
集成学习方法论


在本文中,我将介绍一种关于集成学习的分析优化
因为知乎中对于markdown的支持太差了,本文不在知乎直接排版,所以阅读体验不是很好,若想获得更好的阅读体验,请点击下文链接进行阅读。
所有的文章都会在我的博客和我的知乎专栏同步进行更新,欢迎阅读
下面是正文:
引入
前面的文章介绍了集成学习几种常见的模型,今天,我会就集成学习的原因、类型、改进等进行分析——如何理解这些集成学习算法
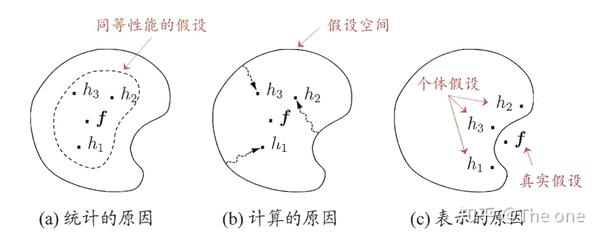
集成原因
为什么要用用弱学习器的结合来形成强学习器,而非直接训练强学习器呢?有以下三方面的原因:
- 统计角度:假设空间很大,必定有多个模型可以拟合训练集,但是单个模型可能因为误选而性能不佳,多个学习器结合则可以降低这个风险,这类似于投资中的分散风险策略。
- 计算角度:类似于多次运行算法,多个弱学习器的结合可以有效降低陷入局部极小值的风险
- 表示角度:真实标记函数可能并不一定在假设空间中,但也许可以通过假设空间中的弱学习器的组合来逼近或者表示。

组合策略
组合策略决定了我们如何通过一系列的弱学习器组合成一个强学习器。可以分为固定的简单组合策略和不固定的学习策略。
简单组合策略
对于数值型回归任务而言,主要有下面两种方法:
- 简单平均法:$H(x)=\frac1T\sum_{i=1}^{T}h_i(x)$,这是最朴素的想法,简单的利用了每个弱学习器
- 加权平均法:$H(x)=\sum_{i=1}^{T}w_ih_i(x)$,其中$w_i$为相应学习器的权重,并要求$\sum w_i = 1$。可以将简单平均法看做它的特例。一般而言,权重是由训练数据学习而来的,但由于现实任务中的噪声等原因,权重并不一定可靠。
当学习器泛化能力相似时,宜用简单平均法,若相差较大宜用加权平均法。
对于判别任务而言,主要有以下三种方法:
- 绝对多数投票法:如果某个标记得到超过半数投票,则输出该标记。若没有标记得到超过半数,则拒绝输出,故绝对多数投票法可能不输出结果,对于要求可靠性较高的任务比较适用。
- 相对多数投票法:如果某个标记得到最多的投票,则输出该标记。该方法必定能输出结果,可以用于必须要求给出结果的任务。
- 加权投票法:与相对多数投票法相似,但是对于不同的学习器有相应的权重,输出获得加权最多投票的标记。
对于判别任务而言,输出的类型一般有两种,要么是概率,例如$\frac 1 3$,要么是标记,例如0或1。一般而言,类概率进行组合的结果常常优于类标记,但是有以下两个原则:
- 类概率必须经过校准才可以使用,校准技术例如:Platt缩放等
- 不同类型的基学习器输出的概率值不可以直接比较,所以异质集成学习必须使用类标记
学习组合策略
与简单组合策略不同的是,学习型组合策略不是固定的,而是通过已经学习在第一阶段已经学习过的初级学习器来得到。
也就是说,初级学习器的输出当做样例的输入特征,而初始样本的标记仍作为标记。
算法伪代码如下:
# 输入:训练集D = {(x1,y1),(x2,y2).....(xm,ym)}
# 输入:初级学习算法 B = {B1 B2 ... BT}
# 输入:次级学习算法 C
def ensembleLearning2(D,B,C):
# 学习得到初级学习器 hi
for i in range(1,T+1):
hi = Bi(D)
# 初始化次级数据集
D’ = 空集
for i in range(1,m+1):
for j in range(1,T+1):
# 得到初级学习器的输出
zij=hj(xi)
# 向次级数据集中添加新的输入特征和标记
D‘ = D’ U {zi1,zi2,zi3......ziT,yi}
H = C(D‘)
return H一般而言,次级学习算法选用多相应线性回归的效果较好。
多样性分析
之前说过,要获得好的集成泛化性能,要求个体学习器要好而不同,下面就不同来进行分析。
多样性分解公式
类似于方差分解,多个弱学习器集成的误差也有一个分解公式:
$$E=\overline E - \overline A$$
其中E是集成后学习器的泛化误差,$\overline E$是个体学习器泛化误差的加权平均,$\overline A$是个体学习器加权分歧值,可以代表个体学习器之间的多样性。
根据公式可以看出:
- 个体学习器性能越好,泛化误差越低
- 多样性越高,泛化误差越低
多样性衡量公式
对于多个学习器而言,多样性衡量一般是通过两两比较得来,对于学习器$h_i,h_j$对于同一个样本x预测结果而言,有以下四种情况,表格中说的是预测的数目
| | $h_i$=+1 | $h_i$=-1 |
| -------- | -------- | -------- |
| $h_j$=+1 | a | c |
| $h_j$=-1 | b | d |
可以用一下方式表达两者的多样性:
- 相关系数:$\rho_{ij}=\frac {ad-bc} {\sqrt{(a+b)(a+c)(b+d)(c+d)}}$,相关系数在[-1,1]之间,0代表完全无关,1代表正相关,-1代表负相关
- $\kappa$-统计量:该统计量比较有效但是复杂。先定义两个量:
- $p_1=\frac{a+d}{m}$,显然,该指标代表了i和j两个学习器在取得一致的概率
- $p_2=\frac {(a+b)(a+c)+(c+d)(b+d)}{m^2}$,该指标代表了i和j两个学习器偶然取得一致的概率。可以看出,a=d=0.5m,该值最小,为0.5;a=m,d=0时,该值最大为1.
由上定义,$\kappa=\frac {p_1-p_2} {1-p_2}$,若i和j完全一样,则值为1,若i和j偶然一样,则值为0.
多样性增强方法
不同的增强多样性的方法可以引出不同的集成算法。
- AdaBoost使用改变样本分布的方法
- bagging使用改变数据集的方法
- 随机森林使用改变属性集的方法
总结来看,有以下四种方法可以生成具有多样性的多个学习器:
- 样本数据扰动:例如通过生成和学习不同的数据子集来训练学习器,这种方法对于不稳定基学习器很有效果,例如线性回归,支持向量机。
- 输入属性扰动:从输出样本中选取不同的子属性集来训练学习器,相当于找到了属性空间的不同子空间,这种方法对于具有大量或者冗余属性的样本适用。
- 输出表示扰动:即对输出的形式进行变换来增强多样性。例如之前讲过的纠错码形式。
- 算法参数扰动:这里的参数指的是超参数,例如神经网络层数,线性回归自变量个数等,一般的选择超参数方法选择一组最优的超参数,而集成学习将多组超参数组合起来使用以增强多样性。
查看更多
所有的文章都会在我的博客和我的知乎专栏同步进行更新,欢迎阅读
