【深度学习最精炼中文讲义】前馈与卷积神经网络详解,复旦邱锡鹏老师《神经网络与深度学习》报告分享02(附报告pdf下载)
点击上方“专知”关注获取专业AI知识!
【导读】复旦大学副教授、博士生导师、开源自然语言处理工具FudanNLP的主要开发者邱锡鹏(http://nlp.fudan.edu.cn/xpqiu/)老师撰写的《神经网络与深度学习》书册,是国内为数不多的深度学习中文基础教程之一,每一章都是干货,非常精炼。邱老师在今年中国中文信息学会《前沿技术讲习班》做了题为《深度学习基础》的精彩报告,报告非常精彩,深入浅出地介绍了神经网络与深度学习的一系列相关知识,基本上围绕着邱老师的《神经网络与深度学习》一书进行讲解。专知希望把如此精华知识资料分发给更多AI从业者,为此,专知特别联系了邱老师,获得他的授权同意分享。邱老师特意做了最新更新版本,非常感谢邱老师!专知内容组围绕邱老师的讲义slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新神经网络与深度学习的slide。
既昨天给大家带来了复旦邱锡鹏老师《神经网络与深度学习》讲义报告分享01,今天继续为大家带来基础模型这一部分。
邱老师的报告内容分为三个部分:
概述
机器学习概述
线性模型
应用
基础模型
前馈神经网络
卷积神经网络
循环神经网络
网络优化与正则化
应用
进阶模型
记忆力与注意力机制
无监督学习
概率图模型
深度生成模型
深度强化学习
模型独立的学习方式
哈工大在事理图谱方面的探索
【特此注明】本报告材料获邱锡鹏老师授权发布,由于笔者能力有限,本篇所有备注皆为专知内容组成员通过根据报告记录和PPT内容自行补全,不代表邱锡鹏老师本人的立场与观点。
邱老师个人主页: http://nlp.fudan.edu.cn/xpqiu/
课程Github主页:https://nndl.github.io/
神经网络与深度学习

深度学习(Deep Learning, DL)是指如何从数据中学习一个“深度模型”的问题,是机器学习的一个子问题。通过构建具有一定“深度”的模型,可以让模型来自动学习好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测或识别的准确性。
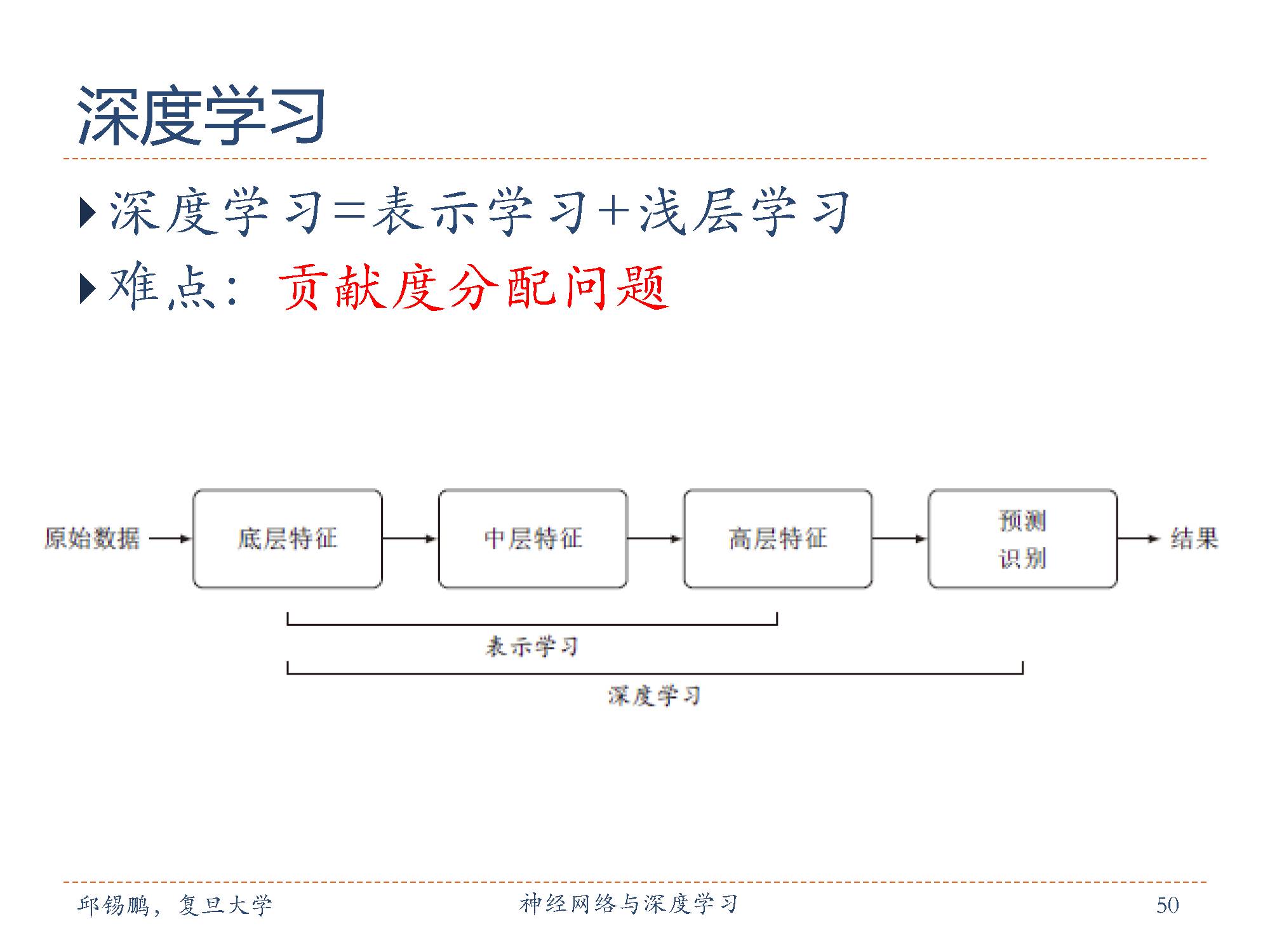
深度学习的主要目的是从数据中自动学习到有效的特征,即表示学习。
深度学习技术在一定程度上可以看作是一个表示学习技术,通过多层的非线性转换,把原始数据变成为更高层次、更抽象的表示。这些学习到的表示可以替代人工设计的特征,从避免“特征工程”。
传统机器学习模型主要关注于分类或预测,这类机器学习模型称为浅层模型,或浅层学习。浅层学习的一个重要特点是不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取。
因此深度学习可以等价于 表示学习+浅层学习 这两部分。
与“浅层”学习不同,深度学习需要解决的关键问题是贡献度分配问题(CreditAssignment Problem),即一个系统中不同的组件(Components)对最终系统输出结果的贡献或影响。
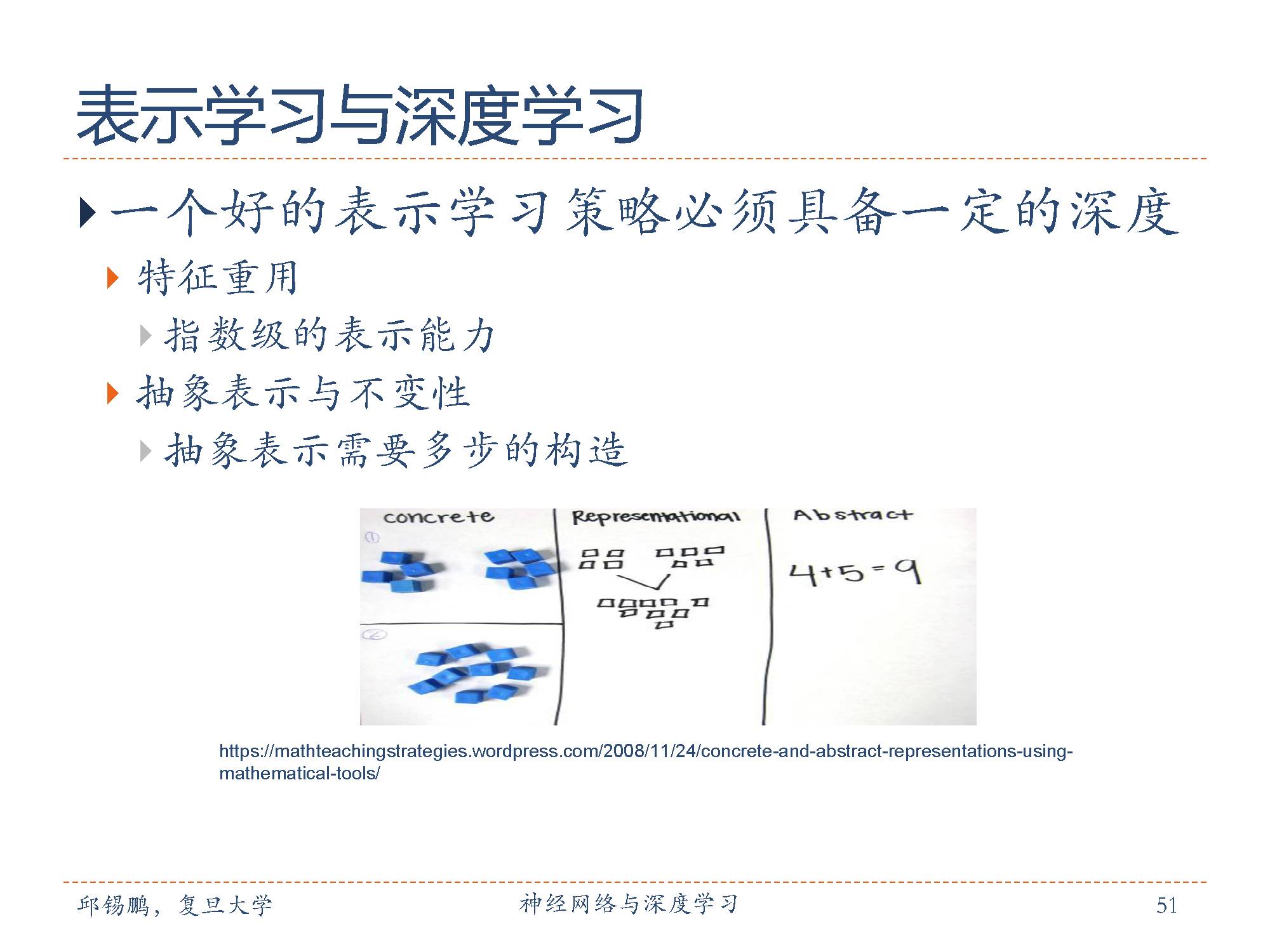
要提高一种表示方法的表示能力,其关键是构建具有一定深度的多层次特征表示。一个深层结构的优点是可以增加特征的重用性,从而指数级地增加表示能力。
此外,从底层特征开始,一般需要多步非线性转换才能得到较为抽象的高层语义特征。
因此,表示学习可以看作是一种深度学习。所谓“深度”是指原始数据进行非线性特征转换的次数。

下面开始介绍神经网络
这是最早是作为一种主要的连接主义模型。
连接主义的神经网络有着多种多样的网络结构以及学习方法,虽然早期模型强调模型的生物可解释性(biological plausibility),但后期更关注于对某种特定认知能力的模拟,比如物体识别、语言理解等。尤其在引入改进其学习能力之后,神经网络也越来越多地应用在各种模式识别任务上。随着训练数据的增多以及(并行)计算能力的增强,神经网络在很多模式识别任务上已经取得了很大的突破,特别是语音、图像等感知信号的处理上,表现出了卓越的学习能力。
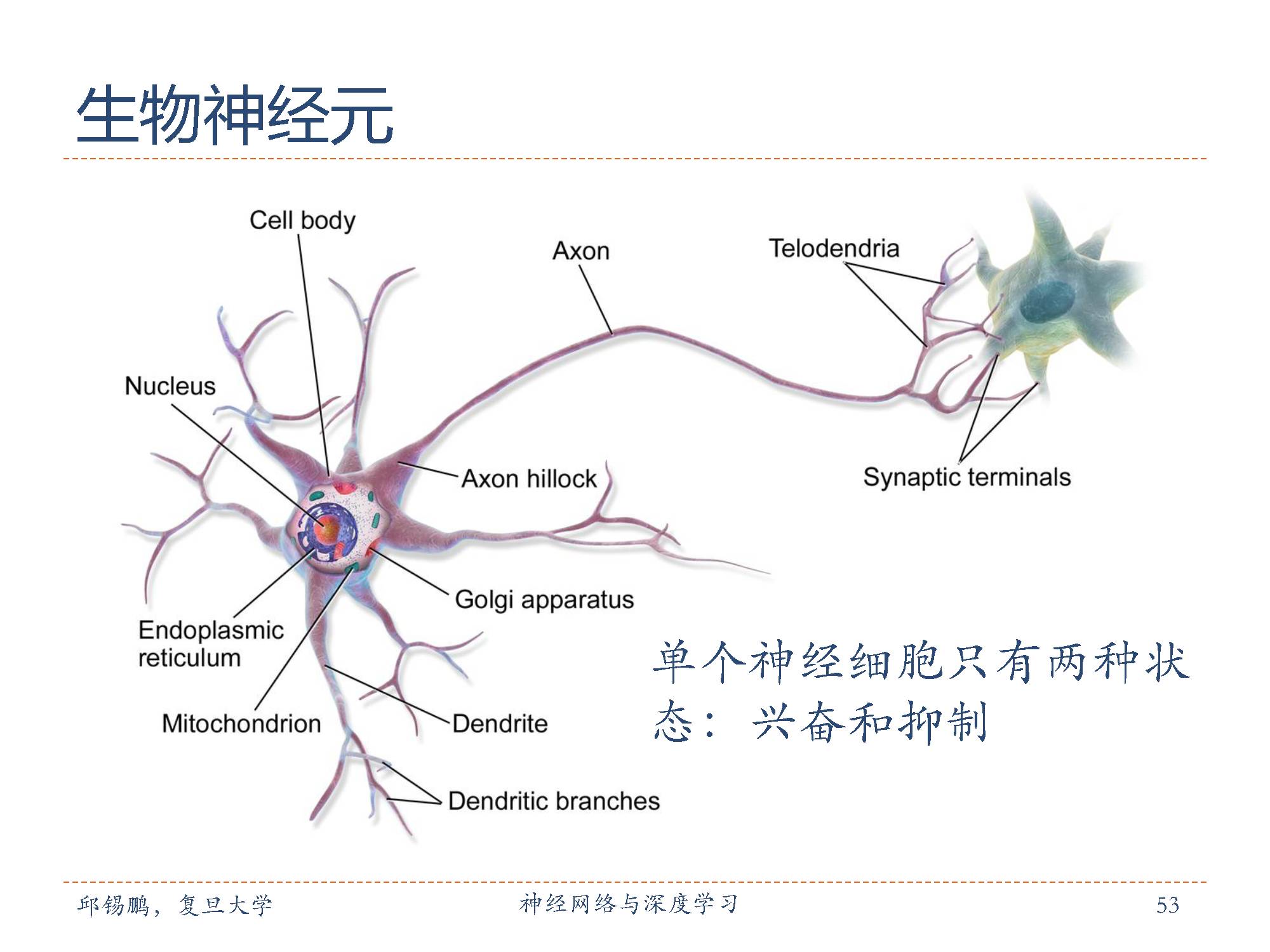
生物学家在20世纪初就发现了生物神经元的结构。一个生物神经元通常具有多个树突和一条轴突。树突用来接受信息,轴突用来发送信息。当神经元所获得的输入信号的积累超过某个阈值时,它就处于兴奋状态,产生电脉冲。轴突尾端有许多末梢可以给其他个神经元的树突产生连接(突触),并将电脉冲信号传递给其它神经元。
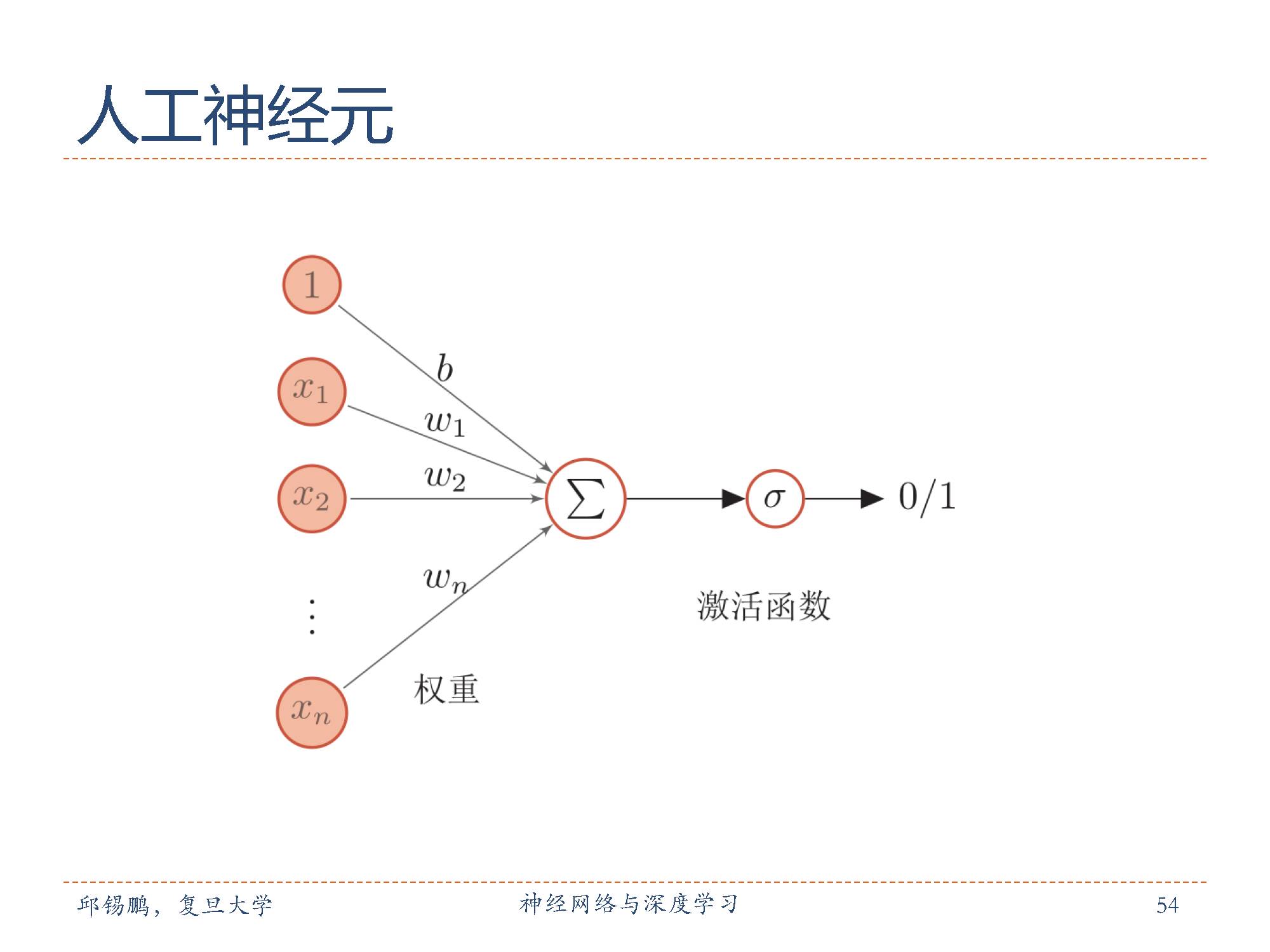
人工神经元(artificialneuron),简称神经元(neuron),是构成神经网络的基本单元,其主要是模拟生物神经元的结构和特性,接受一组输入信号并产出输出。
1943年,心理学家McCulloch和数学家Pitts根据生物神经元的结构,提出了一种非常简单的神经元模型。根据两位学者命名为M-P神经元,M-P神经元模型中,激活函数 f 为 0或 1的阶跃函数。

人工神经网络主要由大量的神经元以及他们之间的有向链接构成。主要需要考虑下面三个方面:
神经元的激活规则:为了增强网络的表达能力以及学习能力,一般使用连续非线性激活函数(activationfunction)。
网络的拓扑结构:不同神经元之间有其链接关系。
学习算法:通过训练数据来学习神经网络的参数。
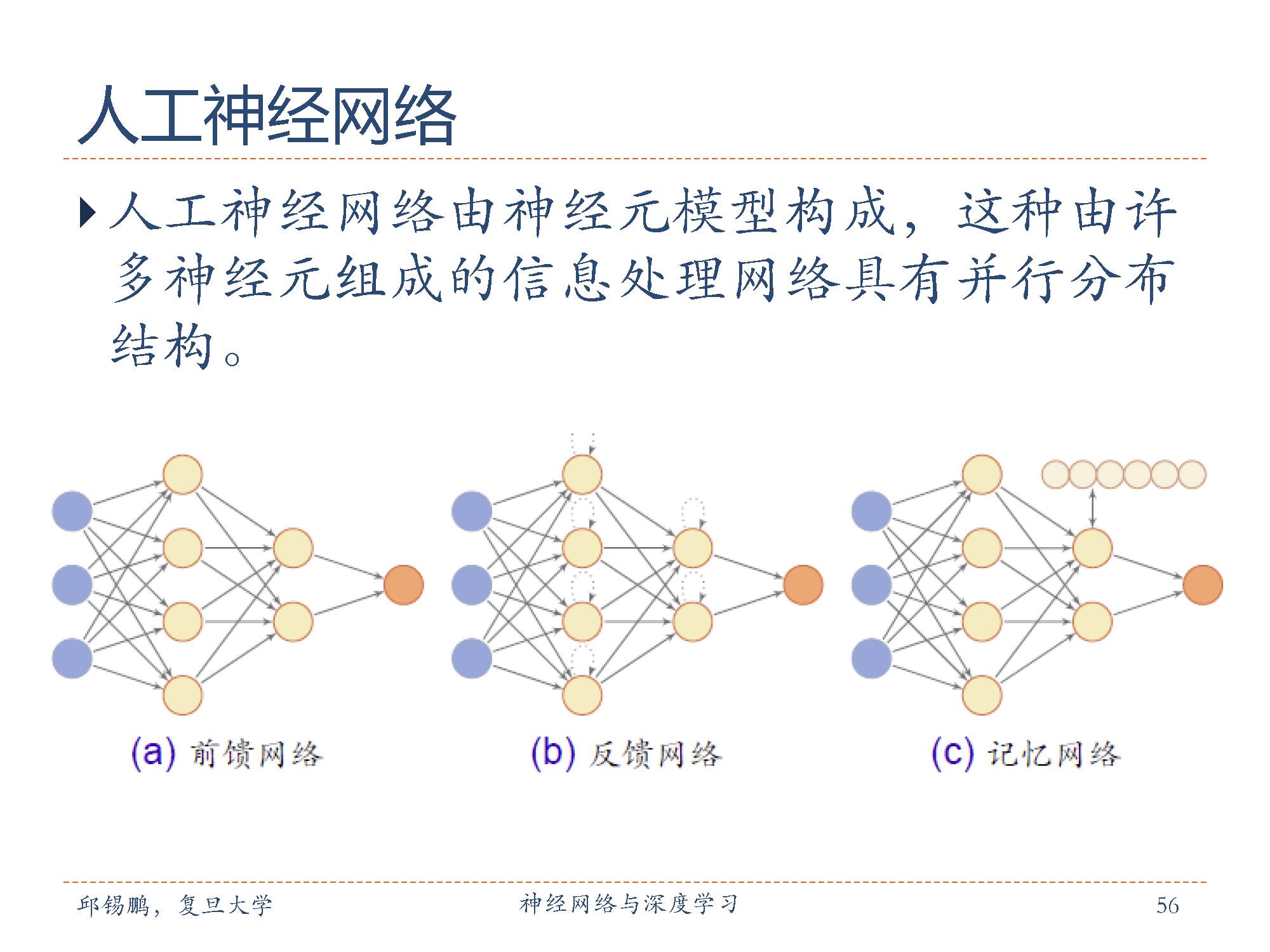
常用的神经网络结构包括前馈网络,反馈网络,记忆网络。
在前馈神经网络中,各神经元分别属于不同的层。每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层。第一层叫输入层,最后一层叫输出层,其它中间层叫做隐藏层。整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
反馈神经网络神经元不仅可以接收其他神经元的信号,也可以接收自己的反馈信号,可用一个完备的无向图表示。和前馈网络相比,反馈网络在不同时刻具有不同的状态,具有记忆功能,因此反馈网络可以看作一个程序,也具有更强的计算能力。主要采用Hebb学习规则,一般情况下计算的收敛速度很快。
记忆网络在前馈网络或反馈网络的基础上,引入一组记忆单元,用来保存中间状态。同时,根据一定的取址、读写机制,来增强网络能力。和反馈网络相比,记忆网络具有更强的记忆功能。

神经网络是重要的机器学习技术,是深度学习的基础。其要解决的问题是贡献度分配问题。
重要:深度学习天然不是神经网络,但神经网络天然是深度学习!

深层神经网络面临一系列的问题,包括参数过多、非凸优化问题、梯度消失问题、下层参数比较难调、参数难以解释问题。
其训练也需要更多的数据、更多的资源同时要有收敛性强的优化算法。

下面聊聊神经网络的简史。
第一阶段:(模型的提出1943年~1969年)
1943 年,传奇人物麦卡洛可(McCulloch)和皮茨(Pitts)就发表了模拟神经网络的原创文章。
1947 年图灵就已经阐述了如何对机器学习的结果进行检查的方法,而且这一方法是很有远见和可操作性的。1948年图灵在论文中描述了一种“B型图灵机”。
神经网络研究的另一个突破是在1958 年。康奈尔大学的实验心理学家弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704 计算机上模拟实现了一种他发明的叫作“感知机”(Perceptron)的神经网络模型。

第二阶段:(冰河期1969年~1983年)
1969年,Marvin Minsky出版《感知机》一书,并和Seymour Papert发现了神经网络中的两个重大缺陷:第一是基本感知机无法处理异或问题;第二,当时的计算机计算能力不足以用来处理大型神经网络,此后一段时间神经网络的研究一度停滞不前。
1974年哈佛大学博士Paul Werbos在博士论文中提出了用误差反向传导来训练人工神经网络有效地解决了异或回路问题,使训练多层神经网络成为可能,但是并未受到重视。

第三阶段:(复兴时期1983年~1995年)
1984年GeoffreyHinton提出 Boltzman机模型。
1986 年,鲁姆哈特(DavidRumelhart)和麦克莱兰(McCelland)等几名学者提出的BP 神经网络是神经网络发展史上的里程碑。
1986年, GeoffreyHinton等人将引入到多层感知器。
1989年, Yann LeCun在将反向传播算法引入了卷积神经网络,并在手写体数字识别上取得了很大的成功。

第四阶段:(流行度降低1995年~2006年)
支持向量机和其它更简单的算法(如线性分类器)的流行程度逐步超过了神经网络。
第五阶段:(崛起时期2006后)
2006年,Geoffrey Hinton 发表一篇文章,经过他改进的算法能够对七层或更多层的深度神经网络进行训练,这让计算机可以渐进地进行学习。随着层次的增加,学习的精确性得到提升,同时该技术还极大地推动了非监督学习的发展,让机器具备“自学”的能力。

在AI 领域,
语音识别:
在语音识别领域,深度学习用深层模型替换声学模型中的混合高斯模型(GaussianMixture Model, GMM),获得了相对30%左右的错误率降低;
图像识别:
在图像识别领域,通过构造深度卷积神经网络(CNN),将Top5错误率由26%大幅降低至15%,又通过加大加深网络结构,进一步降低到11%;
自然语言处理:
在自然语言处理领域,深度学习基本获得了与其他方法水平相当的结果,但可以免去繁琐的特征提取步骤。可以说到目前为止,深度学习是最接近人类大脑的智能学习方法。
在三个DEEP 中,Deep Blue, Deep QA , Deep Learning.
IBM 的深蓝Deep Blue 国际象棋系统在 1997 年击败了世界冠军 Garry Kasparov(Hsu, 2002)。
Deep QA系统是自动问答系统,要预先搜集各个领域的材料,其尝试去理解问题,搞清楚问题到底在问什么;同时做一些初步的分析来决定选择哪种方法来应对这个问题。
Deep Learning是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。

在深度学习领域,上面几个都是国际上比较知名的研究机构和学者。

下面开始介绍前馈神经网络
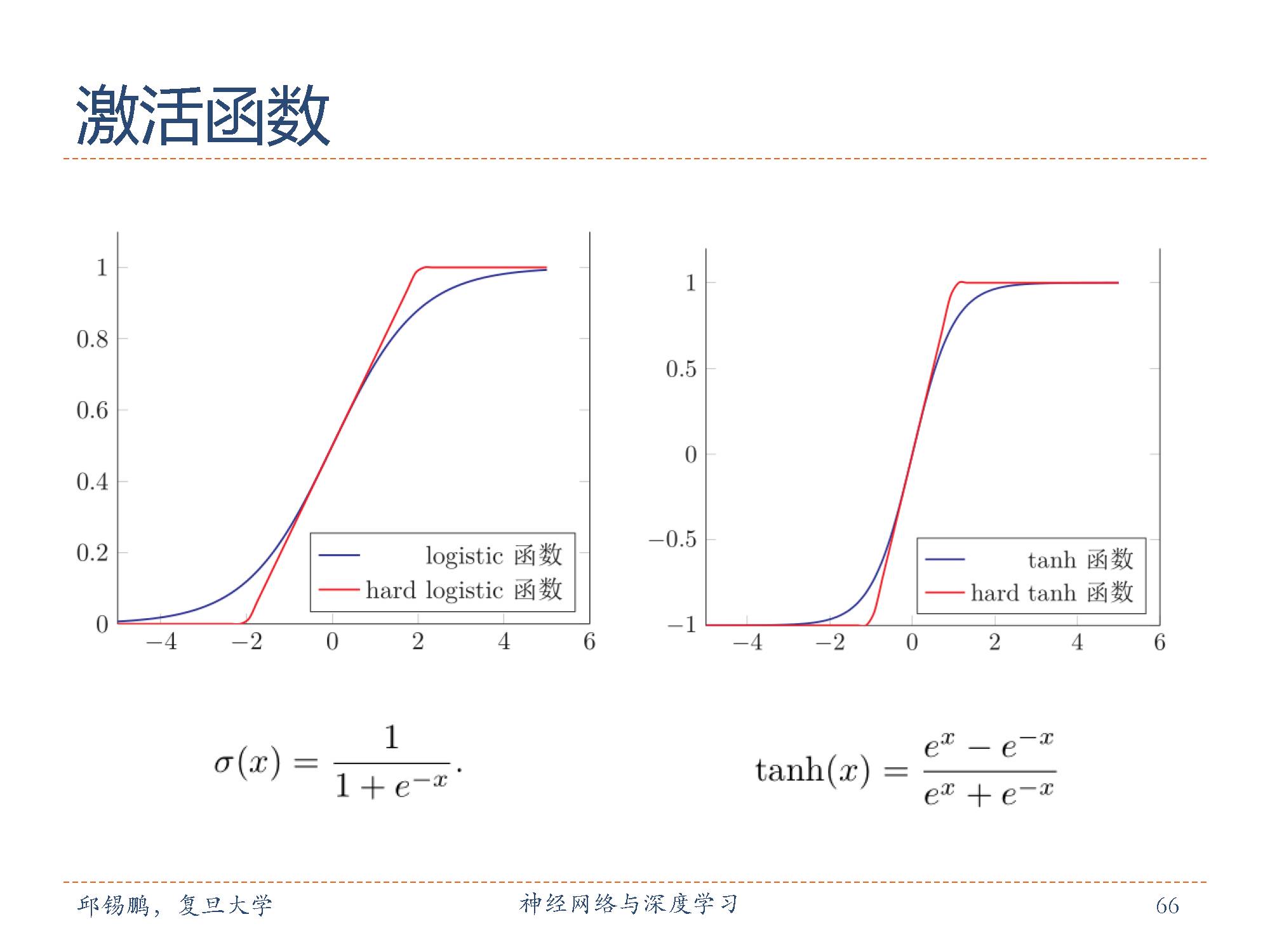
首先介绍一下激活函数,
为了增强网络的表达能力以及学习能力,一般使用连续非线性激活函数(activationfunction)。因为连续非线性激活函数可导,所以可以用最优化的方法来学习网络参数。
左图是Logistic 函数, Logistic函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压”到 (0, 1)。当输入值在 0附近时, sigmoid型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制。输入越小,越接近于 0;输入越大,越接近于 1。
右图是tanh函数
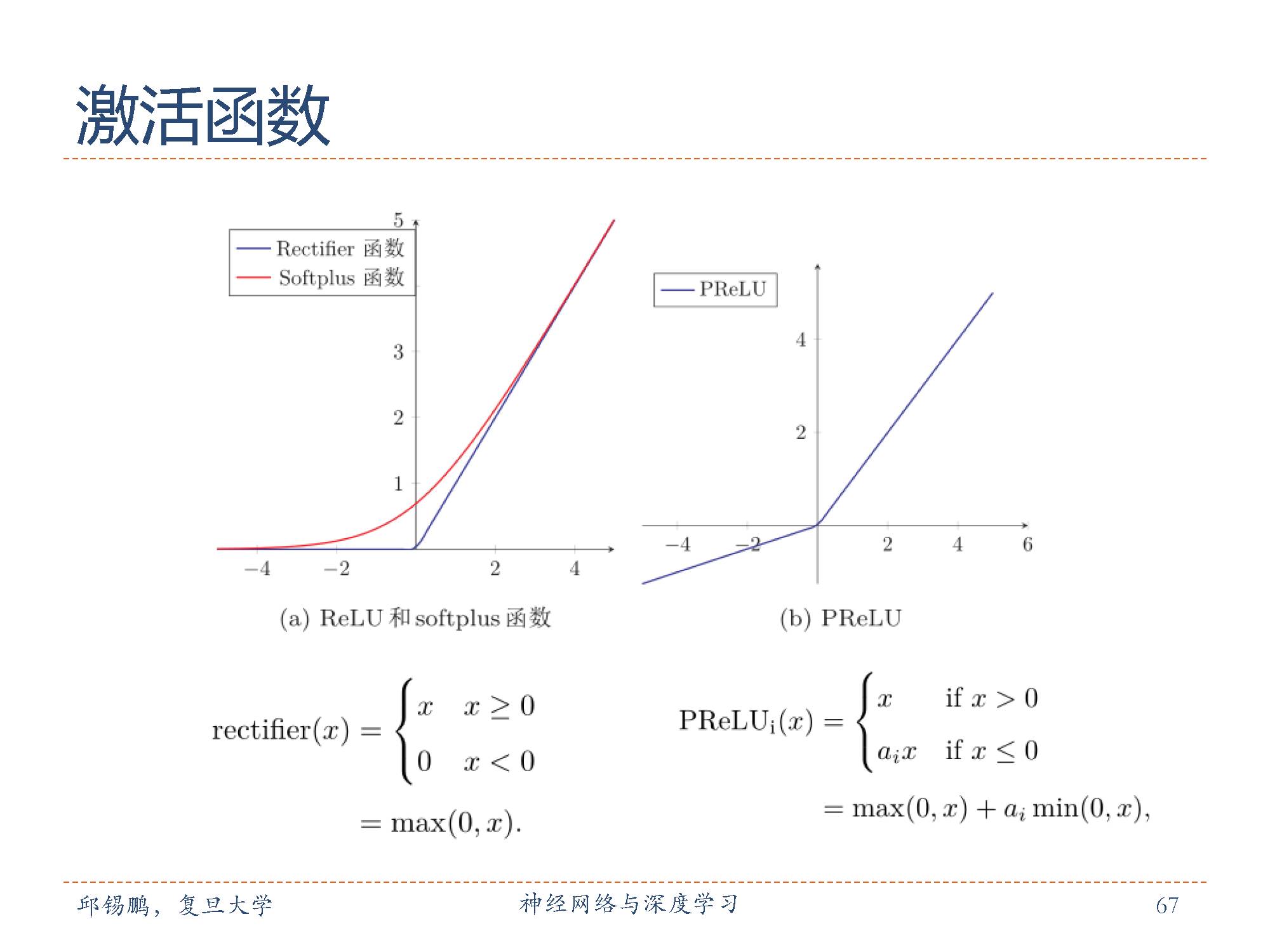
左边是 ReLU 和 Softplus 函数, 右边是PReLU函数。
采用 ReLU的神经网络只需要进行加、乘和比较的操作,计算上也更加高效。此外, rectifier 函数被认为有生物上的解释性。

这是常见激活函数和其相关导数。
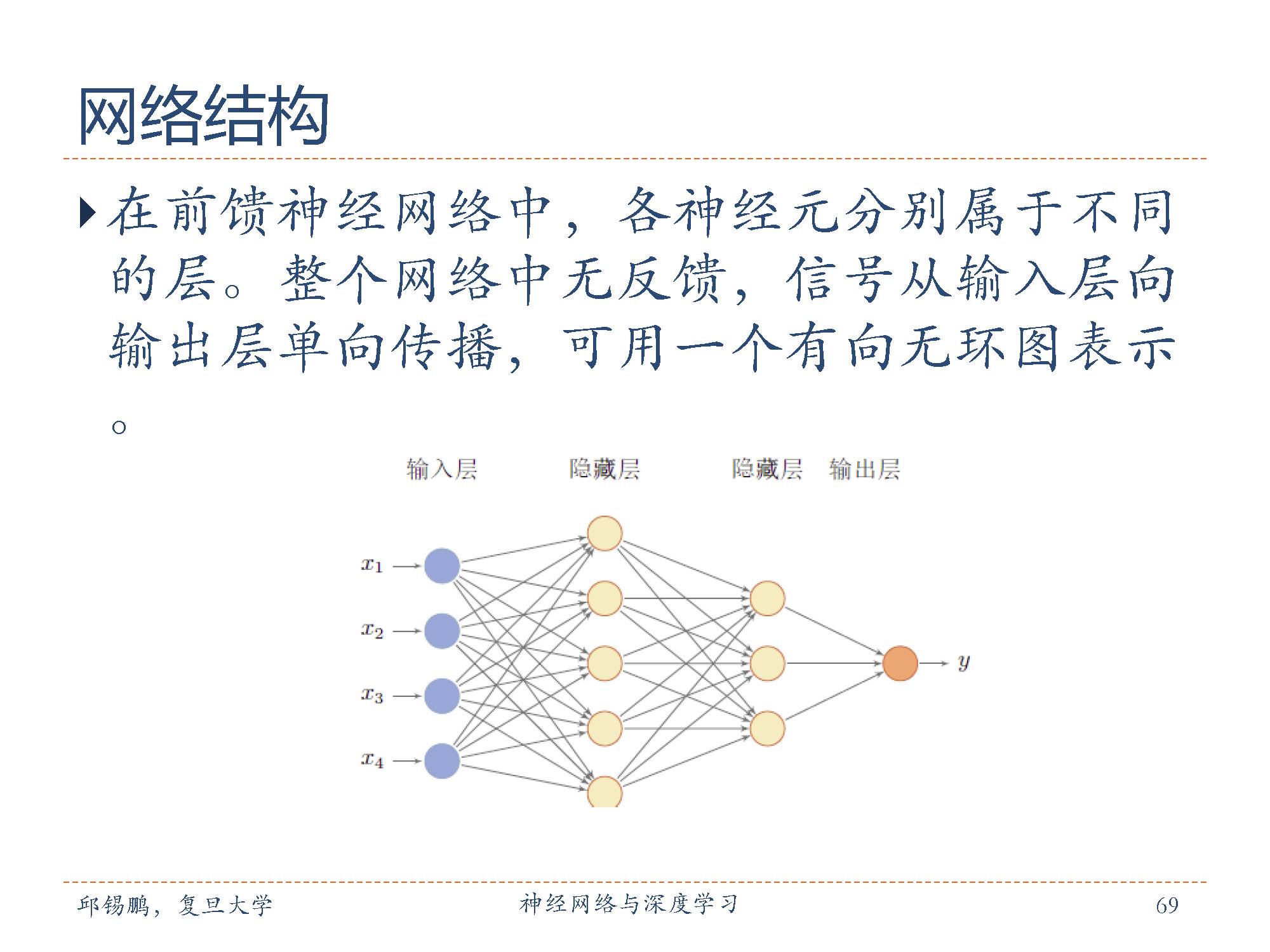
上图是·一个网络结构图,在前馈神经网络中,各神经元分别属于不同的层。每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层。第一层叫输入层,最后一层叫输出层,其它中间层叫做隐藏层。整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。

这是一些符号标记。

前馈神经网络通过下面的公式进行传播,逐层进行传播。
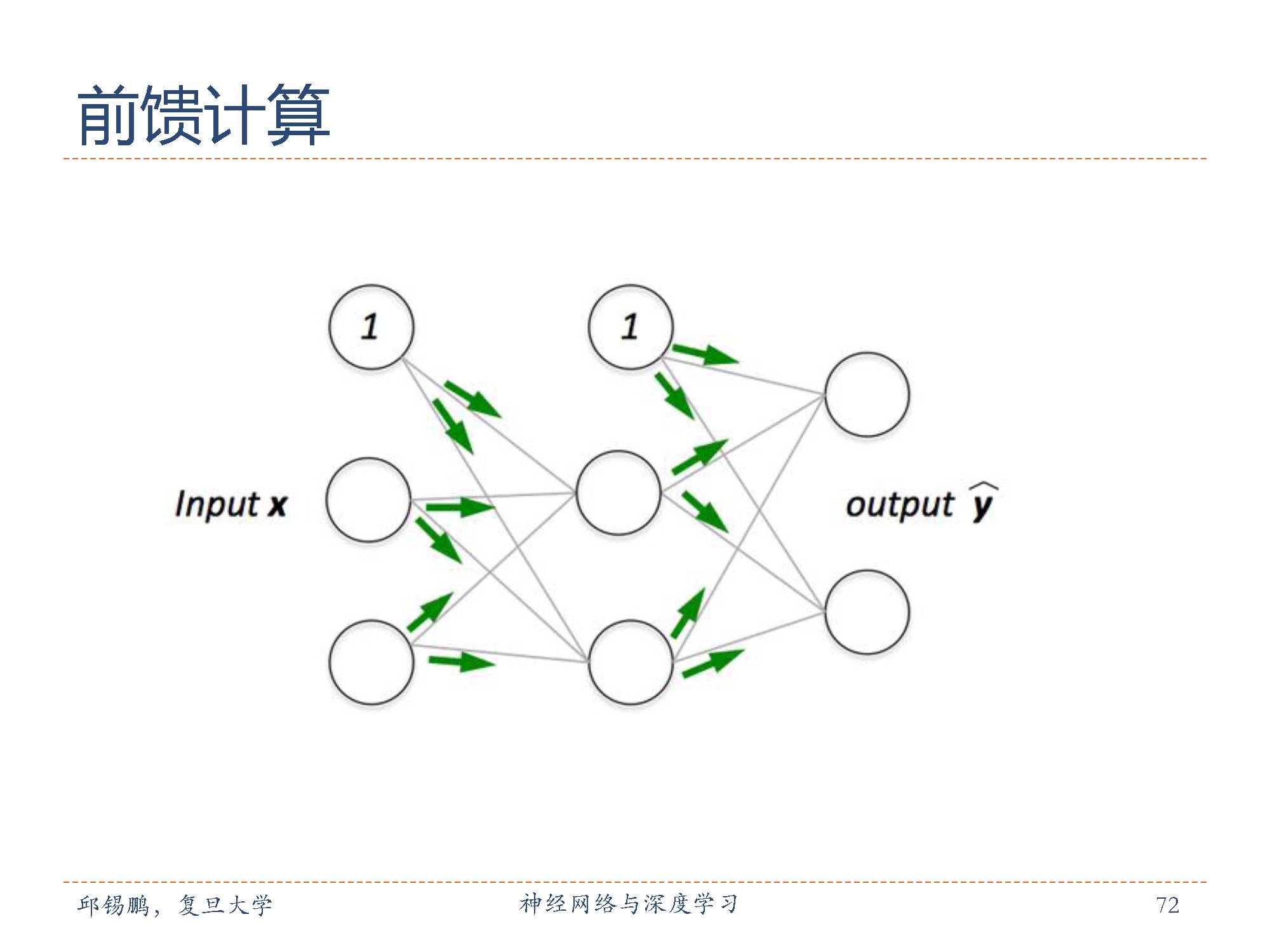
前馈网络可以用一个有向无环路图表示。前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。这种网络结构简单,易于实现。

神经网络在某种程度上可以作为一个“万能”(universal)函数来使用,因此神经网络的使用可以十分灵活,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。
在机器学习中,输入样本的特征对分类器的影响很大。以监督学习为例,好的特征可以极大提高分类器的性能。
对于二分类问题,logistic回归分类器可以看成神经网络的最后一层。也就是说,网络的最后一层只用一个神经元,并且其激活函数为logistic函数。网络的输出可以直接可以作为两个类别的后验概率。
对于多分类问题,使用 softmax回归分类器,相当于网络最后一层设置 C 个神经元,其输出经过 softmax 函数进行归一化后可以作为每个类的后验概率。
在多分类时,使用交叉熵损失函数,来进行模型的优化。

用梯度下降法对交叉熵损失函数进行参数学习,计算损失函数对参数的偏导数,通过链式法则逐一对每个参数进行求偏导效率比较低。
在神经网络的训练中经常使用反向传播算法来计算高效地梯度。
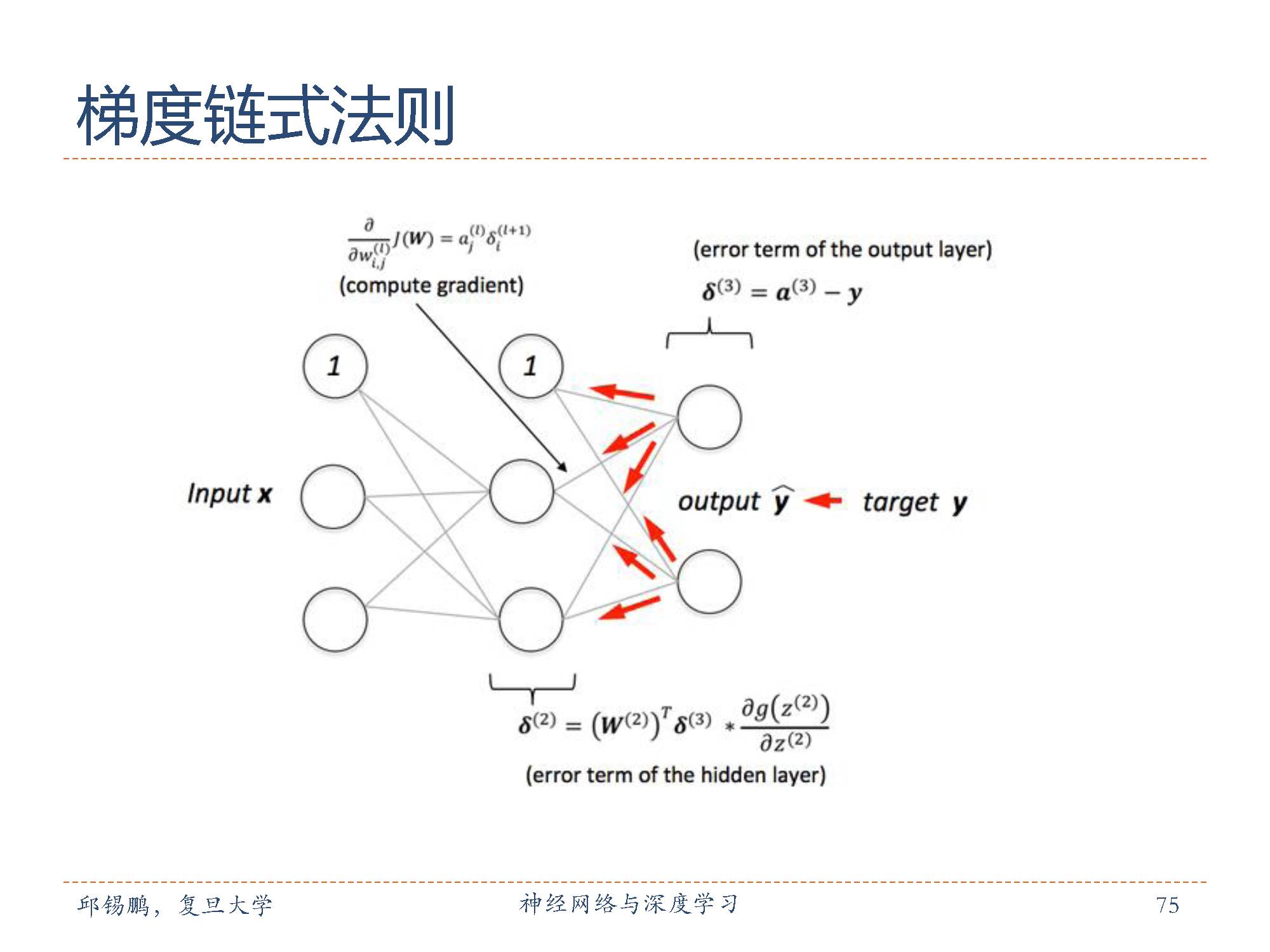
反向传播算法的是训练神经网络,如果神经网络只有一个一层,通过梯度下降可以直接调整这一层的weight,但如果有多层,需要调整各个层次的weight,所以就需要链式求导法则求出各个层的梯度。

可以通过链式反则来逐层向前推进,
用误差项来表示第l层的神经元对最终误差的影响,也反映了最终的输出对第l层的神经元对最终误差的敏感程度。

第 l 层的误差项可以通过第 l + 1层的误差项计算得到,这就是误差的反向传播。反向传播算法的含义是:第 l层的一个神经元的误差项(或敏感性)是所有与该神经元相连的第 l+ 1层的神经元的误差项的权重和。然后,再乘上该神经元激活函数的梯度。


在计算出每一层的误差项之后,我们就可以得到每一层参数的梯度。因此,基于误差反向传播算法(backpropagation, BP)的前馈神经网络训练过程可以分为以下三步:
前馈计算每一层的净输入和激活值,直到最后一层;
反向传播计算每一层的误差项;
计算每一层参数的偏导数,并更新参数。
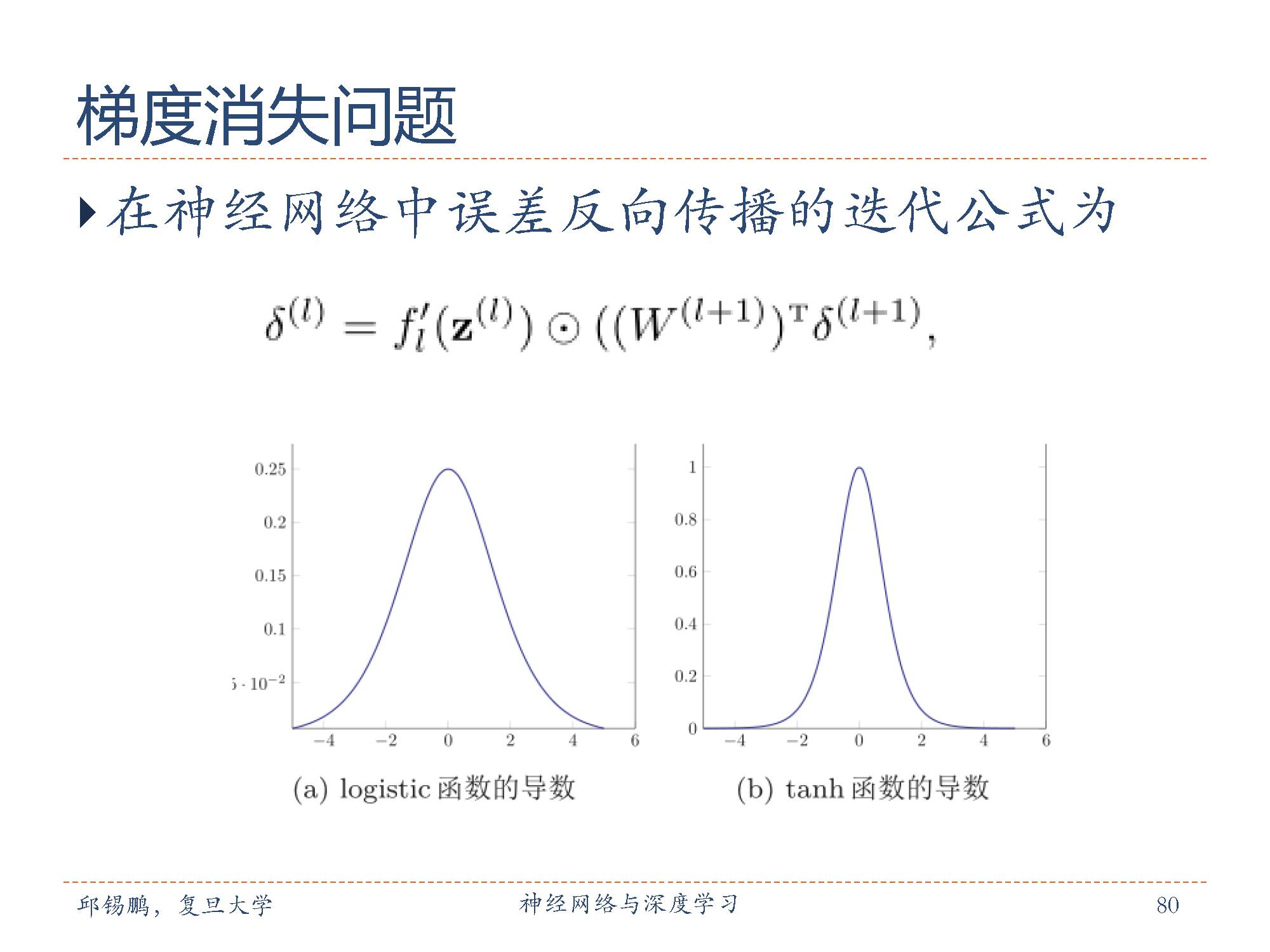
误差从输出层反向传播时,在每一层都要乘以该层的激活函数的导数。
我们可以看到,sigmoid 型函数导数的值域都小于 1。并且由于 sigmoid 型函数的饱和性,饱和区的导数更是接近于 0。这样,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停的衰减,甚至消失,使得整个网络很难训练。这就是所谓的梯度消失问题(VanishingGradient Problem),也叫梯度弥散问题。
在深层神经网络中,减轻梯度消失问题的方法有很多种。一种有效的方式是使用导数比较大的激活函数,比如ReLU等。这样误差可以很好地传播,训练速度得到了很大的提高。
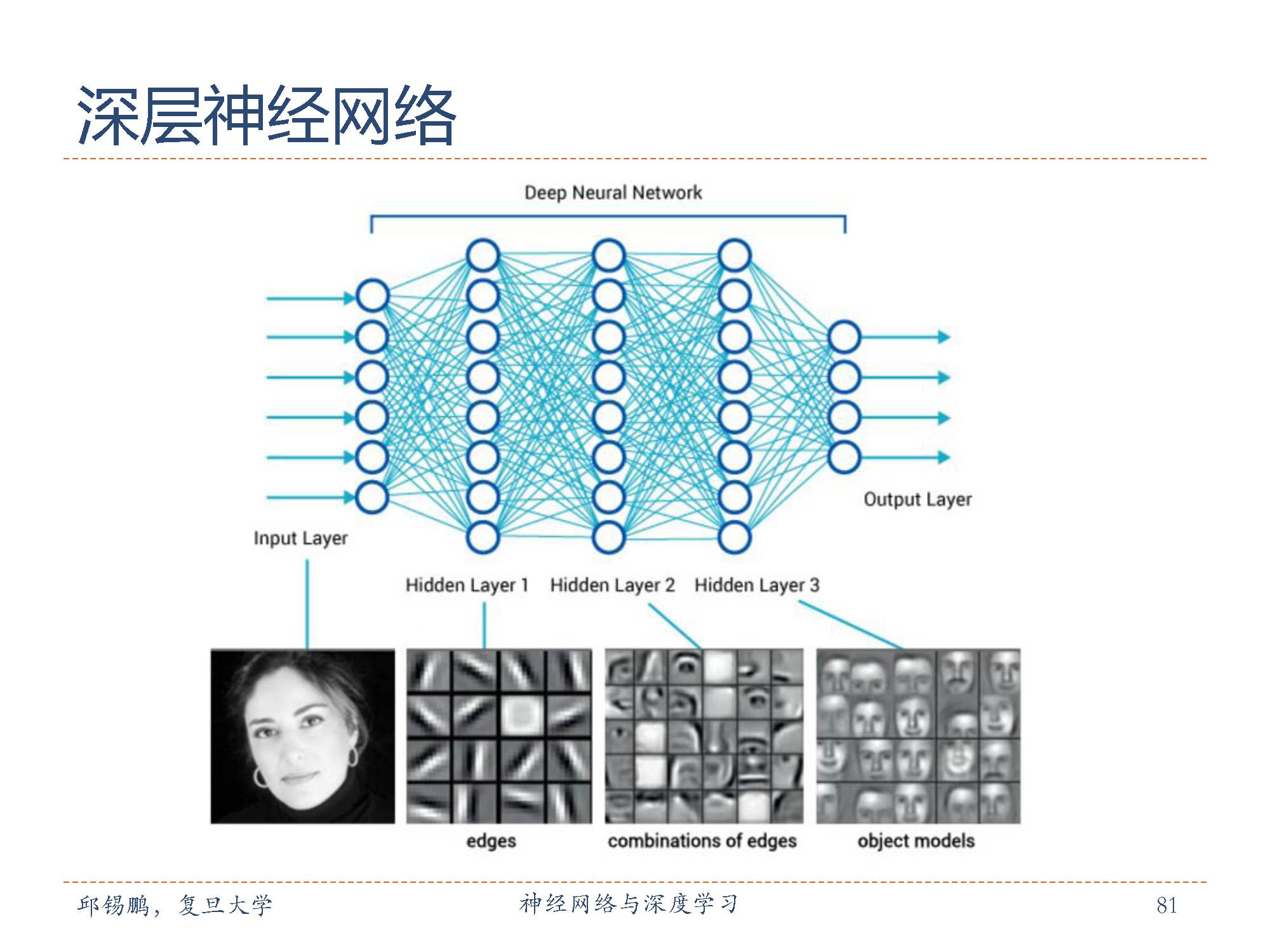
神经网络是基于感知机的扩展,而深度神经网络(DNN)可以理解为有很多隐藏层的神经网络。
这个很多其实也没有什么度量标准, 多层神经网络和深度神经网络DNN其实也是指的一个东西,当然,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP)。
在深度神经网络中相邻两层之间的任一神经元相连,DNN看起来很复杂,但是局部来讲还是和感知机一样的,包含一个线性关系和一个激活函数。

下面开始介绍卷积神经网络。

卷积神经网络与传统的全连接网络最大的区别是,它的结构基于一个假设,即输入数据是图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。

这三种特性一个非常重要的共同点就是可以大幅减少权重参数。减少参数的结果是我们可以设计更深表达能力更强的网络。
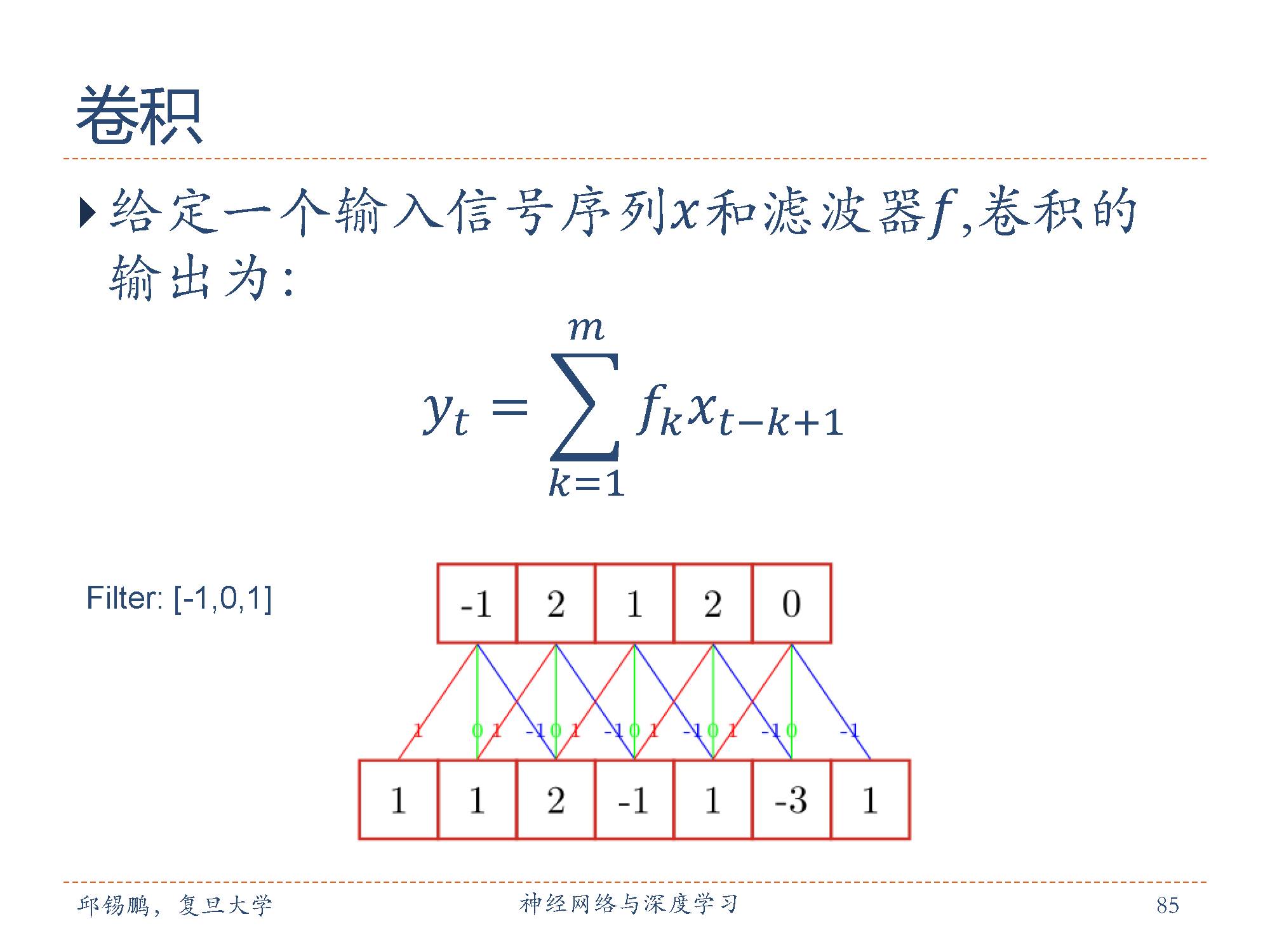
卷积层的参数是有一些可学习的滤波器集合构成的。每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据一致。
在每个卷积层上,我们会有一整个集合的滤波器,每个都会生成一个不同的二维激活图。将这些激活映射在深度方向上层叠起来就生成了输出数据。
例子中卷积核为[-1, 0,1],输出向量的第一个值-1来自卷积核与与对应输出层的乘积 -1 = -1*1 + 0*1 + 2*2
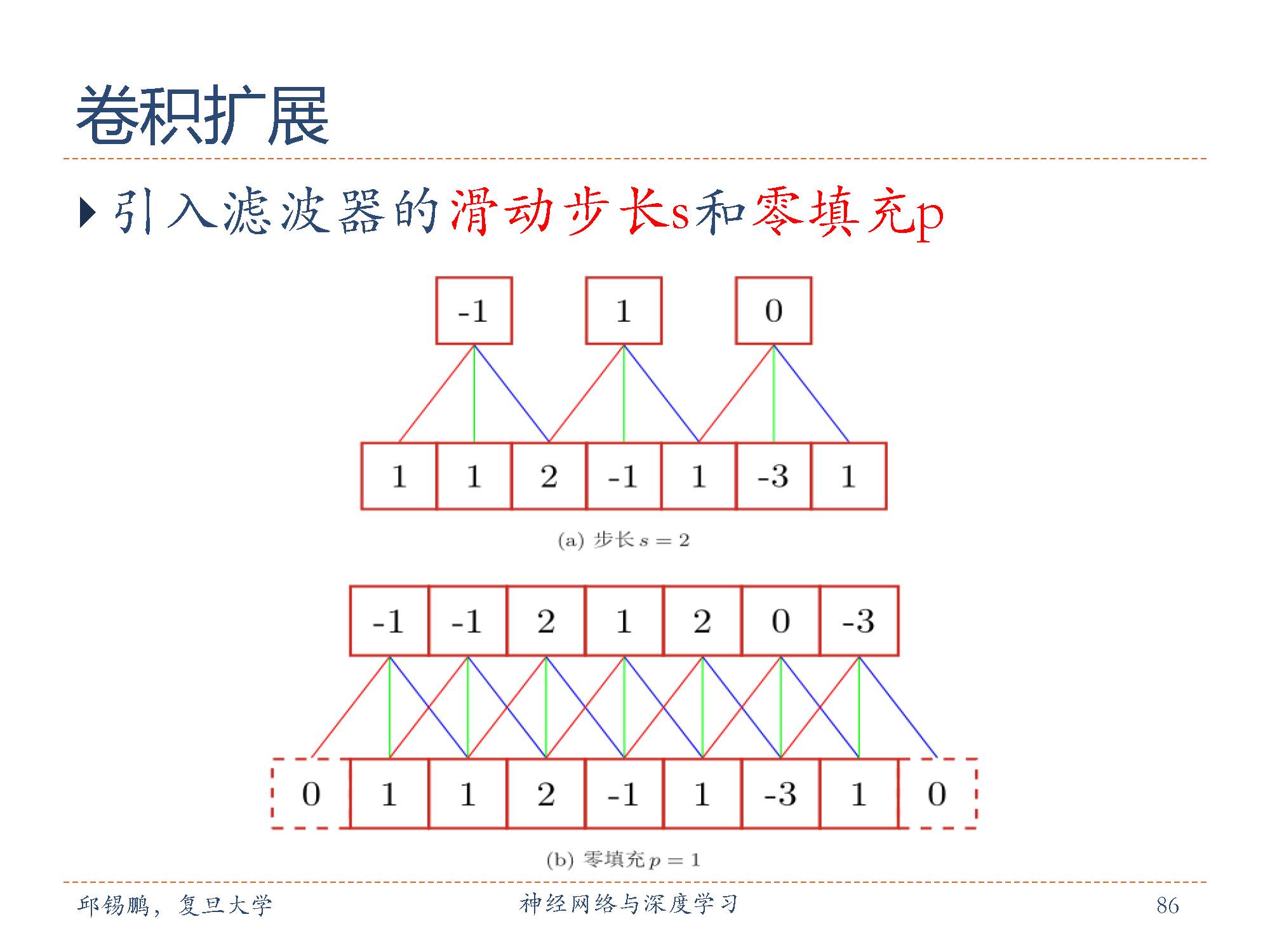
零填充(zero padding)是在输入向量两端进行补零。图中给出了输入的两端各补一个零后的卷积示例。假设卷积层的输入神经元个数为n,卷积大小为m,步长(stride)为s,输入神经元两端各填补 p个零(zero padding),那么该卷积层的神经元数量为 (n − m + 2p)/s + 1。

零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。
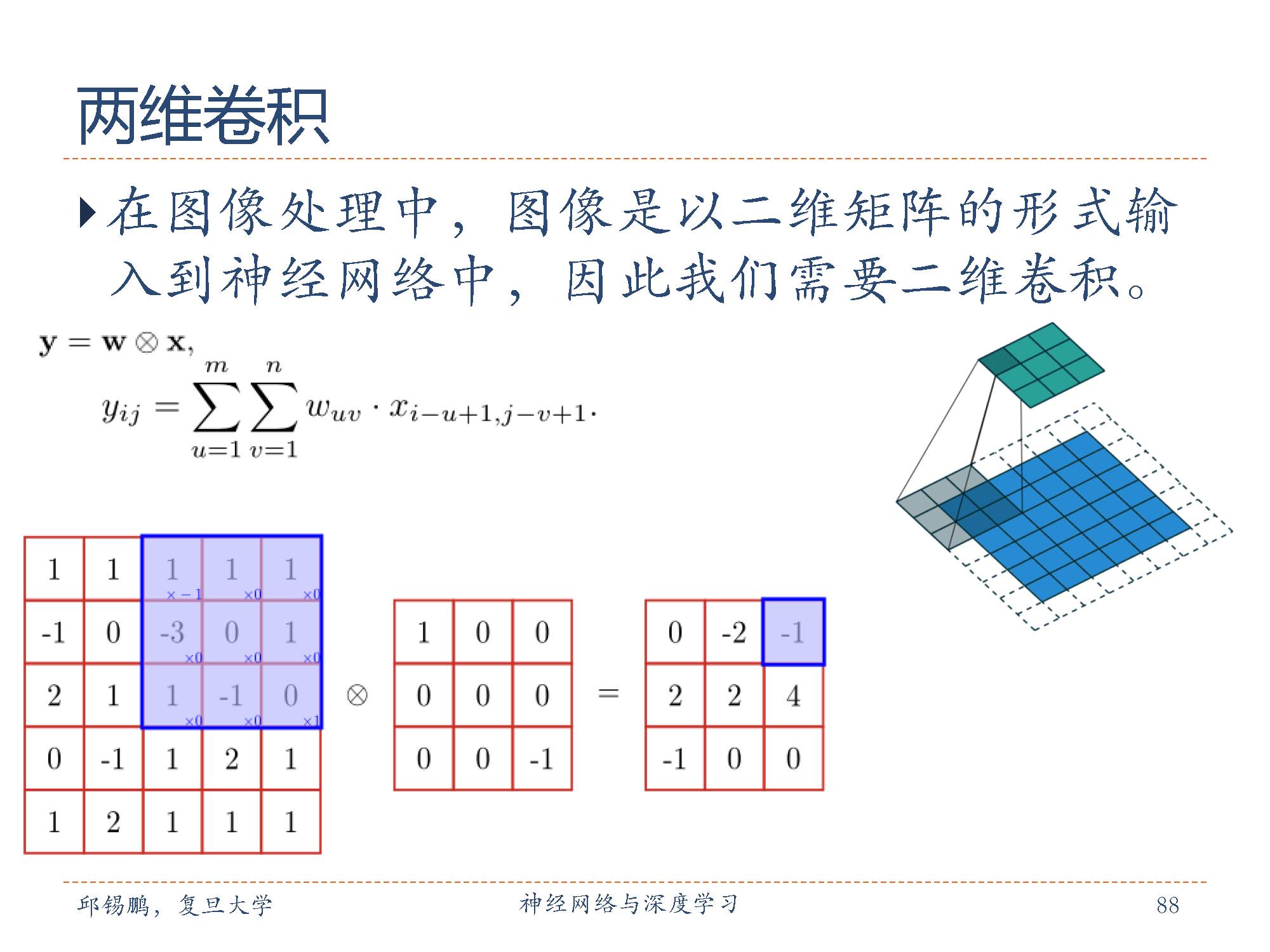
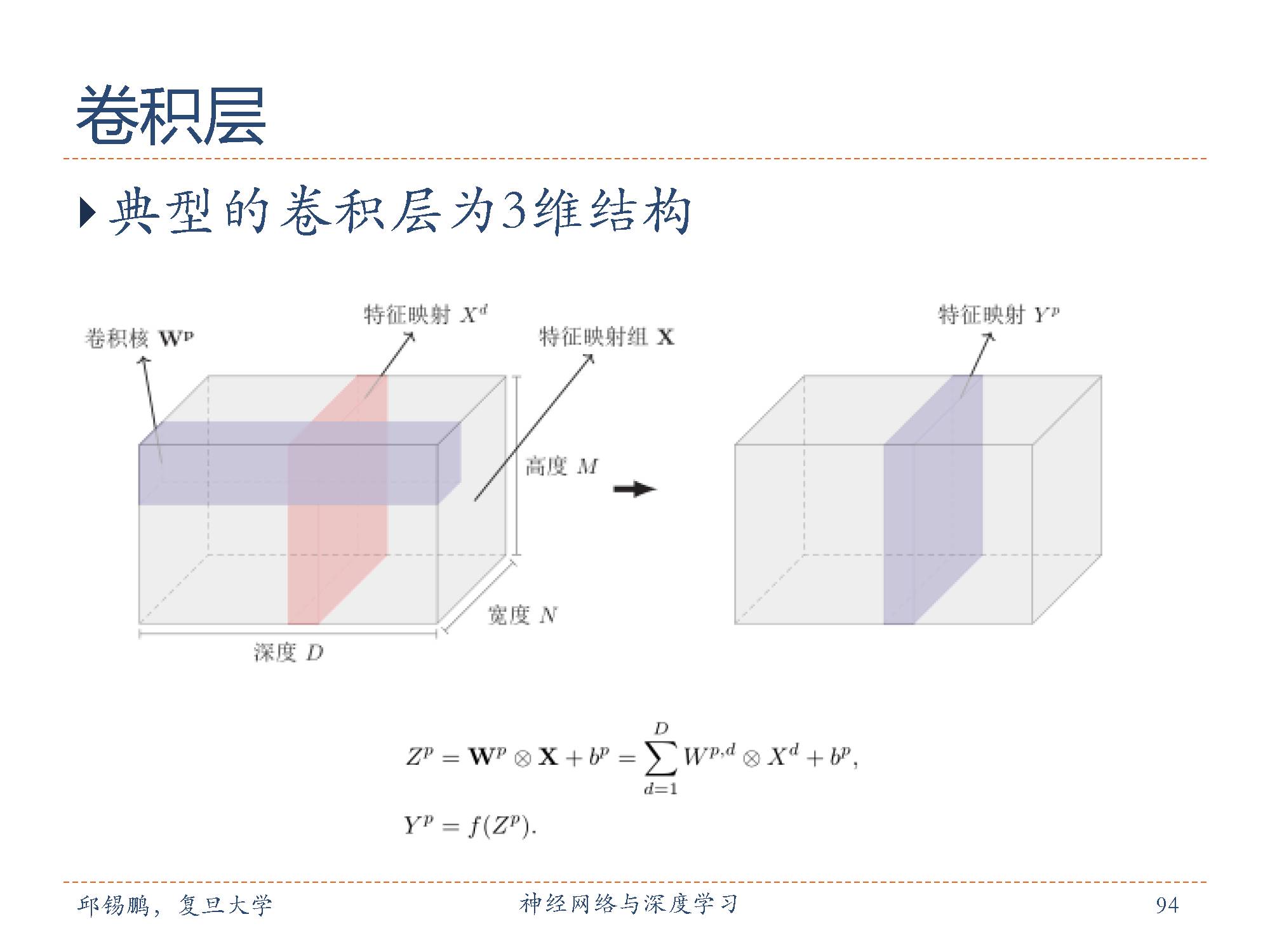
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器。上一节中描述的卷积层的神经元和全连接网络一样都是一维结构。既然卷积网络主要应用在图像处理上,而图像为两维结构,因此为了更充分地利用图像的局部信息,通常将神经元组织为三维结构的神经层,其大小为宽度 M×高度N×深度D,有D 个M × N 大小的特征映射构成。图中现实的尺寸为5x5x1 也就是深度为1,长宽为5
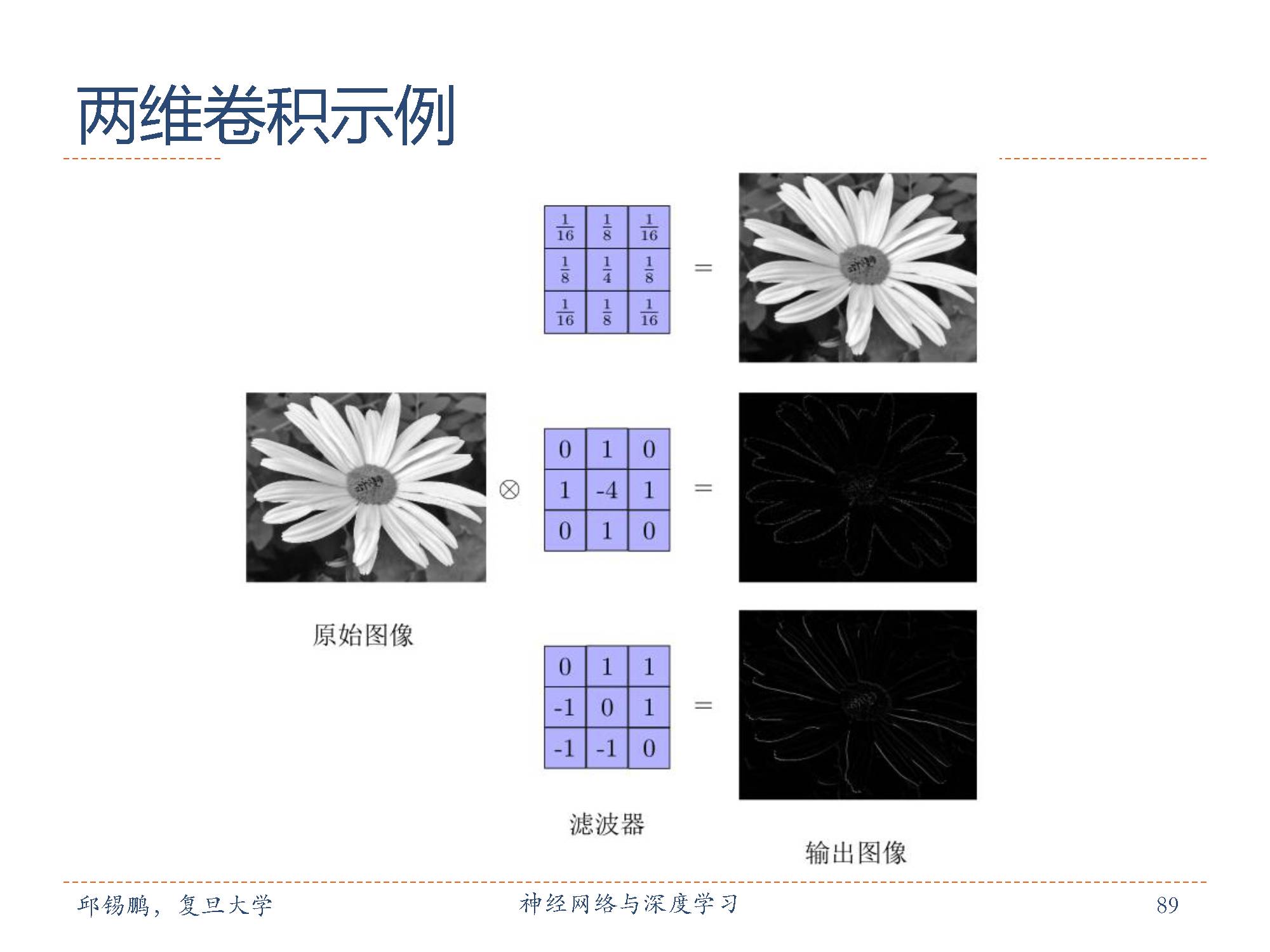
可以看出来卷积操作可以看成对原始图片的某种映射操作,比如提取花的轮廓特征等。
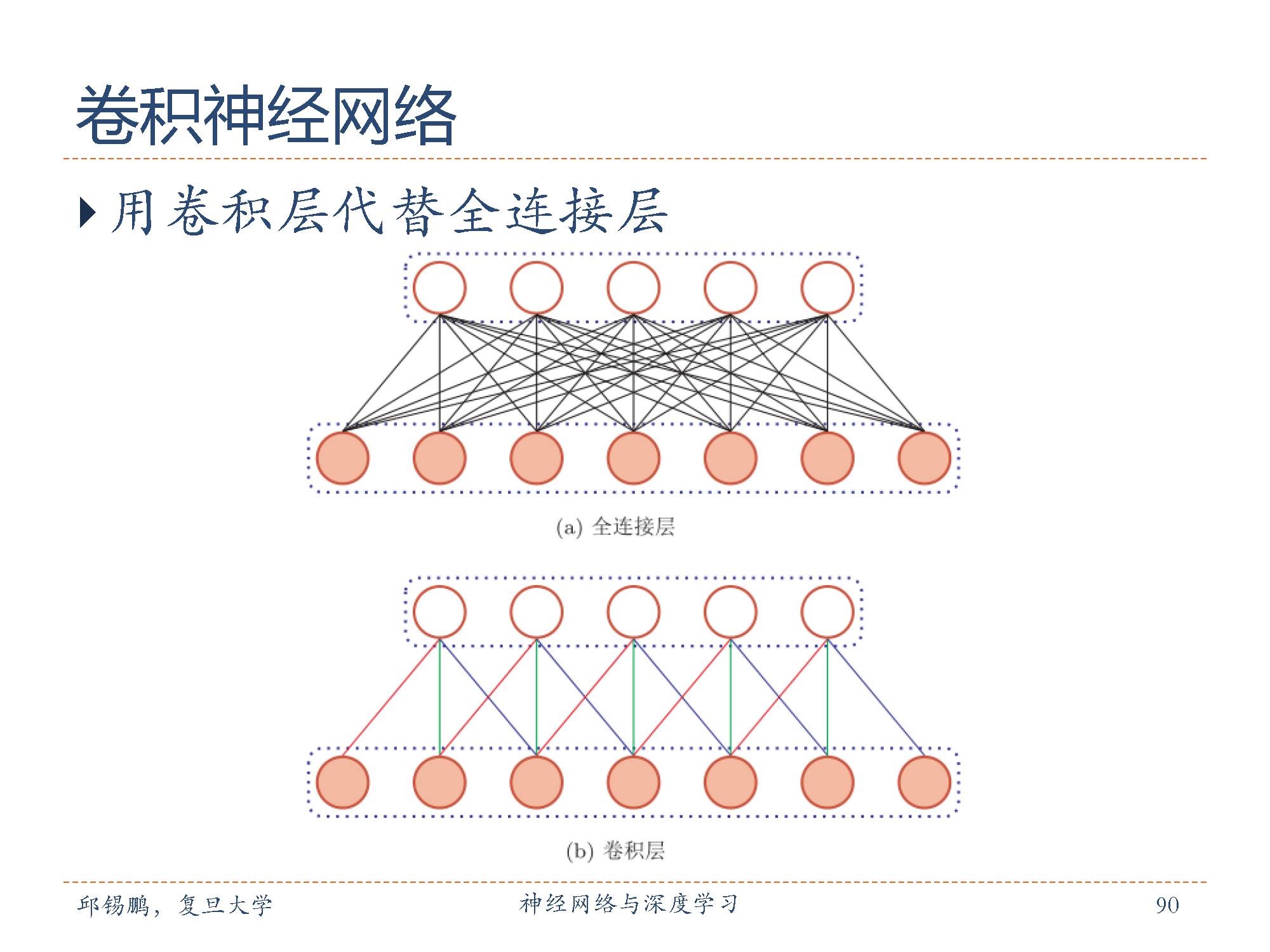
从图中可以非常直观的看出来卷积操作可以极大地减少参数。

特征映射(feature map)为一幅图像(或其它特征映射)在经过卷积提取到的特征,每个特征映射可以作为一类抽取的图像特征。为了卷积网络的表示能力,可以在每一层使用多个不同的特征映射,以更好地表示图像的特征。
在输入层,特征映射就是图像本身。如果是灰度图像,就是有一个特征映射,深度D = 1;如果是彩色图像,分别有RGB三个颜色通道的特征映射,输入层深度D= 3。
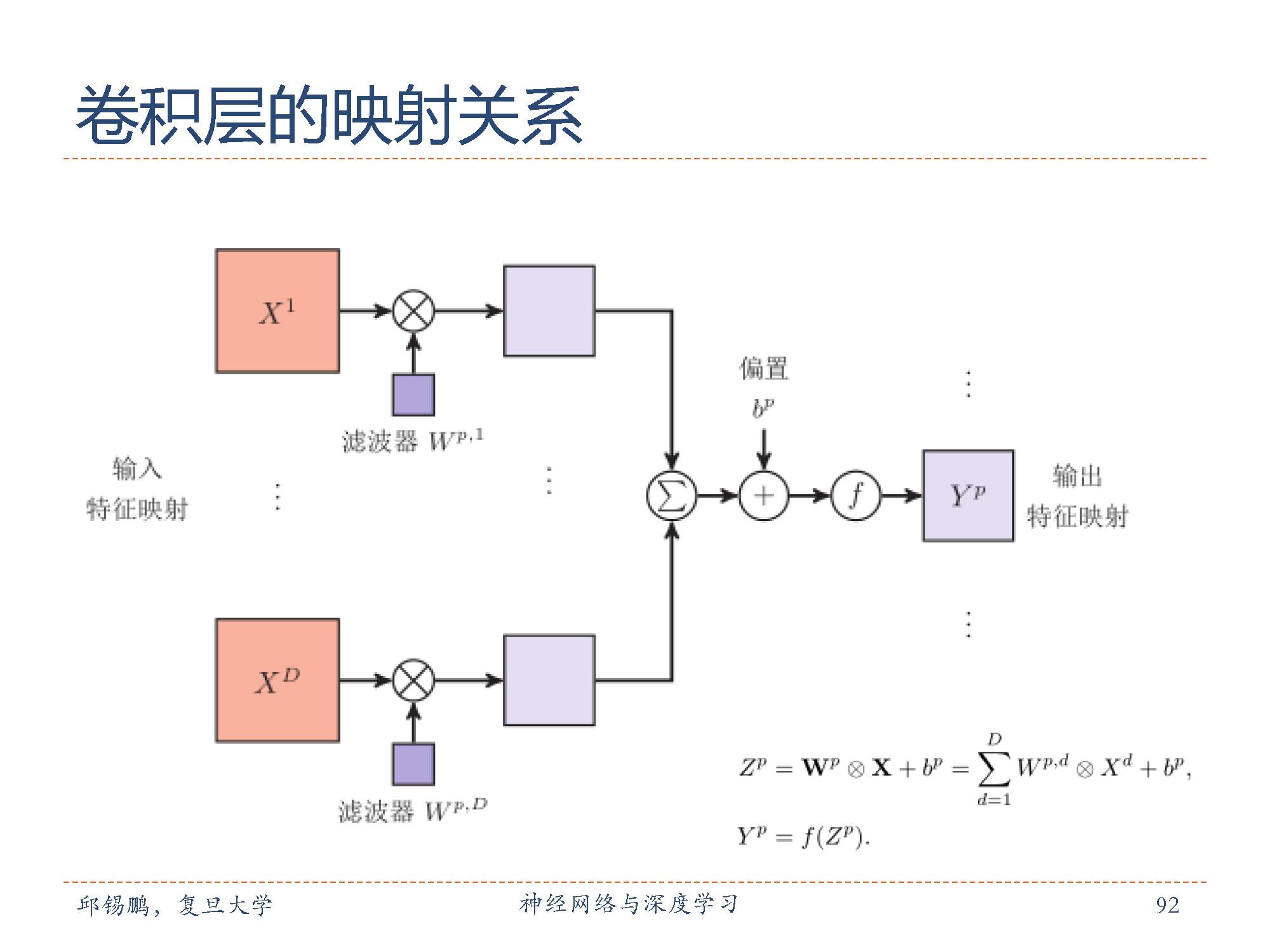
卷积层中从输入特征映射组X到输出特征映射Yp 的计算示例。

这是卷积层的运行演示。因为3D数据难以可视化,所以所有的数据(输入数据体是蓝色,权重数据体是红色,输出数据体是绿色)都采取将深度切片按照列的方式排列展现。输入数据体的尺寸是5x5x3,卷积层参数K=2,F=3,S=2,P=1。就是说,有2个滤波器,滤波器的尺寸是3*3,它们的步长是2.因此,输出数据体的空间尺寸是(5-3+2)/2+1=3。注意输入数据体使用了零填充P=1,所以输入数据体外边缘一圈都是0。下面的例子在绿色的输出激活数据上循环演示,展示了其中每个元素都是先通过蓝色的输入数据和红色的滤波器逐元素相乘,然后求其总和,最后加上偏差得来。
特征映射(feature map)为一幅图像(或其它特征映射)在经过卷积提取到的特征,每个特征映射可以作为一类抽取的图像特征。为了卷积网络的表示能力,可以在每一层使用多个不同的特征映射,以更好地表示图像的特征。
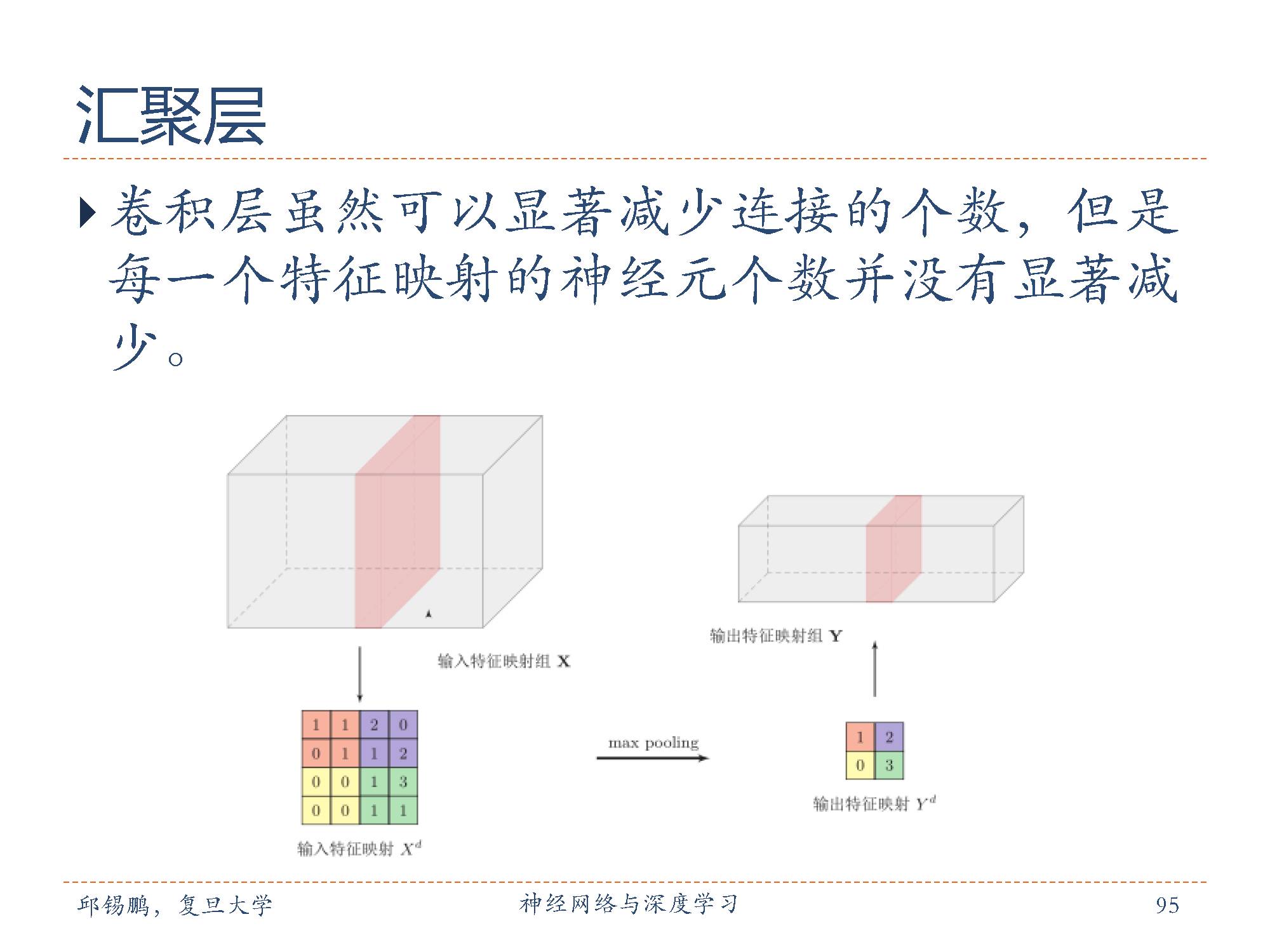
常用的汇聚函数有两种:1. 最大汇聚(maximum pooling):一般是取一个区域内所有神经元的最大值。平均汇聚(mean pooling):一般是取区域内所有神经元的平均值。
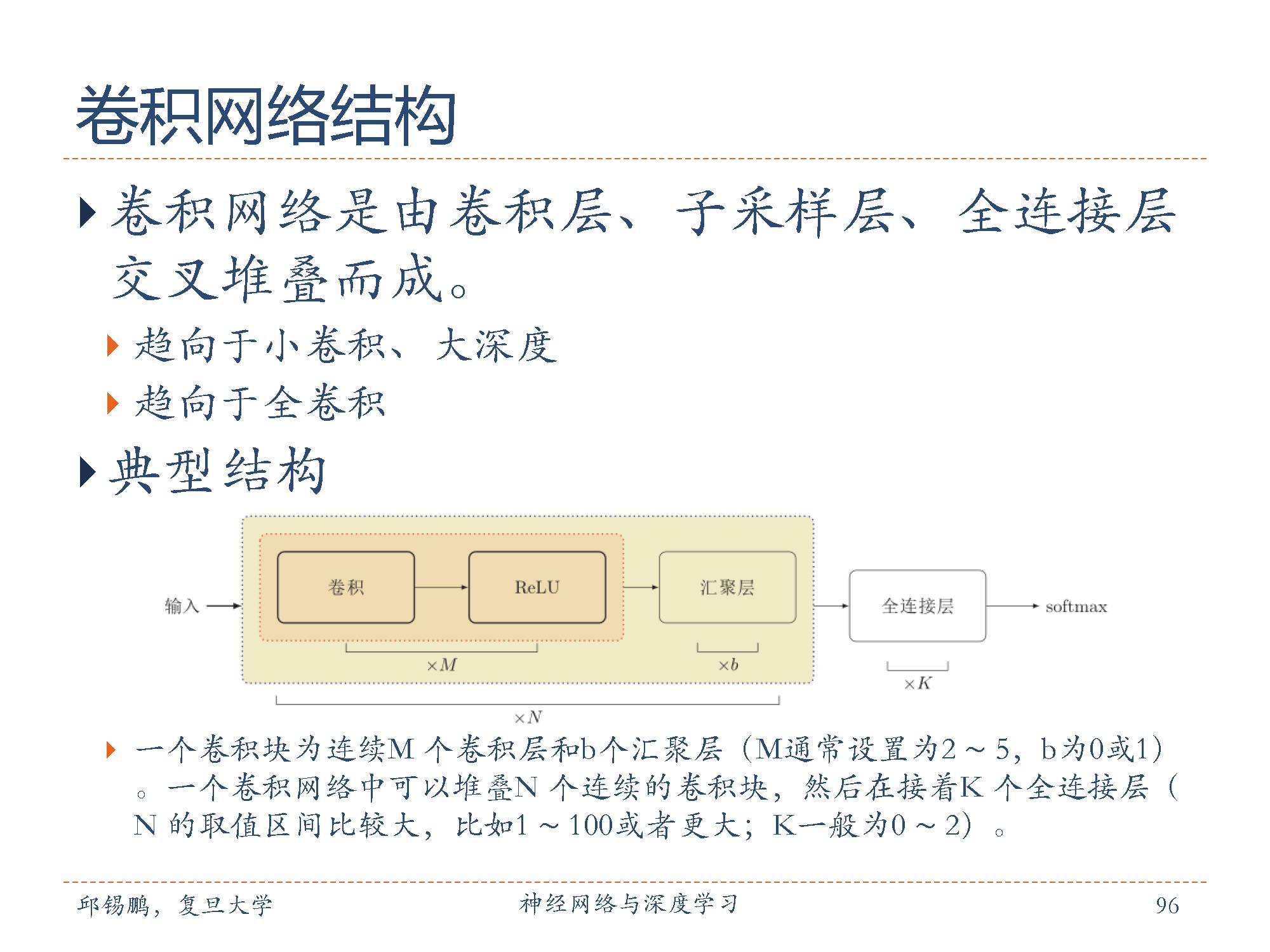
典型的的卷积网络结构通常由多个卷积核汇聚结构组成。
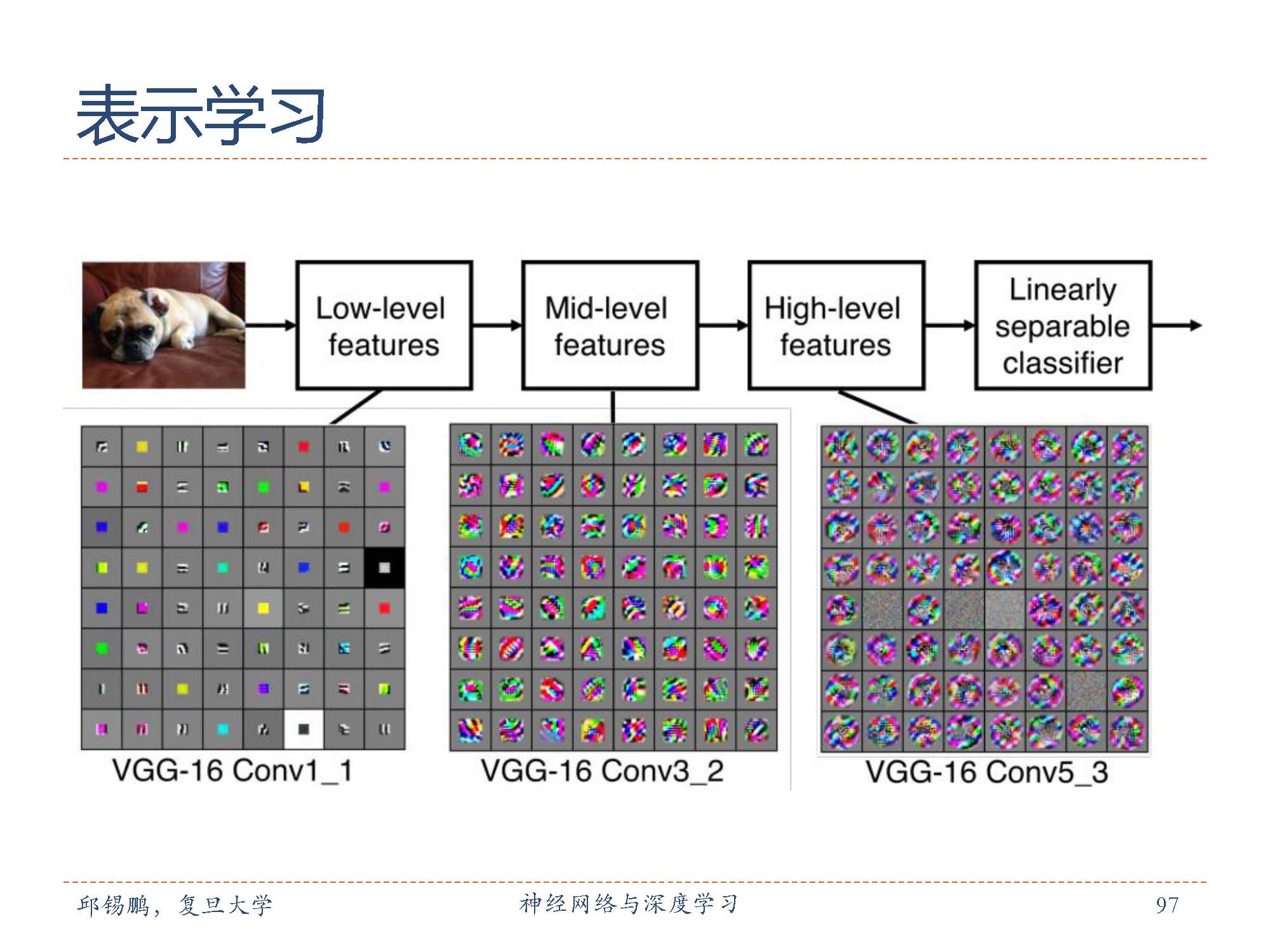
卷积网络的层次结构也是不断地提取原始图像特征的过程,从底层四的边缘特征逐渐到结构特征。

这是识别车辆的一个层级网络结构。

下面开始介绍典型的网络结构。
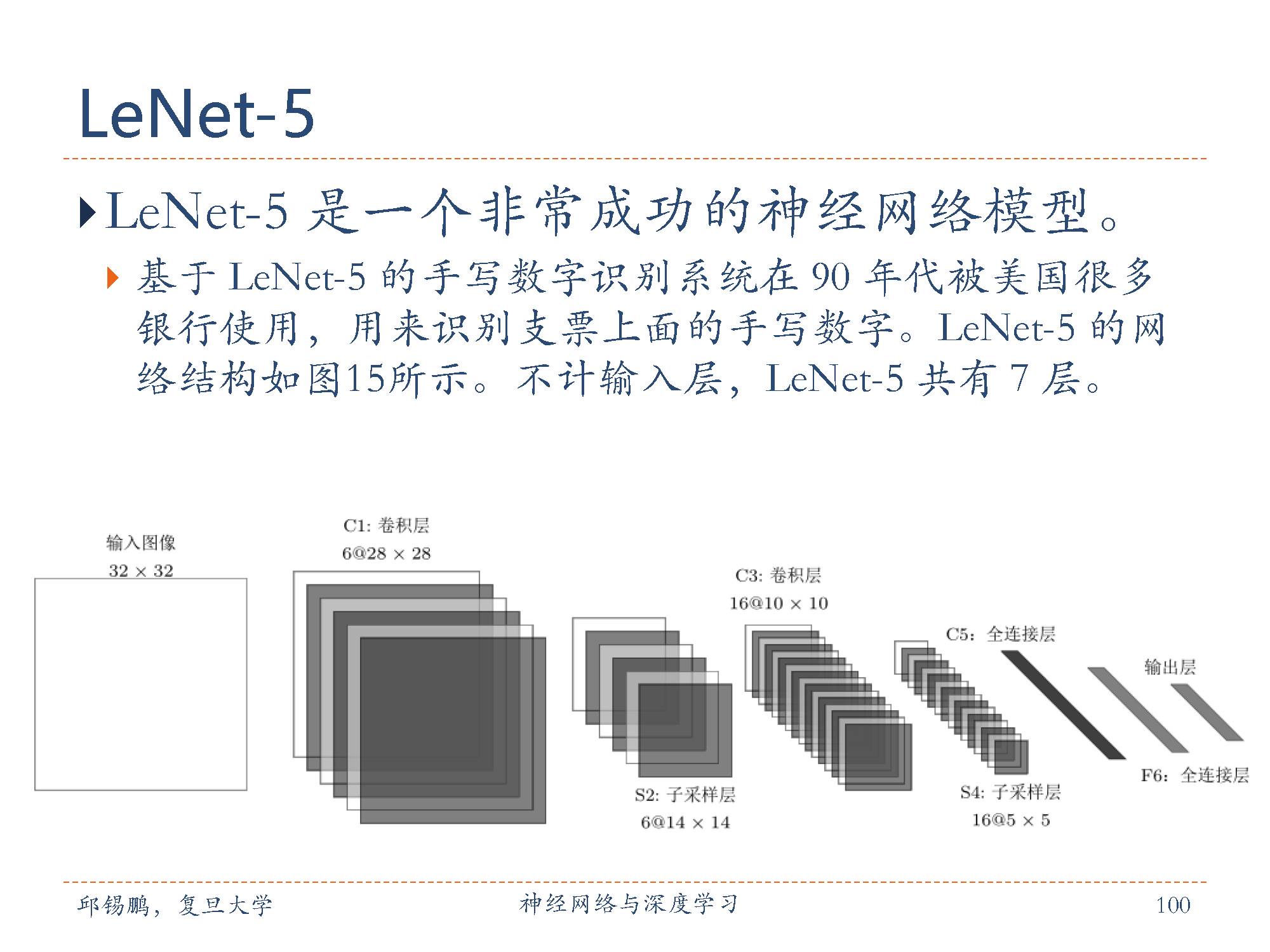
不计输入层,LeNet-5共有7层,每一层的结构为:
1. 输入层:输入图像大小为32 × 32 = 1024。
2. C1层是卷积层,使用6个5 × 5的滤波器,得到6组大小为28 × 28 = 784 的特征映射。因此,C1层的神经元数量为6× 784 = 4, 704,可训练参数数量为6× 25 + 6 = 156,连接数为156× 784 = 122, 304(包括偏置在内,下同)。
3. S2层为汇聚层,采样窗口为2×2,使用平均汇聚,并使用一个非线性函数。神经元个数为 6 × 14 × 14 = 1, 176,可训练参数数量为 6× (1 + 1) = 12,连接数为6× 196 × (4 + 1) = 5, 880。
4. C3层为卷积层。LeNet-5中用一个连接表来定义输入和输出特征映射之间的依赖关系,如图5.11所示,共使用60个5 × 5的滤波器,得到16组大小第105页。为10× 10的特征映射。神经元数量为16 × 100 = 1, 600,可训练参数数量为(60× 25 + 16 = 1, 516,连接数为100× 1, 516× = 151, 600。
5. S4层是一个汇聚层,采样窗口为2× 2,得到16个5 × 5大小的特征映射,可训练参数数量为16 × 2 = 32,连接数为16 × (4 + 1) = 2000。
6. C5层是一个卷积层,使用120 × 16 = 1, 920个5 × 5的滤波器,得到120组大小为1 × 1的特征映射。C5层的神经元数量为120,可训练参数数量为1,920 × 25 + 120 = 48, 120,连接数为120× (16 × 25 + 1) = 48, 120。
7. F6层是一个全连接层,有84个神经元,可训练参数数量为84×(120+1) = 10, 164。连接数和可训练参数个数相同,为10,164。
8. 输出层:输出层由10个欧氏径向基函数(Radial Basis Function,RBF)函数组成。这里不再详述。
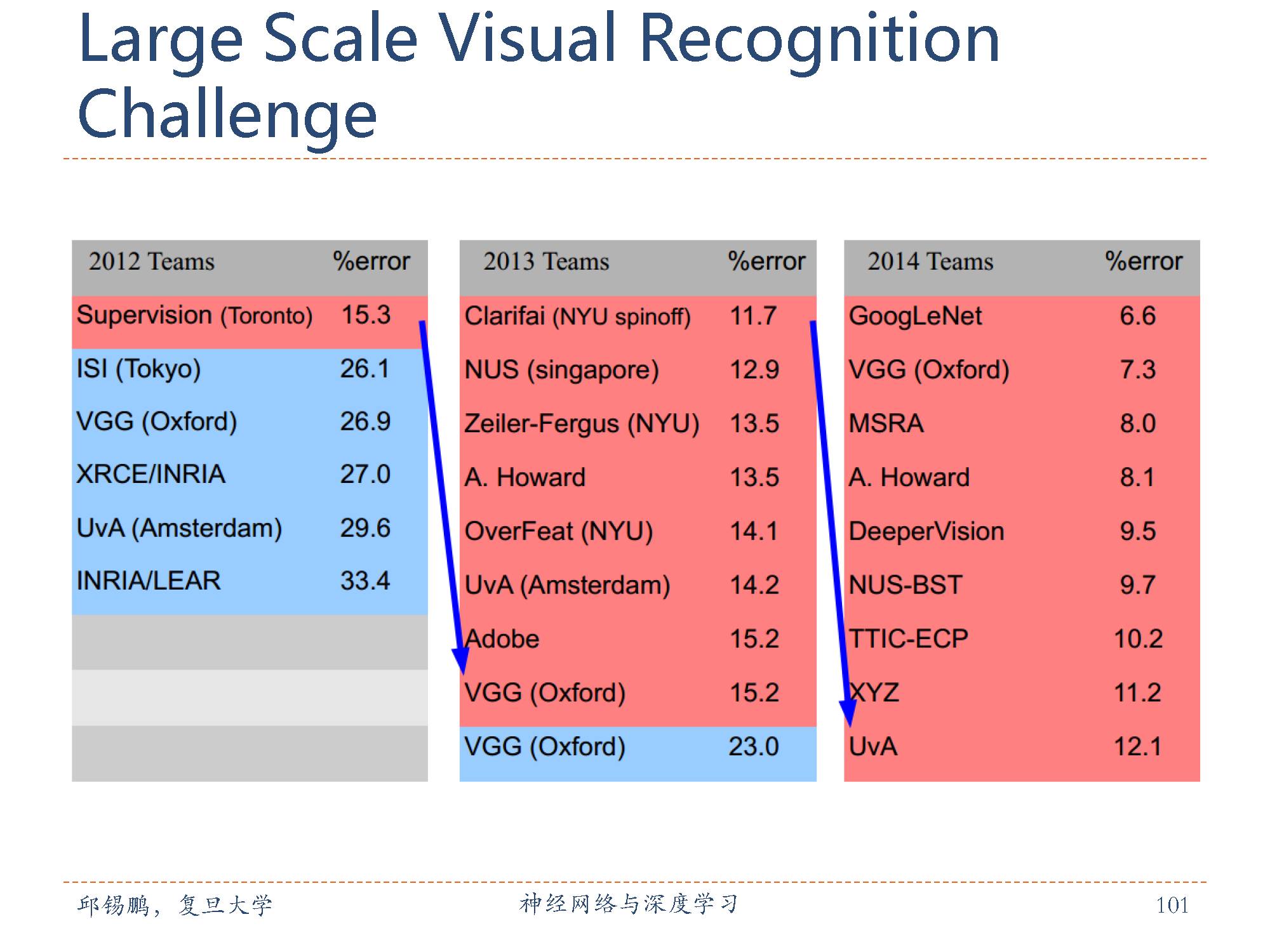
在ImageNet数据集上的图像分类比赛结果。可以看到12之后每一年的最差结果都能达到上年的最好结果。
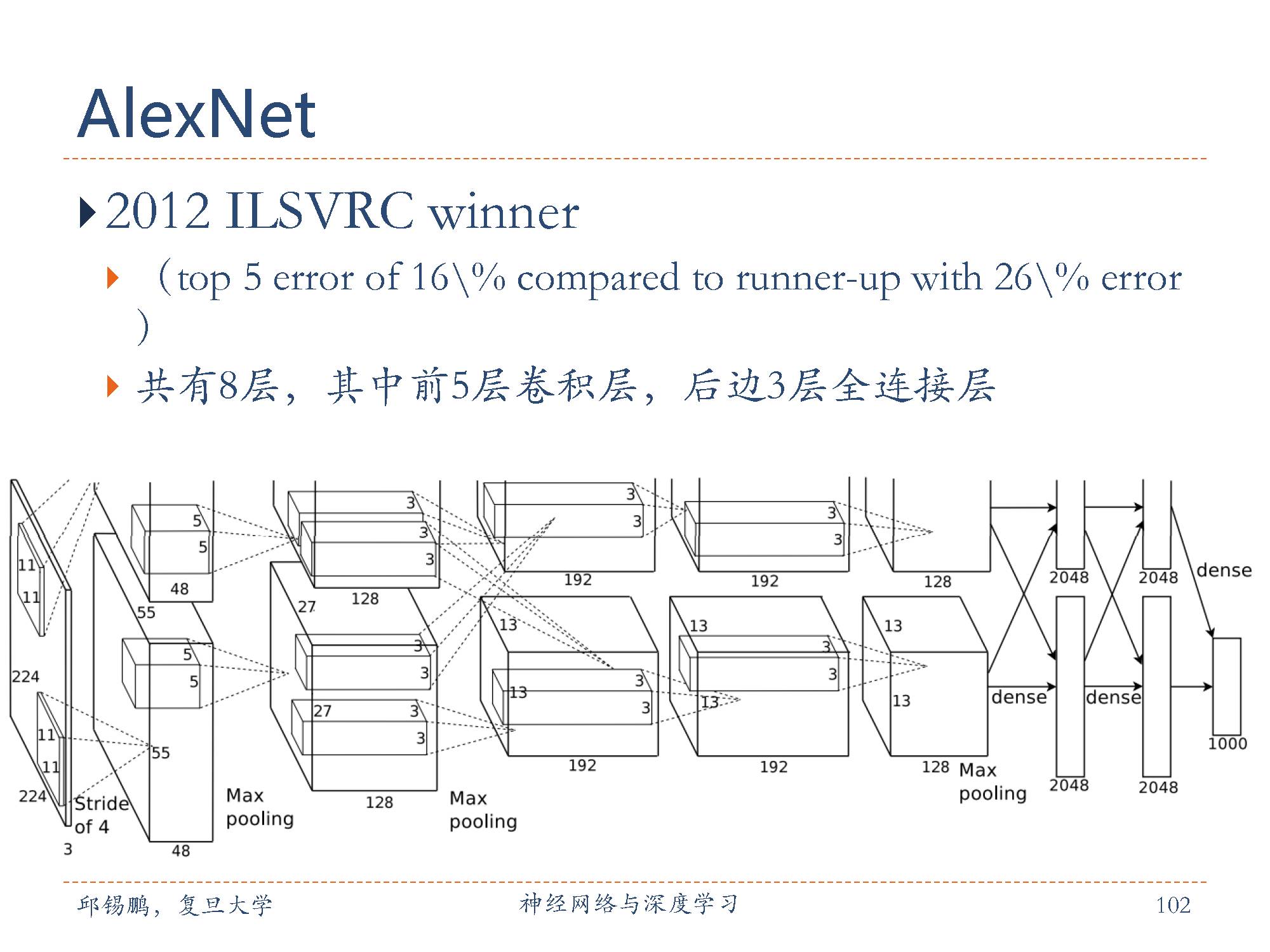
AlexNet[Krizhevsky et al., 2012]是第一个现代深度卷积网络模型,其首次使用了很多现代深度卷积网络的一些技术方法,比如使用GPU 进行并行训练,采用了ReLU作为非线性激活函数,使用Dropout防止过拟合,使用数据增强来提高模型准确率等。AlexNet赢得了2012年ImageNet图像分类竞赛的冠军。 AlexNet的结构包括5个卷积层、3个全连接层和1个softmax 层。因为网络规模超出了当时的单个GPU的内存限制,AlexNet将网络拆为两半,分别放在两个GPU上,GPU间只在某些层(比如第3层)进行通讯。
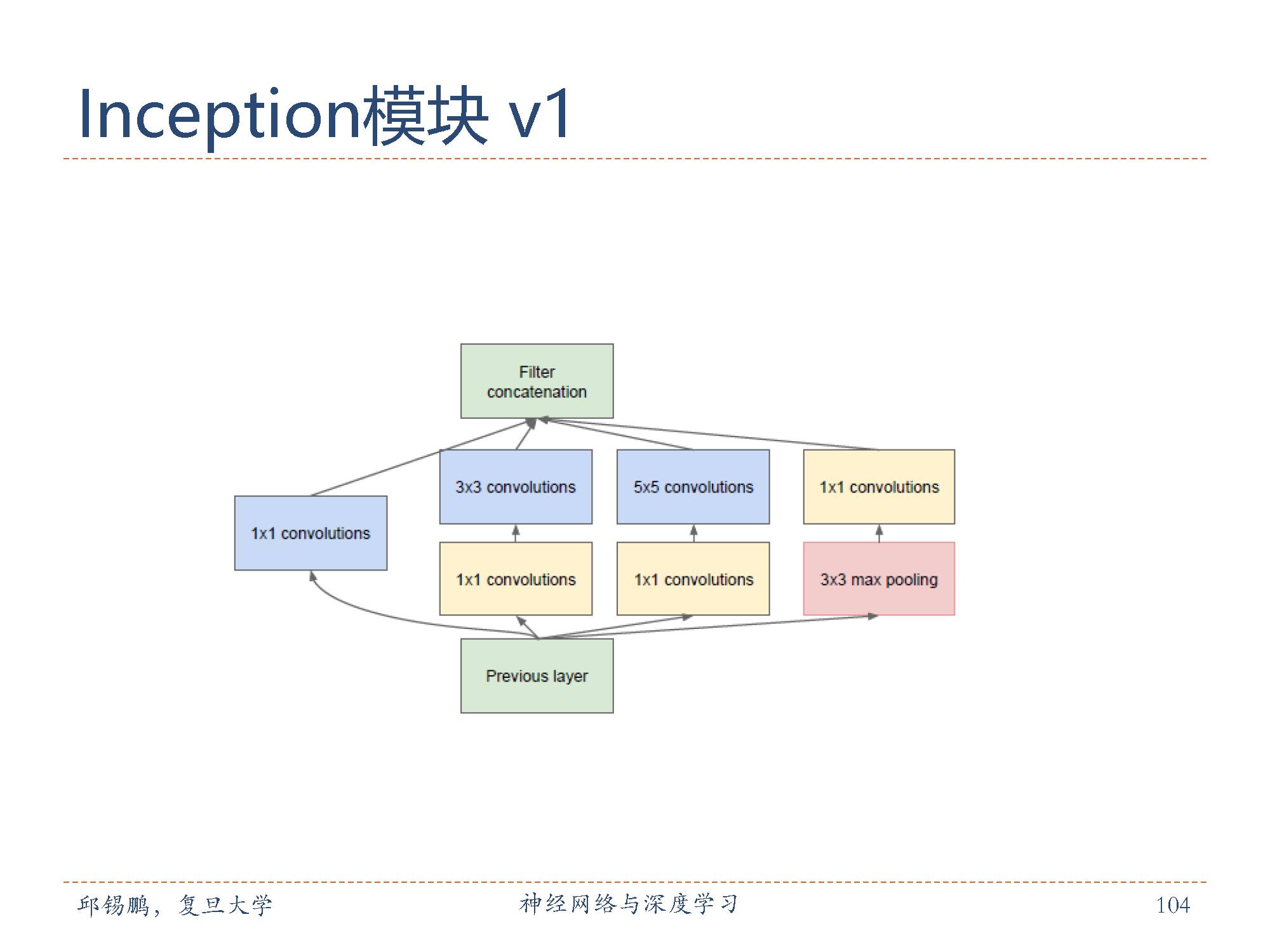
在卷积层中如何选择合适的卷积核大小是一个十分关键的问题。Inception 模块采取的方法是同时使用1× 1、3 × 3、5 × 5的卷积核,并将得到的特征映射拼接起来作为输入特征映射。图中给出了v1版本的inception模块,采用了4 组平行的特征抽取方式,分别为1 × 1、3 × 3、5 × 5的卷积核3× 3的最大汇聚。同时,为了提高计算效率,减少参数数量,inception模块在进行3 × 3、5 × 5的卷积前,先进行一次1 × 1的卷积来减少输入特征映射的深度。如果输入特征映射之间存在冗余信息,1× 1的卷积相当于先进行一次特征抽取。
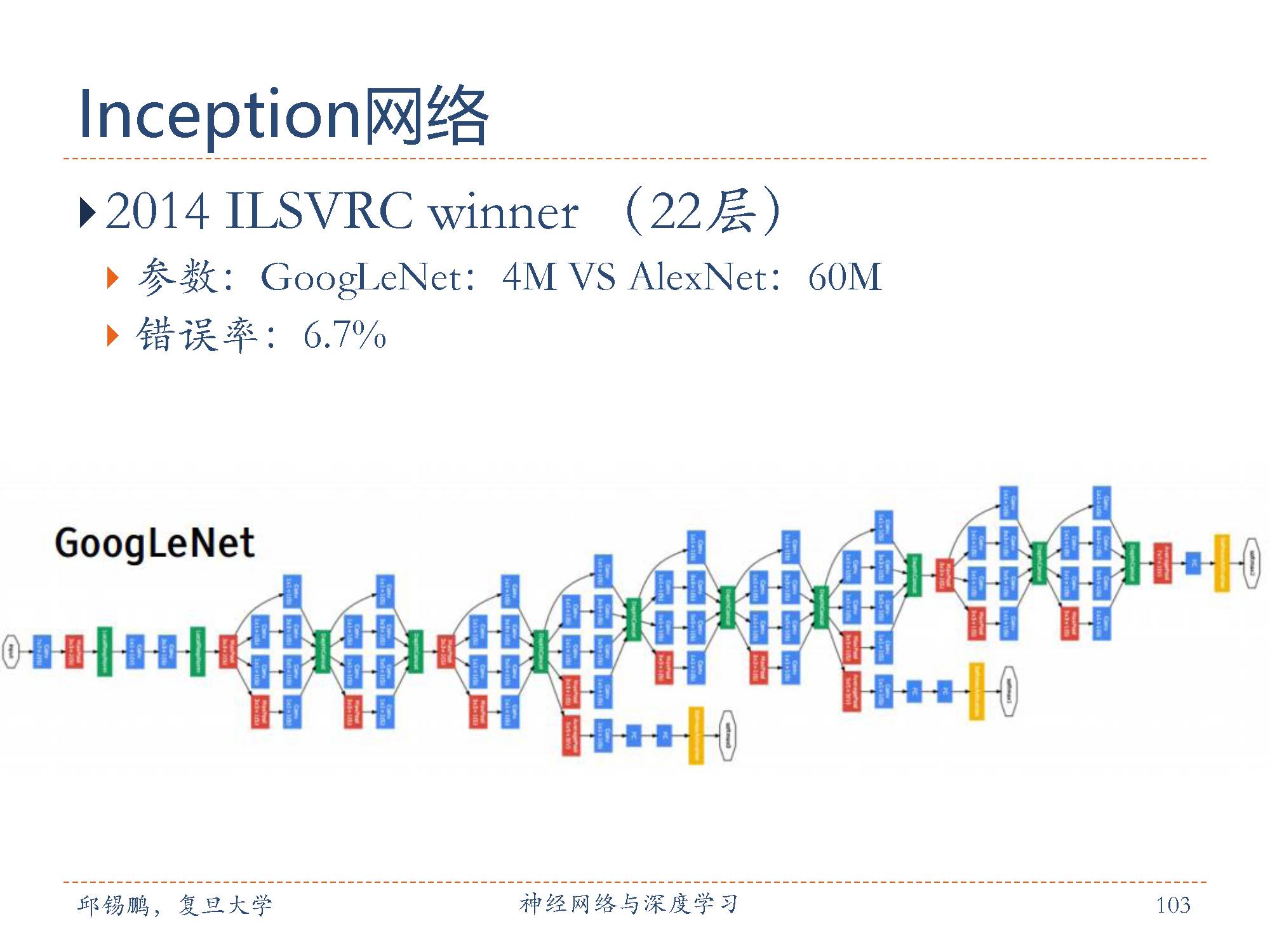
Inception网络最早的v1版本是非常著名的GoogLeNet[Szegedy et al., 2015] (如图5.14),并赢得了2014年ImageNet图像分类竞赛的冠军。
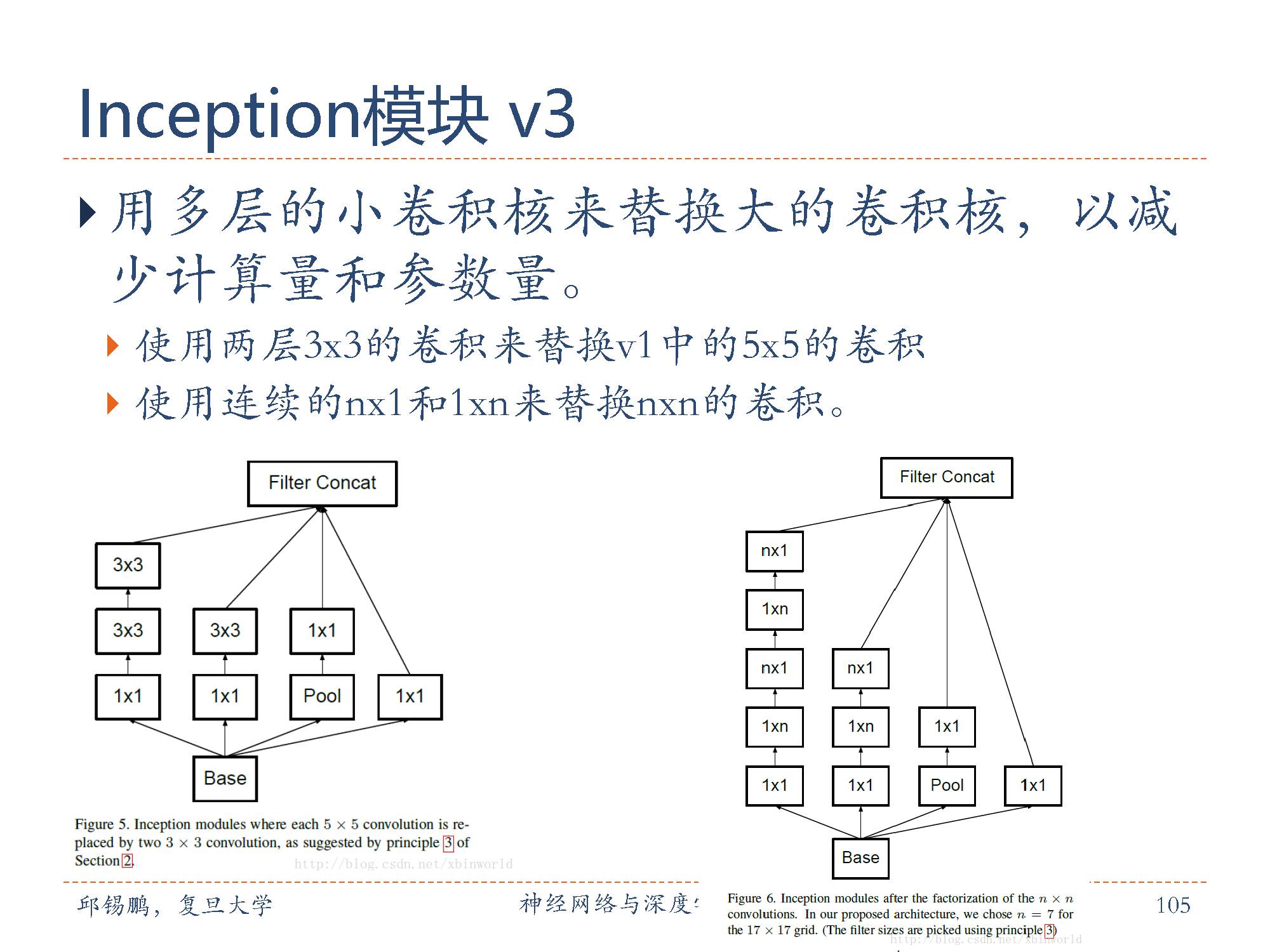
Inception网络有多个改进版本。其中比较有代表性的有Inceptionv3版本 [Szegedy et al., 2016],用多层的小卷积核来替换大的卷积核,以减少计算量和参数量。具体包括(1)使用两层3× 3的卷积来替换v1中的5 × 5的卷;(2)使用连续的n × 1和1 × n来替换n × n的卷积。Inception v3版本同时也引入了标签平滑以及批量归一化等优化方法进行训练。
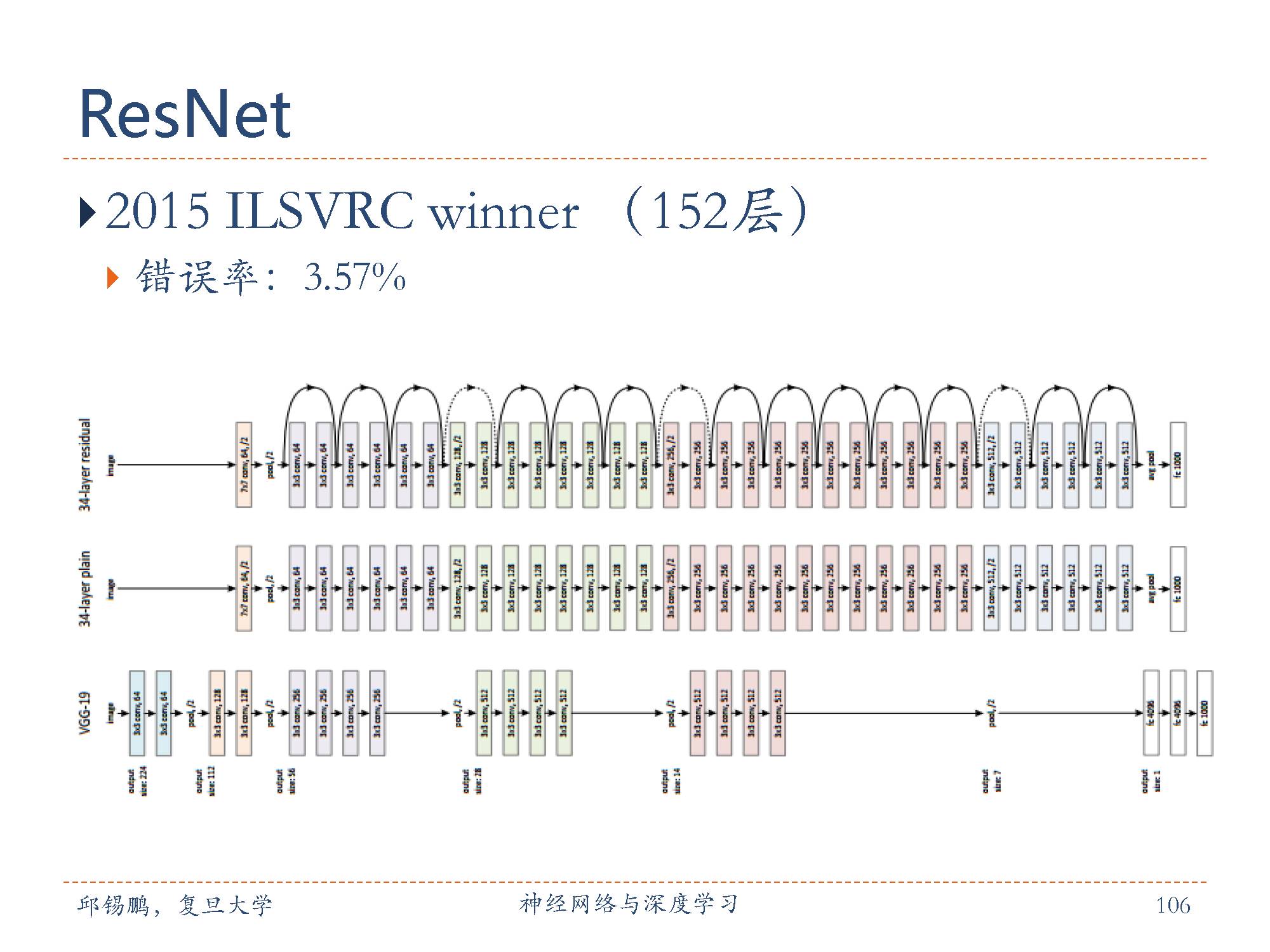
残差网络(residual network,ResNet)是通过给非线性的卷积层增加直连边的方式来提高信息的传播效率。残差网络的思想并不局限与卷积神经网络。
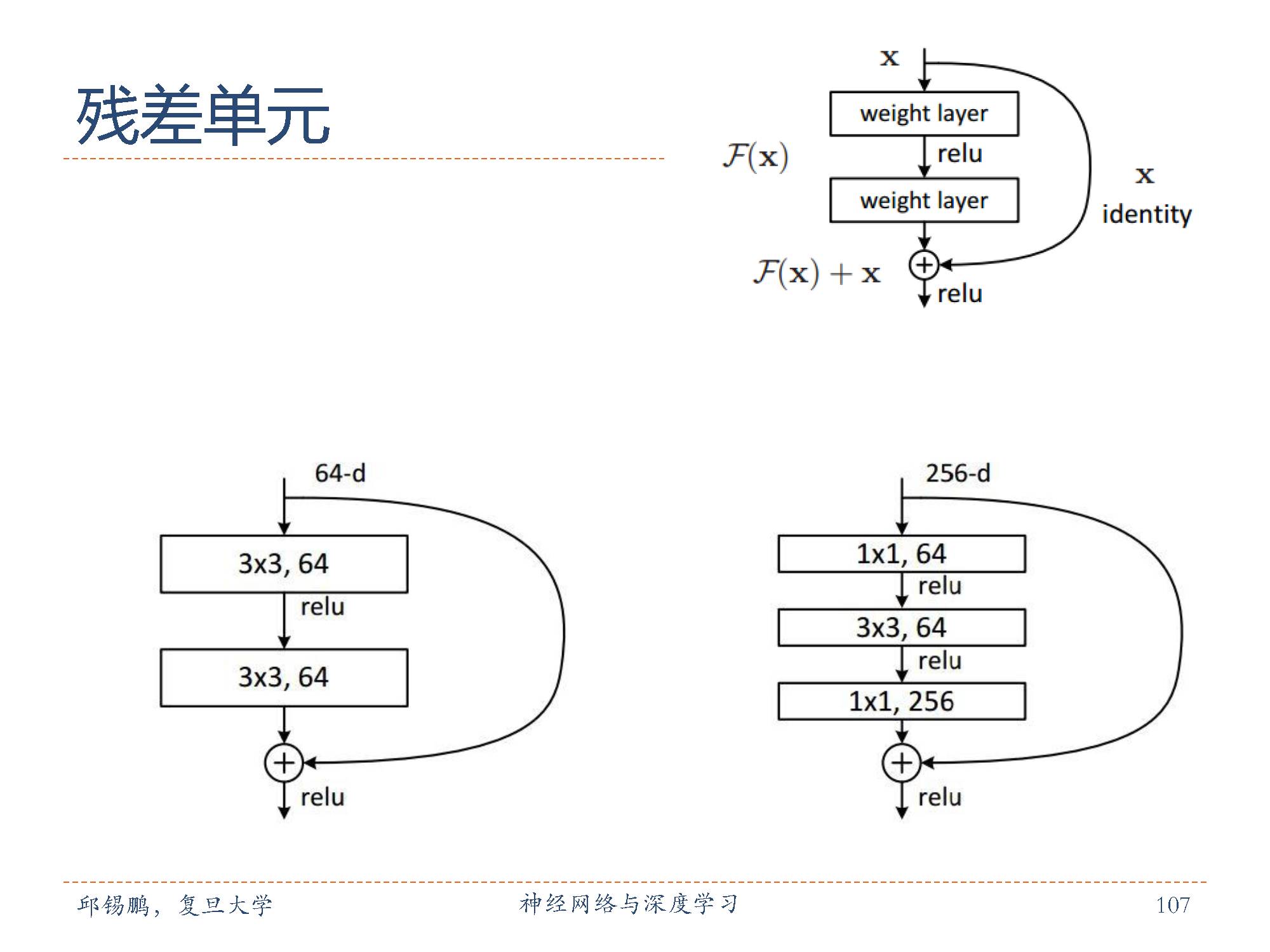
残差单元由多个级联的(等长)卷积层和一个跨层的直连边组成,再经过ReLU激活后得到输出。残差网络就是将很多个残差单元串联起来构成的一个非常深的网络。

AlphaGo的前两个网络都是通过从KGS围棋服务器上获得的3000万个人类高手的对决棋盘状态(Position)进行有监督学习得到的。输入是棋盘状态,输出是人类高手的下一步走子位置。监督学习的策略网络使用了13层的深度卷积神经网络。

Krizhevsky等学习到的滤波器例子。这96个滤波器的尺寸都是[11x11x3],在一个深度切片中,每个滤波器都被55x55个神经元共享。注意参数共享的假设是有道理的:如果在图像某些地方探测到一个水平的边界是很重要的,那么在其他一些地方也会同样是有用的,这是因为图像结构具有平移不变性。所以在卷积层的输出数据体的55x55个不同位置中,就没有必要重新学习去探测一个水平边界了。
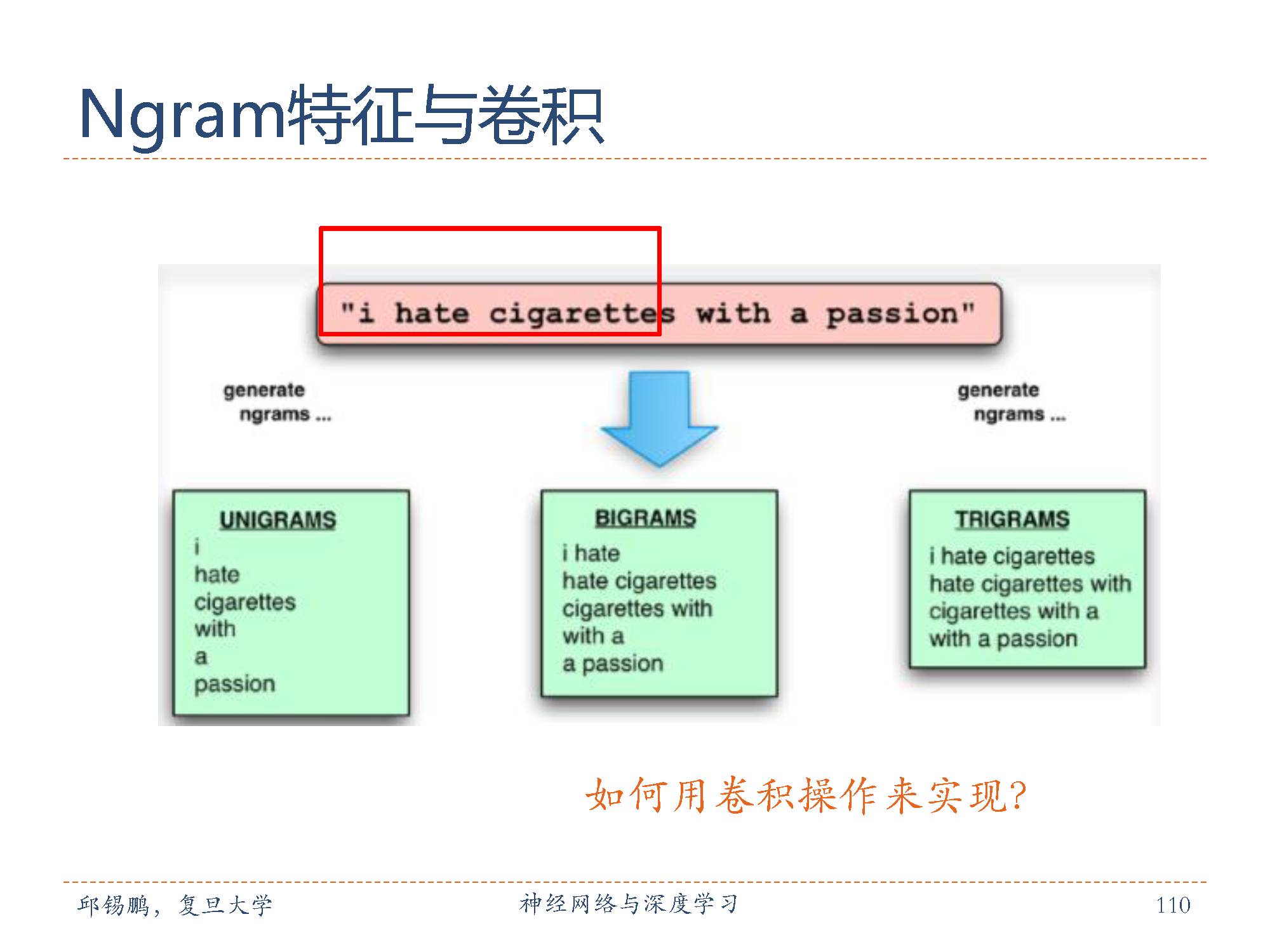
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
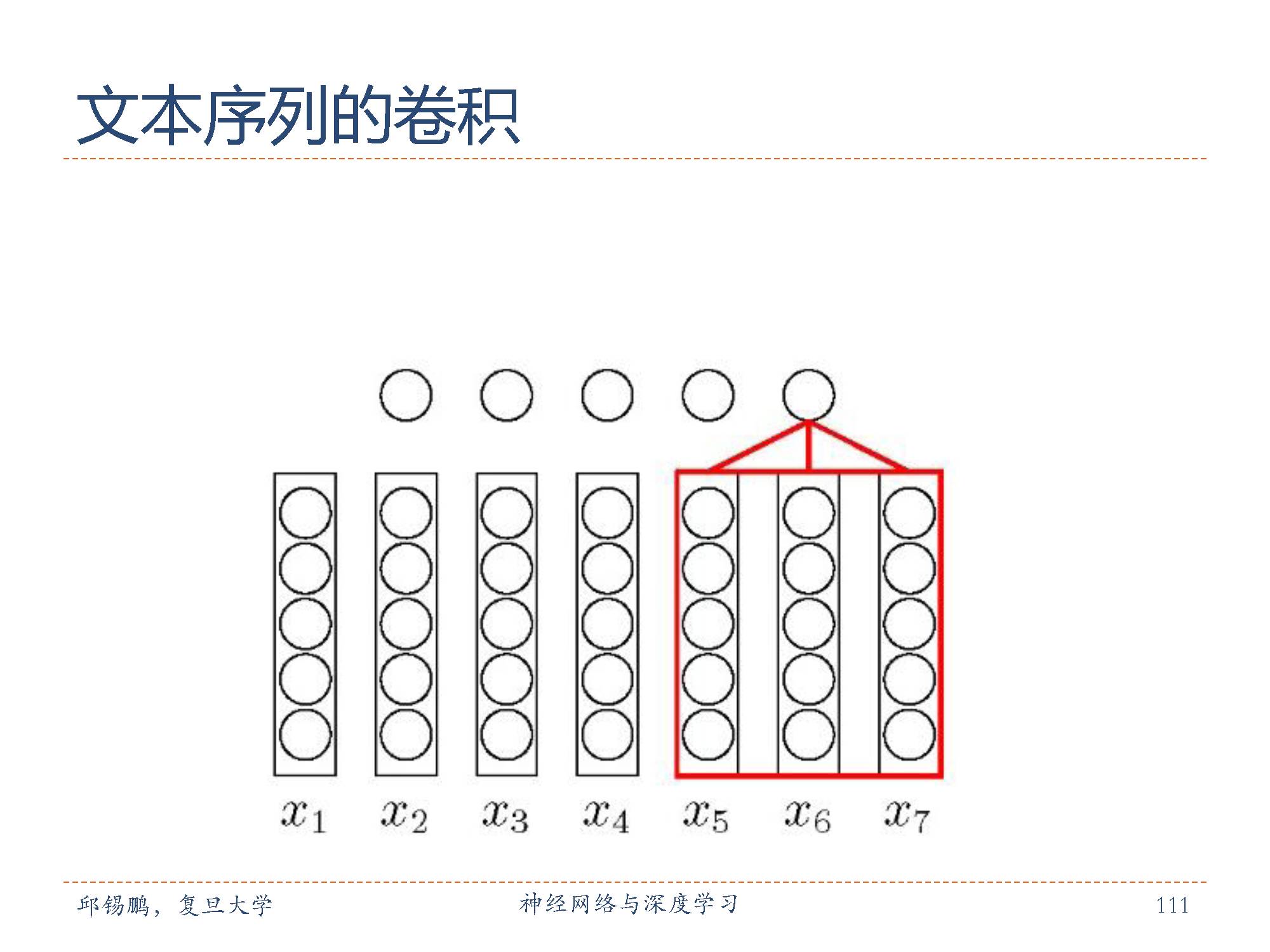
我们把文本序列中的每个词用一个向量表示,则文本序列也可以表示成图像那样的二维形式。卷积核的跨度一般都是词向量的维度。
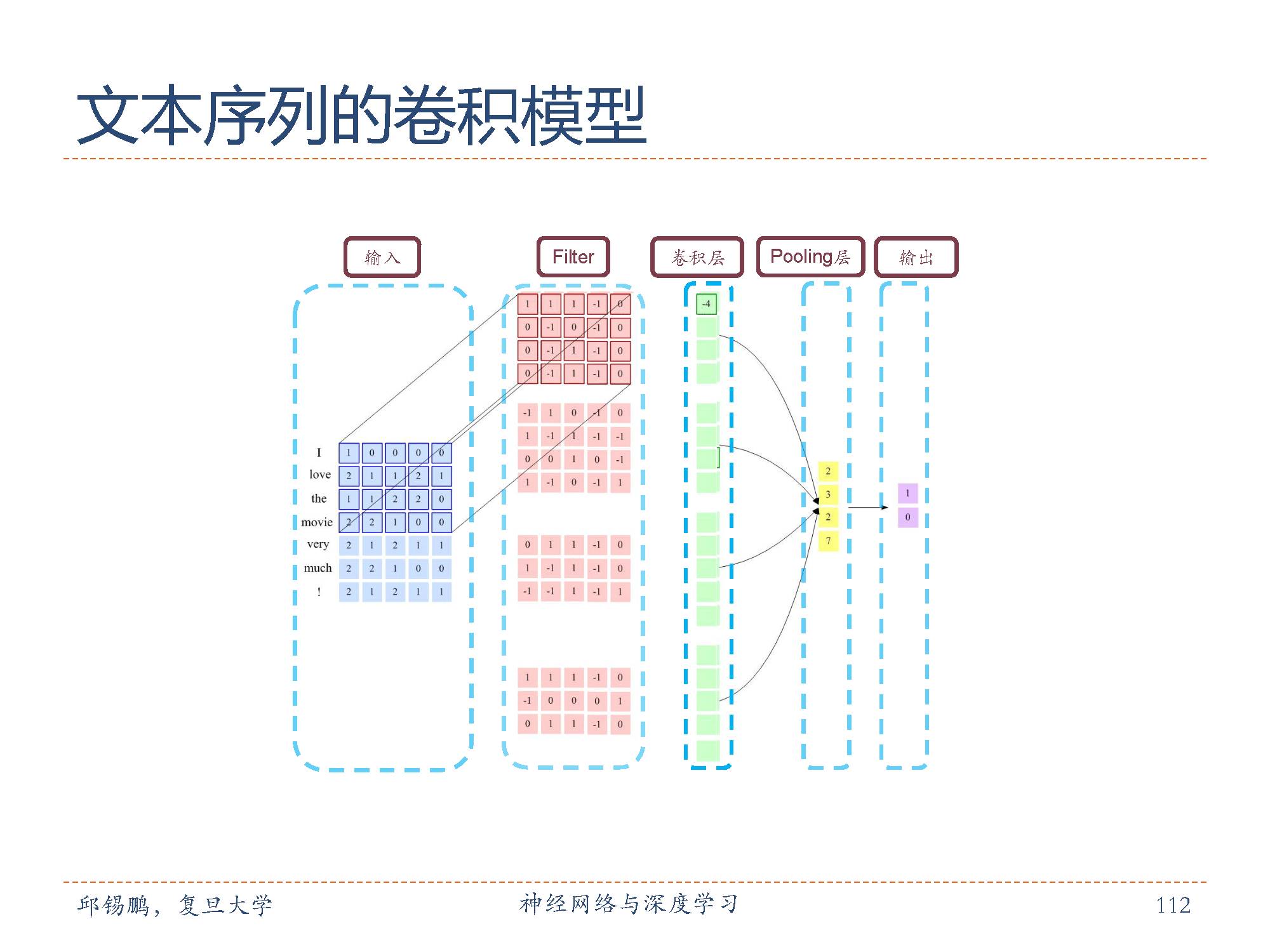
在把文本表示成为二维结构后可以用同样的卷积核汇聚层交替结构来形成卷积网络结构实现对文本的建模。
输入层是一个表示句子的矩阵,每一行是word2vec词向量。接着是由若干个滤波器组成的卷积层,然后是最大池化层,最后是softmax分类器。该论文也尝试了两种不同形式的通道,分别是静态和动态词向量,其中一个通道在训练时动态调整而另一个不变。
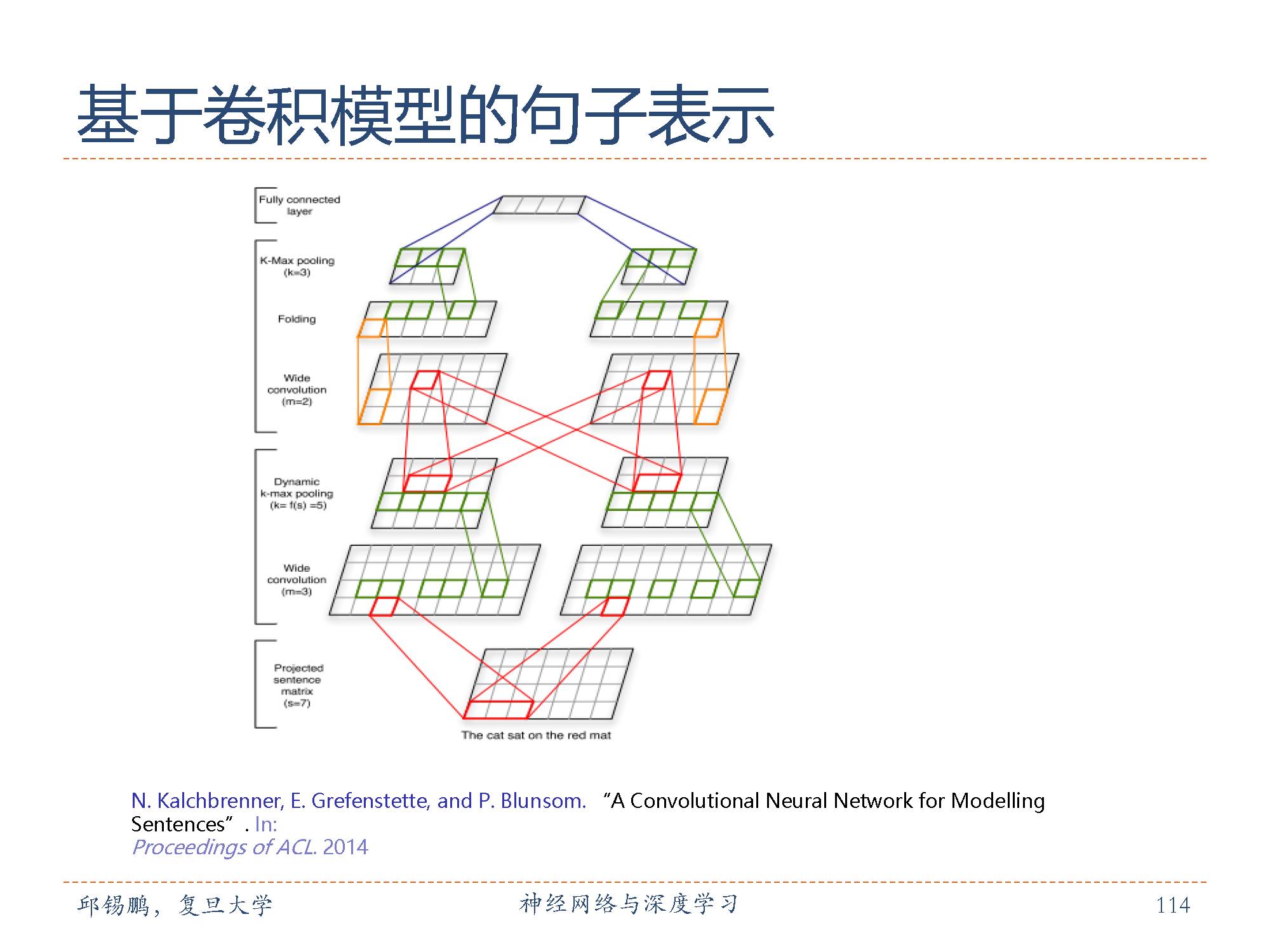
跟的上图类似的结构,但更复杂一些,用于学习整个文本序列的向量表示。
第二部分的深度学习基础模型部分——前馈神经网络和卷积神经网络结束了,敬请期待下一期的深度学习部分-基础模型剩余部分。
特别提示-邱老师深度学习slide-part2下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“nndl2” 就可以获取本部分pdf下载链接~~
请对深度学习感兴趣的同学,扫描如下二维码,加入专知深度学习群,交流学习~

欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请查看更多,登录专知,获取更多AI知识资料,请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录,顶端搜索主题,查看获得对应主题专知荟萃全集知识等资料!如下图所示~
请扫描专知小助手,加入专知人工智能群,交流分享~

专知荟萃知识资料全集获取(关注本公众号-专知,获取下载链接),请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【专知荟萃08】图像描述生成Image Caption知识资料全集(入门/进阶/论文/综述/视频/专家等)
【专知荟萃09】目标检测知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃10】推荐系统RS知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃11】GAN生成式对抗网络知识资料全集(理论/报告/教程/综述/代码等)
【专知荟萃12】信息检索 Information Retrieval 知识资料全集(入门/进阶/综述/代码/专家,附PDF下载)
【专知荟萃13】工业学术界用户画像 User Profile 实用知识资料全集(入门/进阶/竞赛/论文/PPT,附PDF下载)
【专知荟萃14】机器翻译 Machine Translation知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃15】图像检索Image Retrieval知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃16】主题模型Topic Model知识资料全集(基础/进阶/论文/综述/代码/专家,附PDF下载)
-END-
欢迎使用专知
专知,一个新的认知方式! 专注在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



