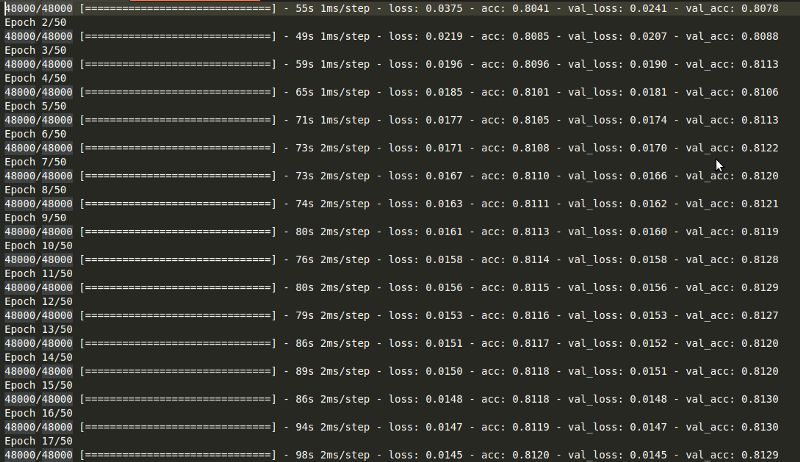
【干货】7种最常用的机器学习算法衡量指标
【导读】你可能在你的机器学习研究或项目中使用分类精度、均方误差这些方法衡量模型的性能。当然,在进行实验的时候,一种或两种衡量指标并不能说明一个模型的好坏,因此我们需要了解常用的几种机器学习算法衡量指标。本文整理介绍了7种最常用的机器学习算法衡量指标:分类精度、对数损失、混淆矩阵、曲线下面积、F1分数、平均绝对误差、均方误差。相信阅读之后你能对这些指标有系统的理解。
Metrics to Evaluate your Machine Learning Algorithm
评估机器学习算法是项目的一个重要部分。你的模型可能在用一个指标来评论时能得到令人满意的结果,但用其他指标(如对数损失或其他指标)进行评估时,可能会给出较差的结果。大多数时候,我们使用分类的准确性来衡量我们的模型的性能,然而这还不足真正判断我们的模型。在这篇文章中,我们将介绍可用的不同类型的评估指标。
分类精度
对数损失
混淆矩阵
曲线下面积(Area under Curve)
F1分数
平均绝对误差
均方误差
1. 分类精度
当我们使用“准确性”这个术语时,指的就是分类精度。它是正确预测数与样本总数的比值。
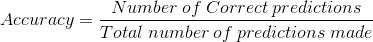
只有当属于每个类的样本数量相等时,它才有效。
例如,假设在我们的训练集中有98%的A类样本和2%的B类样本。然后,我们的模型可以通过简单预测每个训练样本都属于A类而轻松获得98%的训练准确性。
当在60%A级样品和40%B级样品的测试集上采用相同的模型时,测试精度将下降到60%。分类准确度很重要,但是它有时会带给我们一种错觉,使我们认为模型已经很好。
真正的问题出现在,当少量样本类被误分类造成很大的损失的情况下。如果我们处理一种罕见但致命的疾病,那么真正的患者未被诊断出疾病的造成的损失远高于健康人未被诊断出疾病。
2. 对数损失
对数损失,通过惩罚错误的分类来工作。它适用于多类分类。在处理对数损失时,分类器必须为所有样本分配属于每个类的概率。假设,有N个样本属于M类,那么对数损失的计算如下:
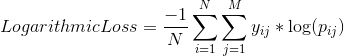
这里,
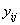
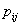
对数损失的值没有上限,它取值于[0,∞)范围内。对数损失接近0表示其有高的准确性,而如果对数损失远离0则表明准确度较低。
一般来说,最大限度地减少对数损失可以提高分类精度。
3. 混淆矩阵
混淆矩阵顾名思义,通过一个矩阵描述了模型的完整性能。
假设我们有一个二元分类问题。我们有一些样本,它们只属于两个类别:是或否。另外,我们有自己的分类器,它用来预测给定输入样本的类。我们在165个样品上测试了我们的模型,得到了如下结果:
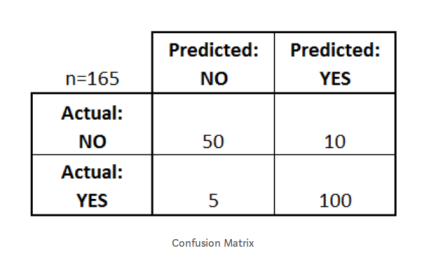
有四个重要的术语:
True Positives:我们预测“是”并且实际产出也是“是”的情况。
True Negatives:我们预测“否”和实际产出也是“是”的情况。
False Positives:我们预测“是”并且实际产出也是“否”的情况。
False Negatives:我们预测“否”并且实际产出也是“否”的情况。
矩阵的精度可以通过取过“主对角线”的平均值来计算。即,
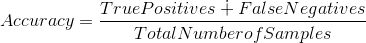
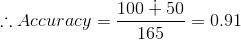
混淆矩阵是其他度量类型的基础。
4. 曲线下面积(Area Under Curve, AUC)
曲线下面积(AUC)是评估中使用最广泛的指标之一。 它用于二分类问题。分类器的AUC等价于分类器随机选择正样本高于随机选择负样本的概率。 在定义AUC之前,让我们理解两个基本术语:
True Positive Rate (真阳性率):它被定义为TP /(FN + TP)。 对于所有正数据点,它对应于正数据点被正确认为是正的比例。
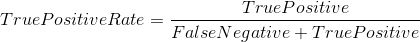
False Positive Rate (假阳性率) :它被定为FP /(FP + TN)。即对应于所有负数据点,负数据点被错误地认为是正的比例。
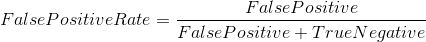
False Positive Rate 和 True Positive Rate的值均在[0,1]范围内。FPR和TPR机器人在阈值如(0.00,0.02,0.04,...,1.00)下计算并绘制对应图形。AUC是[0,1]中不同点的False Positive Rate对True Positive Rate曲线下的面积。
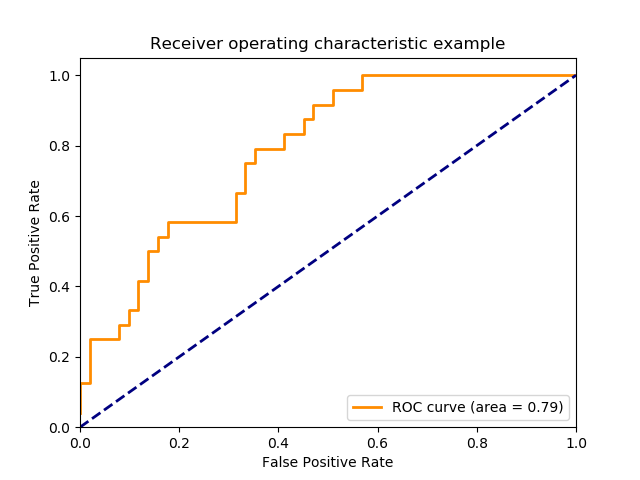
很明显,AUC的范围是[0,1]。 值越大,我们模型的性能越好。
5. F1 分数
F1分数用于衡量测试的准确性
F1分数是精确度和召回率之间的调和平均值(Harmonic Mean)。 F1分数的范围是[0,1]。 它会告诉您分类器的精确程度(正确分类的实例数),以及它的稳健程度(它不会错过大量实例)。
高精度和低召回率,会带来高的精度,但也会错过了很多很难分类的实例。 F1得分越高,我们模型的表现越好。 在数学上,它可以表示为:
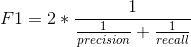
F1分数试图找到精确度和召回率之间的平衡。
Precision :它是正确的正结果的数目除以分类器所预测的正结果的数目。

Recall:它是正确的正结果的数量除以所有相关样本(即所有应该被识别为正结果的样本)的数量。
6. 平均绝对误差
平均绝对误差是原始值与预测值之差的平均值。 它衡量预测与实际输出还差多远。 但是,它们并没有给我们提供任何关于错误方向的信息,即不能给出我们的模型到底是低于预测数据还是高于预测数据。 在数学上,它表示为:
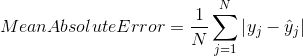
7. 均方误差
均方误差(MSE)与平均绝对误差非常相似,唯一的区别是MSE取原始值与预测值之差的平方的平均值。 MSE的优点是计算梯度更容易,而平均绝对误差需要复杂的线性编程工具来计算梯度。 由于我们采用误差的平方,更大的误差的影响变得更明显,因此模型现在可以更多地关注更大的误差。
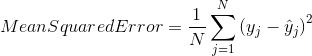
参考
http://www.exegetic.biz/blog/2015/12/making-sense-logarithmic-loss/
http://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/
http://scikit-learn.org/stable/modules/classes.html#sklearn-metrics-metrics
https://stats.stackexchange.com/questions/49226/how-to-interpret-f-measure-values
https://stats.stackexchange.com/questions/132777/what-does-auc-stand-for-and-what-is-it
参考文献:
https://towardsdatascience.com/metrics-to-evaluate-your-machine-learning-algorithm-f10ba6e38234
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



