【干货】TensorFlow协同过滤推荐实战
【导读】本文利用TensorFlow构建了一个用于产品推荐的WALS协同过滤模型。作者从抓取数据开始对模型进行了详细的解读,并且分析了几种推荐中可能隐藏的情况及解决方案。
作者 | Lak Lakshmanan
编译 | 专知
参与 | Xiaowen

向用户推荐巧克力是一个协同过滤问题
如何利用TensorFlow建立个性化推荐协同过滤模型
在本文中,我将通过如何使用TensorFlow’s Estimator API 来构建用于产品推荐的WALS协同过滤模型。最近,我的同事Lukman Ramse发表了一系列解决方案,详细介绍了如何构建推荐模型——阅读这些解决方案【1】,了解推荐的内容以及如何建立端到端系统。
在本文中,我将用Apache Beam取代最初解决方案中的Pandas--这将使解决方案更容易扩展到更大的数据集。由于解决方案中存在上下文,我将在这里讨论技术细节。完整的源代码在GitHub上。
https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/courses/machine_learning/deepdive/10_recommend/wals_tft.ipynb
对于协同过滤,我们不需要知道任何关于用户或内容的属性。本质上,我们需要知道的是特定用户给出的特定项的userID、itemID和打分(ratings)。在这种情况下,我们可以使用在页面上花费的时间作为打分的代表。Google Analytics 360将网络流量信息导出到BigQuery,我是从BigQuery提取数据的:
# standardSQL
WITH
visitor_page_content
AS(
SELECT
fullVisitorID,
(SELECT MAX(IF(index=10, value, NULL)) FROM
UNNEST(hits.customDimensions)) AS
latestContentId,
(LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId ORDER BY hits.time ASC) - hits.time) AS
session_duration
FROM
`cloud - training - demos.GA360_test.ga_sessions_sample`,
UNNEST(hits)
AS
hits
WHERE
# only include hits on pages
hits.type = "PAGE"
GROUP
BY
fullVisitorId, latestContentId, hits.time
)
# aggregate web stats
SELECT
fullVisitorID as visitorId,
latestContentId as contentId,
SUM(session_duration)
AS
session_duration
FROM
visitor_page_content
WHERE
latestContentId
IS
NOT
NULL
GROUP
BY
fullVisitorID, latestContentId
HAVING
session_duration > 0
ORDER
BY
latestContentId
这个查询本身是特定于报纸建立google分析的方式,特别是他们设置自定义维度的方式。你可能需要使用不同的查询将数据提取到类似于此表的内容中:
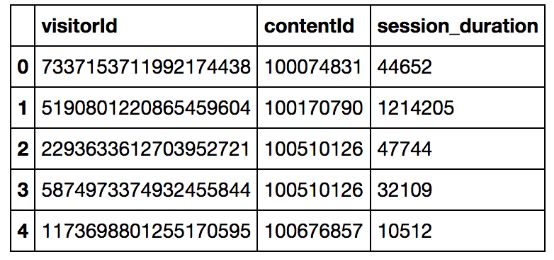
这是进行协同过滤所需的原始数据集。很明显,你将使用什么样的visitorID、contentID和ratings将取决于你的问题。除此之外,其他一切都是相当标准的,你应该能按原样使用。
WALS算法要求枚举用户ID和项ID,即它们应该是交互矩阵中的行号和列号。因此,我们需要接收上面的visitorId,这是一个字符串,并将它们映射到0,1,2,…。对于项目ID,我们需要做同样的事情。此外,rating必须是较小的数字,通常为0-1。因此,我们必须缩放会话持续时间(session_duration)。
做这种映射,我们将使用 TensorFlow Transform(TFT)(https://github.com/tensorflow/transform)-这是一个库,允许你创建预处理的数据集,使用ApacheBeam训练然后将预处理作为你tensorflow graph中的推理!
下面是我使用TFT的预处理功能的关键:
def preprocess_tft(rowdict):
median = 57937
result = {
'userId' : tft.string_to_int(rowdict['visitorId'], vocab_filename='vocab_users'),
'itemId' : tft.string_to_int(rowdict['contentId'], vocab_filename='vocab_items'),
'rating' : 0.3 * (1 + (rowdict['session_duration'] - median)/median)
}
# cap the rating at 1.0
result['rating'] = tf.where(tf.less(result['rating'], tf.ones(tf.shape(result['rating']))),
result['rating'], tf.ones(tf.shape(result['rating'])))
return result
预处理BigQuery中由visitorID、contentID和会话持续时间组成的行的结果是一个名为结果(result)的Python字典,它包含三个列:UserID、ItemID和Rating。
tft.string_to_int查看整个训练数据集,并创建一个映射来枚举访问者,并将映射(“the vocabulary”)写入文件vocab_users。我对contentID做同样的事情,创建ItemID。Rating是通过将会话持续时间缩放为0-1来获得的。我的缩放基本上是剪下极长的会话时间的长尾巴,这可能代表那些在浏览文章时关闭他们的笔记本电脑的人。需要注意的关键是,我只使用TensorFlow函数(如tf.less和tf.ones)进行这种剪裁。这一点很重要,因为这个预处理功能必须在推断(预测)过程中作为TensorFlow serving graph的一部分。
使用Apache Beam将预处理功能应用于训练数据集:
transformed_dataset, transform_fn = (
raw_dataset | beam_impl.AnalyzeAndTransformDataset(preprocess_tft))
WALS训练集由两个文件组成:一个文件提供由某一用户打分的所有项目(交互矩阵按行排列),另一个文件提供所有对某一项目进行评分的用户(交互矩阵按列排列)。显然,这两个文件包含相同的数据,但是有必要拆分数据集,以便能够并行处理它们。我们也可以在执行枚举的同一个Apache Beam pipeline中这样做:
users_for_item = (transformed_data
| 'map_items' >> beam.Map(lambda x : (x['itemId'], x))
| 'group_items' >> beam.GroupByKey()
| 'totfr_items' >> beam.Map(lambda item_userlist : to_tfrecord(item_userlist, 'userId')))
然后,我们可以在Cloud Dataflow上执行Apache Beam pipeline。这里我们不需要在设置基础设施和安装软件方面浪费时间(请参阅GitHub中的笔记本以获得完整代码)
https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/courses/machine_learning/deepdive/10_recommend/wals_tft.ipynb
至此,我们将有以下文件:
items_for_user-00000-of-00003
...
users_for_item-00000-of-00004
...
transform_fn/transform_fn/saved_model.pb
transform_fn/transform_fn/assets/
transform_fn/transform_fn/assets/vocab_items
transform_fn/transform_fn/assets/vocab_users
1. ```User_for_item```以TFExample格式列出每个项目的所有用户/评分。这里的项目和用户是整数(而不是字符串),即itemID不是contentID、userID不是visitorId。评分是按比例调整的。
2. ```items_for_user```以TFExample格式列出每个用户的所有项目/评分。这里的项目和用户是整数(而不是字符串),即itemID不是contentID、userID不是visitorId。评分是按比例调整的。
3. ```vocab_items```包含从contentID到枚举itemID的映射。
4. ```vocab_users```包含从visitorID到枚举UserID的隐射。
5. saved_model.pb包含我们在预处理期间所做的所有TensorFlow转换,因此它们也可以在预测期间应用。
在TensorFlow中有一个Estimator API-based的WALS实现,它的使用方式和其他estimator一样,参见GitHub repo中的read_dataset()和train_and_evaluate()函数。
更有趣的是我们如何使用经过训练的estimator进行批处理预测。对于特定的用户,我们希望找到top-k项,可以在TensorFlow中使用:
def find_top_k(user, item_factors, k):
all_items = tf.matmul(tf.expand_dims(user, 0), tf.transpose(item_factors))
topk = tf.nn.top_k(all_items, k=k)
return tf.cast(topk.indices, dtype=tf.int64)
批量预测涉及为每一个用户调用上面的函数,但确保当我们写出来的字符串visitorID不是数字userID(contentID /userID也一样):
def batch_predict(args):
import numpy as np
# read vocabulary into Python list for quick index-ed lookup
def create_lookup(filename):
from tensorflow.python.lib.io import file_io
dirname = os.path.join(args['input_path'], 'transform_fn/transform_fn/assets/')
with file_io.FileIO(os.path.join(dirname, filename), mode='r') as ifp:
return [x.rstrip() for x in ifp]
originalItemIds = create_lookup('vocab_items')
originalUserIds = create_lookup('vocab_users')
with tf.Session() as sess:
estimator = tf.contrib.factorization.WALSMatrixFactorization(
num_rows=args['nusers'], num_cols=args['nitems'],
embedding_dimension=args['n_embeds'],
model_dir=args['output_dir'])
# but for in-vocab data, the row factors are already in the checkpoint
user_factors = tf.convert_to_tensor(estimator.get_row_factors()[0]) # (nusers, nembeds)
# in either case, we have to assume catalog doesn't change, so col_factors are read in
item_factors = tf.convert_to_tensor(estimator.get_col_factors()[0]) # (nitems, nembeds)
# for each user, find the top K items
topk = tf.squeeze(tf.map_fn(lambda user: find_top_k(user, item_factors, args['topk']),
user_factors, dtype=tf.int64))
with file_io.FileIO(os.path.join(args['output_dir'], 'batch_pred.txt'), mode='w') as f:
for userId, best_items_for_user in enumerate(topk.eval()):
f.write(originalUserIds[userId] + '\t') # write userId \t item1,item2,item3...
f.write(','.join(originalItemIds[itemId] for itemId in best_items_for_user) + '\n')
为了进行训练和批处理预测,我们可以在Cloud ML引擎上运行TensorFlow模型,同样不需要使用任何基础设施:
gcloud ml-engine jobs submit training $JOBNAME \
--region=$REGION \
--module-name=trainer.task \
--package-path=${PWD}/wals_tft/trainer \
--job-dir=$OUTDIR \
--staging-bucket=gs://$BUCKET \
--scale-tier=BASIC_GPU \
--runtime-version=1.5 \
-- \
--output_dir=$OUTDIR \
--input_path=gs://${BUCKET}/wals/preproc_tft \
--num_epochs=10 --nitems=5668 --nusers=82802
像这样硬编码nitems和nusers是一种丑陋的做法。所以,我们可以回到我们的Beam pipeline,让它把nitems和nusers写到文件中,然后简单地做一个“gsutil cat”来得到适当的值-GitHub上的完整代码就是这样做的。
下面是一个输出的例子:

第五步:行和列的系数
虽然做产品推荐是WALS的关键应用,但另一个应用是寻找表示产品和用户的低维方法,例如,通过对项目因素和列因素进行聚类来进行产品或客户细分。因此,我们实现了一个服务函数来向调用方提供这些服务(同样,请参阅GitHub获取完整代码):
def for_user_embeddings(originalUserId):
# convert the userId that the end-user provided to integer
originalUserIds = tf.contrib.lookup.index_table_from_file(
os.path.join(args['input_path'], 'transform_fn/transform_fn/assets/vocab_users'))
userId = originalUserIds.lookup(originalUserId)
# all items for this user (for user_embeddings)
items = tf.range(args['nitems'], dtype=tf.int64)
users = userId * tf.ones([args['nitems']], dtype=tf.int64)
ratings = 0.1 * tf.ones_like(users, dtype=tf.float32)
return items, users, ratings, tf.constant(True)
请注意,本文只是关于替换机器学习训练和批处理预测部分的原始解决方案。原始解决方案还解释了如何进行编排和筛选。现在,我们有了一个BigQuery查询、一个BEAM/DataFlow pipeline和一个潜在的AppEngine应用程序(参见下面)。你如何周期性地一个接一个地运行它们?使用解决方案中建议的Apache Airflow来执行此流程。
如果你向顾客推荐巧克力,那么推荐他们已经尝试过的巧克力是可以的,但如果你向用户推荐报纸文章,那么重要的是不要推荐他们已经阅读过的文章。与原来的解决方案不同,我的批处理预测代码不会过滤掉用户已经阅读过的文章。如果建议中不包括已阅读/购买的项目很重要,那么有两种方法可以做到。
更简单的方法是,在找到top-k之前,将与已经读取的项对应的条目()
(entities)(此处,打分<0.01的项)清零:
def find_top_k(user, item_factors, read_items, k):
all_items = tf.matmul(tf.expand_dims(user, 0),
tf.transpose(item_factors))
all_items = tf.where(tf.less(read_items,
0.01*tf.ones(tf.shape(read_items))),
all_items,
tf.zeros(tf.shape(all_items)))
topk = tf.nn.top_k(all_items, k=k)
return tf.cast(topk.indices, dtype=tf.int64)
这里的问题是延迟——你可能不会推荐用户昨天阅读的项目(因为它在你的训练数据集中),但是批处理预测代码确实可以访问实时读取的文章流,所以你将推荐他们几分钟前阅读的文章。如果这种滞后是你想要避免的问题,那么你应该使批处理预测中的k值更高(例如,你将从推荐者那里得到20篇文章,即使你只推荐其中的5篇),然后按照最初解决方案的建议,在AppEngine中执行二级过滤。
最后,TensorFlow Transform允许我们简化元数据的计算和项目/用户的映射,以适应WALS范式。
【1】https://cloud.google.com/solutions/machine-learning/recommendation-system-tensorflow-overview
参考文献:
https://towardsdatascience.com/how-to-build-a-collaborative-filtering-model-for-personalized-recommendations-using-tensorflow-and-b9a77dc1320
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知
展开全文



