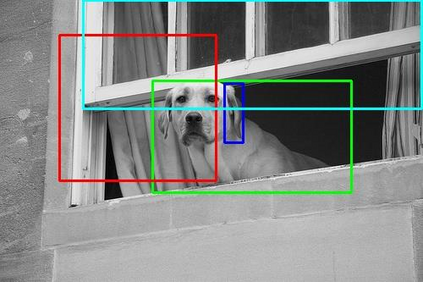
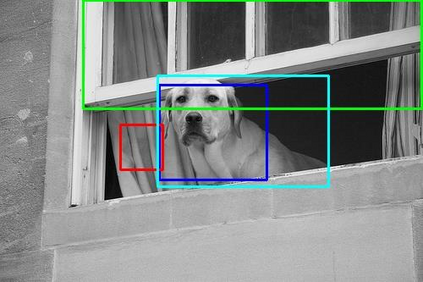
Relationships, as the bond of isolated entities in images, reflect the interaction between objects and lead to a semantic understanding of scenes. Suffering from visually-irrelevant relationships in current scene graph datasets, the utilization of relationships for semantic tasks is difficult. The datasets widely used in scene graph generation tasks are splitted from Visual Genome by label frequency, which even can be well solved by statistical counting. To encourage further development in relationships, we propose a novel method to mine more valuable relationships by automatically filtering out visually-irrelevant relationships. Then, we construct a new scene graph dataset named Visually-Relevant Relationships Dataset (VrR-VG) from Visual Genome. We evaluate several existing methods in scene graph generation in our dataset. The results show the performances degrade significantly compared to the previous dataset and the frequency analysis do not work on our dataset anymore. Moreover, we propose a method to learn feature representations of instances, attributes, and visual relationships jointly from images, then we apply the learned features to image captioning and visual question answering respectively. The improvements on the both tasks demonstrate the efficiency of the features with relation information and the richer semantic information provided in our dataset.
翻译:作为图像中孤立实体的连接关系,我们反映了天体之间的相互作用,并导致对场景的语义理解。从当前场景图表数据集中的视觉关系中发现,使用语义任务的关系是困难的。现场图形生成任务中广泛使用的数据集与视觉基因组任务分开,标签频率甚至可以通过统计计数来很好地解决。为了鼓励进一步的关系发展,我们提出了一个新颖的方法,通过自动过滤视觉关系来挖掘更有价值的关系。然后,我们从视觉基因组中建立一个新的景象图表数据集,名为视觉-相关性关系数据集(VrR-VG),我们评估了我们数据集中场景图生成中现有的几种方法。结果显示,与先前的数据集相比,性能显著退化,频率分析不再对我们的数据集起作用。此外,我们建议一种方法,从图像中学习实例、属性和视觉关系,然后我们将所学到的特征应用于图像说明和视觉问题解答。我们所提供的两个任务都改进了我们数据组合中与更丰富的数据和图像分析的特性的效率。