【盘点影响计算机视觉Top100论文】从ResNet到AlexNet
1新智元编译
来源:github
编译整理: 新智元编辑部
【新智元导读】计算机视觉近年来获得了较大的发展,代表了深度学习最前沿的研究方向。本文梳理了2012到2017年计算机视觉领域的大事件:以论文和其他干货资源为主,并附上资源地址。囊括上百篇论文,分ImageNet 分类、物体检测、物体追踪、物体识别、图像与语言和图像生成等多个方向进行介绍。

今年2月,新智元曾经向大家介绍了近5年100篇被引用次数最多的深度学习论文,覆盖了优化/训练方法、无监督/生成模型、卷积网络模型和图像分割/目标检测等十大子领域。
【进入新智元公众号,在对话框输入“论文100”下载这份经典资料】
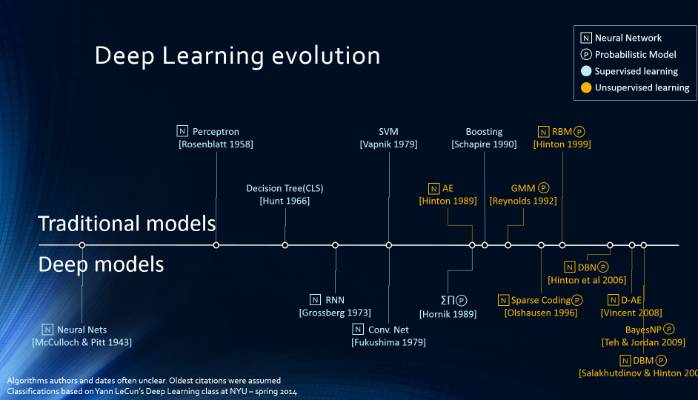
上述的深度学习被引用最多的100篇论文是Github上的一个开源项目,社区的成员都可以参与。在这个项目上,我们发现了另一个项目——Deep Vision,这是一个关于计算机视觉资源的项目,包含了近年来对该领域影响最大的论文、图书和博客等的汇总。其中在论文部分,作者也分为ImageNet 分类、物体检测、物体追踪、物体识别、图像与语言和图像生成等多个方向进行介绍。
经典论文
ImageNet分类
物体检测
物体跟踪
低级视觉
超分辨率
其他应用
边缘检测
语义分割
视觉注意力和显著性
物体识别
人体姿态估计
CNN原理和性质(Understanding CNN)
图像和语言
图像解说
视频解说
问答
图像生成

上面是根据这些论文、作者、机构的一些关键词制作的热图。

图片来源:AlexNet论文
微软ResNet
论文:用于图像识别的深度残差网络
作者:何恺明、张祥雨、任少卿和孙剑
链接(复制后可以在浏览器中打开查看):http://arxiv.org/pdf/1512.03385v1.pdf
微软PRelu(随机纠正线性单元/权重初始化)
论文:深入学习整流器:在ImageNet分类上超越人类水平
作者:何恺明、张祥雨、任少卿和孙剑
链接:https://arxiv.org/pdf/1502.01852.pdf
谷歌Batch Normalization
论文:批量归一化:通过减少内部协变量来加速深度网络训练
作者:Sergey Ioffe, Christian Szegedy
链接:https://arxiv.org/pdf/1502.03167.pdf
谷歌GoogLeNet
论文:更深的卷积,CVPR 2015
作者:Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich
链接:https://arxiv.org/pdf/1409.4842.pdf
牛津VGG-Net
论文:大规模视觉识别中的极深卷积网络,ICLR 2015
作者:Karen Simonyan & Andrew Zisserman
链接:https://arxiv.org/pdf/1409.1556.pdf
AlexNet
论文:使用深度卷积神经网络进行ImageNet分类
作者:Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
链接:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf

图片来源:Faster-RCNN 论文
PVANET
论文:用于实时物体检测的深度轻量神经网络(PVANET:Deep but Lightweight Neural Networks for Real-time Object Detection)
作者:Kye-Hyeon Kim, Sanghoon Hong, Byungseok Roh, Yeongjae Cheon, Minje Park
链接:https://arxiv.org/pdf/1608.08021
纽约大学OverFeat
论文:使用卷积网络进行识别、定位和检测(OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks),ICLR 2014
作者:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun
链接:https://arxiv.org/pdf/1312.6229.pdf
伯克利R-CNN
论文:精确物体检测和语义分割的丰富特征层次结构(Rich feature hierarchies for accurate object detection and semantic segmentation),CVPR 2014
作者:Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik
链接:http://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper.pdf
微软SPP
论文:视觉识别深度卷积网络中的空间金字塔池化(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition),ECCV 2014
作者:何恺明、张祥雨、任少卿和孙剑
链接:https://arxiv.org/pdf/1406.4729.pdf
微软Fast R-CNN
论文:Fast R-CNN
作者:Ross Girshick
链接:https://arxiv.org/pdf/1504.08083.pdf
微软Faster R-CNN
论文:使用RPN走向实时物体检测(Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
作者:任少卿、何恺明、Ross Girshick、孙剑
链接:https://arxiv.org/pdf/1506.01497.pdf
牛津大学R-CNN minus R
论文:R-CNN minus R
作者:Karel Lenc, Andrea Vedaldi
链接:https://arxiv.org/pdf/1506.06981.pdf
端到端行人检测
论文:密集场景中端到端的行人检测(End-to-end People Detection in Crowded Scenes)
作者:Russell Stewart, Mykhaylo Andriluka
链接:https://arxiv.org/pdf/1506.04878.pdf
实时物体检测
论文:你只看一次:统一实时物体检测(You Only Look Once: Unified, Real-Time Object Detection)
作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
链接:https://arxiv.org/pdf/1506.02640.pdf
Inside-Outside Net
论文:使用跳跃池化和RNN在场景中检测物体(Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks)
作者:Sean Bell, C. Lawrence Zitnick, Kavita Bala, Ross Girshick
链接:https://arxiv.org/abs/1512.04143.pdf
微软ResNet
论文:用于图像识别的深度残差网络
作者:何恺明、张祥雨、任少卿和孙剑
链接:http://arxiv.org/pdf/1512.03385v1.pdf
R-FCN
论文:通过区域全卷积网络进行物体识别(R-FCN: Object Detection via Region-based Fully Convolutional Networks)
作者:代季峰,李益,何恺明,孙剑
链接:https://arxiv.org/abs/1605.06409
SSD
论文:单次多框检测器(SSD: Single Shot MultiBox Detector)
作者:Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
链接:https://arxiv.org/pdf/1512.02325v2.pdf
速度/精度权衡
论文:现代卷积物体检测器的速度/精度权衡(Speed/accuracy trade-offs for modern convolutional object detectors)
作者:Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Kevin Murphy
链接:https://arxiv.org/pdf/1611.10012v1.pdf
论文:用卷积神经网络通过学习可区分的显著性地图实现在线跟踪(Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network)
作者:Seunghoon Hong, Tackgeun You, Suha Kwak, Bohyung Han
地址:arXiv:1502.06796.
论文:DeepTrack:通过视觉跟踪的卷积神经网络学习辨别特征表征(DeepTrack: Learning Discriminative Feature Representations by Convolutional Neural Networks for Visual Tracking)
作者:Hanxi Li, Yi Li and Fatih Porikli
发表: BMVC, 2014.
论文:视觉跟踪中,学习深度紧凑图像表示(Learning a Deep Compact Image Representation for Visual Tracking)
作者:N Wang, DY Yeung
发表:NIPS, 2013.
论文:视觉跟踪的分层卷积特征(Hierarchical Convolutional Features for Visual Tracking)
作者:Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang
发表: ICCV 2015
论文:完全卷积网络的视觉跟踪(Visual Tracking with fully Convolutional Networks)
作者:Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu,
发表:ICCV 2015
论文:学习多域卷积神经网络进行视觉跟踪
(Learning Multi-Domain Convolutional Neural Networks for Visual Tracking)
作者:Hyeonseob Namand Bohyung Han
论文:卷积神经网络弱监督学习(Weakly-supervised learning with convolutional neural networks)
作者:Maxime Oquab,Leon Bottou,Ivan Laptev,Josef Sivic,CVPR,2015
链接:http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Oquab_Is_Object_Localization_2015_CVPR_paper.pdf
FV-CNN
论文:深度滤波器组用于纹理识别和分割(Deep Filter Banks for Texture Recognition and Segmentation)
作者:Mircea Cimpoi, Subhransu Maji, Andrea Vedaldi, CVPR, 2015.
链接:http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Cimpoi_Deep_Filter_Banks_2015_CVPR_paper.pdf
论文:使用 Part Affinity Field的实时多人2D姿态估计(Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields)
作者:Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh, CVPR, 2017.
论文:Deepcut:多人姿态估计的联合子集分割和标签(Deepcut: Joint subset partition and labeling for multi person pose estimation)
作者:Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter Gehler, and Bernt Schiele, CVPR, 2016.
论文:Convolutional pose machines
作者:Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh, CVPR, 2016.
论文:人体姿态估计的 Stacked hourglass networks(Stacked hourglass networks for human pose estimation)
作者:Alejandro Newell, Kaiyu Yang, and Jia Deng, ECCV, 2016.
论文:用于视频中人体姿态估计的Flowing convnets(Flowing convnets for human pose estimation in videos)
作者:Tomas Pfister, James Charles, and Andrew Zisserman, ICCV, 2015.
论文:卷积网络和人类姿态估计图模型的联合训练(Joint training of a convolutional network and a graphical model for human pose estimation)
作者:Jonathan J. Tompson, Arjun Jain, Yann LeCun, Christoph Bregler, NIPS, 2014.

图:(from Aravindh Mahendran, Andrea Vedaldi, Understanding Deep Image Representations by Inverting Them, CVPR, 2015.)
论文:通过测量同变性和等价性来理解图像表示(Understanding image representations by measuring their equivariance and equivalence)
作者:Karel Lenc, Andrea Vedaldi, CVPR, 2015.
链接:http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Lenc_Understanding_Image_Representations_2015_CVPR_paper.pdf
论文:深度神经网络容易被愚弄:无法识别的图像的高置信度预测(Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images)
作者:Anh Nguyen, Jason Yosinski, Jeff Clune, CVPR, 2015.
链接:http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Nguyen_Deep_Neural_Networks_2015_CVPR_paper.pdf
论文:通过反演理解深度图像表示(Understanding Deep Image Representations by Inverting Them)
作者:Aravindh Mahendran, Andrea Vedaldi, CVPR, 2015
链接:http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Mahendran_Understanding_Deep_Image_2015_CVPR_paper.pdf
论文:深度场景CNN中的对象检测器(Object Detectors Emerge in Deep Scene CNNs)
作者:Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba, ICLR, 2015.
链接:http://arxiv.org/abs/1412.6856
论文:用卷积网络反演视觉表示(Inverting Visual Representations with Convolutional Networks)
作者:Alexey Dosovitskiy, Thomas Brox, arXiv, 2015.
链接:http://arxiv.org/abs/1506.02753
论文:可视化和理解卷积网络(Visualizing and Understanding Convolutional Networks)
作者:Matthrew Zeiler, Rob Fergus, ECCV, 2014.
链接:https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
图像说明(Image Captioning)

图:(from Andrej Karpathy, Li Fei-Fei, Deep Visual-Semantic Alignments for Generating Image Description, CVPR, 2015.)
UCLA / Baidu
用多模型循环神经网络解释图像(Explain Images with Multimodal Recurrent Neural Networks)
Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Alan L. Yuille, arXiv:1410.1090
http://arxiv.org/pdf/1410.1090
Toronto
使用多模型神经语言模型统一视觉语义嵌入(Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models)
Ryan Kiros, Ruslan Salakhutdinov, Richard S. Zemel, arXiv:1411.2539.
http://arxiv.org/pdf/1411.2539
Berkeley
用于视觉识别和描述的长期循环卷积网络(Long-term Recurrent Convolutional Networks for Visual Recognition and Description)
Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell, arXiv:1411.4389.
http://arxiv.org/pdf/1411.4389
看图写字:神经图像说明生成器(Show and Tell: A Neural Image Caption Generator)
Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan, arXiv:1411.4555.
http://arxiv.org/pdf/1411.4555
Stanford
用于生成图像描述的深度视觉语义对齐(Deep Visual-Semantic Alignments for Generating Image Description)
Andrej Karpathy, Li Fei-Fei, CVPR, 2015.
Web:http://cs.stanford.edu/people/karpathy/deepimagesent/
Paper:http://cs.stanford.edu/people/karpathy/cvpr2015.pdf
UML / UT
使用深度循环神经网络将视频转换为自然语言(Translating Videos to Natural Language Using Deep Recurrent Neural Networks)
Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko, NAACL-HLT, 2015.
http://arxiv.org/pdf/1412.4729
CMU / Microsoft
学习图像说明生成的循环视觉表示(Learning a Recurrent Visual Representation for Image Caption Generation)
Xinlei Chen, C. Lawrence Zitnick, arXiv:1411.5654.
Xinlei Chen, C. Lawrence Zitnick, Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation, CVPR 2015
http://www.cs.cmu.edu/~xinleic/papers/cvpr15_rnn.pdf
Microsoft
从图像说明到视觉概念(From Captions to Visual Concepts and Back)
Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollár, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John C. Platt, C. Lawrence Zitnick, Geoffrey Zweig, CVPR, 2015.
http://arxiv.org/pdf/1411.4952
Univ. Montreal / Univ. Toronto
Show, Attend, and Tell:视觉注意力与神经图像标题生成(Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention)
Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, Yoshua Bengio, arXiv:1502.03044 / ICML 2015
http://www.cs.toronto.edu/~zemel/documents/captionAttn.pdf
Idiap / EPFL / Facebook
基于短语的图像说明(Phrase-based Image Captioning)
Remi Lebret, Pedro O. Pinheiro, Ronan Collobert, arXiv:1502.03671 / ICML 2015
http://arxiv.org/pdf/1502.03671
UCLA / Baidu
像孩子一样学习:从图像句子描述快速学习视觉的新概念(Learning like a Child: Fast Novel Visual Concept Learning from Sentence Descriptions of Images)
Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Zhiheng Huang, Alan L. Yuille, arXiv:1504.06692
http://arxiv.org/pdf/1504.06692
MS + Berkeley
探索图像说明的最近邻方法( Exploring Nearest Neighbor Approaches for Image Captioning)
Jacob Devlin, Saurabh Gupta, Ross Girshick, Margaret Mitchell, C. Lawrence Zitnick, arXiv:1505.04467
http://arxiv.org/pdf/1505.04467.pdf
图像说明的语言模型(Language Models for Image Captioning: The Quirks and What Works)
Jacob Devlin, Hao Cheng, Hao Fang, Saurabh Gupta, Li Deng, Xiaodong He, Geoffrey Zweig, Margaret Mitchell, arXiv:1505.01809
http://arxiv.org/pdf/1505.01809.pdf
阿德莱德
具有中间属性层的图像说明( Image Captioning with an Intermediate Attributes Layer)
Qi Wu, Chunhua Shen, Anton van den Hengel, Lingqiao Liu, Anthony Dick, arXiv:1506.01144
蒂尔堡
通过图片学习语言(Learning language through pictures)
Grzegorz Chrupala, Akos Kadar, Afra Alishahi, arXiv:1506.03694
蒙特利尔大学
使用基于注意力的编码器-解码器网络描述多媒体内容(Describing Multimedia Content using Attention-based Encoder-Decoder Networks)
Kyunghyun Cho, Aaron Courville, Yoshua Bengio, arXiv:1507.01053
康奈尔
图像表示和神经图像说明的新领域(Image Representations and New Domains in Neural Image Captioning)
Jack Hessel, Nicolas Savva, Michael J. Wilber, arXiv:1508.02091
MS + City Univ. of HongKong
Learning Query and Image Similarities with Ranking Canonical Correlation Analysis
Ting Yao, Tao Mei, and Chong-Wah Ngo, ICCV, 2015
视频字幕(Video Captioning)
伯克利
Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell, Long-term Recurrent Convolutional Networks for Visual Recognition and Description, CVPR, 2015.
犹他州/ UML / 伯克利
Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko, Translating Videos to Natural Language Using Deep Recurrent Neural Networks, arXiv:1412.4729.
微软
Yingwei Pan, Tao Mei, Ting Yao, Houqiang Li, Yong Rui, Joint Modeling Embedding and Translation to Bridge Video and Language, arXiv:1505.01861.
犹他州/ UML / 伯克利
Subhashini Venugopalan, Marcus Rohrbach, Jeff Donahue, Raymond Mooney, Trevor Darrell, Kate Saenko, Sequence to Sequence--Video to Text, arXiv:1505.00487.
蒙特利尔大学/ 舍布鲁克
Li Yao, Atousa Torabi, Kyunghyun Cho, Nicolas Ballas, Christopher Pal, Hugo Larochelle, Aaron Courville, Describing Videos by Exploiting Temporal Structure, arXiv:1502.08029
MPI / 伯克利
Anna Rohrbach, Marcus Rohrbach, Bernt Schiele, The Long-Short Story of Movie Description, arXiv:1506.01698
多伦多大学 / MIT
Yukun Zhu, Ryan Kiros, Richard Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, Sanja Fidler, Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books, arXiv:1506.06724
蒙特利尔大学
Kyunghyun Cho, Aaron Courville, Yoshua Bengio, Describing Multimedia Content using Attention-based Encoder-Decoder Networks, arXiv:1507.01053
TAU / 美国南加州大学
Dotan Kaufman, Gil Levi, Tal Hassner, Lior Wolf, Temporal Tessellation for Video Annotation and Summarization, arXiv:1612.06950.
卷积/循环网络
论文:Conditional Image Generation with PixelCNN Decoders”
作者:Aäron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu
论文:Learning to Generate Chairs with Convolutional Neural Networks
作者:Alexey Dosovitskiy, Jost Tobias Springenberg, Thomas Brox
发表:CVPR, 2015.
论文:DRAW: A Recurrent Neural Network For Image Generation
作者:Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, Daan Wierstra
发表:ICML, 2015.
对抗网络
论文:生成对抗网络(Generative Adversarial Networks)
作者:Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
发表:NIPS, 2014.
论文:使用对抗网络Laplacian Pyramid 的深度生成图像模型(Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks)
作者:Emily Denton, Soumith Chintala, Arthur Szlam, Rob Fergus
发表:NIPS, 2015.
论文:生成模型演讲概述 (A note on the evaluation of generative models)
作者:Lucas Theis, Aäron van den Oord, Matthias Bethge
发表:ICLR 2016.
论文:变分自动编码深度高斯过程(Variationally Auto-Encoded Deep Gaussian Processes)
作者:Zhenwen Dai, Andreas Damianou, Javier Gonzalez, Neil Lawrence
发表:ICLR 2016.
论文:用注意力机制从字幕生成图像 (Generating Images from Captions with Attention)
作者:Elman Mansimov, Emilio Parisotto, Jimmy Ba, Ruslan Salakhutdinov
发表: ICLR 2016
论文:分类生成对抗网络的无监督和半监督学习(Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks)
作者:Jost Tobias Springenberg
发表:ICLR 2016
论文:用一个对抗检测表征(Censoring Representations with an Adversary)
作者:Harrison Edwards, Amos Storkey
发表:ICLR 2016
论文:虚拟对抗训练实现分布式顺滑 (Distributional Smoothing with Virtual Adversarial Training)
作者:Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, Ken Nakae, Shin Ishii
发表:ICLR 2016
论文:自然图像流形上的生成视觉操作(Generative Visual Manipulation on the Natural Image Manifold)
作者:朱俊彦, Philipp Krahenbuhl, Eli Shechtman, and Alexei A. Efros
发表: ECCV 2016.
论文:深度卷积生成对抗网络的无监督表示学习(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)
作者:Alec Radford, Luke Metz, Soumith Chintala
发表: ICLR 2016
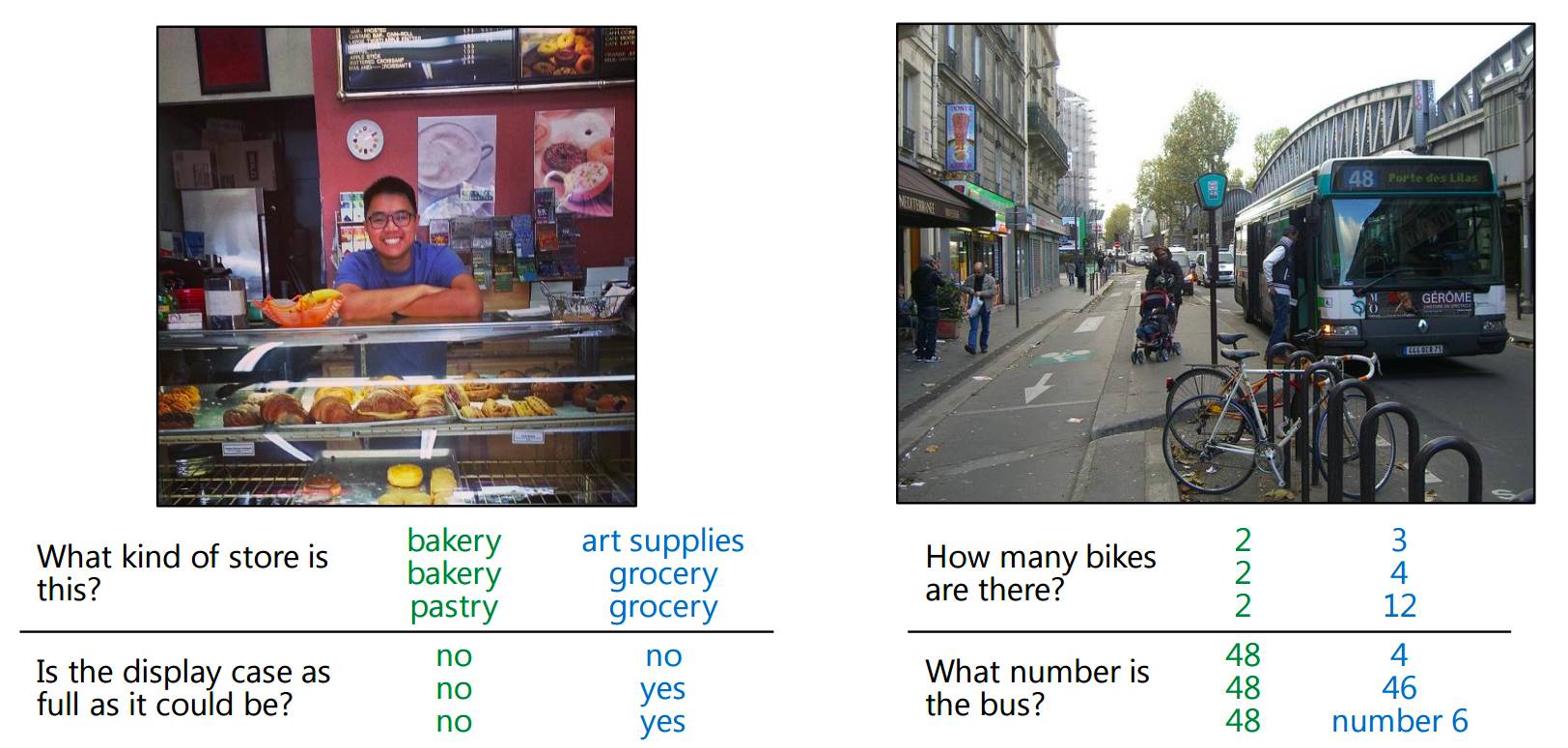
图:(from Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, VQA: Visual Question Answering, CVPR, 2015 SUNw:Scene Understanding workshop)
弗吉尼亚大学 / 微软研究院
论文:VQA: Visual Question Answering, CVPR, 2015 SUNw:Scene Understanding workshop.
作者:Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh
MPI / 伯克利
论文:Ask Your Neurons: A Neural-based Approach to Answering Questions about Images
作者:Mateusz Malinowski, Marcus Rohrbach, Mario Fritz,
发布 : arXiv:1505.01121.
多伦多
论文: Image Question Answering: A Visual Semantic Embedding Model and a New Dataset
作者:Mengye Ren, Ryan Kiros, Richard Zemel
发表: arXiv:1505.02074 / ICML 2015 deep learning workshop.
百度/ 加州大学洛杉矶分校
作者:Hauyuan Gao, Junhua Mao, Jie Zhou, Zhiheng Huang, Lei Wang, 徐伟
论文:Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering
发表: arXiv:1505.05612.
POSTECH(韩国)
论文:Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
作者:Hyeonwoo Noh, Paul Hongsuck Seo, and Bohyung Han
发表: arXiv:1511.05765
CMU / 微软研究院
论文:Stacked Attention Networks for Image Question Answering
作者:Yang, Z., He, X., Gao, J., Deng, L., & Smola, A. (2015)
发表: arXiv:1511.02274.
MetaMind
论文:Dynamic Memory Networks for Visual and Textual Question Answering
作者:Xiong, Caiming, Stephen Merity, and Richard Socher
发表: arXiv:1603.01417 (2016).
首尔国立大学 + NAVER
论文:Multimodal Residual Learning for Visual QA
作者:Jin-Hwa Kim, Sang-Woo Lee, Dong-Hyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhang
发表:arXiv:1606:01455
UC Berkeley + 索尼
论文:Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
作者:Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach
发表:arXiv:1606.01847
Postech
论文:Training Recurrent Answering Units with Joint Loss Minimization for VQA
作者:Hyeonwoo Noh and Bohyung Han
发表: arXiv:1606.03647
首尔国立大学 + NAVER
论文: Hadamard Product for Low-rank Bilinear Pooling
作者:Jin-Hwa Kim, Kyoung Woon On, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhan
发表:arXiv:1610.04325.

Mr-CNN
学习地标的连续搜索
视觉注意力机制实现多物体识别
视觉注意力机制的循环模型
论文:Predicting Eye Fixations using Convolutional Neural Networks
作者:Nian Liu, Junwei Han, Dingwen Zhang, Shifeng Wen, Tianming Liu
发表:CVPR, 2015.
作者:Learning a Sequential Search for Landmarks
论文:Saurabh Singh, Derek Hoiem, David Forsyth
发表:CVPR, 2015.
论文:Multiple Object Recognition with Visual Attention
作者:Jimmy Lei Ba, Volodymyr Mnih, Koray Kavukcuoglu,
发表:ICLR, 2015.
作者:Volodymyr Mnih, Nicolas Heess, Alex Graves, Koray Kavukcuoglu
论文:Recurrent Models of Visual Attention
发表:NIPS, 2014.
超分辨率
Iterative Image Reconstruction
Sven Behnke: Learning Iterative Image Reconstruction. IJCAI, 2001.
Sven Behnke: Learning Iterative Image Reconstruction in the Neural Abstraction Pyramid. International Journal of Computational Intelligence and Applications, vol. 1, no. 4, pp. 427-438, 2001.
Super-Resolution (SRCNN)
Chao Dong, Chen Change Loy, Kaiming He, Xiaoou Tang, Learning a Deep Convolutional Network for Image Super-Resolution, ECCV, 2014.
Chao Dong, Chen Change Loy, Kaiming He, Xiaoou Tang, Image Super-Resolution Using Deep Convolutional Networks, arXiv:1501.00092.
Very Deep Super-Resolution
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee, Accurate Image Super-Resolution Using Very Deep Convolutional Networks, arXiv:1511.04587, 2015.
Deeply-Recursive Convolutional Network
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee, Deeply-Recursive Convolutional Network for Image Super-Resolution, arXiv:1511.04491, 2015.
Casade-Sparse-Coding-Network
Zhaowen Wang, Ding Liu, Wei Han, Jianchao Yang and Thomas S. Huang, Deep Networks for Image Super-Resolution with Sparse Prior. ICCV, 2015.
Perceptual Losses for Super-Resolution
Justin Johnson, Alexandre Alahi, Li Fei-Fei, Perceptual Losses for Real-Time Style Transfer and Super-Resolution, arXiv:1603.08155, 2016.
SRGAN
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi, Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, arXiv:1609.04802v3, 2016.
其他应用
Optical Flow (FlowNet)
Philipp Fischer, Alexey Dosovitskiy, Eddy Ilg, Philip Häusser, Caner Hazırbaş, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, Thomas Brox, FlowNet: Learning Optical Flow with Convolutional Networks, arXiv:1504.06852.
Compression Artifacts Reduction
Chao Dong, Yubin Deng, Chen Change Loy, Xiaoou Tang, Compression Artifacts Reduction by a Deep Convolutional Network, arXiv:1504.06993.
Blur Removal
Christian J. Schuler, Michael Hirsch, Stefan Harmeling, Bernhard Schölkopf, Learning to Deblur, arXiv:1406.7444
Jian Sun, Wenfei Cao, Zongben Xu, Jean Ponce, Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal, CVPR, 2015
Image Deconvolution
Li Xu, Jimmy SJ. Ren, Ce Liu, Jiaya Jia, Deep Convolutional Neural Network for Image Deconvolution, NIPS, 2014.
Deep Edge-Aware Filter
Li Xu, Jimmy SJ. Ren, Qiong Yan, Renjie Liao, Jiaya Jia, Deep Edge-Aware Filters, ICML, 2015.
Computing the Stereo Matching Cost with a Convolutional Neural Network
Jure Žbontar, Yann LeCun, Computing the Stereo Matching Cost with a Convolutional Neural Network, CVPR, 2015.
Colorful Image Colorization Richard Zhang, Phillip Isola, Alexei A. Efros, ECCV, 2016
Feature Learning by Inpainting
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, Alexei A. Efros, Context Encoders: Feature Learning by Inpainting, CVPR, 2016

Holistically-Nested Edge Detection
Saining Xie, Zhuowen Tu, Holistically-Nested Edge Detection, arXiv:1504.06375.
DeepEdge
Gedas Bertasius, Jianbo Shi, Lorenzo Torresani, DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection, CVPR, 2015.
DeepContour
Wei Shen, Xinggang Wang, Yan Wang, Xiang Bai, Zhijiang Zhang, DeepContour: A Deep Convolutional Feature Learned by Positive-Sharing Loss for Contour Detection, CVPR, 2015.

图片来源:BoxSup论文
SEC: Seed, Expand and Constrain
Alexander Kolesnikov, Christoph Lampert, Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation, ECCV, 2016.
Adelaide
Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel, Efficient piecewise training of deep structured models for semantic segmentation, arXiv:1504.01013. (1st ranked in VOC2012)
Guosheng Lin, Chunhua Shen, Ian Reid, Anton van den Hengel, Deeply Learning the Messages in Message Passing Inference, arXiv:1508.02108. (4th ranked in VOC2012)
Deep Parsing Network (DPN)
Ziwei Liu, Xiaoxiao Li, Ping Luo, Chen Change Loy, Xiaoou Tang, Semantic Image Segmentation via Deep Parsing Network, arXiv:1509.02634 / ICCV 2015 (2nd ranked in VOC 2012)
CentraleSuperBoundaries, INRIA
Iasonas Kokkinos, Surpassing Humans in Boundary Detection using Deep Learning, arXiv:1411.07386 (4th ranked in VOC 2012)
BoxSup
Jifeng Dai, Kaiming He, Jian Sun, BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation, arXiv:1503.01640. (6th ranked in VOC2012)
POSTECH
Hyeonwoo Noh, Seunghoon Hong, Bohyung Han, Learning Deconvolution Network for Semantic Segmentation, arXiv:1505.04366. (7th ranked in VOC2012)
Seunghoon Hong, Hyeonwoo Noh, Bohyung Han, Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation, arXiv:1506.04924.
Seunghoon Hong,Junhyuk Oh, Bohyung Han, and Honglak Lee, Learning Transferrable Knowledge for Semantic Segmentation with Deep Convolutional Neural Network, arXiv:1512.07928
Conditional Random Fields as Recurrent Neural Networks
Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, Philip H. S. Torr, Conditional Random Fields as Recurrent Neural Networks, arXiv:1502.03240. (8th ranked in VOC2012)
DeepLab
Liang-Chieh Chen, George Papandreou, Kevin Murphy, Alan L. Yuille, Weakly-and semi-supervised learning of a DCNN for semantic image segmentation, arXiv:1502.02734. (9th ranked in VOC2012)
Zoom-out
Mohammadreza Mostajabi, Payman Yadollahpour, Gregory Shakhnarovich, Feedforward Semantic Segmentation With Zoom-Out Features, CVPR, 2015
Joint Calibration
Holger Caesar, Jasper Uijlings, Vittorio Ferrari, Joint Calibration for Semantic Segmentation, arXiv:1507.01581.
Fully Convolutional Networks for Semantic Segmentation
Jonathan Long, Evan Shelhamer, Trevor Darrell, Fully Convolutional Networks for Semantic Segmentation, CVPR, 2015.
Hypercolumn
Bharath Hariharan, Pablo Arbelaez, Ross Girshick, Jitendra Malik, Hypercolumns for Object Segmentation and Fine-Grained Localization, CVPR, 2015.
Deep Hierarchical Parsing
Abhishek Sharma, Oncel Tuzel, David W. Jacobs, Deep Hierarchical Parsing for Semantic Segmentation, CVPR, 2015.
Learning Hierarchical Features for Scene Labeling
Clement Farabet, Camille Couprie, Laurent Najman, Yann LeCun, Scene Parsing with Multiscale Feature Learning, Purity Trees, and Optimal Covers, ICML, 2012.
Clement Farabet, Camille Couprie, Laurent Najman, Yann LeCun, Learning Hierarchical Features for Scene Labeling, PAMI, 2013.
University of Cambridge
Vijay Badrinarayanan, Alex Kendall and Roberto Cipolla "SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." arXiv preprint arXiv:1511.00561, 2015.
Alex Kendall, Vijay Badrinarayanan and Roberto Cipolla "Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding." arXiv preprint arXiv:1511.02680, 2015.
Princeton
Fisher Yu, Vladlen Koltun, "Multi-Scale Context Aggregation by Dilated Convolutions", ICLR 2016
Univ. of Washington, Allen AI
Hamid Izadinia, Fereshteh Sadeghi, Santosh Kumar Divvala, Yejin Choi, Ali Farhadi, "Segment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing", ICCV, 2015
INRIA
Iasonas Kokkinos, "Pusing the Boundaries of Boundary Detection Using deep Learning", ICLR 2016
UCSB
Niloufar Pourian, S. Karthikeyan, and B.S. Manjunath, "Weakly supervised graph based semantic segmentation by learning communities of image-parts", ICCV, 2015
课程
• 深度视觉
[斯坦福] CS231n: Convolutional Neural Networks for Visual Recognition
[香港中文大学] ELEG 5040: Advanced Topics in Signal Processing(Introduction to Deep Learning)
• 更多深度课程推荐
[斯坦福] CS224d: Deep Learning for Natural Language Processing
[牛津 Deep Learning by Prof. Nando de Freitas
[纽约大学] Deep Learning by Prof. Yann LeCun
图书
免费在线图书
◦ Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
◦ Neural Networks and Deep Learning by Michael Nielsen
◦ Deep Learning Tutorial by LISA lab, University of Montreal
视频
演讲
◦ Deep Learning, Self-Taught Learning and Unsupervised Feature Learning By Andrew Ng
◦ Recent Developments in Deep Learning By Geoff Hinton
◦ The Unreasonable Effectiveness of Deep Learning by Yann LeCun
◦ Deep Learning of Representations by Yoshua bengio
软件
框架
• Tensorflow: An open source software library for numerical computation using data flow graph by Google [Web]
• Torch7: Deep learning library in Lua, used by Facebook and Google Deepmind [Web]
◦ Torch-based deep learning libraries: [torchnet],
• Caffe: Deep learning framework by the BVLC [Web]
• Theano: Mathematical library in Python, maintained by LISA lab [Web]
◦ Theano-based deep learning libraries: [Pylearn2], [Blocks], [Keras], [Lasagne]
• MatConvNet: CNNs for MATLAB [Web]
• MXNet: A flexible and efficient deep learning library for heterogeneous distributed systems with multi-language support [Web]
• Deepgaze: A computer vision library for human-computer interaction based on CNNs [Web]
应用
• 对抗训练 Code and hyperparameters for the paper "Generative Adversarial Networks" [Web]
• 理解与可视化 Source code for "Understanding Deep Image Representations by Inverting Them," CVPR, 2015. [Web]
• 词义分割 Source code for the paper "Rich feature hierarchies for accurate object detection and semantic segmentation," CVPR, 2014. [Web] ; Source code for the paper "Fully Convolutional Networks for Semantic Segmentation," CVPR, 2015. [Web]
• 超分辨率 Image Super-Resolution for Anime-Style-Art [Web]
• 边缘检测 Source code for the paper "DeepContour: A Deep Convolutional Feature Learned by Positive-Sharing Loss for Contour Detection," CVPR, 2015. [Web]
;Source code for the paper "Holistically-Nested Edge Detection", ICCV 2015. [Web]
讲座
• [CVPR 2014] Tutorial on Deep Learning in Computer Vision
• [CVPR 2015] Applied Deep Learning for Computer Vision with Torch
博客
• Deep down the rabbit hole: CVPR 2015 and beyond@Tombone's Computer Vision Blog
• CVPR recap and where we're going@Zoya Bylinskii (MIT PhD Student)'s Blog
• Facebook's AI Painting@Wired
• Inceptionism: Going Deeper into Neural Networks@Google Research
• Implementing Neural networks
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~





