并不是两种方法孤立单独进行着,而是两种方法交替结合的过程。在构建多数据源的知识图谱时采用两种方法的结合,首先采用自顶向下的方式来构建本体库,然后采用自底向上的方式进行提取知识来扩展知识图谱。
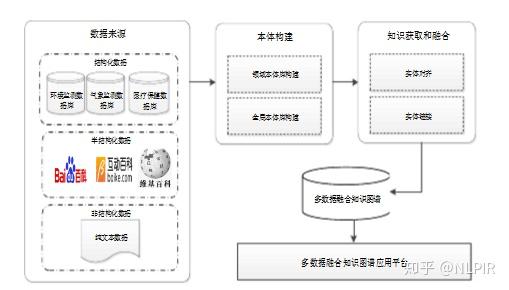

知识图谱构建多基于多种数据源的融合技术,构建相应的知识图谱,具体过程如图1所示。图1中是从多种不同的数据源,如各个领域中的结构化、半结构化和非结构化数据,构建相应的领域本体库,然后将它们映射为全局本体库,接着对这些领域知识图谱通过知识获取和数据融合构造知识图谱,最后通过搭建相应的应用平台,方便对知识图谱进行查询与更新。
北京理工大学大数据搜索与挖掘实验室张华平主任研发的KGB知识图谱引擎,KGB知识图谱引擎(Knowledge Graph Builder)是基于自然语言理解、汉语词法分析,采用KGB语法从结构化数据与非结构化文档中抽取各类知识,大数据语义智能分析与知识推理,深度挖掘知识关联,实时高效构建知识图谱。
KGB知识图谱引擎功能介绍
一、文档提取
1、轻松解析多种格式文档:KGB知识图谱引擎,可轻松解析多种格式、多种版本文档:TXT、DOC、EXCEL、PPT、PDF、XML等。对于图片信息,OCR可自动识别并抽取图片中的文字信息。
2、结构化表格数据知识抽取:KGB能够自适应解读并抽取结构化表格数据,实现知识的快速生成。
3、非结构化文档知识抽取:KGB知识规则引擎,快速定位非结构化文档中的关键信息(主体、时间、金额等),高效抽取知识。
二、知识关联
KGB知识图谱引擎深入挖掘知识关联,将知识实体链接为有意义的知识事实。并具有强大的知识推理能力,推理暗含的知识与结论,丰富知识图谱。
三、知识推理
KGB具有强大的知识推理能力,推理出暗含的知识,获取更多知识与结论,丰富知识图谱。
1、演绎归纳推理(一般—特殊):KGB能够完成由一般特征到特殊个案的演绎知识推理和由特殊个案到一般特征的归纳知识推理,扩充大量暗含的知识,丰富知识图谱。
2、知识计算(数值知识的加减乘除计算):对于数值型知识,KGB能够识别并对数值型知识进行加减乘除的知识计算推理,并可对知识计算的准确性进行核查。
3、知识库检查:KGB能够实时检查知识库,纠正知识错误与冲突,保证知识图谱正确性与一致性。
以上内容希望可以帮助您!