网络节点表示学习论文笔记03—基于异构网络节点表示的推荐系统
【导读】异构网络可以很好地建模推荐系统中的用户、物品和属性,如何利用异构网络来提取用户、物品的特征,并预测user-iterm rating是一个比较有挑战性的问题。网络节点表示学习(NRL)是一个不错的方案,但大多数NRL算法都基于同构网络设计,因此在将其应用在异构网络时,需要做许多改进。本文中的算法使用基于Meta-Path的随机游走、节点过滤、特征融合、矩阵分解等技术,设计了基于异构网络的推荐算法,取得了很好的效果。
【论文】:Heterogeneous Information Network Embedding for Recommendation

论文链接:https://arxiv.org/abs/1711.10730
▌摘要
由于异构网络在建模异构数据上具有很高的灵活性,异构网络(HIN)被用来建模推荐系统中复杂和异构的辅助数据,这类方法被称为基于异构网络的推荐。为基于异构网络的推荐设计能够抽取和利用信息的算法是很有挑战性的。大多数的基于异构网络的推荐的原理是基于路径的相似性,这使得他们很难充分利用网络中用户和物品隐藏的结构特征。
本文中,我们提出一种新奇的基于异构网络节点表示学习的异构网络推荐方法:HERec。为了学习网络节点的表示,我们设计了一种基于Meta-Path的随机游走方法来生成许多有意义的节点序列。学习到的节点表示先被一系列融合算法转换,然后被集成到了一个扩展的矩阵分解模型中。扩展的矩阵分解模型和融合算法会在预测user-item rating的任务中一起被优化。在三个真实数据集上的大规模实验表明了HERec的有效性。另外,我们展示了HERec在处理冷启动问题上的能力,以及,HERec融合节点表示的技术可以提升推荐系统的性能。
▌简介
Embedding在自然语言处理中有很广泛的应用,如Word2Vec、Doc2vec。近几年,Embedding技术也被用在了推荐系统中,例如一些公司将APP和APP的历史下载序列看成词和句子,将APP进行embedding学习APP向量,以达到APP推荐的目的。本文介绍的论文面向更为复杂的场景进行推荐。
这篇论文将推荐问题建模为Network Embedding的问题,users、items及其attributes都被看成是网络中的节点,网络中的边表示它们之间的关系(比如某用户看了某部电影),最终的目的是为每个user和item都学习一个低维的向量表示,并且学习一个能够利用它们预测user-item rating(即是否需要向用户推荐某个物品)。该论文提出的算法为HERec,同时利用了Meta-Path based Random Walk、特征融合和矩阵分解等技术,架构图如下:
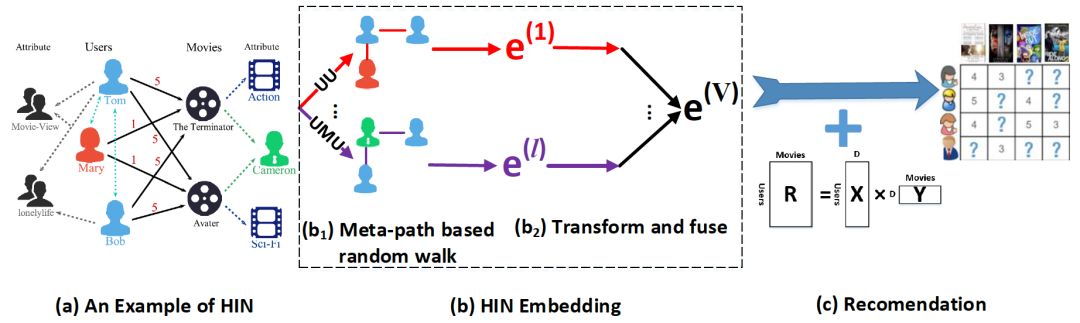
算法的流程主要有下面几步:
1. 利用Random Walk等算法特征提取,为每个user和item学习多个向量特征。
2. 学习如何利用上面提取的特征对user-item rating进行预测。
▌特征提取
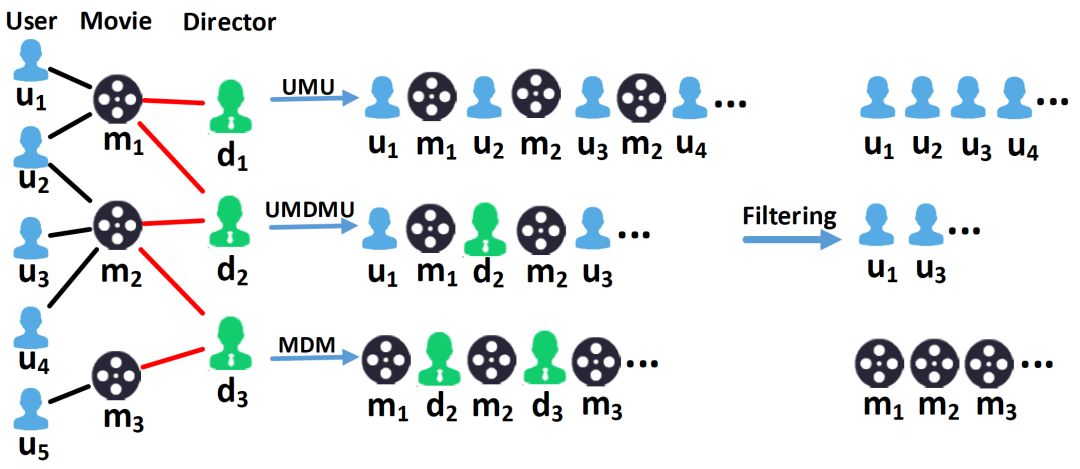
图的左侧是一个异构网络,包含三种节点:User、Movie和Director。在图中,User对应user,Movie对应item,在特征提取流程中,我们希望为每个user(User)和item(Movie)学习多个特征向量表示。Director在这里被认为是Movie的attribute,RandomWalk可以借助attribute节点为user或item建立关系。
算法利用Meta-Path based Random Walk产生了一系列路径。Meta-Pathbased Random Walk与普通Random Walk的不同之处在于,它对游走的路径有一定的约束,例如Meta-Path模式UMU约束了游走时节点的类型必须满足User-Movie-User-Movie-User-……给定多种Meta-Path模式,通过Meta-Path based Random Walk可以产生多种序列。 HERec希望每种序列只用来捕捉一种类型节点之间的关系,因此对于每个序列,HERec只保留一种类型的节点(保留与序列首节点类型相同的节点)。经过过滤,可以得到多个序列,每个序列仅包含User节点或仅包含Movie节点。
对于每个Meta-Path模式,可以产生多个User/Movie序列,在这些序列上使用skip-gram可以为每个User/Movie学习一个特征向量。给定多种Meta-Path模式,我们可以为每个User/Movie学习多个特征向量。
▌预测
基于上面的特征,我们需要学习一些参数,用于预测user-item rating。
首先,对于每个item我们已经得到了多个特征向量,可以用下面的函数来将这些向量融合为一个向量eu(U),这个g(·)函数是需要学习的。对于item,也需要进行同样的操作,为每个item生成一个唯一的item特征向量ei(I)。
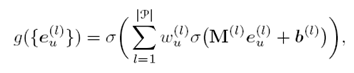
对于每个user-item对,用下面的公式进行对user-item rating进行预测。其中xu、yi、γi(I)、γu(U)都是需要学习的参数。注意,这里并没有直接用eu(U)和ei(I)相乘,这是合理的,在上面利用skip-gram在序列上学习特征时,每个序列只包含user或item,即在学习特征时,并没有将user和item学习到同一个空间中,因此不能用eu(U)和ei(I)直接进行比较,而是要学习新的参数。
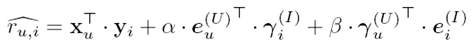
利用预测的user-item rating和真实的user-item rating之间的误差和矩阵分解技术(下图),就可以学习到那些参数了。
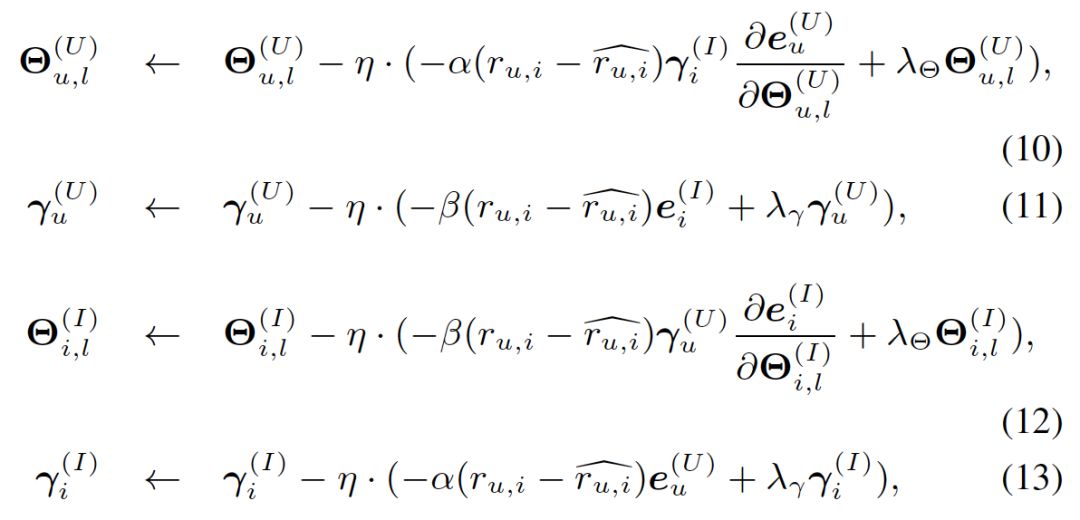
▌实验结果
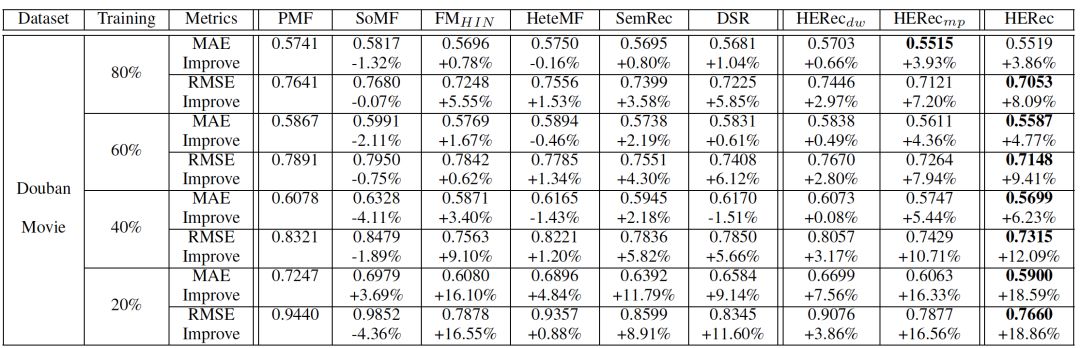
表是在douban movie数据集上不同模型进行推荐的结果

图是不同模型在冷启动预测的结果
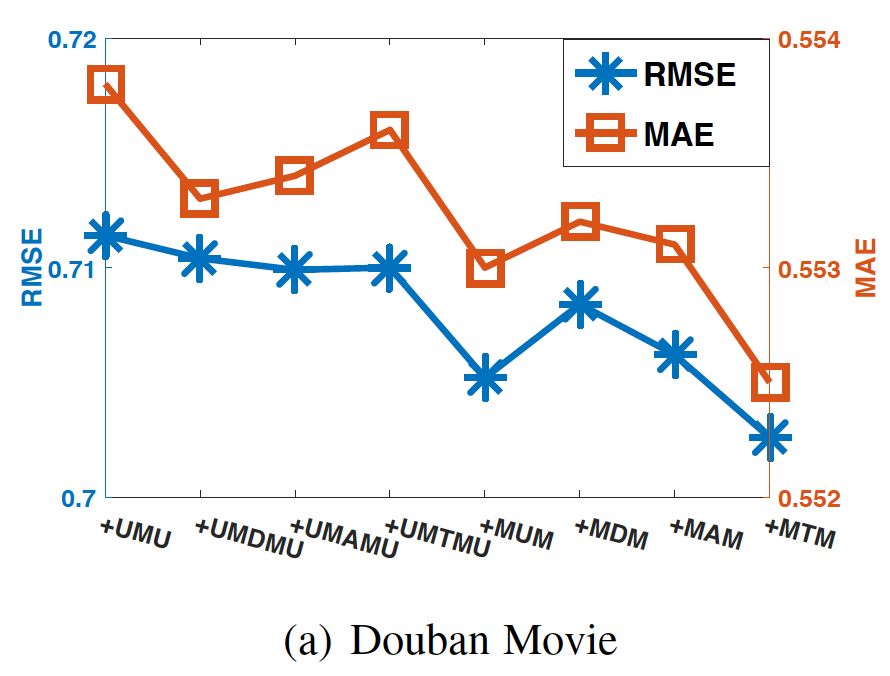
图是meta-paths的结果对HERec的影响。
参考链接:
https://arxiv.org/abs/1711.10730
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



