【论文推荐】最新八篇情感分析相关论文—Pair-wise判别器、多模态情感分析、上下文语境、Gated 卷积网络
【导读】专知内容组既昨天推出八篇情感分析(Sentiment Analysis)相关论文,又
推出最新八篇情感分析(Sentiment Analysis)相关论文,欢迎查看!
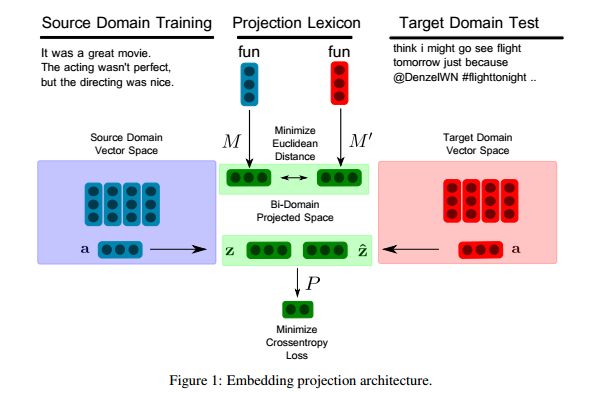
9.Projecting Embeddings for Domain Adaptation: Joint Modeling of Sentiment Analysis in Diverse Domains(Projecting Embeddings for Domain Adaptation:不同领域情感分析的联合建模)
作者:Jeremy Barnes,Roman Klinger,Sabine Schulte im Walde
Accepted to COLING 2018
机构:Universitat Pompeu Fabra,University of Stuttgart
摘要:Domain adaptation for sentiment analysis is challenging due to the fact that supervised classifiers are very sensitive to changes in domain. The two most prominent approaches to this problem are structural correspondence learning and autoencoders. However, they either require long training times or suffer greatly on highly divergent domains. Inspired by recent advances in cross-lingual sentiment analysis, we provide a novel perspective and cast the domain adaptation problem as an embedding projection task. Our model takes as input two mono-domain embedding spaces and learns to project them to a bi-domain space, which is jointly optimized to (1) project across domains and to (2) predict sentiment. We perform domain adaptation experiments on 20 source-target domain pairs for sentiment classification and report novel state-of-the-art results on 11 domain pairs, including the Amazon domain adaptation datasets and SemEval 2013 and 2016 datasets. Our analysis shows that our model performs comparably to state-of-the-art approaches on domains that are similar, while performing significantly better on highly divergent domains. Our code is available at https://github.com/jbarnesspain/domain_blse
期刊:arXiv, 2018年6月14日
网址:
http://www.zhuanzhi.ai/document/309b52eb93cf6d8b337f5fe4e20c0c66
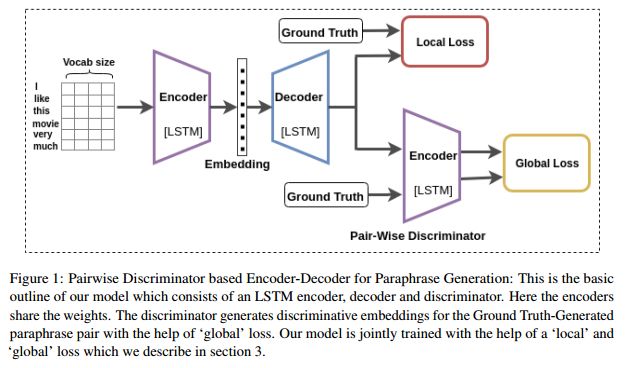
10.Learning Semantic Sentence Embeddings using Pair-wise Discriminator(使用Pair-wise判别器来学习语义句子嵌入)
作者:Badri N. Patro,Vinod K. Kurmi,Sandeep Kumar,Vinay P. Namboodiri
COLING 2018 (accepted).
摘要:In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.
期刊:arXiv, 2018年6月15日
网址:
http://www.zhuanzhi.ai/document/1c12c96dd2e31c56f6afb084b6ef2632
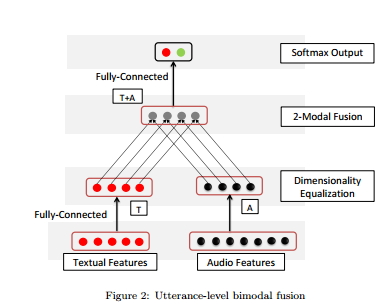
11.Multimodal Sentiment Analysis using Hierarchical Fusion with Context Modeling(运用层次融合和上下文建模的多模态情感分析)
作者:N. Majumder,D. Hazarika,A. Gelbukh,E. Cambria,S. Poria
Accepted for publication at Knowledge Based Systems
机构:Nanyang Technological University,National University of Singapore
摘要:Multimodal sentiment analysis is a very actively growing field of research. A promising area of opportunity in this field is to improve the multimodal fusion mechanism. We present a novel feature fusion strategy that proceeds in a hierarchical fashion, first fusing the modalities two in two and only then fusing all three modalities. On multimodal sentiment analysis of individual utterances, our strategy outperforms conventional concatenation of features by 1%, which amounts to 5% reduction in error rate. On utterance-level multimodal sentiment analysis of multi-utterance video clips, for which current state-of-the-art techniques incorporate contextual information from other utterances of the same clip, our hierarchical fusion gives up to 2.4% (almost 10% error rate reduction) over currently used concatenation. The implementation of our method is publicly available in the form of open-source code.
期刊:arXiv, 2018年6月16日
网址:
http://www.zhuanzhi.ai/document/ca2c4f6f675e2c1ee15626de4b973330
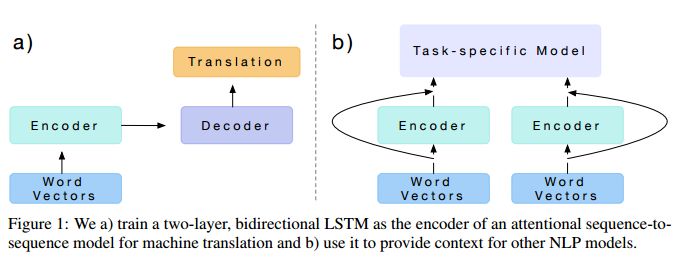
12.Learned in Translation: Contextualized Word Vectors(Learned in Translation:上下文语境的词向量)
作者:Bryan McCann,James Bradbury,Caiming Xiong,Richard Socher
机构:Universidad T´ecnica Federico Santa Mar´ıa
摘要:Computer vision has benefited from initializing multiple deep layers with weights pretrained on large supervised training sets like ImageNet. Natural language processing (NLP) typically sees initialization of only the lowest layer of deep models with pretrained word vectors. In this paper, we use a deep LSTM encoder from an attentional sequence-to-sequence model trained for machine translation (MT) to contextualize word vectors. We show that adding these context vectors (CoVe) improves performance over using only unsupervised word and character vectors on a wide variety of common NLP tasks: sentiment analysis (SST, IMDb), question classification (TREC), entailment (SNLI), and question answering (SQuAD). For fine-grained sentiment analysis and entailment, CoVe improves performance of our baseline models to the state of the art.
期刊:arXiv, 2018年6月20日
网址:
http://www.zhuanzhi.ai/document/970ec2db3b0d64711d6e1cfeeea8d66d
13.A Sentiment Analysis of Breast Cancer Treatment Experiences and Healthcare Perceptions Across Twitter(通过推特对乳腺癌治疗经验和医疗观念的情感分析)
作者:Eric M. Clark,Ted James,Chris A. Jones,Amulya Alapati,Promise Ukandu,Christopher M. Danforth,Peter Sheridan Dodds
机构:The University of Vermont
摘要:Background: Social media has the capacity to afford the healthcare industry with valuable feedback from patients who reveal and express their medical decision-making process, as well as self-reported quality of life indicators both during and post treatment. In prior work, [Crannell et. al.], we have studied an active cancer patient population on Twitter and compiled a set of tweets describing their experience with this disease. We refer to these online public testimonies as "Invisible Patient Reported Outcomes" (iPROs), because they carry relevant indicators, yet are difficult to capture by conventional means of self-report. Methods: Our present study aims to identify tweets related to the patient experience as an additional informative tool for monitoring public health. Using Twitter's public streaming API, we compiled over 5.3 million "breast cancer" related tweets spanning September 2016 until mid December 2017. We combined supervised machine learning methods with natural language processing to sift tweets relevant to breast cancer patient experiences. We analyzed a sample of 845 breast cancer patient and survivor accounts, responsible for over 48,000 posts. We investigated tweet content with a hedonometric sentiment analysis to quantitatively extract emotionally charged topics. Results: We found that positive experiences were shared regarding patient treatment, raising support, and spreading awareness. Further discussions related to healthcare were prevalent and largely negative focusing on fear of political legislation that could result in loss of coverage. Conclusions: Social media can provide a positive outlet for patients to discuss their needs and concerns regarding their healthcare coverage and treatment needs. Capturing iPROs from online communication can help inform healthcare professionals and lead to more connected and personalized treatment regimens.
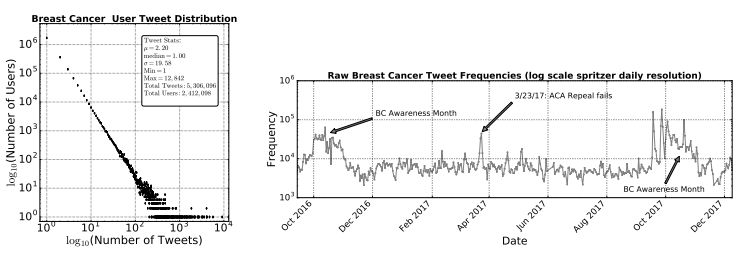
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/a20617987f012062b6ac01f24ac9b0e1
14.Aspect Based Sentiment Analysis with Gated Convolutional Networks(基于Aspect门控卷积网络的情感分析)
作者:Wei Xue,Tao Li
Accepted in ACL 2018
机构:Florida International University
摘要:Aspect based sentiment analysis (ABSA) can provide more detailed information than general sentiment analysis, because it aims to predict the sentiment polarities of the given aspects or entities in text. We summarize previous approaches into two subtasks: aspect-category sentiment analysis (ACSA) and aspect-term sentiment analysis (ATSA). Most previous approaches employ long short-term memory and attention mechanisms to predict the sentiment polarity of the concerned targets, which are often complicated and need more training time. We propose a model based on convolutional neural networks and gating mechanisms, which is more accurate and efficient. First, the novel Gated Tanh-ReLU Units can selectively output the sentiment features according to the given aspect or entity. The architecture is much simpler than attention layer used in the existing models. Second, the computations of our model could be easily parallelized during training, because convolutional layers do not have time dependency as in LSTM layers, and gating units also work independently. The experiments on SemEval datasets demonstrate the efficiency and effectiveness of our models.
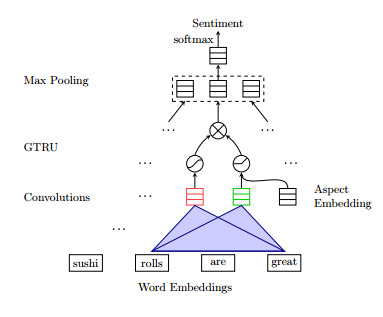
期刊:arXiv, 2018年5月18日
网址:
http://www.zhuanzhi.ai/document/2014ad8a603400fb90090514f36779b5
15.Sentiment Analysis of Arabic Tweets: Feature Engineering and A Hybrid Approach(Sentiment Analysis of Arabic Tweets: 特征工程和混合方法)
作者:Nora Al-Twairesh,Hend Al-Khalifa,AbdulMalik Alsalman,Yousef Al-Ohali
机构:King Saud University
摘要:Sentiment Analysis in Arabic is a challenging task due to the rich morphology of the language. Moreover, the task is further complicated when applied to Twitter data that is known to be highly informal and noisy. In this paper, we develop a hybrid method for sentiment analysis for Arabic tweets for a specific Arabic dialect which is the Saudi Dialect. Several features were engineered and evaluated using a feature backward selection method. Then a hybrid method that combines a corpus-based and lexicon-based method was developed for several classification models (two-way, three-way, four-way). The best F1-score for each of these models was (69.9,61.63,55.07) respectively.
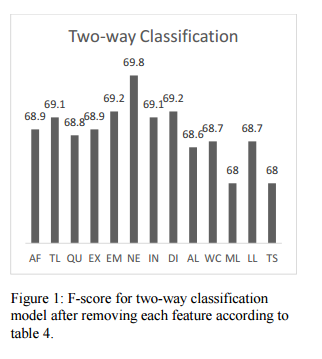
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/2839a4a0253900072285ff1e98d2628e
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



