TextBoxes++:单步多朝向场景文本检测器

场景文本检测是场景文本识别系统的重要步骤,也是一个具有挑战性的问题。与一般物体检测不同,场景文本检测的主要挑战在于任意取向,小尺寸以及自然图像中文本的显着变化的纵横比。在本文中,我们提出了一种名为TextBoxes++的端到端可训练快速场景文本检测器,它可以在单个网络前向传递中以高精度和高效率检测任意朝向的场景文本。除了有效的非最大抑制之外,不涉及后处理。我们已经在四个公共数据集上评估了提议的TextBoxes++。在所有实验中,TextBoxes++在文本定位准确性和运行时方面优于竞争方法。更具体地说,TextBoxes++对于1024×1024 ICDAR 2015附带文本图像,在11.6fps时实现了0.817的f度量,对于768×768 COCO-Text图像,f-measure为0.5591,为19.8fps。此外,与文本识别器相结合,TextBoxes++在流行的基准测试中明显优于最先进的字识别和端到端文本识别任务方法。代码可从以下网址获得:https://github.com/MhLiao/TextBoxes_plusplus
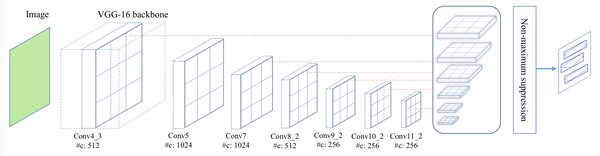

图 1. TextBoxes++的网络结构,一个全卷积网络,包括来自VGG-16的13层,后面是10个额外的卷积层,以及6个连接到6个中间卷积层的文本框层。 文本框层的每个位置预测每个默认框的n维向量,包括文本是否存在的分数(2维),水平边界矩形偏移(4维)和旋转矩形边界框偏移(5维)或四边形边界框偏移(8维)。 在测试阶段应用非最大抑制以合并所有6个文本框图层的结果。 请注意,“#c”代表通道数。
Liao, Minghui, Baoguang Shi, and Xiang Bai. "Textboxes++: A single-shot oriented scene text detector."IEEE transactions on image processing27.8 (2018): 3676-3690.
