【论文推荐】最新八篇生成对抗网络相关论文—BRE、图像合成、多模态图像生成、非配对多域图、注意力、对抗特征增强、深度对抗性训练
【导读】专知内容组整理了最近八篇生成对抗网络(Generative Adversarial Networks )相关文章,为大家进行介绍,欢迎查看!
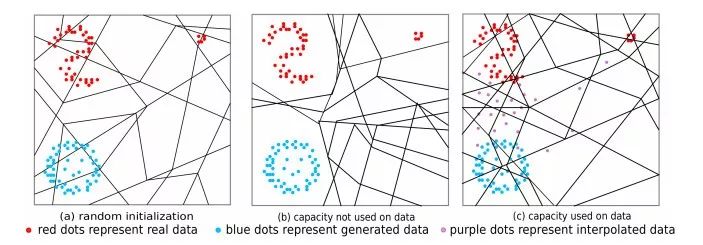
1.Improving GAN Training via Binarized Representation Entropy (BRE) Regularization(通过二值化表示熵(BRE)正则改进GAN训练)
作者:Yanshuai Cao,Gavin Weiguang Ding,Kry Yik-Chau Lui,Ruitong Huang
Published as a conference paper at the 6th International Conference on Learning Representations (ICLR 2018)
摘要:We propose a novel regularizer to improve the training of Generative Adversarial Networks (GANs). The motivation is that when the discriminator D spreads out its model capacity in the right way, the learning signals given to the generator G are more informative and diverse. These in turn help G to explore better and discover the real data manifold while avoiding large unstable jumps due to the erroneous extrapolation made by D. Our regularizer guides the rectifier discriminator D to better allocate its model capacity, by encouraging the binary activation patterns on selected internal layers of D to have a high joint entropy. Experimental results on both synthetic data and real datasets demonstrate improvements in stability and convergence speed of the GAN training, as well as higher sample quality. The approach also leads to higher classification accuracies in semi-supervised learning.
期刊:arXiv, 2018年5月9日
网址:
http://www.zhuanzhi.ai/document/1daa64655b1a4199334be9631bb7dc98
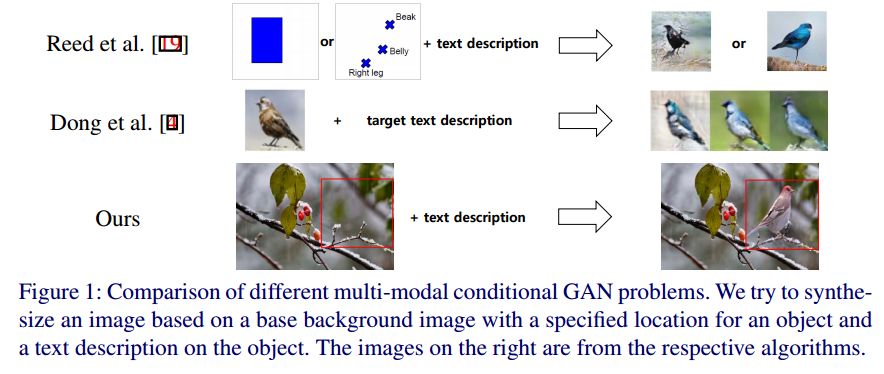
2.MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis(MC-GAN:多条件生成对抗网络的图像合成)
作者:Hyojin Park,YoungJoon Yoo,Nojun Kwak
机构:Seoul National University
摘要:In this paper, we introduce a new method for generating an object image from text attributes on a desired location, when the base image is given. One step further to the existing studies on text-to-image generation mainly focusing on the object's appearance, the proposed method aims to generate an object image preserving the given background information, which is the first attempt in this field. To tackle the problem, we propose a multi-conditional GAN (MC-GAN) which controls both the object and background information jointly. As a core component of MC-GAN, we propose a synthesis block which disentangles the object and background information in the training stage. This block enables MC-GAN to generate a realistic object image with the desired background by controlling the amount of the background information from the given base image using the foreground information from the text attributes. From the experiments with Caltech-200 bird and Oxford-102 flower datasets, we show that our model is able to generate photo-realistic images with a resolution of 128 x 128. The source code of MC-GAN is available soon.
期刊:arXiv, 2018年5月8日
网址:
http://www.zhuanzhi.ai/document/5c97977b9f8ad4b237d8b6f9ba75497f
3.MEGAN: Mixture of Experts of Generative Adversarial Networks for Multimodal Image Generation(MEGAN: 多模态图像生成对抗网络专家的混合)
作者:David Keetae Park,Seungjoo Yoo,Hyojin Bahng,Jaegul Choo,Noseong Park
27th International Joint Conference on Artificial Intelligence (IJCAI 2018)
机构:Korea University,University of North Carolina at Charlotte
摘要:Recently, generative adversarial networks (GANs) have shown promising performance in generating realistic images. However, they often struggle in learning complex underlying modalities in a given dataset, resulting in poor-quality generated images. To mitigate this problem, we present a novel approach called mixture of experts GAN (MEGAN), an ensemble approach of multiple generator networks. Each generator network in MEGAN specializes in generating images with a particular subset of modalities, e.g., an image class. Instead of incorporating a separate step of handcrafted clustering of multiple modalities, our proposed model is trained through an end-to-end learning of multiple generators via gating networks, which is responsible for choosing the appropriate generator network for a given condition. We adopt the categorical reparameterization trick for a categorical decision to be made in selecting a generator while maintaining the flow of the gradients. We demonstrate that individual generators learn different and salient subparts of the data and achieve a multiscale structural similarity (MS-SSIM) score of 0.2470 for CelebA and a competitive unsupervised inception score of 8.33 in CIFAR-10.

期刊:arXiv, 2018年5月8日
网址:
http://www.zhuanzhi.ai/document/4e0326f4e3c2d60536da6874c9c8fc63
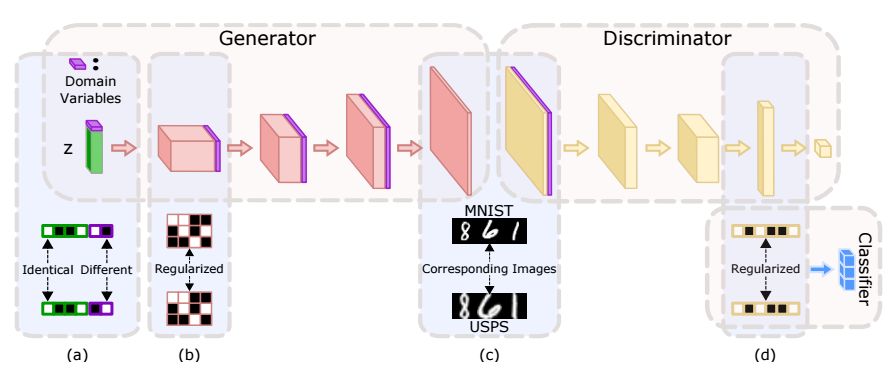
4.Unpaired Multi-Domain Image Generation via Regularized Conditional GANs(利用正则化的条件GANs生成非配对的多域图)
作者:Xudong Mao,Qing Li
机构:City University of Hong Kong
摘要:In this paper, we study the problem of multi-domain image generation, the goal of which is to generate pairs of corresponding images from different domains. With the recent development in generative models, image generation has achieved great progress and has been applied to various computer vision tasks. However, multi-domain image generation may not achieve the desired performance due to the difficulty of learning the correspondence of different domain images, especially when the information of paired samples is not given. To tackle this problem, we propose Regularized Conditional GAN (RegCGAN) which is capable of learning to generate corresponding images in the absence of paired training data. RegCGAN is based on the conditional GAN, and we introduce two regularizers to guide the model to learn the corresponding semantics of different domains. We evaluate the proposed model on several tasks for which paired training data is not given, including the generation of edges and photos, the generation of faces with different attributes, etc. The experimental results show that our model can successfully generate corresponding images for all these tasks, while outperforms the baseline methods. We also introduce an approach of applying RegCGAN to unsupervised domain adaptation.
期刊:arXiv, 2018年5月7日
网址:
http://www.zhuanzhi.ai/document/2782f0094d1961fad34e81a96a114c56
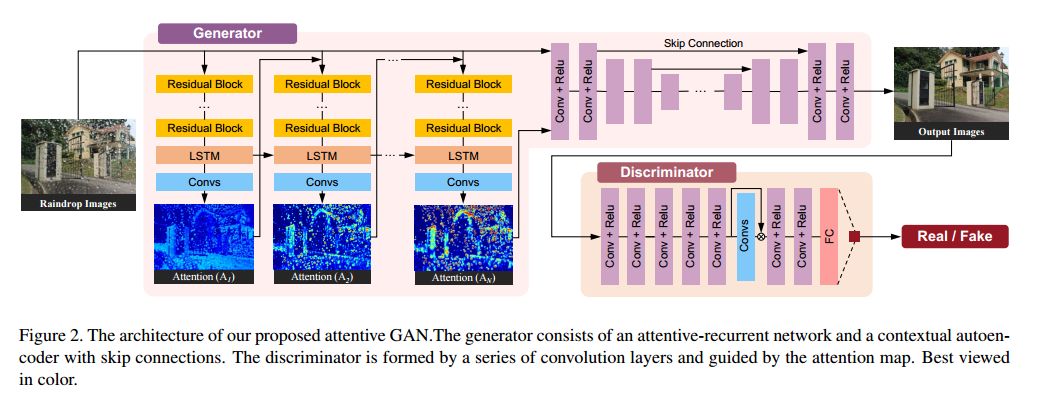
5.Attentive Generative Adversarial Network for Raindrop Removal from a Single Image(从单个图像去除雨滴的注意力的生成对抗网络)
作者:Rui Qian,Robby T. Tan,Wenhan Yang,Jiajun Su,Jiaying Liu
CVPR2018 Spotlight
机构:Peking University,National University of Singapore
摘要:Raindrops adhered to a glass window or camera lens can severely hamper the visibility of a background scene and degrade an image considerably. In this paper, we address the problem by visually removing raindrops, and thus transforming a raindrop degraded image into a clean one. The problem is intractable, since first the regions occluded by raindrops are not given. Second, the information about the background scene of the occluded regions is completely lost for most part. To resolve the problem, we apply an attentive generative network using adversarial training. Our main idea is to inject visual attention into both the generative and discriminative networks. During the training, our visual attention learns about raindrop regions and their surroundings. Hence, by injecting this information, the generative network will pay more attention to the raindrop regions and the surrounding structures, and the discriminative network will be able to assess the local consistency of the restored regions. This injection of visual attention to both generative and discriminative networks is the main contribution of this paper. Our experiments show the effectiveness of our approach, which outperforms the state of the art methods quantitatively and qualitatively.
期刊:arXiv, 2018年5月6日
网址:
http://www.zhuanzhi.ai/document/911b81fc00817b37b029c73318675209
6.Adversarial Feature Augmentation for Unsupervised Domain Adaptation(非监督域适应的对抗特征增强)
作者:Riccardo Volpi,Pietro Morerio,Silvio Savarese,Vittorio Murino
Accepted to CVPR 2018
机构:Universita di Verona,Stanford University
摘要:Recent works showed that Generative Adversarial Networks (GANs) can be successfully applied in unsupervised domain adaptation, where, given a labeled source dataset and an unlabeled target dataset, the goal is to train powerful classifiers for the target samples. In particular, it was shown that a GAN objective function can be used to learn target features indistinguishable from the source ones. In this work, we extend this framework by (i) forcing the learned feature extractor to be domain-invariant, and (ii) training it through data augmentation in the feature space, namely performing feature augmentation. While data augmentation in the image space is a well established technique in deep learning, feature augmentation has not yet received the same level of attention. We accomplish it by means of a feature generator trained by playing the GAN minimax game against source features. Results show that both enforcing domain-invariance and performing feature augmentation lead to superior or comparable performance to state-of-the-art results in several unsupervised domain adaptation benchmarks.
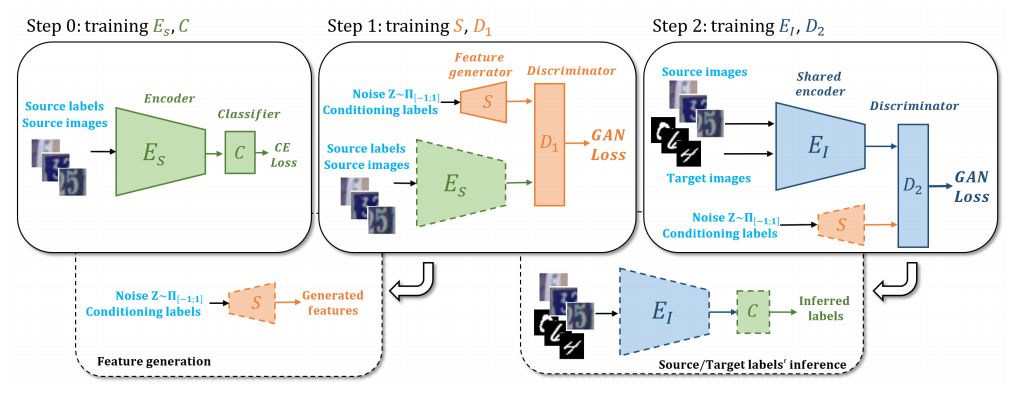
期刊:arXiv, 2018年5月4日
网址:
http://www.zhuanzhi.ai/document/74ec78227fe38592dd361ff04f049d4e
7.Boosting Noise Robustness of Acoustic Model via Deep Adversarial Training(通过深度对抗性训练提高声学模型的噪声鲁棒性)
作者:Bin Liu,Shuai Nie,Yaping Zhang,Dengfeng Ke,Shan Liang,Wenju Liu1
机构:University of Chinese Academy of Sciences,Beijing Forestry University
摘要:In realistic environments, speech is usually interfered by various noise and reverberation, which dramatically degrades the performance of automatic speech recognition (ASR) systems. To alleviate this issue, the commonest way is to use a well-designed speech enhancement approach as the front-end of ASR. However, more complex pipelines, more computations and even higher hardware costs (microphone array) are additionally consumed for this kind of methods. In addition, speech enhancement would result in speech distortions and mismatches to training. In this paper, we propose an adversarial training method to directly boost noise robustness of acoustic model. Specifically, a jointly compositional scheme of generative adversarial net (GAN) and neural network-based acoustic model (AM) is used in the training phase. GAN is used to generate clean feature representations from noisy features by the guidance of a discriminator that tries to distinguish between the true clean signals and generated signals. The joint optimization of generator, discriminator and AM concentrates the strengths of both GAN and AM for speech recognition. Systematic experiments on CHiME-4 show that the proposed method significantly improves the noise robustness of AM and achieves the average relative error rate reduction of 23.38% and 11.54% on the development and test set, respectively.
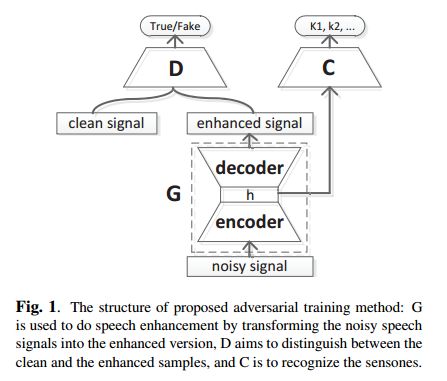
期刊:arXiv, 2018年5月2日
网址:
http://www.zhuanzhi.ai/document/9dd23e2b343ed994cf5e6143700df612
8.Controllable Generative Adversarial Network(可控的生成对抗网络)
作者:Minhyeok Lee,Junhee Seok
机构:Korea University
摘要:Recently introduced generative adversarial network (GAN) has been shown numerous promising results to generate realistic samples. The essential task of GAN is to control the features of samples generated from a random distribution. While the current GAN structures, such as conditional GAN, successfully generate samples with desired major features, they often fail to produce detailed features that bring specific differences among samples. To overcome this limitation, here we propose a controllable GAN (ControlGAN) structure. By separating a feature classifier from a discriminator, the generator of ControlGAN is designed to learn generating synthetic samples with the specific detailed features. Evaluated with multiple image datasets, ControlGAN shows a power to generate improved samples with well-controlled features. Furthermore, we demonstrate that ControlGAN can generate intermediate features and opposite features for interpolated and extrapolated input labels that are not used in the training process. It implies that ControlGAN can significantly contribute to the variety of generated samples.

期刊:arXiv, 2018年5月2日
网址:
http://www.zhuanzhi.ai/document/a8cf307e26ee5cbbc1af9a940b7bcc7f
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



