Instance Segmentation 比 Semantic Segmentation 难很多吗?

本硕博都是数学学位
博士期间接触到图像分割、语义分割、实例分割
这里尝试用组合数学的角度对比一下这俩个task的难度
希望仅有排列组合基础的初中生也能看懂
如今大热的计算机视觉领域几个经典问题
首先盗用一下 @周博磊 回答里的图
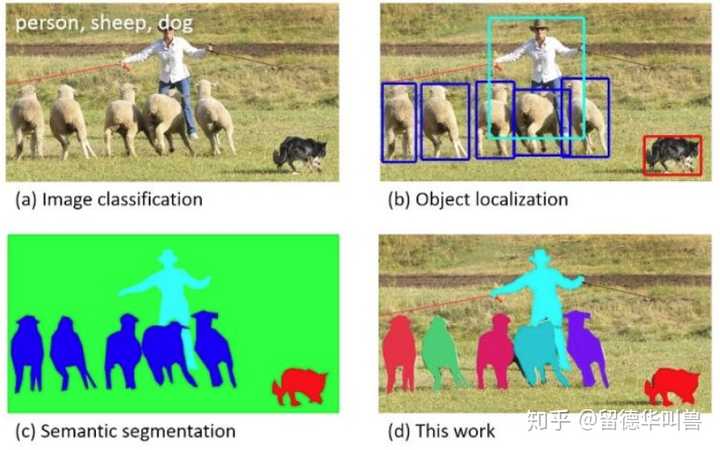

一、任务定义
Semantic Segmentation(c语义分割):将每一个像素分类
Object Localization|detection(b目标检测):检测并用方框标记出图片中的物体(找出方框中心点和长宽),并作分类
Instance Segmentation(d实例分割):将图片中属于物体类别的像素识别出来并作分类
其中分类的类别可以是天空、草地、人、狗
Object(物体)特指可以被方框框定的类别
二、实例分割 难于 目标检测
这里我们做出这样一个假设
因为目前主流做实例分割的方法大都基于目标检测
即:
先跑目标检测
然后对于每一个方框跑一个二元图像分割(binary segmenation)
三、目标检测 难于 语义分割
假设一张图片10x10=100个像素
类别:草地、人、狗=3类
从组合数学的角度
语义分割是对每一个像素做分类
所以总共有3^100种不同的分类方法
即:
每个像素有3种不同可能性
换句话说
语义分割问题可以转化为一个从3^100种分类方案里找最好方案的组合优化问题 @运筹OR帷幄
而目标检测
首先
对于每一个像素
你不知道这个像素是否为某个物体的中心
因此有2种可能性(是或不是)
其次
每个方框里面是什么有3种可能性
再次
方框的长和宽也是不确定的
长和宽的可能性是1-5(这里5取了0和10的平均)、相乘便是25种可能性
因此
对于一张100个像素的图所有可能性的组合是(3x2x25)^100
即:
每个像素有150种不同可能性
P.S.:
这里提一个小插曲
因为博士期间没有接触过目标检测
找工作面试的时候被面到这个问题
结果“想当然”地答错了
希望这个回答可以提供给刚入门视觉的小伙伴
一些不一样的insights