【NLP】Facebook推出最新跨语言预训练模型,刷新多项跨语言任务记录
【导读】近几个月,NLP领域,预训练语言模型相关方向的进展,可谓风风火火。从一开始ELMo的Bi-LSTM多层预训练结构,到后来的GPT,再到风头无两的BERT,你方唱罢我登场,这不,Facebook在前几天推出了XLM模型,旨在跨语言方面跟其他预训练模型进行P.K。实验结果显示XML在XNLI任务上比原来的state-of-the-art直接高了4.9个百分点;在无监督机器翻译WMT’16 German-English中,比原来的state-of-the-art高了9个BLEU;在有监督的机器翻译WMT’16 Romanian-English中,比原来的state-of-the-art高了4个BLEU;
【简介】
最近的研究已经表明使用预训练的语言模型,对提高英语自然语言理解的能力有很大帮助。在这项工作中,我们将这种方法扩展到多种语言,并展示了跨语言预训练模型的有效性。我们提出了两种学习跨语言模型的方法:一种是只依赖单语数据的无监督方法,另一种是利用具有新的跨语言模型目标的并行数据的监督方法。我们在跨语言分类、无监督和有监督机器翻译方面取得了最先进的成果。实验结果显示XML在XNLI任务上比原来的state-of-the-art直接高了4.9个百分点;在无监督机器翻译WMT’16 German-English中,比原来的state-of-the-art高了9个BLEU;在有监督的机器翻译WMT’16 Romanian-English中,比原来的state-of-the-art高了4个BLEU;我们的代码和经过训练的模型将公开提供。
【论文首页】

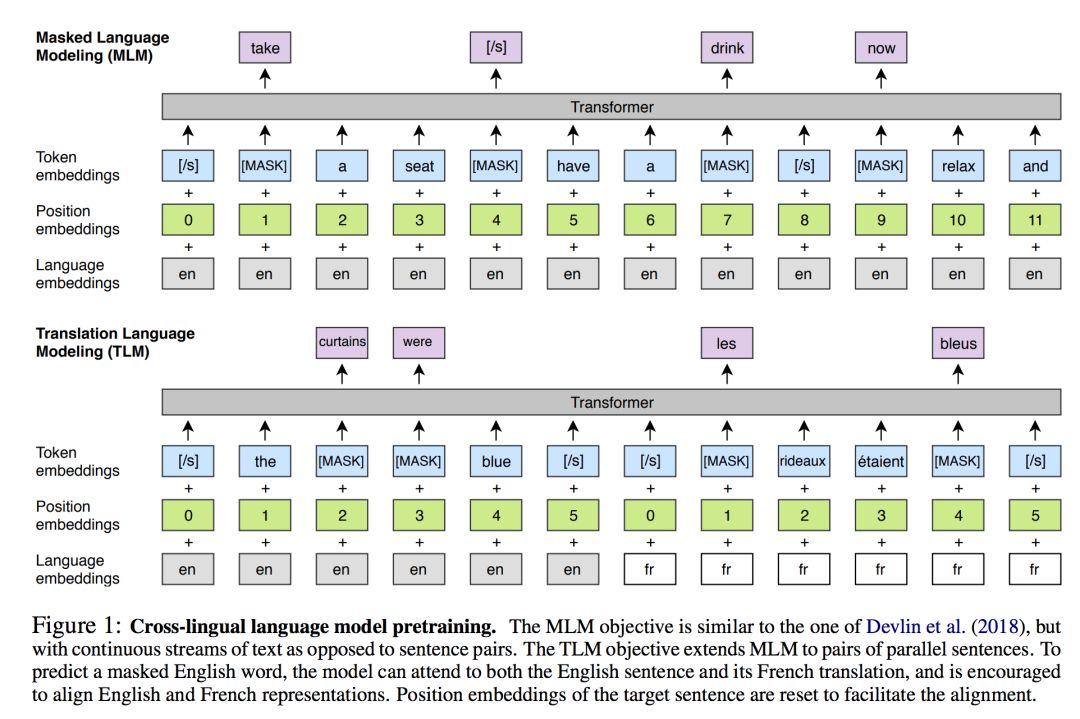
【模型架构】
请关注专知公众号(点击标题下方蓝色专知关注)
后台回复“XLM” 就可以获取该论文《Cross-lingual Language Model Pretraining》下载链接~
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!461位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



