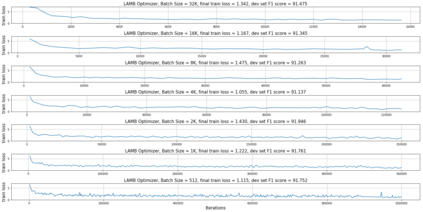
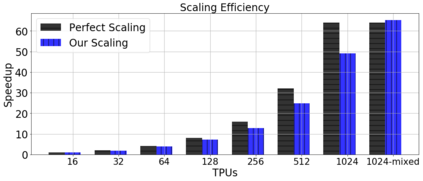
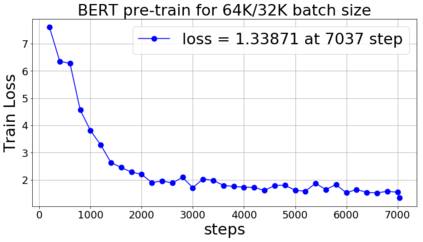
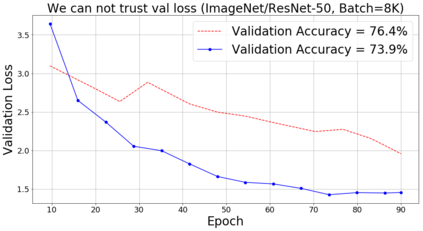
Training large deep neural networks on massive datasets is very challenging. One promising approach to tackle this issue is through the use of large batch stochastic optimization. However, our understanding of this approach in the context of deep learning is still very limited. Furthermore, the current approaches in this direction are heavily hand-tuned. To this end, we first study a general adaptation strategy to accelerate training of deep neural networks using large minibatches. Using this strategy, we develop a new layer-wise adaptive large batch optimization technique called LAMB. We also provide a formal convergence analysis of LAMB as well as the previous published layerwise optimizer LARS, showing convergence to a stationary point in general nonconvex settings. Our empirical results demonstrate the superior performance of LAMB for BERT and ResNet-50 training. In particular, for BERT training, our optimization technique enables use of very large batches sizes of 32868; thereby, requiring just 8599 iterations to train (as opposed to 1 million iterations in the original paper). By increasing the batch size to the memory limit of a TPUv3 pod, BERT training time can be reduced from 3 days to 76 minutes. Finally, we also demonstrate that LAMB outperforms previous large-batch training algorithms for ResNet-50 on ImageNet; obtaining state-of-the-art performance in just a few minutes.
翻译:对大型数据集进行大型深层神经网络培训非常富有挑战性。 解决这一问题的一个有希望的方法是使用大型批量随机优化,然而,我们在深层次学习背景下对这种方法的理解仍然非常有限。 此外,目前朝这一方向采取的方法是手动操作式的。 为此,我们首先研究一项总体适应战略,以利用大型微型信箱加快对深层神经网络的培训。 使用这一战略,我们开发了一种新的、层次上适应性适应性大型批量优化技术,即LAMB。我们还对LAMB以及先前出版的分层优化LARS进行了正式的趋同分析,显示了在一般非康克斯环境中与固定点的趋同。我们的经验结果表明,LAMB为BERT和ResNet-50培训提供了优异端的成绩。 特别是,在BERT培训中,我们的优化技术使得能够使用大批量的368的神经网络网络网络网络网络网络网络;因此,我们只需要85-99次培训(而原始文件中只有100万次重复)。 通过将LAMB-50级培训的批量尺寸提高到一个总的记忆限度。 通过将LPUV3-EMET培训时间从最后从3分钟减少到76分钟。