【专知-Java Deeplearning4j深度学习教程05】无监督特征提取神器—AutoEncoder:图文+代码
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。继Pytorch教程后,我们推出面向Java程序员的深度学习教程DeepLearning4J。Deeplearning4j的案例和资料很少,官方的doc文件也非常简陋,基本上所有的类和函数的都没有解释。为此,我们推出来自中科院自动化所专知小组博士生Hujun与Sanglei创作的-分布式Java开源深度学习框架Deeplearning4j学习教程,第五篇,无监督特征提取神器—AutoEncoder。
使用多层神经网络分类MNIST数据集
使用CNN进行文本分类:图文+代码
基于DL4J的AutoEncoder、RNN、Word2Vec等模型的实现
特征提取
对很多机器学习/数据挖掘任务来说,选取或设计优质的的特征比设计一个好的分类器显得更为重要,然而优质特征的设计往往需要耗费大量的时间。深度学习包含了许多优质的无监督的特征自动提取算法,可以自动化地从原始特征(例如图像像素向量、文本词频向量等)中提取优质的特征,大大地节约了特征设计的成本,收到工业界的青睐。本文介绍一种无监督学习特征的模型——AutoEncoder,并提供DL4J实现AutoEncoder的代码。
特征提取示例
Iris是一个经典的数据集,数据由150个样本组成,包含3个类别的样本(3种标签),每个样本由4个特征和1个标签组成。例如数据的前几行如下所示,数据的前4列分别表示样本的4个特征,最后一列Iris-setosa是样本的标签,即样本的所属类别,是分类器需要预测的标签。
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
Iris数据集的下载地址为https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data。可以看出,很难人工设计一个区分这三种花。将Iris数据集可视化之后如下图所示,每个小图表示从某2个维度(一个维度对应一种特征)去观察Iris得到的结果,可以看出该数据集在一些小图中是线性可分的(任选两类样本,可以用一条直线去大致分隔这两类样本)。
但依赖可视化的方法是不可行的,Iris数据集只有4个特征和150个样本,如果换成MNIST数据集,则有784个特征,会产生613872张小图。另外,大部分情况下不是选取2个特征进行线性组合就可以获得优质特征的,而是需要多个特征做复杂的数学运算才可以得到优质的特征,因此,需要其他的方法来解决设计优质特征的问题。
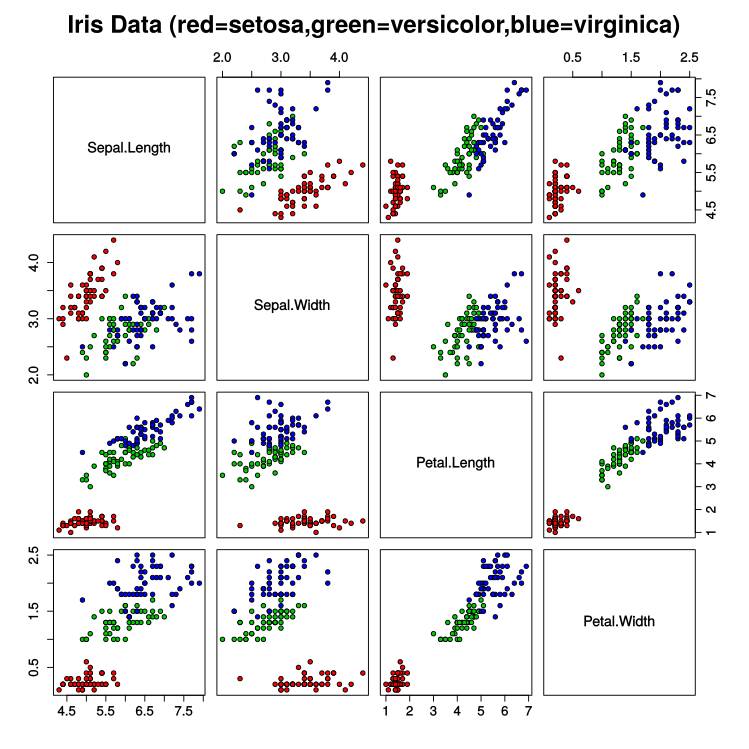
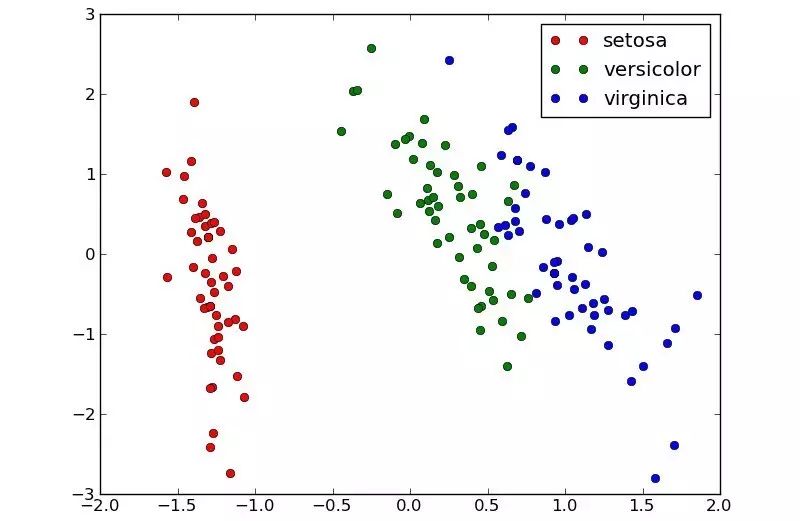
PCA(主成分分析)是一种传统的学习特征的方法。PCA可以将Iris数据集的4个特征变换为2个新的特征,2个新特征的可视化如下图所示,可以看到,学到的特征是线性可分的,可直接用于分类。下面,我们将介绍深度学习中一个简单粗暴的特征学习神器——AutoEncoder。
AutoEncoder
AutoEncoder其实就是一个3层神经网络,由1个输入层、1个隐藏层和1个输出层构成(如下图所示)。AutoEncoder用网络的输入数据作为Label,即希望网络的输出层输出和输入层一样的东西。如果将整个网络看作一个函数,这个函数为hW,b(x)≈x,其中x表示网络的输入(例如对于Iris数据集来说,x是一个4维向量,代表某个样本的4个特征)。AutoEncoder训练成功后,输入一个样本的特征,隐藏层的激活值即为学习到的该样本的新特征。
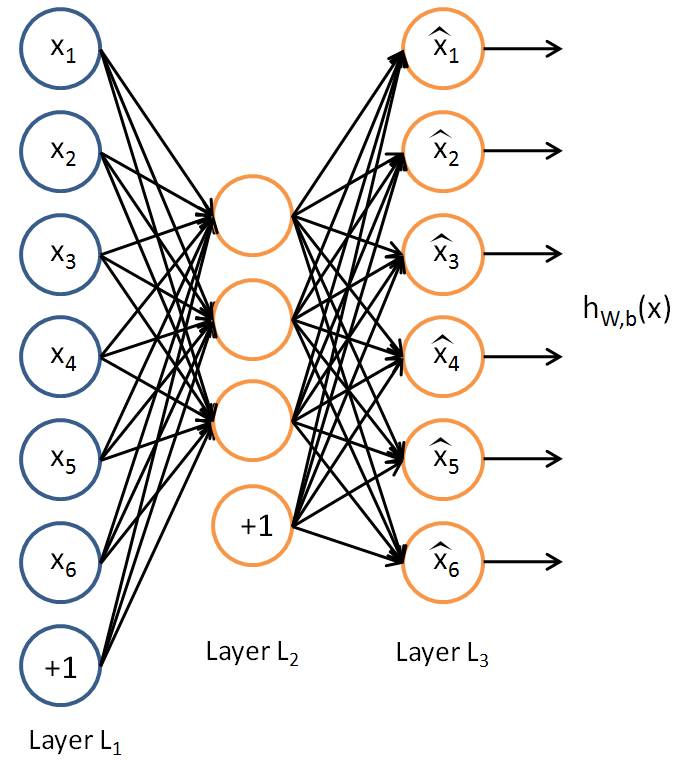
直观地理解为什么AutoEncoder为什么可以学习到特征,数据从AutoEncoder的输入层到输出层会经过两次变换,第一次将输入数据变换为隐藏层的激活值,第二次将隐藏层的激活值变换为输出层(即还原为输入),如果可以成功地还原输入数据,则说明隐藏层的激活值包含了输入层所有的信息(严格地说,是隐藏层的激活值加上AutoEncoder的网络参数包含了输入层的所有信息,但网络参数是所有样本共享的,因此在网络参数固定的情况下,可以认为隐藏层的激活值等价于其对应的输入数据)。
下面给出Deeplearning4j实现AutoEncoder的代码,有几个需要注意的地方:
除了DL4J所需的基础库,还需要导入JMathPlot的Maven依赖:https://mvnrepository.com/artifact/com.github.yannrichet/JMathPlot
由于AutoEncoder需要还原数据,且输出层的激活值大小有范围(例如tanh的大小范围是(-1,1)),因此在代码中设置了数据的归一化。
import org.deeplearning4j.datasets.iterator.impl.IrisDataSetIterator;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.math.plot.Plot2DPanel;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.NormalizerMinMaxScaler;
import org.nd4j.linalg.lossfunctions.LossFunctions.LossFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.swing.*;
import java.awt.*;
import java.util.List;
/**
*
* 本教程由专知提供:http://www.zhuanzhi.ai/
*
* 本教程演示如何用Deeplearning4j构建AutoEncoder
* 除了DL4J所需的基础库,还需要导入JMathPlot的Maven依赖:
* https://mvnrepository.com/artifact/com.github.yannrichet/JMathPlot
*
* 本教程用DL4J在Iris数据集上学习AutoEncoder
* 将Iris数据集的4维的原始特征变换为2维的优质特征
* 最后用JMathPlot绘制学习到的特征
*
* @author hu
*/
public class AutoEncoderExample {
private static Logger log = LoggerFactory.getLogger(AutoEncoderExample.class);
public static void main(String[] args) throws Exception {
int inputDim = 4; // 输入数据维度,即原始特征数量
final int hiddenDim = 2; //隐藏层维度,即学习到的特征的维度
int batchSize = 150; // 这里用整个数据集的大小作为batchSize
int rngSeed = 123; // 随机种子,保证每次运行程序获得同样的结果
int numEpochs = 1000; // epoch数量,扫描一遍数据集为一个epoch
//用DL4J自带的Iris数据集
DataSetIterator irisDataSet = new IrisDataSetIterator(batchSize, 150);
//将Iris数据集归一化到-1和1之间
//本示例用tanh激活输出层,所以用-1到1
DataNormalization norm = new NormalizerMinMaxScaler(-1,1);
norm.fit(irisDataSet);
irisDataSet.setPreProcessor(norm);
log.info("Build model....");
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(rngSeed) //设置随机种子,保证每次运行程序获得同样的结果
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.iterations(1)
.learningRate(3e-2) //学习速率
.regularization(true).l2(1e-4)
.list()
//构建Encoder
.layer(0, new DenseLayer.Builder()
.nIn(inputDim)
.nOut(hiddenDim)
.activation(Activation.TANH)
.build())
//构建Decoder
.layer(1, new OutputLayer.Builder(LossFunction.MSE)
.nIn(hiddenDim)
.nOut(inputDim)
.activation(Activation.TANH)
.build())
.pretrain(false).backprop(true)
.build();
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
//每50个Iteration就print一次score
model.setListeners(new ScoreIterationListener(50));
log.info("Train model....");
//训练
for( int i=0; i<numEpochs; i++ ){
irisDataSet.reset();
while(irisDataSet.hasNext()){
INDArray inputs = irisDataSet.next().getFeatures();
//将网络的输入和Label都设置为样本原始特征
model.fit(inputs, inputs);
}
}
log.info("Plot learned features....");
irisDataSet.reset();
//取一个batch的数据,这里batchSize为数据集大小
//因此这里会取出所有的数据
DataSet plotDataSet = irisDataSet.next();
//获取原始特征
INDArray inputs = plotDataSet.getFeatures();
//前向传播到第0层(即隐藏层)
//返回的是一个数组,数组包含前向传播到指定层所经过的所有层的激活值(包括指定层)
List<INDArray> activationList = model.feedForwardToLayer(0,inputs,false);
//取出数组中的最后一层激活值(也就是隐藏层的激活值)
INDArray features = activationList.get(activationList.size() - 1);
//取出原始数据的Label,原始数据的Label用one hot格式,因此需要用argMax(1)将其转换为普通数值Label
INDArray labels = plotDataSet.getLabels().argMax(1);
//使用JMathPlot绘制特征2D图
//用2个坐标轴表示学习到的特征的2个维度
//用颜色表示样本的类别
Plot2DPanel plot = new Plot2DPanel();
Color[] colors = new Color[]{Color.red, Color.green, Color.blue};
for(int i = 0;i<features.shape()[0];i++){
Color color = colors[labels.getInt(i)];
double x = features.getDouble(i,0);
double y = features.getDouble(i,1);
plot.addScatterPlot("iris", color,new double[]{x},new double[]{y});
}
//将JMathPlot嵌套在JFrame里展示
JFrame frame = new JFrame("a plot panel");
frame.setBounds(200,200,800,800);
frame.setContentPane(plot);
frame.setVisible(true);
}
}
运行结果:
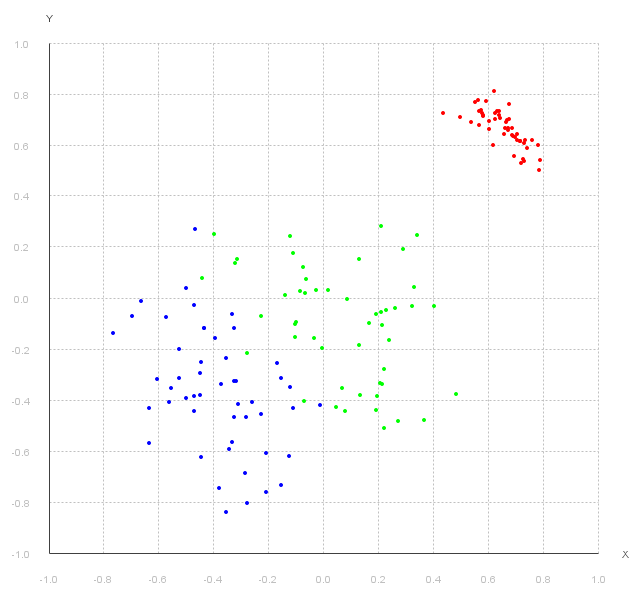
请登录www.zhuanzhi.ai,
搜索“DeepLearning4j”,查看获得代码。
明天请继续关注“DeepLearning4j”教程。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“DeepLearning4j”即可得。
对DeepLearning4j教程感兴趣的同学,欢迎进入我们的专知DeepLearning4j主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

如果群满,请扫描小助手,加入进群~

了解使用专知-获取更多AI知识!
阅读更多专知干货:
【干货】RL-GAN For NLP: 强化学习在生成对抗网络文本生成中扮演的角色
欢迎转发分享到微信群和朋友圈!

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



