【伯克利博士论文】统计与优化—统计学习算法的计算保障(附143页PDF全文下载)
【导读】作者Fanny Yang是UC伯克利大学的博士生,主要研究方向为统计与优化交叉领域算法,同时致力于生物医学与机器学习问题研究。近期,在校内做了论文报告,并公开发布了他的博士论文,本期特编译如下。
介绍:
现代科技的进步,促使大量的现代领域(例如机器学习以及很多传统学科)开始收集大规模数据集。这导致了对可扩展机器学习算法和统计方法的需求正不断增加。在所有数据驱动的场景中,数据科学家面临了如下的基本问题:1、应该如何设计学习算法;2、应该运行多长时间;3、应该收集哪些样本进行培训;4、哪些样本足以将将结论推广到看不见的数据上去。这些问题涉及数据和算法的统计与计算属性。本文探讨了它们在非凸优化、非参数估计、主动学习和多重测试领域的作用。

本论文的第一部分中,我们提供了关于一阶类型方法在共同估计过程中的统计和计算属性的相互作用过程。EM算法通过在非凸问题上运行一阶类型方法来估计潜变量模型的参数。对于非参数估计问题,使用函数梯度下降类型算法来估计无限维函数空间中的最佳拟合。我们涉及了一种新的证明技术,表明早期停止算法可能会产生一个没有明确正则化的最优估计,
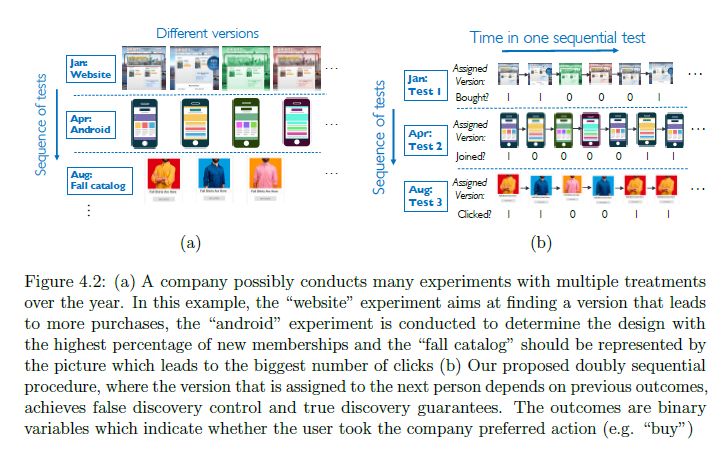
在论文的第二部分中,我们探讨了如何使用不断更新的估计,自适应地收集数据可以导致多个假设检验问题的样本复杂性显著降低。特别的,我们展示了如何使用自适应策略来同时控制多个测试中的错误发现率,并以在线方式以最佳样本复杂度为每个测试返回最佳替代。

内容大纲:
论文内容主要分为两大部分:估计(Estimation)与检验(Testing)。
Chapter 2: Guarantees for the Baum-Welch Algorithm
在这部分中,作者首先介绍了隐马尔可夫过程的重要地位,同时说明了传统最大似然估计的方法不能很好的得到非凸问题的最优解。因此需要引入Baum-Welch 算法,它可以被理解为是EM算法的一个特例,可以对隐马尔可夫模型进行最大似然估计。但尽管此算法应用广泛,但它仍然可能陷入局部最优解,如何理解这种行为,是过去几十年里的主要工作之一。

Chapter 3: Early stopping of kernel boosting
当非参数模型提供了很大的灵活性的同时,也可能导致过拟合问题,以及更差的泛化性能。因此,在这一部分必须提供某种形式的正则项,来规避这一问题。

Chapter 4: Adaptive Sampling for Multiple testing
本部份,作者介绍了多种检验指标下的自适应采样方法设计过程。

参考链接:
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2018/EECS-2018-126.html
作者主页:
http://fanny-yang.de/
其他更多详情,下载全文查看:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“SOCGSLA” 就可以获取论文的下载链接~
专知2019年1月将开设一门《深度学习:算法到实战》讲述相关ML2018论文,欢迎关注报名!
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!
-END-
专 · 知
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



