【干货】Batch Normalization: 如何更快地训练深度神经网络
【导读】本文是谷歌机器学习工程师 Chris Rawles 撰写的一篇技术博文,探讨了如何在 TensorFlow 和 tf.keras 上利用 Batch Normalization 加快深度神经网络的训练。我们知道,深度神经网络一般非常复杂,即使是在当前高性能GPU的加持下,要想快速训练深度神经网络依然不容易。Batch Normalization 也许是一个不错的加速方法,本文介绍了它如何帮助解决梯度消失和梯度爆炸问题,并讨论了ReLu激活以及其他激活函数对于抵消梯度消失问题的作用。最后,本文使用TensorFlow和tf.keras实现了在MNIST上Batch Normalization,有助于加深读者理解。

How to use Batch Normalization with TensorFlow and tf.keras to train deep neural networks faster
训练深度神经网络可能非常耗时。但是可以通过消除梯度来显着地减少训练时间,这种情况发生在网络由于梯度(特别是在较早的层中的梯度)接近零值而停止更新。 结合Xavier权重初始化和ReLu激活功能有助于抵消消失梯度问题。 这些技术也有助于解决与之相反的梯度爆炸问题,这种情况下梯度变得非常大,它防止模型更新。
批量标准化(Batch Normalization)也许是对付梯度消失和爆炸问题的最有力工具。 批量标准化的工作方式如下:对于给定层中的每个单元,首先计算z分数,然后在两个受过训练的变量γ和β应用线性转换。 批量标准化通常在非线性激活函数之前完成(参见下文),但在激活函数之后应用批量标准也可能是有利的。 查看这个讲座了解该技术如何工作的更多细节。
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
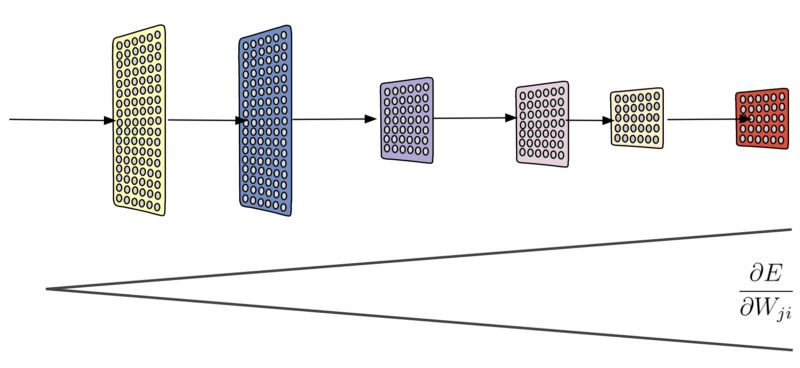
在反向传播过程中,梯度倾向于在较低层里变得更小,从而减缓权重更新并因此减少训练次数。 批量标准化有助于消除所谓的梯度消失问题。
批量标准化可以在TensorFlow中以三种方式实现。使用:
1. tf.keras.layers.BatchNormalization
2. tf.layers.batch_normalization
3. tf.nn.batch_normalization
tf.keras模块成为1.4版TensorFlow API的核心的一部分。 并为构建TensorFlow模型提供高级API; 所以我会告诉你如何在Keras做到这一点。tf.layers.batch_normalization函数具有类似的功能,但Keras被证明是在TensorFlow中编写模型函数的一种更简单的方法。
in_training_mode = tf.placeholder(tf.bool)
hidden = tf.keras.layers.Dense(n_units,
activation=None)(X) # no activation function, yet
batch_normed = tf.keras.layers.BatchNormalization()(hidden, training=in_training_mode)
output = tf.keras.activations\
.relu(batch_normed) # ReLu is typically done after batch normalization
# optimizer code here …
extra_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_ops):
train_op = optimizer.minimize(loss)
注意批量标准化函数中的训练变量。 这是必需的,因为批量标准化在训练期间与应用阶段的操作方式不同。在训练期间,z分数是使用批均值和方差计算的,而在推断中,则是使用从整个训练集估算的均值和方差计算的。
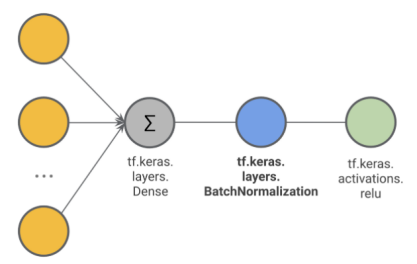
在TensorFlow中,批量标准化可以使用tf.keras.layers作为附加层实现。
包含tf.GraphKeys.UPDATE_OPS的第二个代码块很重要。对于网络中的每个单元,使用tf.keras.layers.BatchNormalization,TensorFlow会不断估计训练数据集上权重的均值和方差。这些存储的值用于在预测时间应用批量标准化。 每个单元的训练集均值和方差可以通过打印extra_ops来观察,extra_ops包含网络中每图层的列表:
print(extra_ops)
[<tf.Tensor ‘batch_normalization/AssignMovingAvg:0’ shape=(500,) dtype=float32_ref>,
# layer 1 mean values
<tf.Tensor ‘batch_normalization/AssignMovingAvg_1:0’ shape=(500,) dtype=float32_ref>,
# layer 1 variances ...]
虽然批量标准化在tf.nn模块中也可用,但它需要额外的记录,因为均值和方差是函数的必需参数。 因此,用户必须在批次级别和训练集级别上手动计算均值和方差。 因此,它是一个比tf.keras.layers或tf.layers更低的抽象层次;应避免用tf.nn实现。
▌在MNIST上批量标准化
下面,我使用TensorFlow将批量标准化应用到突出的MNIST数据集。 看看这里的代码。 MNIST是一个易于分析的数据集,不需要很多层就可以实现较低的分类错误。 但是,我们仍然可以构建深度网络并观察批量标准化如何实现收敛。
我们使用tf.estimator API构建自定义估算器。 首先我们建立模型:
def dnn_custom_estimator(features, labels, mode, params):
in_training = mode == tf.estimator.ModeKeys.TRAIN
use_batch_norm = params['batch_norm']
net = tf.feature_column.input_layer(features, params['features'])
for i, n_units in enumerate(params['hidden_units']):
net = build_fully_connected(net, n_units=n_units, training=in_training,
batch_normalization=use_batch_norm,
activation=params['activation'],
name='hidden_layer' + str(i))
logits = output_layer(net, 10, batch_normalization=use_batch_norm,
training=in_training)
predicted_classes = tf.argmax(logits, 1)
loss = tf.losses.softmax_cross_entropy(onehot_labels=labels, logits=logits)
accuracy = tf.metrics.accuracy(labels=tf.argmax(labels, 1),
predictions=predicted_classes,
name='acc_op')
tf.summary.scalar('accuracy', accuracy[1]) # for visualizing in TensorBoard
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss,
eval_metric_ops={'accuracy': accuracy})
# Create training op.
assert mode == tf.estimator.ModeKeys.TRAIN
extra_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
optimizer = tf.train.AdamOptimizer(learning_rate=params['learning_rate'])
with tf.control_dependencies(extra_ops):
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
在我们定义模型函数之后,让我们构建自定义估计器并训练和评估我们的模型:
def train_and_evaluate(output_dir):
features = [tf.feature_column.numeric_column(key='image_data', shape=(28*28))]
classifier = tf.estimator.Estimator(model_fn=dnn_custom_estimator,
model_dir=output_dir,
params={'features': features,
'batch_norm': USE_BATCH_NORMALIZATION,
'activation': ACTIVATION,
'hidden_units': HIDDEN_UNITS,
'learning_rate': LEARNING_RATE})
train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn, max_steps=NUM_STEPS)
eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn)
tf.estimator.train_and_evaluate(classifier, train_spec, eval_spec)
train_and_evaluate('mnist_model')
让我们来测试批量标准化如何影响不同深度的模型。将我们的代码打包到Python包后,我们可以使用Cloud ML Engine并行执行多个实验:
# def ml-engine function
submitMLEngineJob() {
gcloud ml-engine jobs submit training $JOBNAME \
--package-path=$(pwd)/mnist_classifier/trainer \
--module-name trainer.task \
--region $REGION \
--staging-bucket=gs://$BUCKET \
--scale-tier=BASIC \
--runtime-version=1.4 \
-- \
--outdir $OUTDIR \
--hidden_units $net \
--num_steps 1000 \
$batchNorm
}
# launch jobs in parallel
export PYTHONPATH=${PYTHONPATH}:${PWD}/mnist_classifier
for batchNorm in '' '--use_batch_normalization'
do
net=''
for layer in 500 400 300 200 100 50 25;
do
net=$net$layer
netname=${net//,/_}${batchNorm/--use_batch_normalization/_bn}
JOBNAME=mnist$netname_$(date -u +%y%m%d_%H%M%S)
OUTDIR=gs://${BUCKET}/mnist_models/mnist_model$netname/trained_model
echo $OUTDIR $REGION $JOBNAME
gsutil -m rm -rf $OUTDIR
submitMLEngineJob
net=$net,
done
done
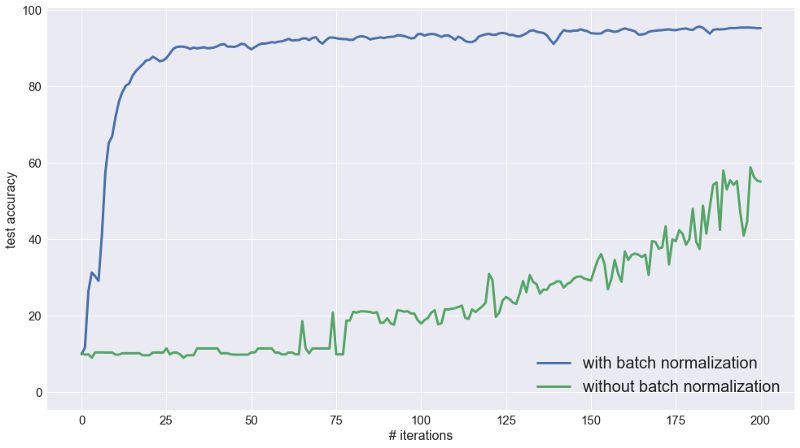
下图显示了达到90%测试精度所需的训练迭代次数(1次迭代包含的批次大小为500)。 很明显,批量标准化显著加快了深度网络的训练。如果没有批量标准化,随着每个后续层的增加,训练步骤的数量都会增加,但使用它后,训练步数几乎保持不变。 在实践中,它是面对更困难的数据集,更多层网络结构时取得成功的先决条件。
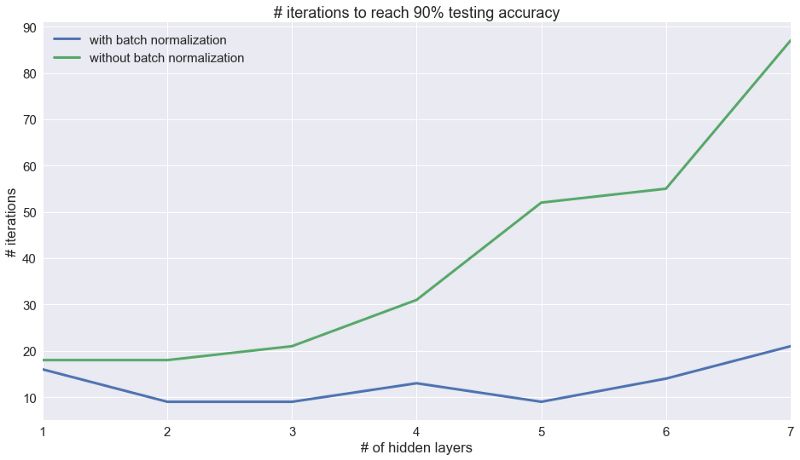
如果没有批量标准化,达到90%准确度所需的训练迭代次数会随着层数的增加而增加,这可能是由于梯度消失造成的。
同样,如下所示,对于具有7个隐藏层的全连接的网络,没有批量标准化的收敛时间较慢
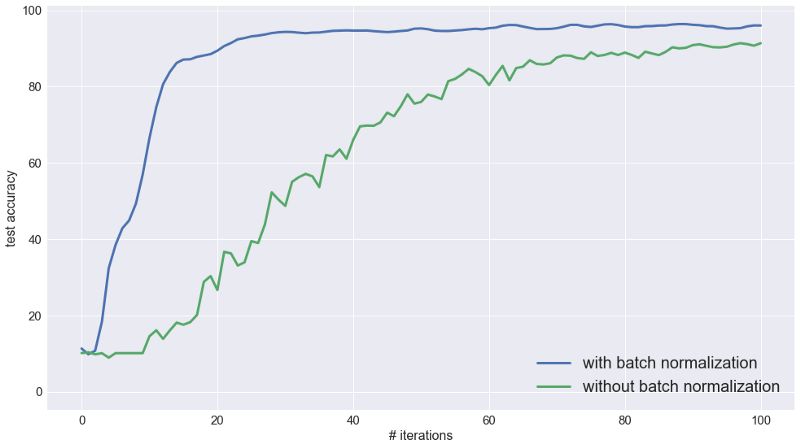
上述实验利用了常用的ReLu激活功能。 虽然不能像上面所示一样抵挡梯度消失带来的效应,ReLu激活比Sigmoid或tanh激活功能要好得多。 Sigmoid激活函数对梯度消失很无力。在更大的数值(非常正或负)时,sigmoid函数“饱和” 即S形函数的导数接近零。 当越来越多节点饱和时,更新次数减少,网络停止训练。
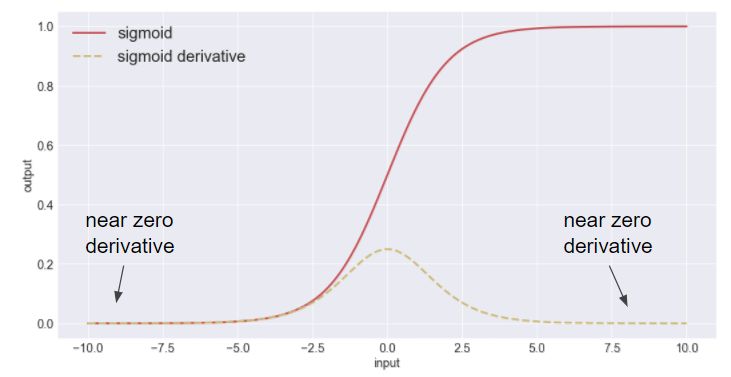
使用sigmoid激活函数而不使用批量标准化,相同的7层网络训练会显著减慢。当使用批量标准化,网络达到收敛时的迭代次数与使用ReLu相似。
另一方面,其他激活函数(如指数ReLu或泄漏ReLu函数)可以帮助抵制梯度消失问题,因为它们对于正数和负数都具有非零导数。
最后,重要的是要注意批量标准化会给训练带来额外的时间成本。 尽管批量标准化通常会减少达到收敛的训练步数,但它会带来额外的时间成本,因为它引入了额外的操作,并且还给每个单元引入了两个新的训练参数。
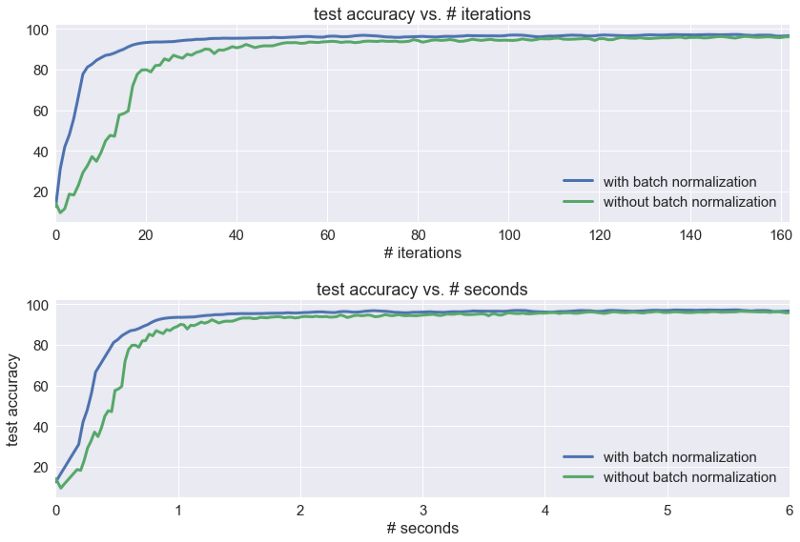
对于MNIST分类问题(使用1080 GTX GPU),批量标准化能在较少的迭代次数收敛,但每次迭代的时间较慢。 最终,批量标准化版本的收敛速度仍然较快,但整合训练时间后,改进效果并不明显。
结合XLA和混合批量标准化(fused Batch Normalization)(在tf.layers.batch_normalization中融合了参数)可以通过将几个单独的操作组合到单个内核中来加速批量标准化操作。
无论如何,批量标准化可以成为加速深度神经网络训练的非常有价值的工具。 像训练深度神经网络一样,确定一种方法是否有助于解决问题的最佳方法就是做一下实验!
附Keras官方资源
官网:keras.io
中文版文档:keras.io/zh/
快速入门:keras.io/zh/#30-kera…
Github:github.com/keras-team/…
Google+网上论坛:groups.google.com/forum/#!for…
slack:kerasteam.slack.com/
参考文献:
https://towardsdatascience.com/how-to-use-batch-normalization-with-tensorflow-and-tf-keras-to-train-deep-neural-networks-faster-60ba4d054b73
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



