【论文笔记】基于实体、属性和关系的知识表示学习
【导读】随着知识图谱的广泛应用,关于知识图谱的研究也越来越多,这篇IJCAI 2016文章通过将知识图谱的关系分为关系与属性,从而很好地提高了实验效果。
【IJCAI 2016 论文】
Knowledge representation learning with entities, attributes and relations
Yankai Lin, Zhiyuan Liu, Maosong Sun

摘要:
分布式知识表示将实体和关系投影到低维度的语义向量,极大地提升了关系的抽取和知识推理的效果。在许多知识图谱中,一些关系代表实体的属性而一些关系代表实体之间的关系。目前的知识图谱将这些关系同等看待,当解决1对多或者多对1关系取得很差的实验效果。本文中,我们将目前的知识图谱关系分为关系与属性,并且提出了一个新的模型KR-RAE。实验结果显示,KR-EAR能在关系、属性和实体预测中取得最好的结果。
本文的源代码如下:
https://github.com/thunlp/KR-EAR
介绍:
人们构建大规模的知识图谱(KG)去存储现实生活中复杂的结构信息。知识图谱中的信息经常以三元组(Washington, CapitalOf, USA)的信息进行存储。知识图谱已经被广泛应用在各种不同的应用,例如知识问答和网页搜索。
知识图谱中包含无数的关系,实体及三元组。但目前知识图谱的信息和现实生活的所有信息差距依然很大。为了去进一步拓展知识图谱,许多研究者试图的尝试知识图谱的自动拓展。
最近,基于神经表示学习方法被广泛应用,该方法将实体和关系投影到低维语义向量。作为一个简单而且有效的神经表示学习模型,TransE为关系和实体学习低维向量,并且将关系表示视为头实体表示和尾实体表示之间的平移,对于三元组(h,r,t)我们有h+r≈t。TransE在知识图谱填充和关系抽取中取得很好的效果。
然而,TransE在遇到1对多和多对1问题上效果很差。因为知识图谱的很多关系实际上表示属性,比如性别和职业。所以,我们应该将目前知识图谱的关系分为关系与属性。
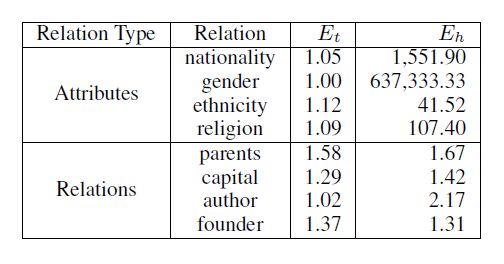
表1 关系和属性典型的例子
从表1,我们举了几个典型的例子,每个头实体关联的尾实体的个数做为Et, 每个尾实体关联的头实体的个数做为Eh。对于属性性别,属性值“男性”如果做为一个尾实体,其对应头实体则是数以亿计的人名。如果将其看做关系,TransE和它的拓展模型会取得很差的效果。
明显地,属性和关系有其很明显的特征:1.对于关系,头实体和尾实体常常有一个很大的实体集。每个实体通过一个关系仅仅和一个有限数量的实体有关联。2.对于属性,属性集中包含的属性值个数很少,但每个属性值对应着很多实体,所以我们应该将知识图谱的关系分为关系和属性。
本文中,我们提出了一个新的模型KR-EAR。在这个模型中,实体和关系表示为低维向量,这个低维向量是这样得到的:1.基于关系建立头实体和尾实体之间的平移,类似TransE。2.基于实体低维向量学习属性值的表示。
我们新建了一个数据集进行实验,实验包括关系预测,实体预测和属性预测。实验显示我们的模型能够取得最好的效果。
论文思想
框架:
我们定义了一个目标函数,这个目标函数最大化关系三元组和属性三元组之间的共同概率,这假定关系三元组和属性三元组之间是独立的。
其中P((h,r,t)|X)是关系三元组的条件概率,P((e,a,v)|X)是属性三元组的条件概率。该模型分为两个部分:1.关系三元组编码器。2.属性三元组编码器。
1.关系三元组编码器
在关系三元组编码器,我们学习实体和关系之间的联系。实际情况下,我们需要优化条件概率P(h|r,t,X),P(t|h,r,X)和P(r|h,t,X)而不是P((h,r,t)|X)。我们以P(h|r,t,X)作为例子讲解。对于P(h|r,t,X)我们有
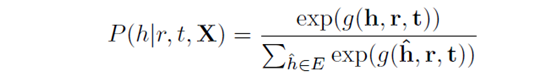
其中g()是能量函数代表关系r和实体对(h,r)之间的关系。对于TransE,其能量函数g(h,r,t)为
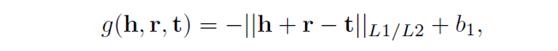
对于TransR,其能量函数g(h,r,t)定义为:
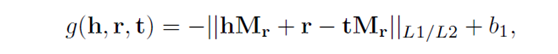
其中b1为偏置,Mr为投影矩阵。我们分别命名以上为KR-EAR(TransE)和KR-EAR(TransR)。
2.属性三元组编码器
关系和其属性应该被划分为一个分类问题。所以我们对于每个三元组(e,a,v)考虑条件概率P(v|a,r,X), 于是我们有
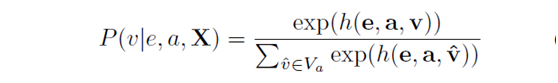
其中h()是给定实体的每个属性值的评分函数。h()函数定义如下:
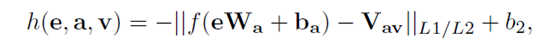
其中f是非线性函数,Vav是属性值v的表示,b2是偏置项。这个函数将向量从实体空间投影于属性空间,然后计算被转换的向量和对应属性值向量的语义相似度。
3.属性之间的关联
不同属性之间会有很强的联系,比如一个是有英国国籍很大概率能说英语。所以KR-EAR模型考虑属性之间的关联。对于一个实体e和它的属性三元组(e,a,v),假设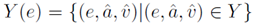
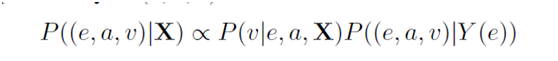
其中P((e,a,v)|Y(e))表示给定e的其他属性三元组求得(e,a,v)的概率,定义如下:
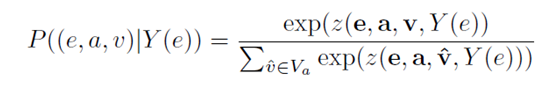
Z()为测量不同属性之间关联的评分函数,定义如下:
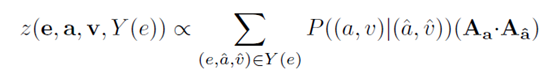
其中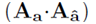
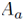
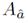
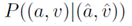
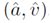
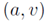
训练:
我们定义优化函数为log似然的目标函数:
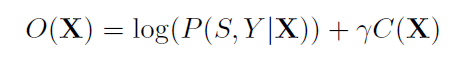
其中
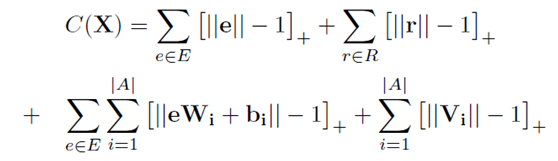
其中
Softmax函数的近似
在KR-EAR模型中,直接去计算P(h|r,t,X),P(t|h,r,X),P(r|h,r,X),P(v|e,a,X)和P((e,a,v)|Y(e))是不切实际的。因为所需计算量极大,特别是对于大型的知识图谱比如Freebase。所以我们采用负采样作为softmax函数的近似,以P(h|r,t,X)举例:
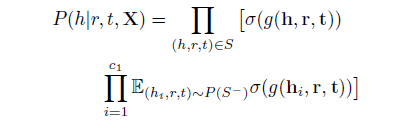
其中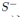
实验结果:
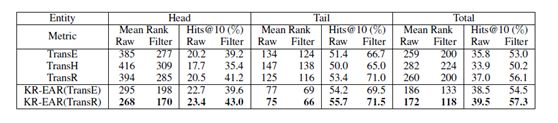
1.实体预测:
2.关系预测:
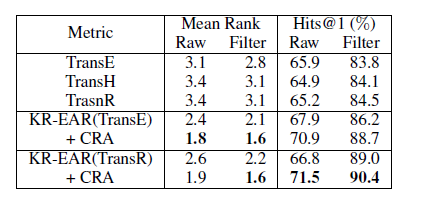
3.属性预测:
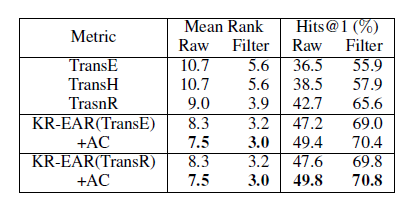
从中可以看出KR-EAR均能取得最好的结果。
原文链接:
https://www.ijcai.org/Proceedings/16/Papers/407.pdf
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



