【论文推荐】最新九篇目标检测相关论文—混合区域嵌入、FSSD、尺度不敏感、图像篡改检测、对抗实例、条件生成模型
【导读】专知内容组整理了最近九篇目标检测(Object Detection)相关文章,为大家进行介绍,欢迎查看!
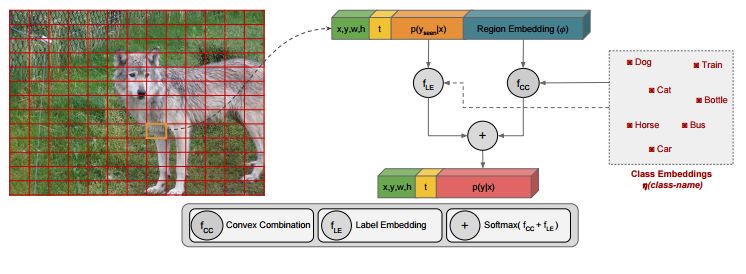
1.Zero-Shot Object Detection by Hybrid Region Embedding(由混合区域嵌入的Zero-Shot目标检测)
作者:Berkan Demirel,Ramazan Gokberk Cinbis,Nazli Ikizler-Cinbis
机构:Middle East Technical University,Hacettepe University
摘要:Object detection is considered as one of the most challenging problems in computer vision, since it requires correct prediction of both classes and locations of objects in images. In this study, we define a more difficult scenario, namely zero-shot object detection (ZSD) where no visual training data is available for some of the target object classes. We present a novel approach to tackle this ZSD problem, where a convex combination of embeddings are used in conjunction with a detection framework. For evaluation of ZSD methods, we propose a simple dataset constructed from Fashion-MNIST images and also a custom zero-shot split for the Pascal VOC detection challenge. The experimental results suggest that our method yields promising results for ZSD.
期刊:arXiv, 2018年5月17日
网址:
http://www.zhuanzhi.ai/document/d97099124f1e6662c11549385a9d0b93
2.FSSD: Feature Fusion Single Shot Multibox Detector(FSSD:特征融合Single Shot Multibox检测器)
作者:Zuoxin Li,Fuqiang Zhou
机构:Beihang University
摘要:SSD (Single Shot Multibox Detector) is one of the best object detection algorithms with both high accuracy and fast speed. However, SSD's feature pyramid detection method makes it hard to fuse the features from different scales. In this paper, we proposed FSSD (Feature Fusion Single Shot Multibox Detector), an enhanced SSD with a novel and lightweight feature fusion module which can improve the performance significantly over SSD with just a little speed drop. In the feature fusion module, features from different layers with different scales are concatenated together, followed by some down-sampling blocks to generate new feature pyramid, which will be fed to multibox detectors to predict the final detection results. On the Pascal VOC 2007 test, our network can achieve 82.7 mAP (mean average precision) at the speed of 65.8 FPS (frame per second) with the input size 300$\times$300 using a single Nvidia 1080Ti GPU. In addition, our result on COCO is also better than the conventional SSD with a large margin. Our FSSD outperforms a lot of state-of-the-art object detection algorithms in both aspects of accuracy and speed. Code is available at https://github.com/lzx1413/CAFFE_SSD/tree/fssd.
期刊:arXiv, 2018年5月17日
网址:
http://www.zhuanzhi.ai/document/bf33853afa77109998116d9c70577e52
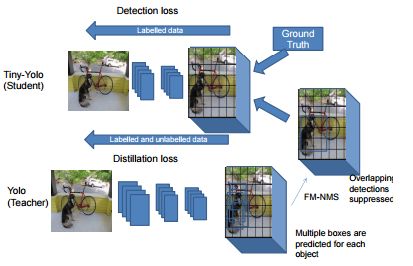
3.Object detection at 200 Frames Per Second (目标检测每秒200帧)
作者:Rakesh Mehta,Cemalettin Ozturk
摘要:In this paper, we propose an efficient and fast object detector which can process hundreds of frames per second. To achieve this goal we investigate three main aspects of the object detection framework: network architecture, loss function and training data (labeled and unlabeled). In order to obtain compact network architecture, we introduce various improvements, based on recent work, to develop an architecture which is computationally light-weight and achieves a reasonable performance. To further improve the performance, while keeping the complexity same, we utilize distillation loss function. Using distillation loss we transfer the knowledge of a more accurate teacher network to proposed light-weight student network. We propose various innovations to make distillation efficient for the proposed one stage detector pipeline: objectness scaled distillation loss, feature map non-maximal suppression and a single unified distillation loss function for detection. Finally, building upon the distillation loss, we explore how much can we push the performance by utilizing the unlabeled data. We train our model with unlabeled data using the soft labels of the teacher network. Our final network consists of 10x fewer parameters than the VGG based object detection network and it achieves a speed of more than 200 FPS and proposed changes improve the detection accuracy by 14 mAP over the baseline on Pascal dataset.
期刊:arXiv, 2018年5月16日
网址:
http://www.zhuanzhi.ai/document/7e08442ed3e5c3c39e2d7d6ff8244760
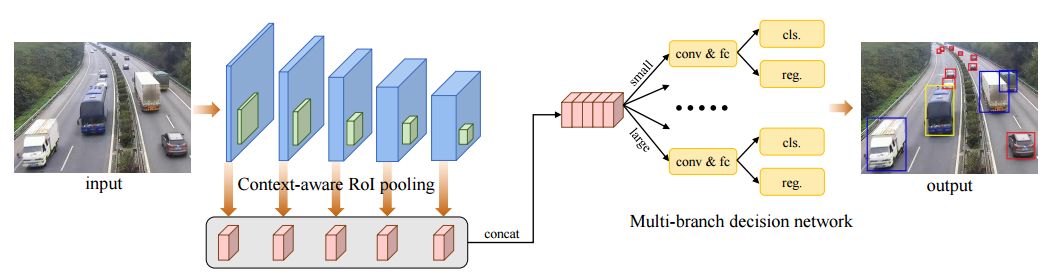
4.SINet: A Scale-insensitive Convolutional Neural Network for Fast Vehicle Detection(SINet:基于尺度不敏感卷积神经网络的快速车辆检测)
作者:Xiaowei Hu,Xuemiao Xu,Yongjie Xiao,Hao Chen,Shengfeng He,Jing Qin,Pheng-Ann Heng
Accepted by IEEE Transactions on Intelligent Transportation Systems (T-ITS)
摘要:Vision-based vehicle detection approaches achieve incredible success in recent years with the development of deep convolutional neural network (CNN). However, existing CNN based algorithms suffer from the problem that the convolutional features are scale-sensitive in object detection task but it is common that traffic images and videos contain vehicles with a large variance of scales. In this paper, we delve into the source of scale sensitivity, and reveal two key issues: 1) existing RoI pooling destroys the structure of small scale objects, 2) the large intra-class distance for a large variance of scales exceeds the representation capability of a single network. Based on these findings, we present a scale-insensitive convolutional neural network (SINet) for fast detecting vehicles with a large variance of scales. First, we present a context-aware RoI pooling to maintain the contextual information and original structure of small scale objects. Second, we present a multi-branch decision network to minimize the intra-class distance of features. These lightweight techniques bring zero extra time complexity but prominent detection accuracy improvement. The proposed techniques can be equipped with any deep network architectures and keep them trained end-to-end. Our SINet achieves state-of-the-art performance in terms of accuracy and speed (up to 37 FPS) on the KITTI benchmark and a new highway dataset, which contains a large variance of scales and extremely small objects.
期刊:arXiv, 2018年5月16日
网址:
http://www.zhuanzhi.ai/document/8df1262f07efaeedd4f44b238b34eb13
5.Differentiating Objects by Motion: Joint Detection and Tracking of Small Flying Objects(通过运动区分物体:小型飞行物体的联合检测和跟踪)
作者:Ryota Yoshihashi,Tu Tuan Trinh,Rei Kawakami,Shaodi You,Makoto Iida,Takeshi Naemura
机构:The University of Tokyo,Australian National University
摘要:While generic object detection has achieved large improvements with rich feature hierarchies from deep nets, detecting small objects with poor visual cues remains challenging. Motion cues from multiple frames may be more informative for detecting such hard-to-distinguish objects in each frame. However, how to encode discriminative motion patterns, such as deformations and pose changes that characterize objects, has remained an open question. To learn them and thereby realize small object detection, we present a neural model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. A convolutional long short-term memory network is utilized for learning informative appearance change for detection, while learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on the bird dataset.

期刊:arXiv, 2018年5月15日
网址:
http://www.zhuanzhi.ai/document/7e7cf1b33409c25f68352d7df61d48a6
6.Learning Rich Features for Image Manipulation Detection(学习丰富特征进行图像篡改检测)
作者:Peng Zhou,Xintong Han,Vlad I. Morariu,Larry S. Davis
CVPR 2018 Camera Ready
机构:University of Maryland
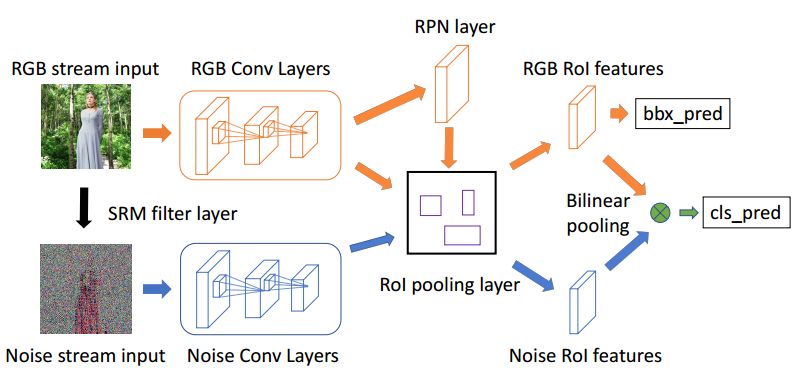
摘要:Image manipulation detection is different from traditional semantic object detection because it pays more attention to tampering artifacts than to image content, which suggests that richer features need to be learned. We propose a two-stream Faster R-CNN network and train it endto- end to detect the tampered regions given a manipulated image. One of the two streams is an RGB stream whose purpose is to extract features from the RGB image input to find tampering artifacts like strong contrast difference, unnatural tampered boundaries, and so on. The other is a noise stream that leverages the noise features extracted from a steganalysis rich model filter layer to discover the noise inconsistency between authentic and tampered regions. We then fuse features from the two streams through a bilinear pooling layer to further incorporate spatial co-occurrence of these two modalities. Experiments on four standard image manipulation datasets demonstrate that our two-stream framework outperforms each individual stream, and also achieves state-of-the-art performance compared to alternative methods with robustness to resizing and compression.
期刊:arXiv, 2018年5月14日
网址:
http://www.zhuanzhi.ai/document/1af8fc26a2179e87327366b8bb16ebe5
7.LMNet: Real-time Multiclass Object Detection on CPU using 3D LiDARs (LMNet:基于3D LiDARs的CPU实时多类目标检测)
作者:Kazuki Minemura,Hengfui Liau,Abraham Monrroy,Shinpei Kato
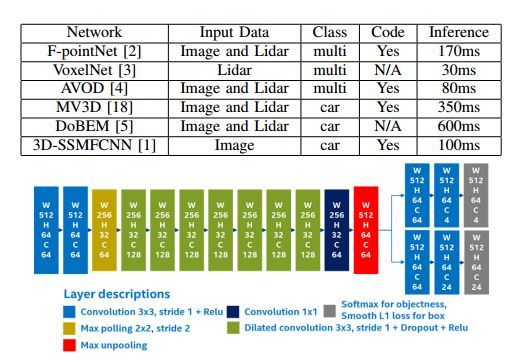
摘要:This paper describes an optimized single-stage deep convolutional neural network to detect objects in urban environments, using nothing more than point cloud data. This feature enables our method to work regardless the time of the day and the lighting conditions.The proposed network structure employs dilated convolutions to gradually increase the perceptive field as depth increases, this helps to reduce the computation time by about 30\%. The network input consists of five perspective representations of the unorganized point cloud data. The network outputs an objectness map and the bounding box offset values for each point. Our experiments showed that using reflection, range, and the position on each of the three axes helped to improve the location and orientation of the output bounding box. We carried out quantitative evaluations with the help of the KITTI dataset evaluation server. It achieved the fastest processing speed among the other contenders, making it suitable for real-time applications. We implemented and tested it on a real vehicle with a Velodyne HDL-64 mounted on top of it. We achieved execution times as fast as 50 FPS using desktop GPUs, and up to 10 FPS on a single Intel Core i5 CPU. The deploy implementation is open-sourced and it can be found as a feature branch inside the autonomous driving framework Autoware. Code is available at:
https://github.com/CPFL/Autoware/tree/feature/cnn_lidar_detection
期刊:arXiv, 2018年5月13日
网址:
http://www.zhuanzhi.ai/document/b7e0783651fa7fa95f51a4cbd2d67d13
8.Deceiving End-to-End Deep Learning Malware Detectors using Adversarial Examples (利用对抗实例欺骗基于端到端深度学习的恶意软件检测器)
作者:Felix Kreuk,Assi Barak,Shir Aviv-Reuven,Moran Baruch,Benny Pinkas,Joseph Keshet
机构:Bar-Ilan University
摘要:In recent years, deep learning has shown performance breakthroughs in many applications, such as image detection, image segmentation, pose estimation, and speech recognition. However, this comes with a major concern: deep networks have been found to be vulnerable to adversarial examples. Adversarial examples are slightly modified inputs that are intentionally designed to cause a misclassification by the model. In the domains of images and speech, the modifications are so small that they are not seen or heard by humans, but nevertheless greatly affect the classification of the model. Deep learning models have been successfully applied to malware detection. In this domain, generating adversarial examples is not straightforward, as small modifications to the bytes of the file could lead to significant changes in its functionality and validity. We introduce a novel loss function for generating adversarial examples specifically tailored for discrete input sets, such as executable bytes. We modify malicious binaries so that they would be detected as benign, while preserving their original functionality, by injecting a small sequence of bytes (payload) in the binary file. We applied this approach to an end-to-end convolutional deep learning malware detection model and show a high rate of detection evasion. Moreover, we show that our generated payload is robust enough to be transferable within different locations of the same file and across different files, and that its entropy is low and similar to that of benign data sections.
期刊:arXiv, 2018年5月13日
网址:
http://www.zhuanzhi.ai/document/90e6333ddce0984d7036e906473bbbc9
9.Stingray Detection of Aerial Images Using Augmented Training Images Generated by A Conditional Generative Model (利用由条件生成模型生成的增强训练图像对航空图像拍摄的黄貂鱼进行检测)
作者:Yi-Min Chou,Chein-Hung Chen,Keng-Hao Liu,Chu-Song Chen
to appear in CVPR 2018 Workshop (CVPR 2018 Workshop and Challenge: Automated Analysis of Marine Video for Environmental Monitoring)
机构:National Sun Yat-sen University
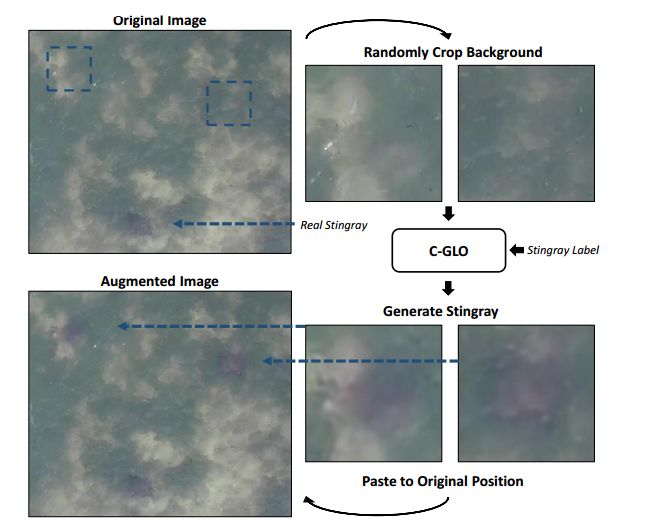
摘要:In this paper, we present an object detection method that tackles the stingray detection problem based on aerial images. In this problem, the images are aerially captured on a sea-surface area by using an Unmanned Aerial Vehicle (UAV), and the stingrays swimming under (but close to) the sea surface are the target we want to detect and locate. To this end, we use a deep object detection method, faster RCNN, to train a stingray detector based on a limited training set of images. To boost the performance, we develop a new generative approach, conditional GLO, to increase the training samples of stingray, which is an extension of the Generative Latent Optimization (GLO) approach. Unlike traditional data augmentation methods that generate new data only for image classification, our proposed method that mixes foreground and background together can generate new data for an object detection task, and thus improve the training efficacy of a CNN detector. Experimental results show that satisfiable performance can be obtained by using our approach on stingray detection in aerial images.
期刊:arXiv, 2018年5月11日
网址:
http://www.zhuanzhi.ai/document/b9a0e813a97144e371beba4900b8b260
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



