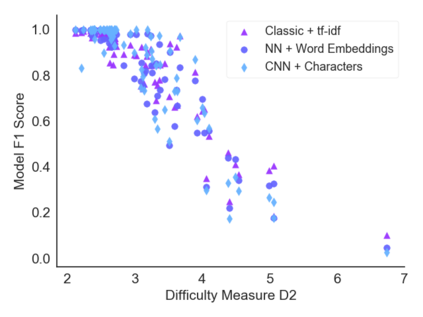
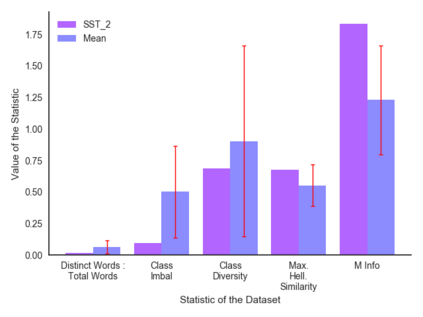
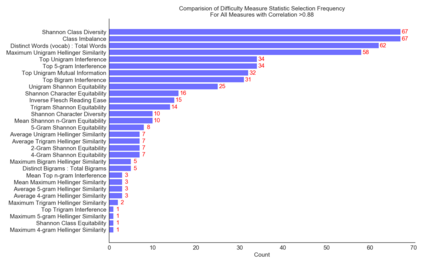
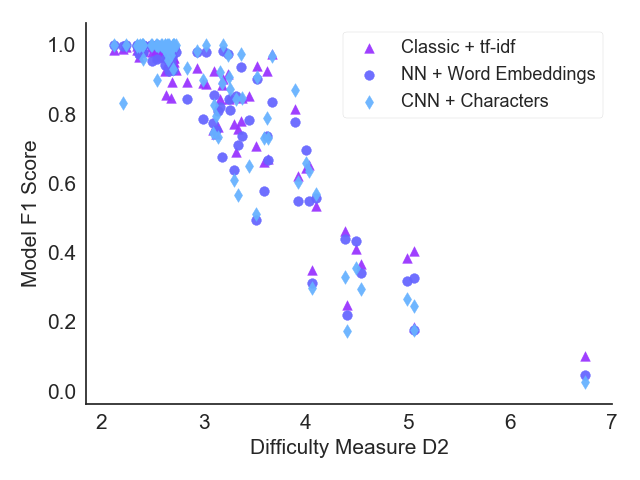
Classification tasks are usually analysed and improved through new model architectures or hyperparameter optimisation but the underlying properties of datasets are discovered on an ad-hoc basis as errors occur. However, understanding the properties of the data is crucial in perfecting models. In this paper we analyse exactly which characteristics of a dataset best determine how difficult that dataset is for the task of text classification. We then propose an intuitive measure of difficulty for text classification datasets which is simple and fast to calculate. We show that this measure generalises to unseen data by comparing it to state-of-the-art datasets and results. This measure can be used to analyse the precise source of errors in a dataset and allows fast estimation of how difficult a dataset is to learn. We searched for this measure by training 12 classical and neural network based models on 78 real-world datasets, then use a genetic algorithm to discover the best measure of difficulty. Our difficulty-calculating code ( https://github.com/Wluper/edm ) and datasets ( http://data.wluper.com ) are publicly available.
翻译:通常通过新的模型结构或超参数优化来分析和改进分类任务,但数据集的基本特性会在发生错误时以临时方式发现。然而,了解数据特性对于完善模型至关重要。在本文件中,我们精确地分析数据集的哪些特性最能确定数据集对文本分类任务的困难程度。然后我们提出文本分类数据集简单而快速计算的一个直观的难度度量。我们通过将它与最新数据集和结果进行比较,来显示对不可见数据的一般度量度。这一度量可用于分析数据集中错误的确切来源,并允许快速估计数据集学习的困难程度。我们通过培训基于78个真实世界数据集的模型的12个经典和神经网络来搜索这一度量,然后使用基因算法来发现最难度。我们的困难计算代码(http://github.com/Wluper/edm)和数据集(http://data.wluper.com)是公开提供的。