【论文推荐】最新七篇目标检测相关论文—Self Paced、上下文注意力、特征反射、层次特征、Tiny SSD、少样本、协同学习
【导读】专知内容组整理了最近七篇目标检测(Object Detection)相关文章,为大家进行介绍,欢迎查看!
1. Self Paced Deep Learning for Weakly Supervised Object Detection(基于Self Paced深度学习的弱监督目标检测)
作者:Enver Sangineto,Moin Nabi,Dubravko Culibrk,Nicu Sebe
摘要:In a weakly-supervised scenario object detectors need to be trained using image-level annotation alone. Since bounding-box-level ground truth is not available, most of the solutions proposed so far are based on an iterative, Multiple Instance Learning framework in which the current classifier is used to select the highest-confidence boxes in each image, which are treated as pseudo-ground truth in the next training iteration. However, the errors of an immature classifier can make the process drift, usually introducing many of false positives in the training dataset. To alleviate this problem, we propose in this paper a training protocol based on the self-paced learning paradigm. The main idea is to iteratively select a subset of images and boxes that are the most reliable, and use them for training. While in the past few years similar strategies have been adopted for SVMs and other classifiers, we are the first showing that a self-paced approach can be used with deep-network-based classifiers in an end-to-end training pipeline. The method we propose is built on the fully-supervised Fast-RCNN architecture and can be applied to similar architectures which represent the input image as a bag of boxes. We show state-of-the-art results on Pascal VOC 2007, Pascal VOC 2010 and ILSVRC 2013. On ILSVRC 2013 our results based on a low-capacity AlexNet network outperform even those weakly-supervised approaches which are based on much higher-capacity networks.

期刊:arXiv, 2018年2月22日
网址:
http://www.zhuanzhi.ai/document/282de21f835031f18a0123b6b5f07584
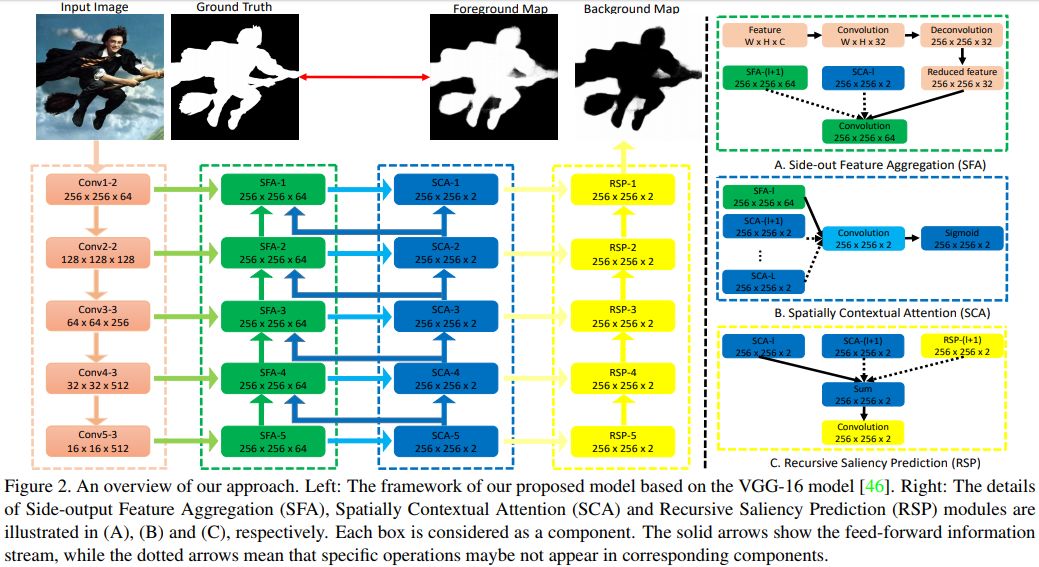
2. Agile Amulet: Real-Time Salient Object Detection with Contextual Attention(Agile Amulet: 具有上下文注意力机制的实时显著目标检测)
作者:Pingping Zhang,Luyao Wang,Dong Wang,Huchuan Lu,Chunhua Shen
摘要:This paper proposes an Agile Aggregating Multi-Level feaTure framework (Agile Amulet) for salient object detection. The Agile Amulet builds on previous works to predict saliency maps using multi-level convolutional features. Compared to previous works, Agile Amulet employs some key innovations to improve training and testing speed while also increase prediction accuracy. More specifically, we first introduce a contextual attention module that can rapidly highlight most salient objects or regions with contextual pyramids. Thus, it effectively guides the learning of low-layer convolutional features and tells the backbone network where to look. The contextual attention module is a fully convolutional mechanism that simultaneously learns complementary features and predicts saliency scores at each pixel. In addition, we propose a novel method to aggregate multi-level deep convolutional features. As a result, we are able to use the integrated side-output features of pre-trained convolutional networks alone, which significantly reduces the model parameters leading to a model size of 67 MB, about half of Amulet. Compared to other deep learning based saliency methods, Agile Amulet is of much lighter-weight, runs faster (30 fps in real-time) and achieves higher performance on seven public benchmarks in terms of both quantitative and qualitative evaluation.
期刊:arXiv, 2018年2月20日
网址:
http://www.zhuanzhi.ai/document/70070ef1920c12227a4441cbf67ee8ef
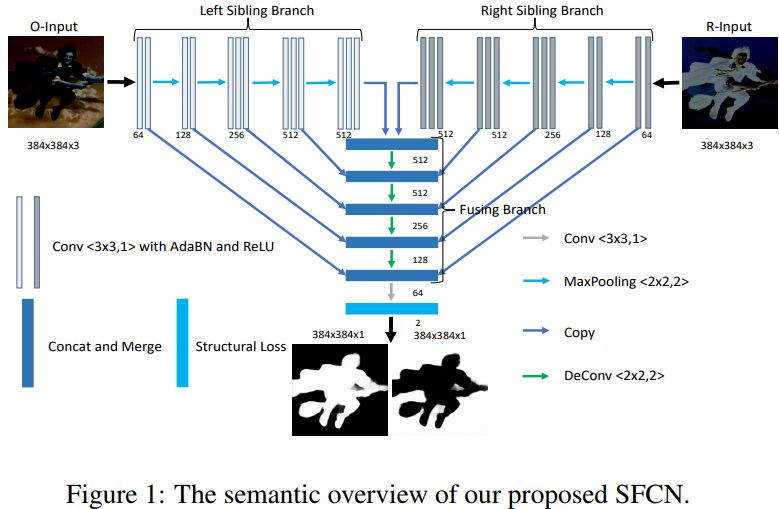
3. Salient Object Detection by Lossless Feature Reflection(Lossless 特征反射的显著目标检测)
作者:Pingping Zhang,Wei Liu,Huchuan Lu,Chunhua Shen
摘要:Salient object detection, which aims to identify and locate the most salient pixels or regions in images, has been attracting more and more interest due to its various real-world applications. However, this vision task is quite challenging, especially under complex image scenes. Inspired by the intrinsic reflection of natural images, in this paper we propose a novel feature learning framework for large-scale salient object detection. Specifically, we design a symmetrical fully convolutional network (SFCN) to learn complementary saliency features under the guidance of lossless feature reflection. The location information, together with contextual and semantic information, of salient objects are jointly utilized to supervise the proposed network for more accurate saliency predictions. In addition, to overcome the blurry boundary problem, we propose a new structural loss function to learn clear object boundaries and spatially consistent saliency. The coarse prediction results are effectively refined by these structural information for performance improvements. Extensive experiments on seven saliency detection datasets demonstrate that our approach achieves consistently superior performance and outperforms the very recent state-of-the-art methods.
期刊:arXiv, 2018年2月19日
网址:
http://www.zhuanzhi.ai/document/0038b3b3c5fca31a387743fed7e25016
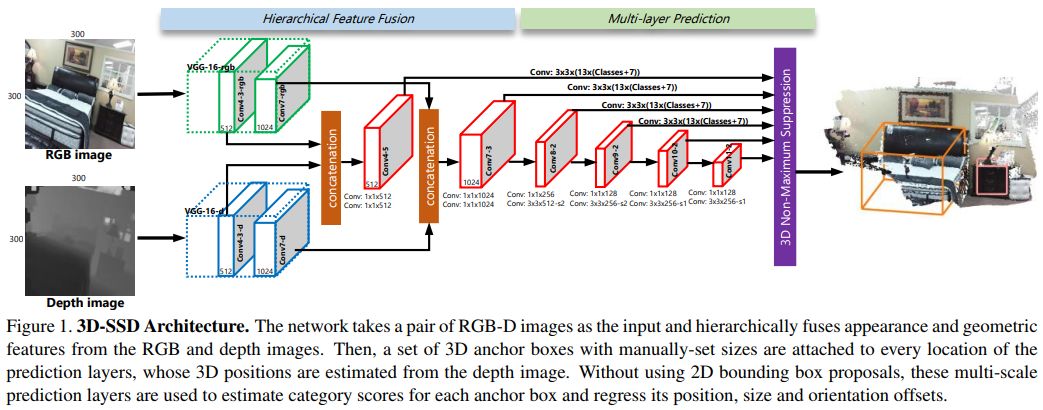
4. 3D-SSD: Learning Hierarchical Features from RGB-D Images for Amodal 3D Object Detection(3D-SSD:基于RGB-D图像层次特征学习的Amodal三维目标检测)
作者:Qianhui Luo,Huifang Ma,Yue Wang,Li Tang,Rong Xiong
摘要:This paper aims at developing a faster and a more accurate solution to the amodal 3D object detection problem for indoor scenes. It is achieved through a novel neural network that takes a pair of RGB-D images as the input and delivers oriented 3D bounding boxes as the output. The network, named 3D-SSD, composed of two parts: hierarchical feature fusion and multi-layer prediction. The hierarchical feature fusion combines appearance and geometric features from RGB-D images while the multi-layer prediction utilizes multi-scale features for object detection. As a result, the network can exploit 2.5D representations in a synergetic way to improve the accuracy and efficiency. The issue of object sizes is addressed by attaching a set of 3D anchor boxes with varying sizes to every location of the prediction layers. At the end stage, the category scores for 3D anchor boxes are generated with adjusted positions, sizes and orientations respectively, leading to the final detections using non-maximum suppression. In the training phase, the positive samples are identified with the aid of 2D ground truth to avoid the noisy estimation of depth from raw data, which guide to a better converged model. Experiments performed on the challenging SUN RGB-D dataset show that our algorithm outperforms the state-of-the-art Deep Sliding Shape by 10.2% mAP and 88x faster. Further, experiments also suggest our approach achieves comparable accuracy and is 386x faster than the state-of-art method on the NYUv2 dataset even with a smaller input image size.
期刊:arXiv, 2018年2月21日
网址:
http://www.zhuanzhi.ai/document/9f38397585b59d60ac02c8531d3d17c8
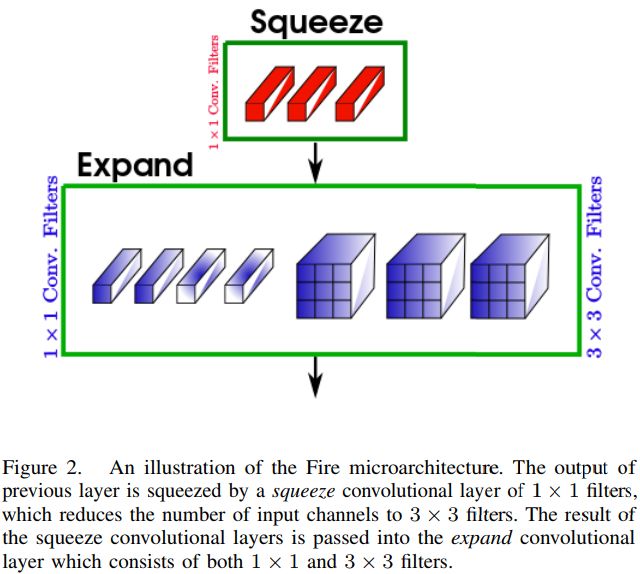
5. Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection(Tiny SSD:一种用于实时嵌入式目标检测的微型Single-shot检测深度卷积神经网络方法)
作者:Alexander Wong,Mohammad Javad Shafiee,Francis Li,Brendan Chwyl
摘要:Object detection is a major challenge in computer vision, involving both object classification and object localization within a scene. While deep neural networks have been shown in recent years to yield very powerful techniques for tackling the challenge of object detection, one of the biggest challenges with enabling such object detection networks for widespread deployment on embedded devices is high computational and memory requirements. Recently, there has been an increasing focus in exploring small deep neural network architectures for object detection that are more suitable for embedded devices, such as Tiny YOLO and SqueezeDet. Inspired by the efficiency of the Fire microarchitecture introduced in SqueezeNet and the object detection performance of the single-shot detection macroarchitecture introduced in SSD, this paper introduces Tiny SSD, a single-shot detection deep convolutional neural network for real-time embedded object detection that is composed of a highly optimized, non-uniform Fire sub-network stack and a non-uniform sub-network stack of highly optimized SSD-based auxiliary convolutional feature layers designed specifically to minimize model size while maintaining object detection performance. The resulting Tiny SSD possess a model size of 2.3MB (~26X smaller than Tiny YOLO) while still achieving an mAP of 61.3% on VOC 2007 (~4.2% higher than Tiny YOLO). These experimental results show that very small deep neural network architectures can be designed for real-time object detection that are well-suited for embedded scenarios.
期刊:arXiv, 2018年2月19日
网址:
http://www.zhuanzhi.ai/document/a2366becabd876786429653cebfd7e7e
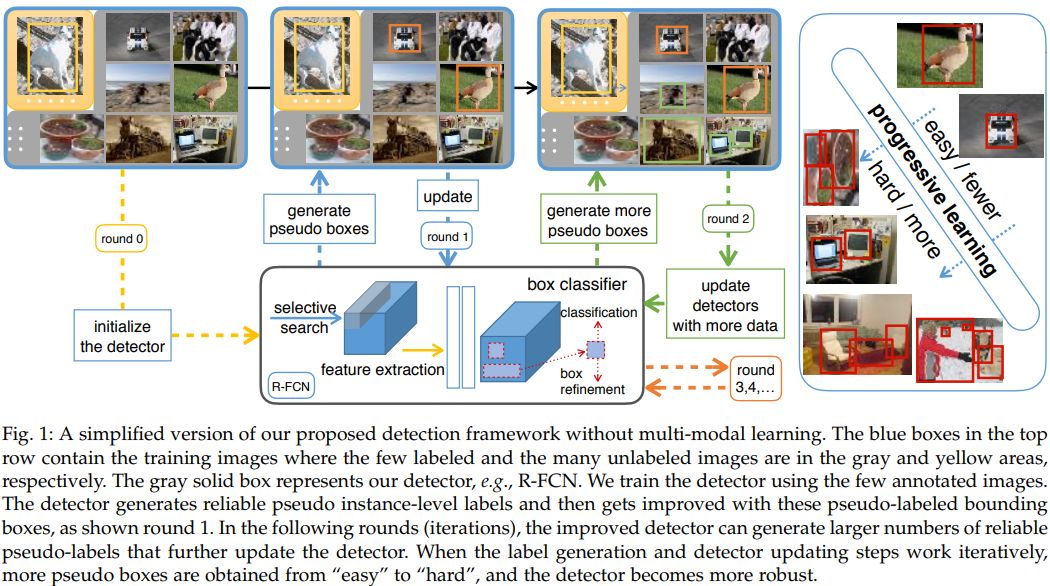
6. Few-Example Object Detection with Model Communication(基于模型通信的少样本目标检测)
作者:Xuanyi Dong,Liang Zheng,Fan Ma,Yi Yang,Deyu Meng
摘要:In this paper, we study object detection using a large pool of unlabeled images and only a few labeled images per category, named "few-example object detection". The key challenge consists in generating trustworthy training samples as many as possible from the pool. Using few training examples as seeds, our method iterates between model training and high-confidence sample selection. In training, easy samples are generated first and, then the poorly initialized model undergoes improvement. As the model becomes more discriminative, challenging but reliable samples are selected. After that, another round of model improvement takes place. To further improve the precision and recall of the generated training samples, we embed multiple detection models in our framework, which has proven to outperform the single model baseline and the model ensemble method. Experiments on PASCAL VOC'07, MS COCO'14, and ILSVRC'13 indicate that by using as few as three or four samples selected for each category, our method produces very competitive results when compared to the state-of-the-art weakly-supervised approaches using a large number of image-level labels.
期刊:arXiv, 2018年2月14日
网址:
http://www.zhuanzhi.ai/document/11c9ffa680772db8f5c60ffffeb3d01b
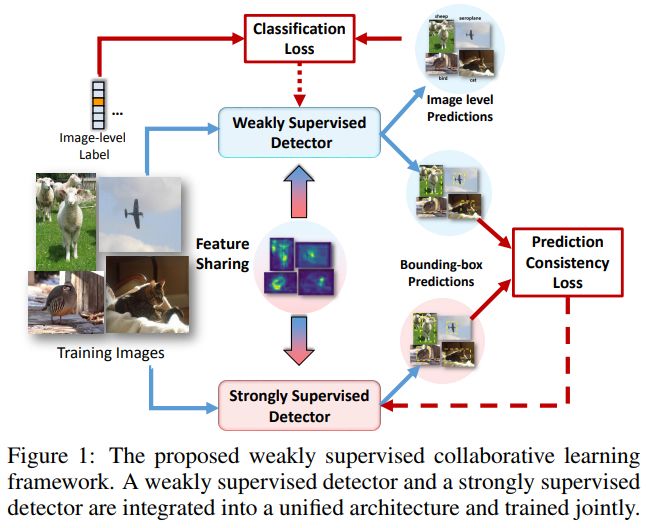
7. Collaborative Learning for Weakly Supervised Object Detection(基于协同学习的弱监督目标检测)
作者:Jiajie Wang,Jiangchao Yao,Ya Zhang,Rui Zhang
摘要:Weakly supervised object detection has recently received much attention, since it only requires image-level labels instead of the bounding-box labels consumed in strongly supervised learning. Nevertheless, the save in labeling expense is usually at the cost of model accuracy. In this paper, we propose a simple but effective weakly supervised collaborative learning framework to resolve this problem, which trains a weakly supervised learner and a strongly supervised learner jointly by enforcing partial feature sharing and prediction consistency. For object detection, taking WSDDN-like architecture as weakly supervised detector sub-network and Faster-RCNN-like architecture as strongly supervised detector sub-network, we propose an end-to-end Weakly Supervised Collaborative Detection Network. As there is no strong supervision available to train the Faster-RCNN-like sub-network, a new prediction consistency loss is defined to enforce consistency of predictions between the two sub-networks as well as within the Faster-RCNN-like sub-networks. At the same time, the two detectors are designed to partially share features to further guarantee the model consistency at perceptual level. Extensive experiments on PASCAL VOC 2007 and 2012 data sets have demonstrated the effectiveness of the proposed framework.
期刊:arXiv, 2018年2月10日
网址:
http://www.zhuanzhi.ai/document/66ae256a29a9a1180950df011d8f5bb5
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



