实体消歧论文笔记(一)

Deep Joint Entity Disambiguation with Local Neural Attention
论文提出了一种新的文档级实体消歧的深度学习模型,关键模块包括:
- 实体嵌入
- 局部上下文窗口的神经网络注意力机制
- 用于消除歧义的可微分联合推理阶段
论文的主要贡献
- Entity Embeddings:将实体和单词嵌入到公共的向量空间中;(这避免了手工设计特征)
- Context Attention:将注意力集中于为消歧决策提供信息的词语选择上,对基于上下文的实体得分和提及-实体先验知识进行组合,产生最终的局部得分;(注意力机制具有一定的可解释性,能够可视化)---局部ED
- Collective Disambiguation:文档中的提及使用一个带参数化的条件随机场联合解析,除了预训练的单词和实体嵌入之外,模型是一个端到端的训练模型。(可微,模型能够使用反向传播进行优化)---全局ED
论文中提出的模型特点:精度高、内存小、训练快。
一、实体嵌入
第一步就是训练可用于ED任务的实体向量。
由于传统的实体共现统计面临着稀疏性问题和内存占用大的问题,而单独训练目标子域的实体向量能够提速和节省内存,所以为每个实体独立训练Entity Embedding(Entity Embedding是由word Embedding引导的)。
模型将单词和实体嵌入到相同的低维向量空间中,以便于利用他们之间的几何相似性。
具体步骤是从一个预训练好的word Embedding映射x:W\rightarrow R^{d}开始,其中 单词w\rightarrow W ,将这个映射扩展到实体集 E ,例如 x:E\rightarrow R^{d} 。
为了更好的理解,我们假设一个生成模型,其中与实体 e 同时出现的单词在生成时从条件概率分布 p(w|e) 中采样,单词-实体共现计数来源有两个(1)实体的规范知识库描述页面;(2)带注释的语料库中围绕实体提及的固定大小窗口。这些计数定义了上述单词-实体条件分布的近似值。
我们将单词的"正"分布称之为与实体相关,令 q(w) 为通用词概率分布,它用于对与一个特定实体不相关的"负"词进行采样。期望的结果是正词向量比随机单词的向量更接近于实体e的嵌入(就点乘而言)。
我们使用一个max-margin目标函数来推断实体e的最优嵌入:
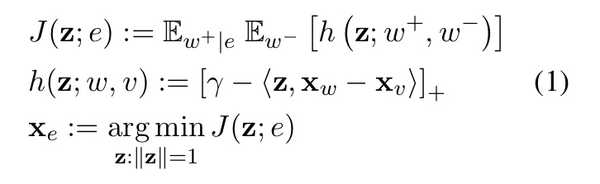

其中, γ >0是一个边缘参数, [·]+ 是ReLU函数。上述损失使用随机梯度下降对采样对 (w+,w-) 上的仿射进行优化。
二、使用注意力机制的局部模型
1、上下文分数
假设我们已经计算了提及-实体的先验概率 \hat p(e|m) 。除此之外,对于每一个提及 m ,已经识别除了最多有 S 个实体的修剪候选集 \Gamma(m) 。模型会基于大小为K的上下文窗口为每一个实体 e∈\Gamma(m) 计算一个分数。这是一个可微分函数的组合,因此我们可以对其进行梯度计算和反向传播。


其中,A是一个参数化的对角矩阵。如果这个单词与至少一个候选实体强相关,则它的权重很高。 w 是单词, e 是实体,而 x 是预训练的映射。
由于没有信息的单词(类似于停用词)可能会得到不可忽略的分数,进而对我们的局部上下文模型添加噪音。所以,我们进行剪枝,只保留top R(<=K)个最高的分数,然后再这些权重上面应用softmax函数:
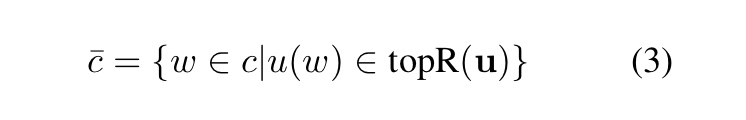

最终的attention权重为:
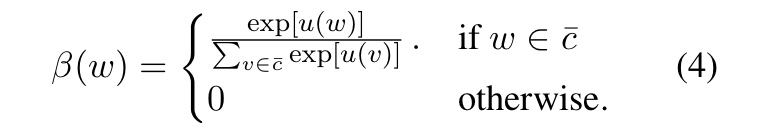

最后,我们定义一个 β 加权的基于上下文的实体-提及分数为:
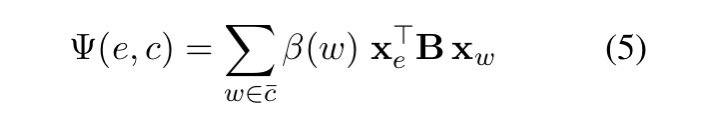

其中B是另一个可以训练的对角矩阵。
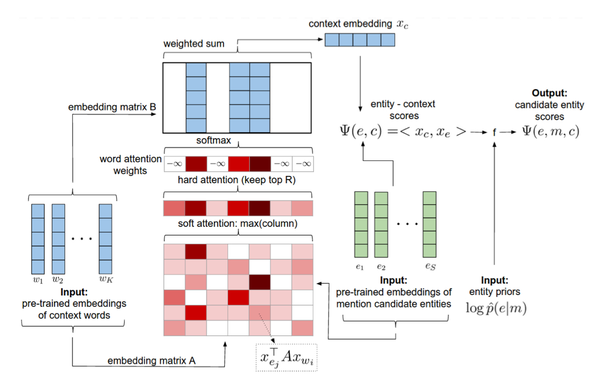

上图是具有神经网络注意力机制的局部模型。
输入:上下文单词向量,候选实体先验概率和候选实体嵌入。
输出:候选实体分数。
所有的部分都是可微的,可以通过反向传播进行训练。
2、局部分数组合
我们将这些上下文得分与以 \hat p(e|m) 编码的上下文无关得分相结合。最终得到一个(非规范)local model,它是\Psi(e, c)和log \hat{p}(e | m)两者的结合。
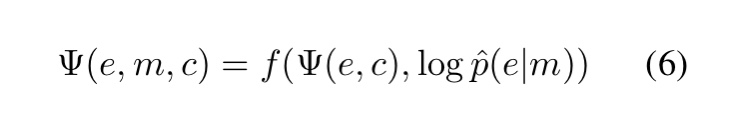

我们发现 f 的选择很重要,其优于一个朴素的加权平均组合模型。
预测过程是独立地最大化每个提及m i和上下文c i的\Psi(e, m i, c i)分数。
3、学习局部模型
实体和词嵌入都是预训练的,所以要学习的参数只有对角矩阵A和B,再加上 f 的参数。参数较少可以防止过拟合,能够用很少的注释数据进行训练。
假设已经从语料库中一系列提及-实体对 \{(m, e^{*}) \} 和它们对应的上下文窗口。对于模型拟合,利用一个max-margin损失使得真实实体的得分高于候选实体。所以有了下面的目标函数:
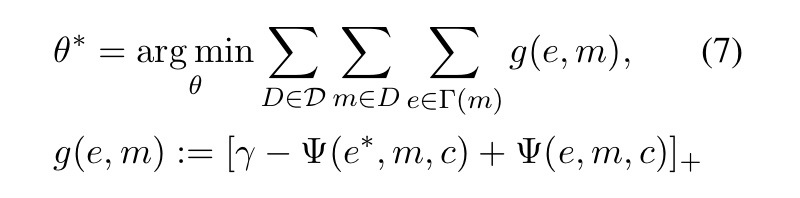

其中, \gamma >0是一个边缘参数, Ð 是一个实体注释文档的训练集。我们旨在发现一个 \Psi (例如由 \theta 参数化)使得由 m 引用的正确实体 e^{*} 的得分至少比任何一个其他的候选实体 e 要高出一个边缘 \gamma 。当情况不是这样的时候,边缘偏差就变成了期望损失。
三、文档级深度模型
接下来,我们假设实体间具有文档一致性来处理全局ED。假设文档中具有一组提及 m=m_{1},...,m_{n} ,它们的上下文窗口为 c=c_{1},...,c_{n} 。我们的目标是定义一个基于 \Gamma(m_{1})×...×\Gamma(m_{n})\ni e 的联合概率分布。每一个这样的 e 为文档中的每一个提及选择一个候选实体。显然, e 的状态空间随着提及的数量 n 呈指数级增长。
1、CRF模型
条件随机场的公式定义为:
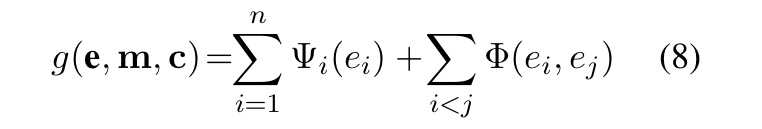

其中,一元的特征是局部分数 \Psi_{i}(e_{i}) = \Psi_{i}(e_{i}, c_{i}) (式5)。成对的特征是实体嵌入的双线性形式:
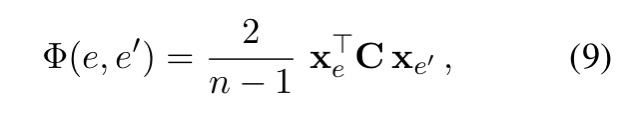

其中, C 是一个对角矩阵。上述的正则化平衡了有不同数目的提及的文档间的一元项和成对项。
对于语义相关的实体集(也具有本地的支持),函数值 g(e, m, c) 的值较高。全局ED是在CRF上进行最大值后验,以找到使 g(e, m, c) 最大化的实体 e 的集合。
2、可微推理
训练和预测诸如上面的CRF模型中的是NP难的。因此,在学习中通常会最大化似然近似,在预测中通常会基于消息传递来使用近似推理过程。
我们将循环信念传播(LBP)的截断拟合应用于固定数量的消息传递迭代。模型直接优化了边际可能性。该方法对于模型错误指定具有鲁棒性,可避免分区函数固有的困难,并且与双环似然训练(在每次随机更新中,推理一直运行到收敛)相比,它更快。
论文的架构如下图所示。一个带有T层的神经网络对同步max-product LBP的T次消息传递迭代进行编码,它旨在查找最大化 g(e,m,c) 的最可能(MAP)实体分配。我们还使用消息衰减,它可以加快并稳定消息传递的收敛。
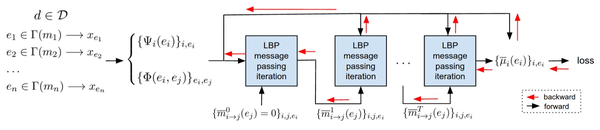

形式上,在第t次迭代时,提及 m_{i} 使用归一化的log-message \bar m_{i\rightarrow j}^{t}(e) 对提及 m_{j} 的实体候选 e\in\Gamma(m_{j}) 进行投票:
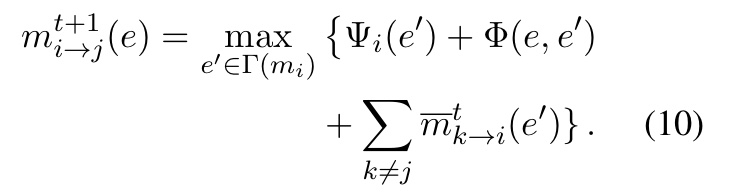

其中,第一部分就是CRF,第二部分定义如下:
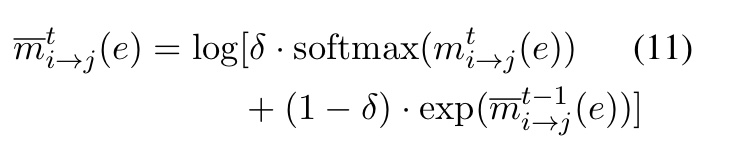

其中, \delta\in(0, 1] 是一个衰减因子。不失一般性,我们通过删除因子节点来简化LBP过程。第一次迭代(层)的消息设置为0。
经过T次迭代(网络层),信念(边际)的计算公式为:
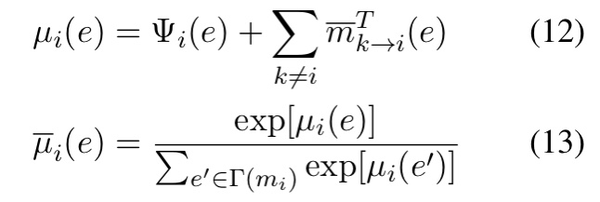

类似于局部ED,我们使用和式6中相同的非线性组合函数 f 组合提及-实体先验概率 \hat p(e|m) 和边际 \mu_{i}(e) ,这提高了准确率:


全局ED的可学习函数 f 是不可忽视的,实验表明,对于较大的 \mu(e) ,先验的影响趋于减弱。然而只要文档级的证据薄弱,它就会起主要作用。
作者还对直接将先验知识集成于一元因子 \Psi_{i}(e_{i}) 做了实验,但是结果差强人意,因为在某些情况下,全局ED不能够应对严重错误的先验知识。
全局模型的参数是对角矩阵A,B,C和网络 f 的权重。同样和之前一样,最有效的方式是基于目标函数找到一个边缘:
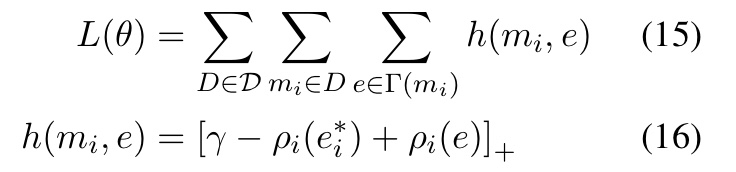

每一步都是可微的,并且可以使用链式法则在结果边际上计算模型参数的梯度,并通过消息进行反向传播。
在测试时,使用此网络对每个文档联合计算边际 \rho_{i}(e),但是对每个mention m_{i} 是独立地最大化它们的边际得分。
四、候选选择
论文不仅使用提及-实体先验 \hat p(e|m) 作为特征,还将其用于实体候选选择。它是通过对来自维基百科和大型Web语料库的提及实体超链接计数统计数据的两个索引的概率进行平均计算得出的。此外,作者还添加了YAGO字典,其中每个候选都是统一的先验。
对于每一个mention,候选选择,即 \Gamma(e) 的构造,如下:
首先,根据先验 \hat p(e|m) 选择前30个候选。然后,为了优化内存和运行时间。只保留了这些实体中的7个:
①基于 \hat p(e|m) 选择的前4个实体
②使用式5计算的局部上下文-实体相似度最高的前3个
在某些情况下,对同一人的通用提及(例如Peter)是同一文档中更具体提及(例如Peter Such)的共同引用。解决办法是:对于每一个mention m ,如果存在人的提及包含 m 作为单词的连续子序列,我们就将这些具体提及的候选集的合并集视为mention m 的候选集。如果 \hat p(e|m) 最有可能的候选对象是人,则我们决定提及是指一个人。
五、实验
略。
六、错误分析
- 注释错误
- 未出现在提及的候选集中的真实实体
- 提及的真实实体具有很低的 p(e|m) 先验,而不正确的实体候选有较高的先验
例如,提及"意大利人"在某些特定的情况下是指"意大利国家足球队",而不是代表代表该国家的实体。这种情况下,上下文信息不足以避免错误。
另一方面,有很多情况是上下文具有误导性,例如,大量讨论板球的文档将会把提及"澳大利亚"映射为"澳大利亚国家板球队",而不是真实实体"澳大利亚"(在板球比赛的上下文中命名一个位置)。
