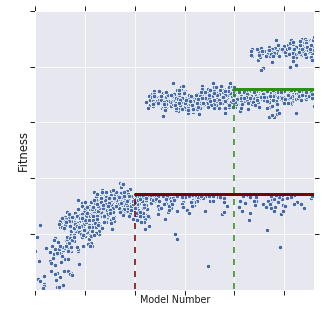
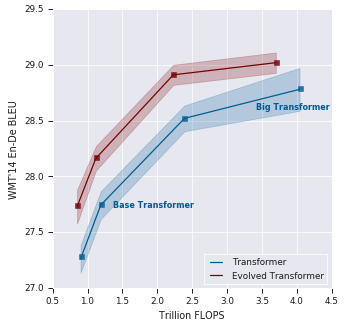
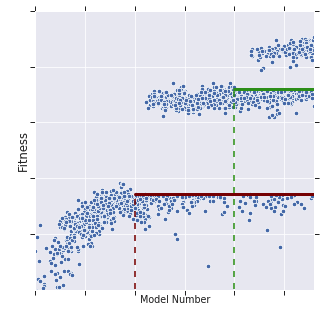
Recent works have highlighted the strengths of the Transformer architecture for dealing with sequence tasks. At the same time, neural architecture search has advanced to the point where it can outperform human-designed models. The goal of this work is to use architecture search to find a better Transformer architecture. We first construct a large search space inspired by the recent advances in feed-forward sequential models and then run evolutionary architecture search, seeding our initial population with the Transformer. To effectively run this search on the computationally expensive WMT 2014 English-German translation task, we develop the progressive dynamic hurdles method, which allows us to dynamically allocate more resources to more promising candidate models. The architecture found in our experiments - the Evolved Transformer - demonstrates consistent improvement over the Transformer on four well-established language tasks: WMT 2014 English-German, WMT 2014 English-French, WMT 2014 English-Czech and LM1B. At big model size, the Evolved Transformer is twice as efficient as the Transformer in FLOPS without loss in quality. At a much smaller - mobile-friendly - model size of ~7M parameters, the Evolved Transformer outperforms the Transformer by 0.7 BLEU on WMT'14 English-German.
翻译:近期的工程凸显了用于处理序列任务的变换器结构的长处。 与此同时,神经结构搜索已经发展到能够超越人类设计模型的超模。 这项工作的目标是利用结构搜索寻找更好的变换器结构。 我们首先根据最近进料-向上顺序模型的进展建造了巨大的搜索空间, 然后用变换器播种我们的初始人口。 为了在计算成本昂贵的2014 WMT 英文-德文翻译任务中有效地进行这一搜索, 我们开发了进步的动态障碍方法, 从而使我们能够动态地向更有希望的候选模型分配更多的资源。 我们实验中发现的结构―― 变动变异变异器―― 在四种既定语言任务上展示了相对于变异器的一致改进: WMT 2014 英德、 WMT 2014 英法、 WMT 2014 英文- 捷克和 LM1B。 在大模型规模上, Evolved变异变换器比FLOPS的变换器效率高一倍而没有质量损失。 一个小得多- 移动友好的模型规模, 由 ~ 7M 7M 的参数 变换变换式的英国变换式变换式变压器由制的英国变压器由制制制制成制成制成制成制成制制成制成制成制成制成制制成制成制成制成制成制成制制制成制成制成制成制成制制制成制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制制