【干货】计算机视觉实战系列05——用Python做图像处理
【导读】专知成员Hui上一次为大家介绍讲解图像的缩放、图像均匀操作和直方图均衡化,这一次为大家详细讲解主成分分析(PCA)、以及其在图像上的应用。
【干货】计算机视觉实战系列01——用Python做图像处理(基本的图像操作和处理)
【干货】计算机视觉实战系列02——用Python做图像处理(Matplotlib基本的图像操作和处理)
【干货】计算机视觉实战系列03——用Python做图像处理(Numpy基本操作和图像灰度变换)
【干货】计算机视觉实战系列04——用Python做图像处理(图像的缩放、均匀操作和直方图均衡化)

主成分分析(PCA)以及在图像上的应用
▌主成分分析
PCA(Principal Component Analysis,主成分分析)是一个非常有用的降维技巧,它可以在使用尽可能少维数的前提下,尽量多地保持训练数据的信息,在此意义上是一个最佳技巧。
当我们在处理多指标问题时主要存在两个问题,一是为了避免遗漏重要的信息而需要考虑尽可能多的指标,二是由于各指标都是对同一事物的反映,使得彼此间具有相关性。这将导致所观测到的数据在定程度上反映的信息有所重叠,从而大大增加分析问题的复杂性。因此,如果能用较少的综合指标来取代原来较多的原始指标,而这几个综合指标又能尽可能全面地反映原始指标的信息,且彼此之间互不相关,那么将在很大程度上降低处理多指标问题的复杂度。
即使是一幅100x100像素的小灰度图像,也有10000维可以看成是10000维空间中的一个点。一兆像素的图像具有百万维。由于图像具有很高的维数,在许多计算机视觉应用中,我们经常使用降维操作。PCA产生的投影矩阵可以被视为将原始坐标变换到现有的坐标系,坐标系中的各个坐标按照重要性递减排列。
PCA从本质上说,可以看成是找一些投影方向,使得数据在这些投影方向上的方差最大,且这些投影方向是正交的,这其实也是寻找新正交基的过程。为此我们需要计算这些正交基上投影的方差,方差越大就说明在对应正交基上包含了更多的信息量。
对于多维的数据,我们则需要计算数据的协方差矩阵的特征值,其特征值越大,对应的方差就越大,在对应的特征向量上的投影所包含的信息量就越大,反之,如果特征值较小,则说明数据在这些特征向量上的投影的信息量就很小,可以将小特征值对应方向上的数据删除以达到降维的目的。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
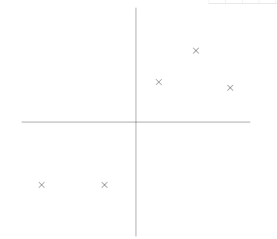
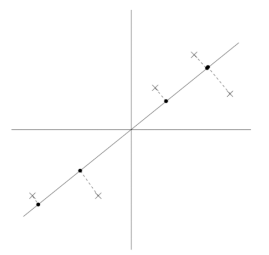
从实际算法实习上来看,PCA主要分为三个部分。(1)生成协方差矩阵;(2)计算特征值和特征向量,并选取主成分;(3)将原始数据投影到降维的子空间中。
第一步生成协方差矩阵首先,什么是协方差矩阵?首先说方差,当我们衡量一组数据的离散程度时,使用方差来表示。即如下所示。
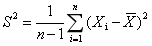
S为方差。即样本中各个数据与其平均值之差的平方的和的平方。在matlab或者numpy中可以利用cov(X,X)计算。但是,该方法只能描述数据自身的离散程度。换句话说,只能描述一维数据。当我们想研究多维数据之间的关系时,就会用到协方差。如下图所示。

当我们研究维数大于2的数据组之间的关系时,便需要用到协方差矩阵。如C表示3维数据的协方差矩阵,对角线上为X,Y,Z各自的方法,其他位置表示数据之间的协方差。协方差越小,数据越相关。
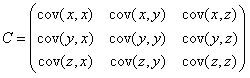
那么如何计算协方差矩阵,matlab和numpy都可以利用cov(x)进行直接计算。注意这个地方输入的X为一个矩阵,在matlab中默认每一列为一个一维数据,行数代表了数据组的维数。其实现方法主要有以下两种:一是依据定义计算,即将每一组数据减去该数据的平均值再与另一组数据的结果相乘,除以n-1.第二种是简化的去中心化方法。值得注意的是numpy中的cov函数与matlab不同,其将每一行作为一个一维数据。因此利用cov进行计算,需先对其转置。
PCA的具体步骤:
首先需要让整个数据集的均值为0,如果这个数据集的均值已经是0,则此步骤忽略;
接下来我们需要更新每个属性的数据使得在同一个属性上的数据具有单位方差(归一化),从而保证不同的属性都有相同的数据范围而受到“平等对待”,打个比方,如果属性x1表示汽车的最快时速,用mph来表示,数据范围通常在大几十到一百多,x2表示汽车的座位数,数据范围通常在2-4,此时就需要重新标准化这两个不同的属性使他们更有可比性,当然,如果我们已经得知不同的属性具有相同的数据规模时此步骤可以省略,例如当每个数据点代表一个灰度图像时,此时每个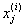
现在,我们已经执行了数据的标准化,接下来该计算“数据差异主要所在”的轴u,即数据主要集中的方向,解决这个问题的方法是找到一个单位向量u使得当数据投影到这个方向时,投影数据的方差最大化,直观上理解,数据集中包含了数据的方差和数据信息,我们应该选择一个方向u使得我们能近似的让这些数据集中在u代表的方向或者子空间上,并且尽可能的保留这些数据的方差。
PCA的代码:
我们定义一个PCA的函数:
from PIL import Image
from numpy import *
from pylab import *
def pca(X):
num_data, dim = X.shape # 获取维数
mean_X = X.mean(axis=0) # 数据中心化
X = X - mean_X
if dim > num_data:
# 使用紧致技巧
M = dot(X, X.T) # 协方差矩阵
e, EV = linalg.eight(M) # 特征值和特征向量
tmp = dot(X.T, EV) # 紧致技巧
V = tmp[::-1] # 由于最后的特征向量是我们所需要的,所以要将其逆转
S = sqrt(e)[::-1] # 由于特征值是按照递增顺序排列的,所以需要将其逆转
for i in range(V.shape[1]):
V[:, i] /= S
else:
U, S, V = linalg.svd(X)
V = V[:num_data] # 仅仅返回前num_data维的数据才合理
return V, S, mean_X
这个函数中输入军阵X其中该矩阵中存储训练数据,每一行为一条训练数据,返回的是投影矩阵(按照维度的重要性排序)、方差和均值。
该函数首先通过减去每一维的均值将数据中心化,然后计算协方差矩阵对应最大特征值的特征向量,此时可以使用简明的技巧或者SVD分解。这里我们使用了range()函数该函数的输入参数为一个整数n,函数返回整数0,...,(n-1)的一个列表。当然你也可以用arrange()函数来返回一个数组,或者用xrange()函数返回一个产生器(可能会提升速度)。
如果数据个数小于向量维数,我们就不用SVD分解,而是计算维数更小的协方差矩阵的特征向量。通过仅计算对应前k(k是降维后的维数)最大特征值的特征向量可以使上面PCA操作更快。矩阵V的每行向量都是正交的,并且包含了训练数据方差依次减少的坐标方向。
▌主成分分析在图像上的应用
接下来我们利用上面定义的PCA函数对图像数据集进行PCA分解:
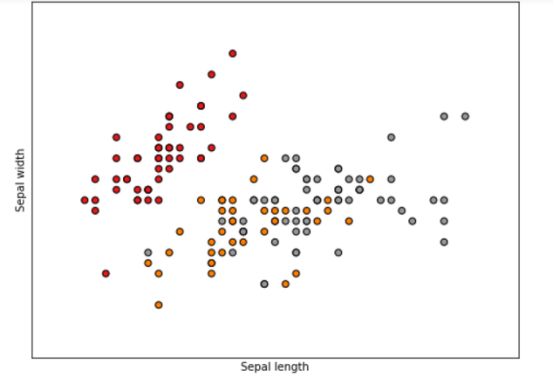
这里我们借助iris数据集,这个数据是一个简易有趣的数据集,是由三种鸢尾花,各50组数据构成的数据集。这个数据集来源于科学家在一岛上找到一种花的三种不同亚类别,分别叫做setosa,versicolor,virginica。但是这三个种类并不是很好分辩,所以他们又从花萼长度,花萼宽度,花瓣长度,花瓣宽度这四个角度测量不同的种类用于定量分析。基于这四个特征,这些数据成了一个多重变量分析的数据集。

import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 三维绘图工具包
from sklearn import datasets
from sklearn.decomposition import PCA
# 导入一些数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 取数据集的前两个特征
y = iris.target # 取出类别
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
plt.figure(2, figsize=(8, 6))
plt.clf() # 清除整个当前数字。
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1,
edgecolor='k') # 绘制散点图,设置颜色为黑色
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(()) # 为x,y轴的主刻度和次刻度设置颜色、大小、方向,以及标签大小
# To getter a better understanding of interaction of the dimensions
# plot the first three PCA dimensions
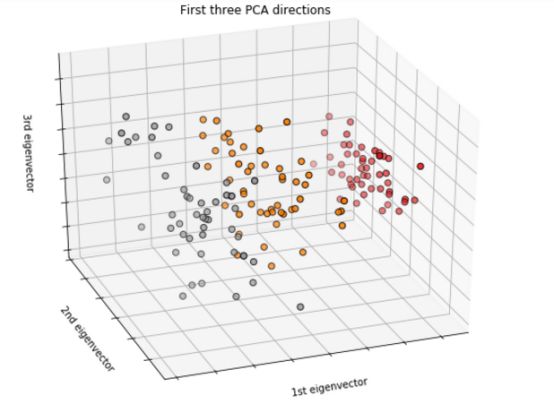
fig = plt.figure(1, figsize=(8, 6))
ax = Axes3D(fig, elev=-150, azim=110)
X_reduced = PCA(n_components=3).fit_transform(iris.data)
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=y,
cmap=plt.cm.Set1, edgecolor='k', s=40)
ax.set_title("First three PCA directions")
ax.set_xlabel("1st eigenvector")
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel("2nd eigenvector")
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel("3rd eigenvector")
ax.w_zaxis.set_ticklabels([])
plt.show()
sklearn中的iris 是python的数据集,有5个key:[‘target_names’, ‘data’, ‘target’, ‘DESCR’, ‘feature_names’]
target_names : 分类名称 [‘setosa’ ‘versicolor’ ‘virginica’]
target:分类(150个) (150L,)
feature_names: 特征名称 (‘feature_names:’, [‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’])
data : 特征值 (150L, 4L)
data[0]:[ 5.1 3.5 1.4 0.2]
输出的结果为:
参考文献:
python计算机视觉编程:http://yongyuan.name/pcvwithpython/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
展开全文



