【NeurIPS 2018】 Facebook成果汇总
【导读】机器学习和计算神经科学专家从12月2日到12月8日都将聚集在蒙特利尔,参加第三十二届NeurIPS (Conference on Neural Information Processing Systems)年度会议。Faceboook的研究将在口头报告和海报展示环节上进行介绍。Facebook的研究人员和工程师也将在本周内组织和参加研讨会。
作者 | Facebook Research
编译 | Xiaowen

将在NeurIPS 2018上发表的Facebook研究
A^2-Nets: Double Attention Networks
Yunpeng Chen, Yannis Kalantidis, Jianshu Li, Shuicheng Yan and Jiashi Feng
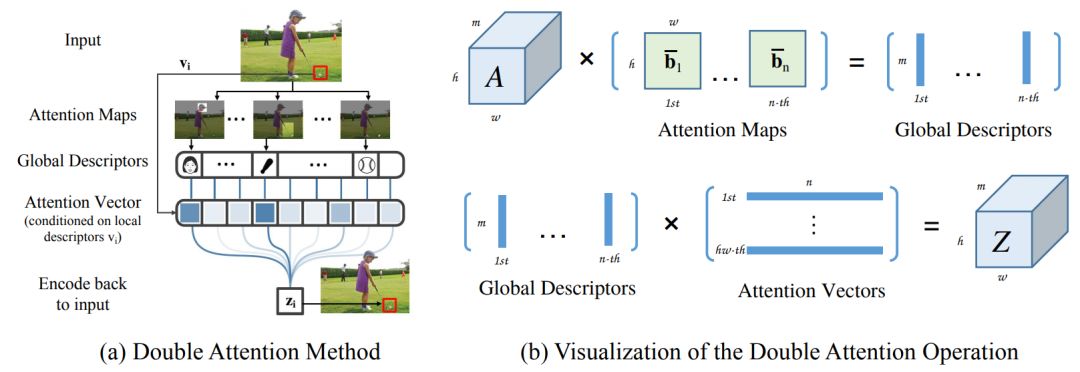
学习捕捉远程关系是图像/视频识别的基础。现有的CNN模型通常依赖于不断增长的深度来模拟这种关系,这是非常低效的。在本文中,我们提出了“双注意力块(Double attention block)”,这是一种新的组件,它从输入图像/视频的整个时空空间聚集和传播信息全局特征,从而使后续卷积层能够有效地从整个空间访问特征。该组件采用两个步骤的双重注意机制设计,其中第一步通过二阶注意力池化(second-order attention pooling)将整个空间的特征集合成一个紧凑的集合,第二步通过另一个注意力模块自适应地选择和分配特征到每个位置。该双注意力块易于采用,可以方便地插入到现有的深层神经网络中。我们对图像和视频识别任务进行了广泛的模型简化测试(ablation study)研究和实验,以评估其性能。在图像识别任务中,一个ResNet-50配备了我们的双注意力块,它的性能要比ImageNet-1k数据集上一个大得多的ResNet-152体系结构好得多,参数减少了40%以上,FLOPs也减少了。在动作识别任务上,我们提出的模型在Kinetics和UCF-101数据集上取得了state-of-the-art 的结果,效率明显高于最近的工作。
论文地址:https://arxiv.org/abs/1810.11579
A Block Coordinate Ascent Algorithm for Mean-Variance Optimization
Bo Liu, Tengyang Xie, Yangyang Xu, Mohammad Ghavamzadeh, Yinlam
Chow, Daoming Lyu and Daesub Yoon
动态决策问题中的风险管理是金融投资、自动驾驶和医疗保健等诸多领域的首要关注问题。均值-方差函数是风险管理中应用最广泛的目标函数之一,它简单易懂,易于解释。现有的均值-方差优化算法都是基于多时间尺度随机逼近的(multi-time-scale stochastic approximation),其学习速率往往难以调整,且只有渐近收敛性证明。本文提出了一种基于有限样本误差界分析(局部最优)的均值-方差优化的无模型策略搜索框架。本文首先对原有的均值-方差函数及其Legendre-fenel对偶进行了重新构造,并在此基础上提出了一种随机块坐标上升策略搜索算法。给出了最后一次迭代解的渐近收敛性保证和随机选取解的收敛速度,并在几个benchmark domains 上证明了它们的适用性。
论文地址:https://arxiv.org/abs/1809.02292
A Lyapunov-based Approach to Safe Reinforcement Learning
Yinlam Chow, Ofir Nachum, Edgar Duenez-Guzman and Mohammad Ghavamzadeh
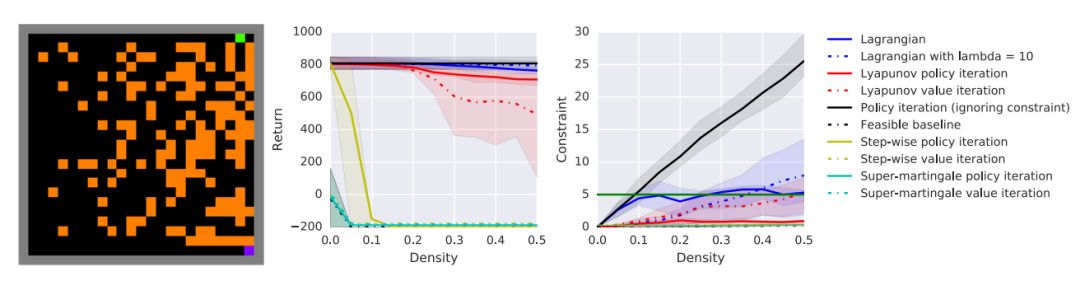
在许多实际的强化学习(RL)问题中,除了优化主目标函数外,Agent还必须同时避免违反多个约束。特别是,除了优化性能外,在训练和部署过程中还必须保证Agent的安全(例如,机器人应避免采取不可挽回的损害其硬件的探索性或非探索性行动)。为了在RL中引入安全性,我们在约束马尔可夫决策过程(CMDPs)框架下导出了算法,这是对标准马尔可夫决策过程(MDPs)的扩展,并对期望累积成本进行了约束。我们的方法依赖于一种新的Lyapunov方法。定义并提出了一种构造Lyapunov函数的方法,该方法通过一组局部线性约束来保证训练过程中行为策略的全局安全性。利用这些理论基础,我们展示了如何利用Lyapunov方法系统地将动态规划(DP)和RL算法转化为它们的安全算法。 为了证明这些算法的有效性,我们在一个安全基准域中对几个CMDP规划和决策任务进行了评估。结果表明,该方法在平衡约束满意度和性能方面明显优于现有baselines。
论文地址:https://arxiv.org/abs/1805.07708
The Description Length of Deep Learning Models
Léonard Blier and Yann Ollivier
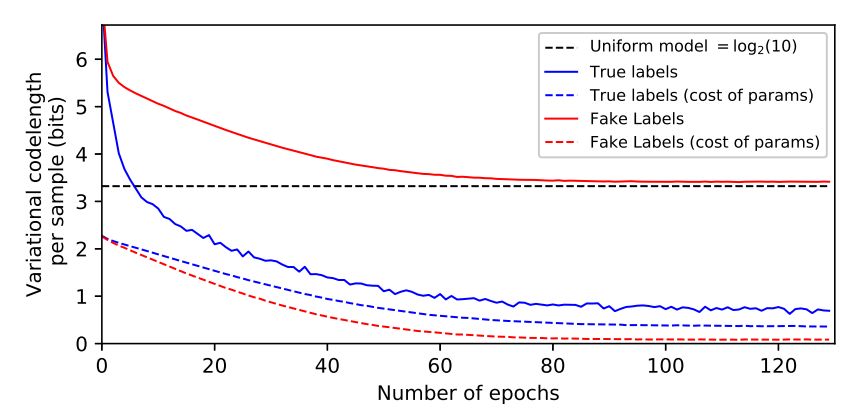
Solomonoff的一般推理理论(Solomonoff,1964)和最小描述长度原则(Grünwald,2007;Rissanen,2007)使Occam剃刀正规化,并认为一个好的数据模型是一个善于无损压缩数据的模型,包括描述模型本身的成本。考虑到需要编码的大量参数,深层神经网络似乎违背了这一原则。实验证明了在考虑参数编码的情况下,深层神经网络对训练数据进行压缩的能力。压缩观点最初促使在神经网络中使用变分方法(Hinton and van cAMP,1993; Schmidhuber,1997)。出乎意料的是,我们发现这些变分方法提供了令人惊讶的糟糕的压缩界,尽管这些方法是显式构建的,这可能解释了变分法在深度学习中的实际应用效果相对较差的原因。另一方面,简单的增量编码方法在深度网络上产生了优良的压缩值,证明了Solomonoff方法的正确性。
论文地址:https://arxiv.org/abs/1802.07044
Fast Approximate Natural Gradient Descent in a Kronecker Factored Eigenbasis
Thomas George, César Laurent, Xavier Bouthillier, Nicolas Ballas and Pascal Vincent

利用梯度协方差信息的优化算法,如自然梯度下降变量(Amari,1998),提供了产生更有效下降方向的前景。对于具有多个参数的模型,它们所基于的协方差矩阵变得巨大,使它们不再适用于原来的形式。这激发了对简单对角线近似和更复杂的因子逼近的研究,例如KFAC (diskes,2000;marten)。在本工作中,我们从两种方法中得到启发,提出了一种比KFAC更好的新的近似方法,并且可以修正为廉价的部分更新。它包括跟踪对角线方差,不是在参数坐标中,而是在Kronecker因子特征基中,其中对角线近似可能更有效。实验表明,与KFAC相比,几种深层网络结构的优化速度都有所提高。
论文地址:https://arxiv.org/abs/1806.03884
Fighting Boredom in Recommender Systems with Linear Reinforcement Learning
Romain Warlop, Alessandro Lazaric and Jérémie Mary
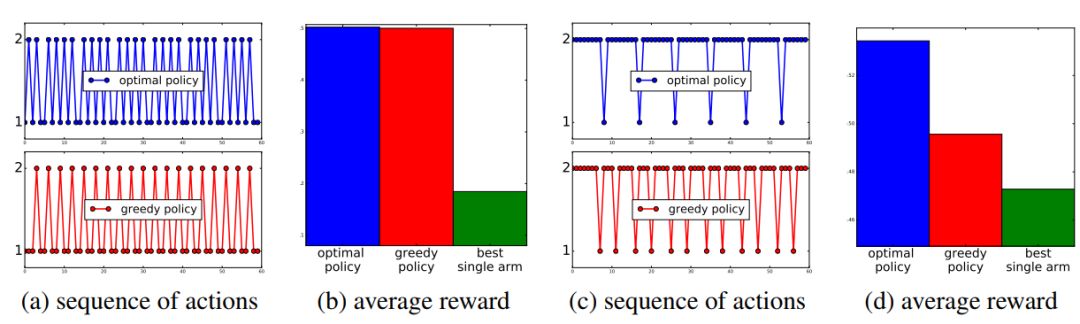
推荐系统(Rs)的一个常见假设是存在一个最佳的固定推荐策略。这种策略可以是简单的,并且可以在 item 级别上工作,或者实现更复杂的RS (例如,a/b测试的目标是找到最佳的固定 RS 并随后执行)。我们认为,这种假设在实践中很少得到验证,因为推荐过程本身可能会影响用户的兴趣偏好。例如,用户可能会对当前策略感到厌烦,而如果上次使用该策略距离现在已经有足够长的时间,则这种策略可能会再次引起用户的兴趣。在这种情况下,更好的方法是在正确的频率上交替不同的解决方案,以充分利用它们的潜力。在本文中,我们首先将问题描述为马尔可夫决策过程,其中 rewards 是近期行动历史上的线性函数,并且我们证明了考虑建议的长期影响的策略可能优于固定行为和上下文贪婪策略。在此基础上,我们引入了对 UCRL 算法(LINUCRL)的扩展,有效地平衡了未知环境下的勘探和开发,并得到了一个与状态数无关的regret bound。最后,我们在实际场景中对模型假设和算法进行了实证验证。
论文地址:
https://papers.nips.cc/paper/7447-fighting-boredom-in-recommender-systems-with-linear-reinforcement-learning.pdf
Forward Modeling for Partial Observation Strategy Games – A StarCraft Defogger
Gabriel Synnaeve, Zeming Lin, Jonas Gehring, Dan Gant, Vegard Mella, Vasil Khalidov, Nicolas Carion and Nicolas Usunier
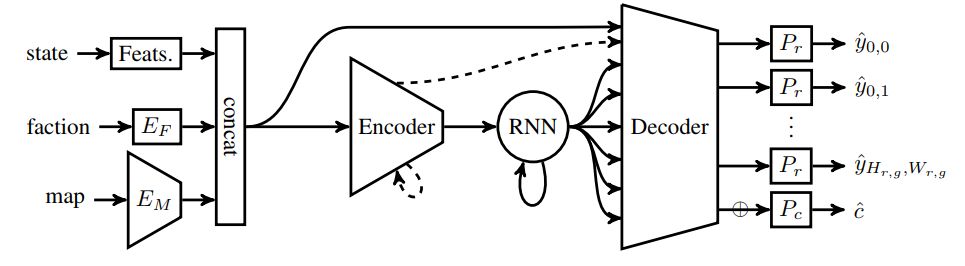
在实时策略博弈的背景下,我们将脱轨问题描述为状态估计和基于先前、部分观测的未来状态预测问题。我们提出采用编解码神经网络来完成这项任务,并引入 proxy tasks和 baselines 进行评估,以评估它们捕获基本游戏规则和高级动态的能力。通过将卷积神经网络和递归网络相结合,我们利用空间和顺序相关性,并在星际争霸的大型人类游戏数据集:Brood War 上训练性能良好的模型。最后,我们展示了我们的模型与下游任务的相关性,将它们应用于一个先进的、基于规则的星际争霸机器人中的敌人单位预测。我们观察到,与几个强大的社区机器人相比,获胜率有所提高。
论文地址:
https://papers.nips.cc/paper/8272-forward-modeling-for-partial-observation-strategy-games-a-starcraft-defogger.pdf
GLoMo: Unsupervisedly Learned Relational tGraphs as Transferable Representations
Zhilin Yang, Jake Zhao, Bhuwan Dhingra, Kaiming He, William Cohen, Ruslan Salakhutdinov andYann LeCun
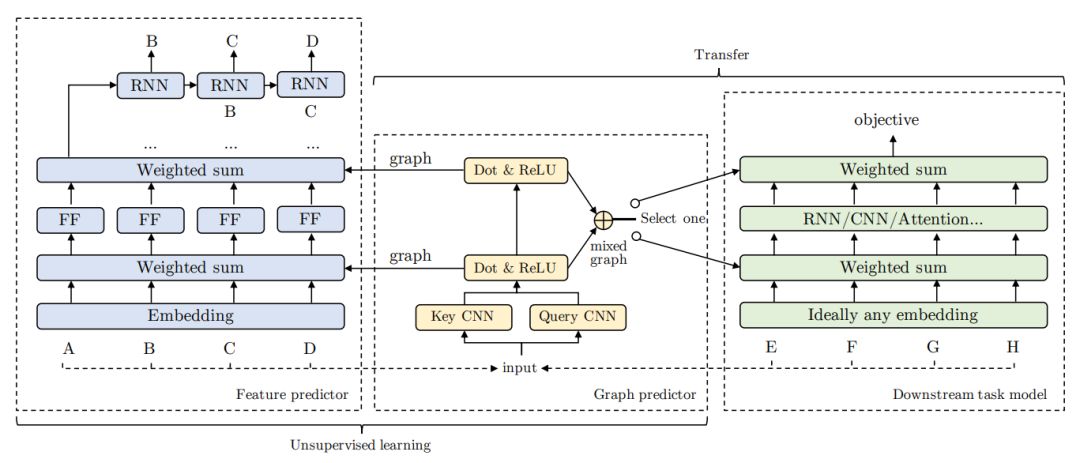
现代深度迁移学习方法主要集中在从一个可转移到其他任务的任务中学习通用特征向量,如语言中的词嵌入和视觉中经过预处理的卷积特征。然而,这些方法通常传递一元特性,而忽略了更结构化的图形表示。这项工作探索了学习通用潜在关系图的可能性,这种关系图可以从大规模的未标记数据中捕获数据单元 (例如单词或像素) 之间的依赖关系,并将这些图传递给下游任务。我们提出的迁移学习框架提高了各种任务的性能,包括问答、自然语言推理、情感分析和图像分类。我们还证明了所学习的图是足够通用的,可以转移到没有经过训练的不同的嵌入(包括GloVe嵌入、ELMo嵌入和任务特定的RNN隐藏单元),或者没有嵌入的单元 (如图像像素)。
论文地址:https://arxiv.org/abs/1806.05662
Near Optimal Exploration-Exploitation in Non-Communicating Markov Decision Processes
Ronan Fruit, Matteo Pirotta and Alessandro Lazaric

在设计MDP的状态空间时,通常包括任何策略都无法到达的瞬态状态 (例如,在山区汽车中,速度和位置的乘积空间包含物理上无法到达的配置)。这导致弱沟通或多链MDPS。本文介绍了TUCRL算法,它可以在任何有限马尔可夫决策过程 (MDP) 中不需要任何形式的先验知识进行有效的勘探开发。特别地,对于任何具有扫描状态、动作和γc≤sc可能通信的下一状态的MDP,我们得到一个(dc√γcscat) regret bound,其中dc是 MDP 通信部分的直径(即任意两个状态之间最长最短路径的长度)。这与现有的优化算法(例如,UCRL、Optimistic PSRL)形成了对比,这些算法在弱通信MDPS中遭受 linear regret,以及后验抽样或正则化算法(例如:REGAL),这些算法要求事先了解最优策略的偏差范围,以实现次线性regret。我们还证明了在弱通信的MDPS中,任何算法都不可能在不经历MDP参数指数级的多步线性regret的情况下实现regret的对数增长。最后,我们展示了支持我们的理论发现的数值模拟,并展示了TUCRL 如何克服了state-of-the-art 的限制。
论文地址:https://arxiv.org/abs/1807.02373
Non-Adversarial Mapping with VAEs
Yedid Hoshen

近年来,无监督的跨域映射(cross-domain mapping)研究引起了人们的广泛关注。最近取得的许多进展是由于使用了对抗性训练以及周期限制。对抗性训练的实际困难促使人们对非对抗性训练方法进行研究。在最近的一篇论文中,我们证明了在不使用cycles或GANS的情况下,跨域映射是可能的。虽然这种方法很有前途,但也存在一些缺点,包括代价高昂的推理,以及每个训练示例都有一个优化变量,防止了该方法使用大量的训练集。我们提出了一种替代的方法,它能够实现非对抗性映射,使用一种新的变分自编码器形式。我们的方法在推理时速度更快,能够充分利用大型数据集,并具有简单的解释。
论文地址:http://www.cs.huji.ac.il/~ydidh/namvae.pdf
One-Shot Unsupervised Cross Domain Translation
Sagie Benaim and Lior Wolf
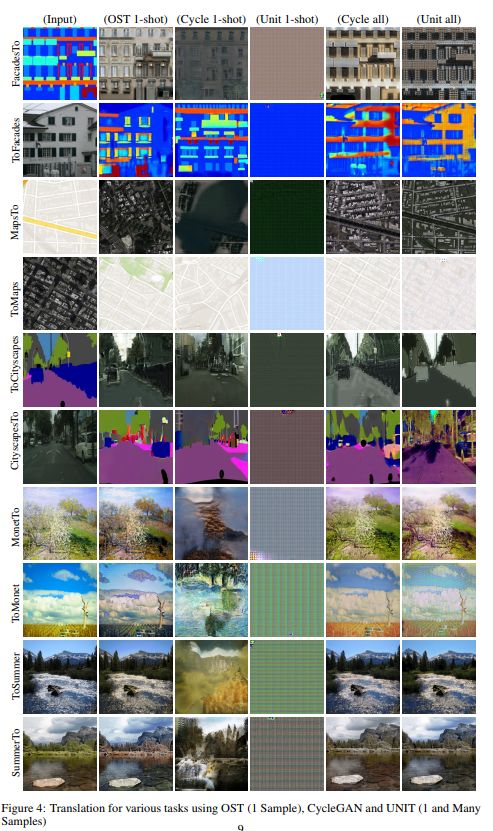
给定域A中的单个图像x和域B中的一组图像,我们的任务是生成x在B中的类似物。我们认为,这个任务突出了认知主体在世界上的行为能力,并提供了现有的无监督域翻译方法在这个任务上失败的经验证据。我们的方法遵循两个步骤。首先,对域B的变分自编码器进行了训练。然后,给出新的样本x,我们通过调整与图像接近的层来直接拟合x,而只间接地适应其他层,从而为域A创建一个变分自编码器。我们的实验表明,当在一个样本x上训练时,与现有的域转移方法一样,当这些方法享受到来自A域的大量训练样本时,新方法也同样有效。
论文地址:https://arxiv.org/abs/1806.06029
代码地址:
https://github.com/sagiebenaim/OneShotTranslation
SING: Symbol-to-Instrument Neural Generator
Alexandre Defossez, Neil Zeghidour, Nicolas Usunier, Leon Bottou and Francis Bach
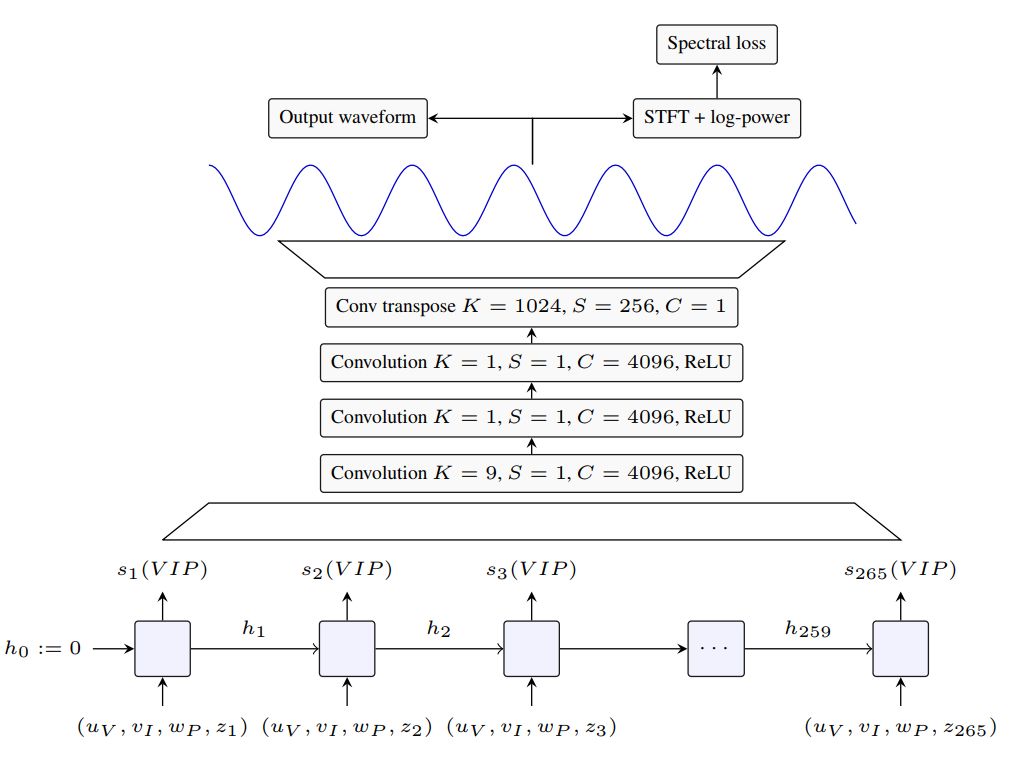
最近在音频合成的深入学习方面的进展为直接产生波形的模型开辟了道路,从传统的依赖于语音或音乐产生的语音或MIDI合成器的范式转变。尽管它们取得了成功,但目前最先进的神经音频合成器,如WaveNet和SampleRNN,受到了禁止性训练和推理时间的困扰,因为它们基于自回归模型,每次生成一个音频样本,速度为16 khz。在本文中,我们研究了一种计算效率更高的大跨步逐帧波形生成方案。我们介绍了SING,一种轻量级的神经音频合成器,用于产生给定的乐器、音高和速度的音符。我们的模型被训练成用一个解码器从近1000个仪器产生音符,这要归功于一个新的损失函数,它使生成的波形与目标波形的log spectrograms之间的距离最小化。在综合训练中未见的音高和乐器音符的综合任务上,SING产生的音频与最先进的基于WaveNet 的自编码器相比,音质有了显著的改善,而平均意见评分(MOS)则是前者的32倍,后者的推理速度要快2500倍。
论文地址:https://arxiv.org/abs/1810.09785
代码地址:https://github.com/facebookresearch/SING
Temporal Regularization for Markov Decision Process
Pierre Thodoroff, Audrey Durand, Joelle Pineau and Doina Precup
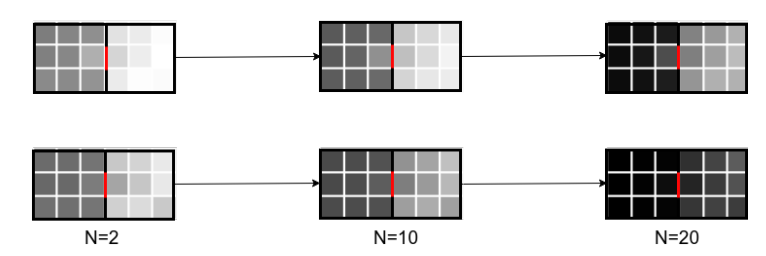
强化学习的几种应用都会因高方差而产生不稳定性,这在高维领域尤其普遍。正则化是机器学习中常用的一种降低方差的方法,其代价是引入了一些偏差。现有的正则化技术主要集中在空间正则化方面。然而,在强化学习中,由于Bellman方程的性质,也有机会利用基于轨迹的数值估计的平滑性来进行时间正则化。本文探讨了一类时态正则化方法。我们用马尔可夫链的概念形式化地刻画了这种技术引起的偏差。我们通过一系列简单的离散和连续的MDPs来说明时态正则化的各种特性,并表明即使在高维Atari游戏中,该技术也提供了改进。
论文地址:https://arxiv.org/abs/1811.00429
原文链接:
https://research.fb.com/facebook-at-neurips-2018/
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



