
任务型对话管理的产品实践(第二篇)- Data-driven 方法应用的困难

副标题:语料问题和领域逻辑
丁南 更新于 2019-05-28
上一篇 我们聊了对话管理的 handcrafted 和 data-driven 方法,本文从项目实施的角度讨论一下 data-driven 应用的困难,以及两种方法不同的适用场景。下图深色节点是本文的思维导图。


图 1 本文思维导图
对话管理所依赖的语料问题
首先,实现「基于数据」的方法前提肯定是需要大量标注数据的,开发者在准备标注语料时通常会面临:标注难度高,数量要求多,数据质量低,以及语料来源有限等问题。
跟一般的 NLP 任务的数据标注不同,对话管理所需的语料并不是一段段孤立的文本,而是整个对话序列。标注时需要考虑上下文以及整个对话的目标,以便确定系统的最佳选择,这样的标注工作难度很高。
另外,对话场景有多变性和多样性的特点,也就是说样本空间很大,统计学习对数据集规模有很高的要求。通常情况下需要远大于 10000 条的对话语料 [1],这是项目能有效实施一个很大的阻碍。
再者,企业并没有那么多专业的领域专家来做语料标注,非专业的数据标注质量也影响着机器学习方法的有效性。通常在开发对话项目的过程中,领域专家设计对话逻辑、完成对话描述、定义用户意图和 dialog act 等信息。项目的 deadline 一般不会允许他/她来做数据标注,这部分工作一般由专门的标注团队来辅助,甚至外包给第三方。但标注团队毕竟不是领域专家,对任务理解不当会导致出现很多标注错误。由于对话系统依赖的语料数量太大,要想快速扩充数据通常会实施多人标注,不同人对项目理解不一致会进一步加重数据质量的问题。
最后,开发者在做数据准备时还会遇到数据来源匮乏的问题。这恐怕是最严重的问题,因为真实世界的语料分布几乎决定了机器人上线后的泛化能力。而现实情况是,企业在项目冷启动时往往并没有人机对话数据,手头上可能只有任务描述书,好一点儿的可能会有同领域的人人语料(human-human dialogs),但这些都不足以覆盖整个人机对话真实场景。
现实情况一:已有人机对话语料
对于那些要开发基于统计学习 DM 的企业来说,如果已经有了人机对话日志的话,是一种比较理想的情况。这种情形一般指的是企业已经用上了基于规则对话系统,想通过已有的人机日志来改善系统的鲁棒性和任务的覆盖率。由于已经有了海量的真实对话样本,数量要求和数据来源都已不是问题,重要的是标注难度和标注质量。
业界一般采用先随机选择后主动学习(active learning)的思路来降低标注成本。大致做法是标注同学先随机抽取人机会话日志,根据每一通对话的上下文和任务目标,顺序检查会话中的所有系统响应。如果响应符合对话目标,该响应保留;如果响应不正确,手工将之修改为正确的系统响应,然后舍弃剩下的对话。这里舍弃的原因,并不是不想处理余下的用户问题,而是用户有可能被错误的系统响应「带偏」,做出了理想对话中不会出现的交互,对话的进展已经不是我们期望的那样,处理这些不正常对话的成本很高,使用价值低,所以一般的处理方式都是直接将其丢弃 [2]。跟其他的机器学习任务一样,在有了一批随机选择并标注的语料后,利用主动学习也可以降低 DM 的标注成本(这里主要指的是用监督学习做 DM 的方法)。随机选择标注一段时间后,就可以用这批种子语料来训练一个初始模型,根据该模型的预测结果可得到 DM 输出的「不确定性得分」(有的学者也将「样本代表性」考虑进去,但主动学习的选择策略不是本文的重点,不展开讨论)。最后求出所有会话的平均得分,根据得分进行排序,排序的结果就是对模型提升有价值的一种假设。标注人员优先选择不确定最高的会话进行标注,标注后再迭代模型和下一轮的数据排序。(也有学者是反对 active learning 的,因为这样会生成 biased data,降低标注数据的利用价值,具体讨论可见这个 博客)
解决了项目的数据标注问题,拿到了大批标注语料,本以为模型会立刻起飞、项目会顺利上线、团队会庆祝里程碑 ,但真实情况很可能是 DM 的响应预测并不靠谱,预测正确率和对话完成率都达不到上线要求,这时一种可能的原因是标注质量太差。标注质量问题在机器学习项目中普遍存在,尤其是标注工作外包给非专业的第三方。标注错误的原因大致可分成三类 [3],主观理解错误(subjective error),例如不同人员对任务描述的理解可能会不同;数据录入错误(data-entry error),例如将多人标注的结果汇总到一起时的操作错误;以及关键信息缺失(shortage of information)导致不足以做标注判断。
提高标注质量一般从两个方面入手,处理已标注的错误,和质量控制(quality control)。
比较常见的处理标注错误的方法是数据清洗(data cleansing)。如图 2,根据一种过滤条件,用一类过滤器将标注数据中「最可能出错」的样本剔除,用清洗后的语料训练模型。过滤器可以有很多选择,常见的是 ensemble filtering,根据 model variation 或 data variation 策略训练多个 base classifiers [4]。过滤条件常用的是 majority filtering 或 consensus filtering,majority filtering 指的是如果一半以上的 base classifiers 预测结果都和标注不一致,则该样本为错误样本;Consensus filtering 指的是所有 classifiers 都与标注 label 不一致,才视为错误。可见 consensus 过滤条件更苛刻、更保守,不容易将错误的样本剔除出去;而 majority 过滤条件相对宽松,能更好地识别标注错误,但这是以丢弃正确数据为代价的。在实际项目中,往往不会将标注数据直接丢弃,毕竟是经过真金白银进行了标注工作(通过强渠道可自动打标的项目除外,例如微软的 DSSM 模型 [5])。标注数据是如此宝贵(尤其是项目前期),以致于我们宁愿花人力去审核这些被过滤的样本。
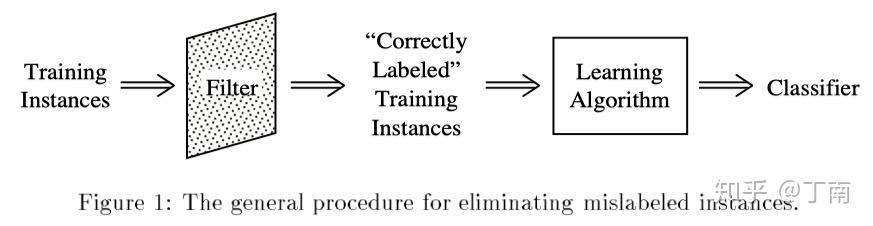

图 2 标注错误 filtering 处理流程 [3]
另一方面,提高标注质量还可以从工具和流程层面入手。一般数据录入(data-entry)错误很多是标注同学的无心之举,毕竟标注任务繁重,不可能 100% 集中注意力,这就对标注工具的产品设计提出了很高的要求。标注工具应尽可能的自动化标注操作,让 annotators 尽可能地只做简单的决策。例如用标签选项代替人工输入,以便排除输入错误的可能性。或者推荐最佳预测标签,annotators 只需做判断题,降低决策成本。数据准备期通常占一个机器学习项目一半以上的时间,优秀的标注工具的重要性是不言而喻的,我们从优秀的产品中学到了很多经验,特别推荐大家使用 Dataturks、LightTag 和 tagtog。
标注质量控制的流程大多用在外包和众包的场景,当公司有独立的标注团队时(比如我们公司),也常用来规范跨团队合作的流程。质量控制一般采取前期任务设计(up-front task design),和事后结果分析(post-hoc result analysis)[6]。在开始标注工作之前,负责人根据手上的任务描述设计标注任务,这时就需要考虑可以通过什么手段来降低标注出错的概率,提高工作的容错率。例如将一个复杂的标注任务拆分成多个简单的子任务,将子任务分派给能力或技能不同的人,最后将子任务的结果再自动化或人工进行合并汇总,这个流程类似分布式系统的 MapReduce,如图 3。它的假设是相比于复杂的任务,普通人更擅长处理简单的任务,如果将任务拆分,整个流程的效率和质量更易控制。而且将一个任务由多人完成,可以更好的利用集体智慧(collective intelligence)[7]。一次标注任务结束后,需要对标注结果进行分析,分析的目的主要有几个,一是让负责人了解这次标注的有效情况,二是有利于标注团队的工作改进,三是方便将无效数据进行过滤或重新审核,四是规避作弊情况(主要针对众包场景)。标注的自动化分析较常用的是结果一致性指标(agreement),通过将一部分相同的语料分给多个 annotators,最后计算这部分标注的一致性结果。这个方法虽然很好操作,但不能 100% 规避作弊问题 [8]。类似 Amazon Mechanical Turk 众包平台更常用的是 Golden Answers [9],即提前准备一小部分已正确标注的数据,将其作为标注任务的一部分分配给 annotators,这部分的正确率就可以评估标注团队的工作。
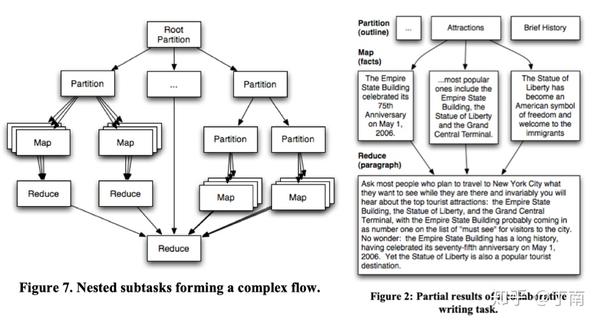

图 3 Partition-Map-Reduce 标注框架及示例 [7]
现实情况二:冷启动
对于很多企业来说,当开启一个新的对话系统项目时,通常是没有任何语料的,这种情况我们称为冷启动。这时如果要想实现一个基于统计的对话管理就更困难了,开发者面临的主要问题是:数量要求和语料来源。
在没有任何语料的情况下,大家一般会选择自造数据。得到一份初始种子语料后,快速迭代模型,选择一批种子用户快速得到反馈和新一批测试语料,迭代更新模型,再扩大测试用户,如此滚雪球,将语料和模型慢慢做大。由于对话语料不同于一般 NLP 数据,需要多轮的交互数据才能反映真实的对话场景,Walliams [10] 提出用一种 interactive teaching 的方式,让开发者一人分饰两角,模仿用户的问题并同时为系统做对话标注,见图 4 示例。这种方法也应用在了 Rasa 的对话管理开源框架中 [11],Rasa 建议开发者通过 command line 编写领域内的对话,与 command line 交互过程也可以对意图识别、实体识别的结果进行纠错,非常方便。
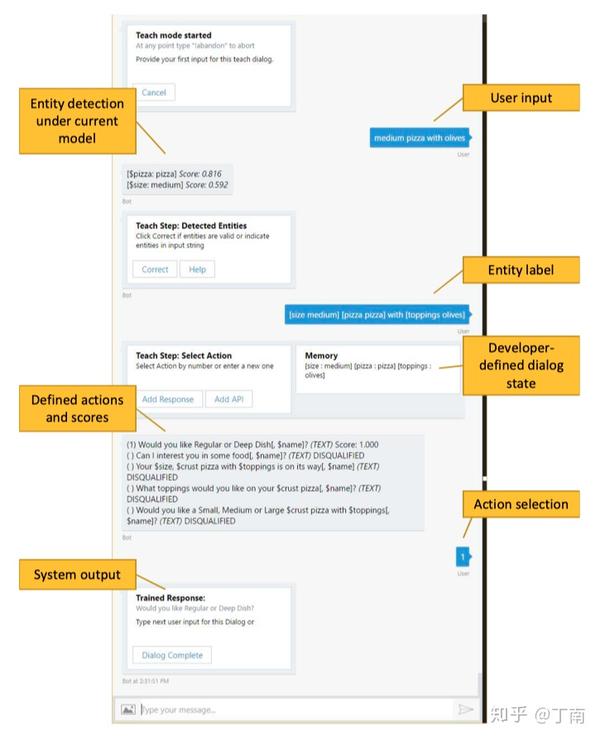

图 4 Dialog interactive learning [10]
自造数据最大的问题是扩展速度太慢,覆盖场景太有限。虽然有种子用户的测试,但测试范围太窄,必须不断迭代扩大种子用户,小心翼翼的反复测试。而如果在场景覆盖不完备的情况下将系统暴露给用户,会立即变成战五渣。所以自造数据往往并不满足统计方法对语料量的要求。为了解决这个问题,研究者提出可以使用 user simulator 模拟人机对话,让机器自动生成对话交互语料。User simulator 是一个很大的话题,也一直是对话系统的研究热点。早期的方法很直接,用 action bi-gram model 根据系统上一个 machine action 预测下一个 user action [12]。这种方法弊端很明显,它仅仅依赖系统的上一个 action,并且也没有考虑诸如 user profile、user goal 等特征,产生的会话一致性会很差。后来 Schatzmann 提出一种很适合任务型对话的 agenda-based user simulator [13],这个方法借鉴了类似 goal-based 方法,用一个 stack 结构来维护将要进行的 user action,这个数据结构称为 agenda(图 5)。和机器交互后 simulator 会更新 agenda 中的 future user actions,例如 pop 或 push 新的 user action 到 agenda 中。由于 agenda 隐含了用户目标,会话目的始终是完成对话任务,所以这样生成的对话有很好的一致性。这几年 sequence-to-sequence 方法很火,也有学者将其应用到 user simulator 中 [14],将 machine context 到 user action 看做一个 source-to-target 序列生成问题,由于可控性不高,这种方法应用在任务型的对话系统还不常见 [15]。
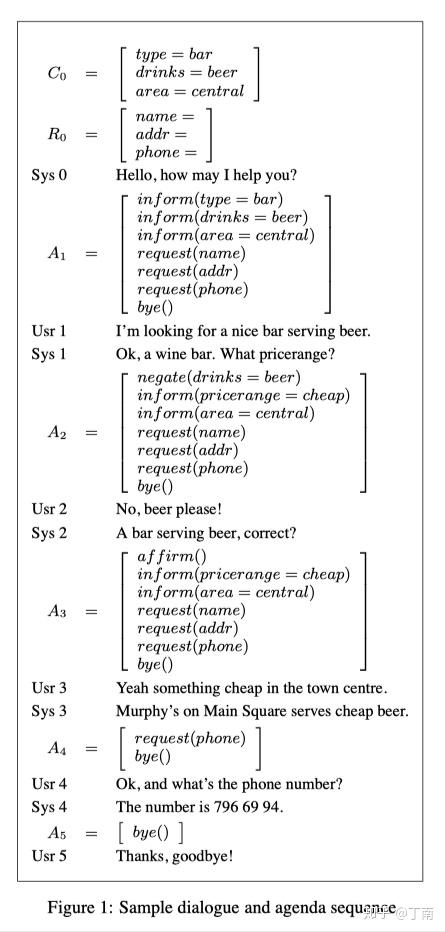

图 5 Sample dialog and agenda sequence [1]
自造语料可以解决数据从 0 到 1 的问题,对话模拟器可以解决从 1 到 10000 的问题,但这两个方式都不能解决数据来源的问题。企业自造语料时找到的测试用户通常是公司内的同事,他们很可能已经对测试流程和对话场景非常熟悉了,这样产出的语料往往会拟合于已有的对话逻辑。并且种子用户的身份和企业的真实用户可能差距很大,例如理财公司的用户是有真实理财需求的,如果种子用户并没有理财经验,他们无法完全模拟真实用户使用对话系统的情况。一种解决办法是用灰度发布,通过接入小范围的真实用户,检验系统响应质量,收集真实世界的数据。这个方法很普遍也很有效,但有几个限制条件,一是企业已经有一个效果还算 ok 的对话系统,例如先做一个基于规则的 DM 跑灰度测试;二是对话任务涉及的业务可以容忍一定程度上的错误率。但如果涉及的业务非常重要,企业需要让对话失败的风险尽可能可控,这样就很难说服业务负责人把未经真实验证的对话系统跑上线,甚至是灰度环境。我们在做一款语音机器人的业务时,就遇到了类似的场景。这时另外一种解决办法可以缓解这个问题,学界一般称为 Wizard of Oz(WOz),一种非常有名的对话数据收集方法 [16]。WOz 简单来说是通过让人模拟机器的行为,来服务真实用户,收集真实的用户语料。在对话系统开发中,一般也是采用迭代开发,不同模块的完成时间并不一样,不同模块的研发成熟度也不一样,为了尽快推出一个原型,开发者可以选择将某些模块 mock 掉。但这里的 mock 并不是敏捷开发的 mock,而是用业务专家(wizard)在系统运行时代替这个模块,根据这个模块的输入,wizard 给出模块合理化的输出。值得注意的是,wizard 在模仿模块的行为时不能超出这个模块的设计边界,即不能用他自己的先验知识做超出模块能力范围的行为,否则会导致产生的对话并不符合对话系统的真实场景,拉低数据的可用性 [17]。WOz 的方法能让系统在成熟之前就接触到真实用户,快速收集真实世界的数据分布,降低了上线后泛化的风险。同时也让企业提前检验对话流程的有效性,及时对问题做出调整。
Trade-off of control and automation
从大量语料中自动学习人机对话交互模式,是企业开发对话系统的理想方式。在从事了很多个对话项目之后,我们发现企业对任务型机器人有很多现实的需求,而目前基于数据的方法都很难满足。除了数据获取的困难,data-driven 方法遇到的另一个很大的问题是:自动化和控制权的权衡(control and automation)[18]。自动化的 DM 方法往往是以牺牲对 VUI 逻辑的控制为代价的。我们知道机器学习对非专家来说是一个黑盒,虽然知道模型归纳的依据来自于语料,但如何用语料来解释模型的行为、如何通过变更语料来快速修改模型的结果、如何精确的对模型逻辑进行设计,这些能方便控制对话行为的权限是企业开发对话项目时必需的,而基于统计的方法并不能完全支持。
开发者经常要用到的控制权主要包括:快速修改 VUI 逻辑和 debugging/monitoring。
快速增删改 VUI 的逻辑是 hand-crafted 方法非常大的优势。对话的任务描述也是迭代优化的,项目上线后,早期的 VUI 很可能已经不适合业务的发展需要了,企业需要一个手段能快速对 VUI 逻辑进行修改。如果是基于数据的方法,修改的代价可能是巨大的,需要重新收集新的对话语料,并 review 和清洗所有的老数据。就算完成了数据的更新也可能是不够的,数据一旦变化对原有对话策略的影响也需要评估。如果企业只是想对 VUI 做微小的改动,实施这么一套更新流程的成本就太高了。而 hand-crafted 方法就简单的多,只需要修改涉及到的 VUI 即可。从优化机器人策略的角度来看,对话开发者的项目经验,和算法学习到的对话模式,都可以优化对话效果,但这两者的职责并不在一个维度上 [19]。由于统计算法仅支持在封闭域中学习,所以它只能在一个有限的候选集中优化它的策略。而对话开发者可以根据需要做更多的修改,例如增加一个新的对话分支、新增或删除一个系统响应、甚至为某些需求做定制的处理。
在实际场景中,只靠 data-driven 而脱离人工设计并不现实,两个方法的差异性是可以相互补充的,很多研究者开始探索用 hybrid 方式来开发对话管理。例如上文提到的 Hybrid Code Network [2] 可以让开发者在 end-to-end RNN 架构中添加领域相关的逻辑,如图 6 论文中的示例,梯形的部分代表领域相关的模块,其中 entity tracking 是开发者集成的领域代码,用于将文本和实体处理成上下文特征(context features),以及响应掩码(action mask)。Context features 由开发者根据实体和自定义逻辑自行设计,action mask 表示某些场景下不可能出现的系统响应。运行时需要 action mask 是由于模型的输出空间是所有 actions 候选集,但在一些实际条件的限制下,有些 actions 在当前 timestamp 是不可能出现的。例如信用卡还款场景,在得到用户信息和账号之前,应禁止进行还款操作。所以为了 100% 规避模型预测的风险,需要 mask 来控制模型的输出。这个方法也曾经被 Walliams 用在了 POMDP 上,为 action selection function 设定限定域,是一种对有风险的 actions 减枝(pruned)操作,可以让 POMDP 优化过程更快、预测结果更可靠 [20]。


图 6 Hybrid Code Network 系统架构图 [2]
以上我们讨论了很多关于如何设计对话模型和策略的话题,但此时系统仅是一个开环(open-loop),缺少项目优化所必需的系统诊断方法 [21]。对话策略设计仅是对话系统功能的一部分,项目开发时 DS developers 需要对 VUI 进行调试,项目部署前需要对用例进行回归,项目上线后需要对指标进行监控,出现异常时需要对错误进行定位,这些都是企业经常用到的控制权。系统诊断的重点是通过会话分析发现对话策略的不合理之处,为项目优化提供数据上的支撑。现代对话系统平台一般有两种诊断的功能,一个是 debugging,一个是 monitoring。Debugging 指的是,为了验证对话交互是否符合业务目标和项目预期,开发者所需要的对话调试功能。通常包括,实时查看一通对话的状态,定位当前交互节点的位置,查看历史 VUI 日志等等。例如图 7 百度 Kitt.ai 支持对会话进行单步调试,方便开发者分析每个 timestamp 的状态。又如图 8 IBM Watson 对话平台,开发者可以点击模拟器中某一轮对话(红框标记的位置),相应的节点即时在左侧的流程图中显示出来。再如图 9 SAP Conversation AI,开发者可通过模拟器查看一通会话的操作日志,方便问题定位。
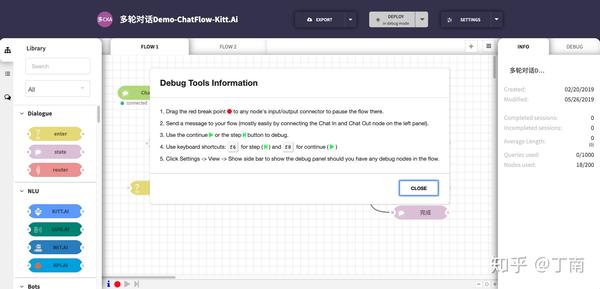

图 7 百度 Kitt.ai 对话调试
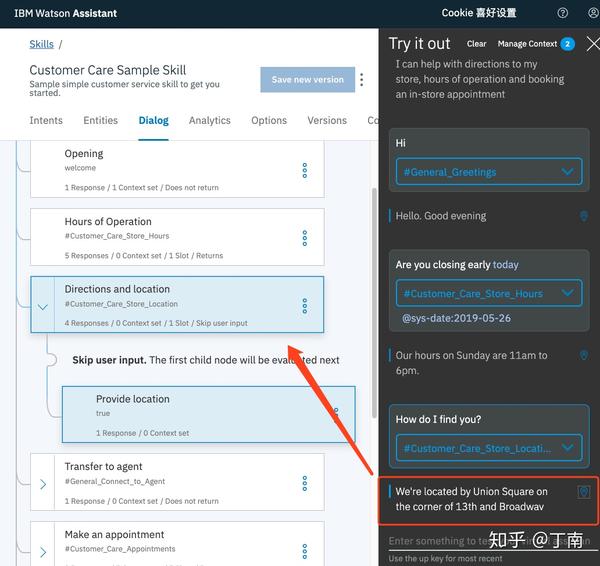

图 8 IBM Watson 对话节点定位
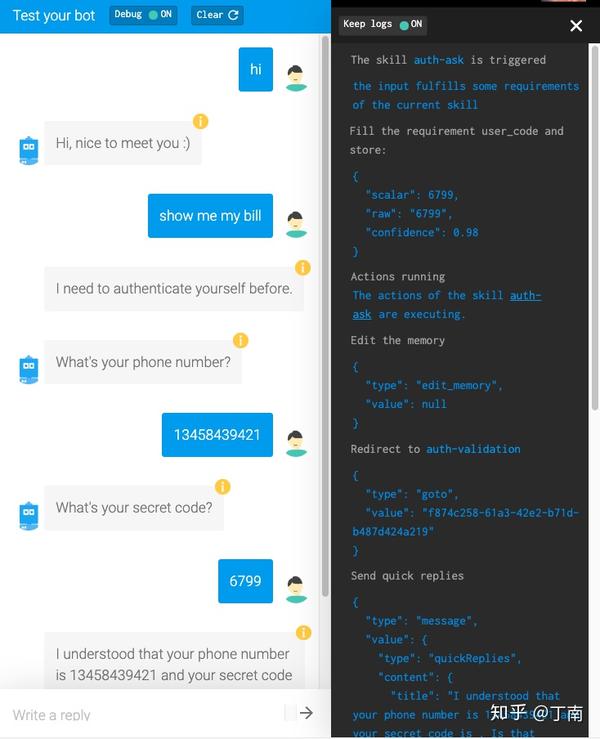

图 9 SAP Conversational AI 对话日志
Monitoring 指的是项目上线后的监控和分析,其意义是通过监控数据指标或 A_B testing,验证对话策略的有效性,持续优化机器人效果。对话策略包括机器人不同的话术、不同的 fallback 方式、不同的 VUI 逻辑、甚至是不同的目标人群等等。Monitor 一般使用业务 KPI 的 summary reports 来监控项目的整体运行情况,以及利用会话日志可视化来宏观调整 VUI 逻辑。对话系统最常用的 KPI 是任务完成率,但任务是否完成并不是那么容易定义。最直接的做法是监控业务数据指标来验证对话目标,例如图 10 Intercom 的每一个对话任务都可以自定义任务指标,对话任务发布后根据这个指标就可以评估对话任务的有效性。Intercom 也支持为同一类客户划分设定不同的对话策略,通过 A_B testing 选择更优的策略。虽然用业务指标来优化策略非常有效,但有时候业务数据并不是即时产生的,甚至有时候对话系统都拿不到敏感的业务数据。这种场景就需要一个间接指标来假设业务目标是否达成,比如通过监控某些节点的完成率来模拟对话目标。可视化整体日志也可以辅助项目分析,例如图 11 Google DialogFlow 的 session flow 功能可将日志的对话流占比可视化出来,方便分析 VUI 有效性。
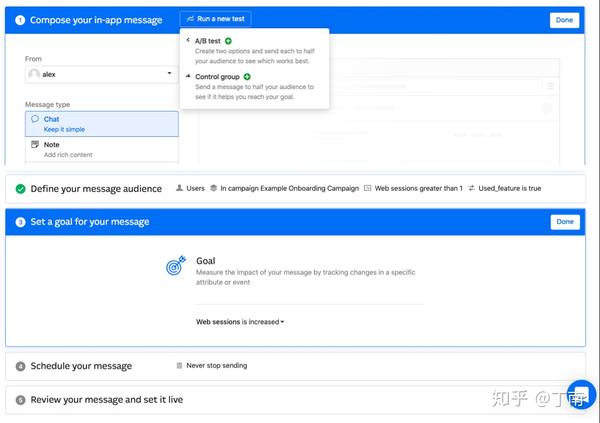

图 10 Intercom 中一个对话任务的监控指标和 A/B testing
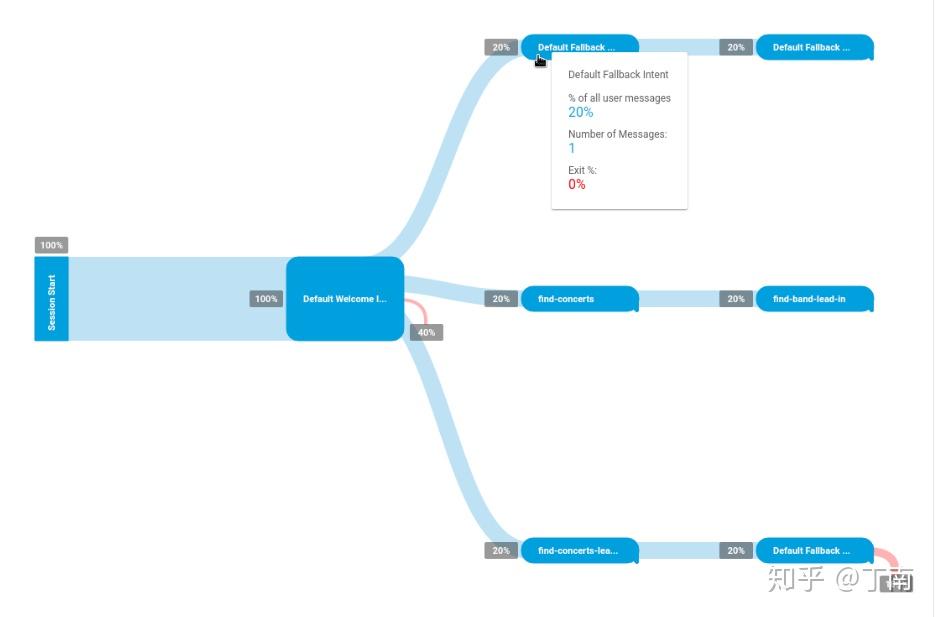

图 11 DialogFlow session flow
从上面的论述和实例,我们可以发现最适合 debugging 和 monitoring 目前还是 hand-crafted 方法,它的 VUI design tools 可以非常方便地发现对话运行时的问题,方便修改对话逻辑,方便 VUI 的快速迭代。不过有的 data-driven 方法也在积极探索这方面的应用,例如图 12 Rasa 框架支持可视化训练数据,可以把对话语料映射成流程图,这样让 DS developers 从宏观角度上审阅目前的数据。这里也可以用类似 Abella 提出的对话轨迹分析方法(dialog trajectory analysis)[21],将运行时产生的实际日志可视化出来,这样训练集和真实日志都以流程图的形式表现出来,之前提到的基于 VUI tools 的功能就可以复用起来了。


图 12 Rasa X 可视化 Story
上面大段的讨论虽然看起来是在聊 data-driven 在实际项目中的不足,其实想强调的是商业对话系统中有很多不可忽略的工作。不论用何种方法,如果这些问题没能有效解决,都将是机器人上线后的重要瓶颈。当然,data-driven dialog manager 的潮流是不可逆的,每年都有大量的研究成果和产品值得我们学习。下一篇 我们来聊一聊不同优秀公司给出的多轮对话解决方案。
Reference
[1] J. Schatzmann, B. Thomson, K. Weilhammer, and H. Ye S. Young. Agenda- based user simulation for bootstrapping a POMDP dialogue system. In Proc. HLT/NAACL, Rochester, NY, 2007.
[2] J. D. Williams, K. Asadi, and G. Zweig. Hybrid code networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning. arXiv preprint arXiv:1702.03274, 2017.
[3] C.E. Brodley, and M.A. Friedl, Identifying mislabeled training data, Journal of Artificial Intelligence Research, Vol. 11, pp. 131‑67, 1999.
[4] D. Guan and W. Yuan, A Survey of Mislabeled Training Data Detection Techniques for Pattern Classification, IETE Technical Review, vol. 30, issue-6, pp. 524-530, Nov-Dec 2013.
[5] Huang, P., He, X., Gao, J., Deng, L., Acero, A., and Heck, L. 2013. Learning deep structured semantic models for web search using clickthrough data. In CIKM.
[6] Aniket Kittur, Jeffrey V Nickerson, Michael Bernstein, Elizabeth Gerber, Aaron Shaw, John Zimmerman, Matt Lease, and John Horton. 2013. The future of crowd work. In CSCW 2013. 1301–1318.
[7] Kittur, A., Smus, B., Khamkar, S., and Kraut, R.E. Crowdforge: Crowdsourcing complex work. Proceedings of the 24th annual ACM symposium on User interface software and technology, (2011), 43– 52.
[8] Della Penn, N. and Reid, M.D. Crowd & Prejudice: An Impossibility Theorem for Crowd Labelling without a Gold Standard. Collective Intelligence, 2012.
[10] J. D. Williams and L. Liden. Demonstration of interactive teaching for end-to-end dialog control with hybrid code networks. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 82–85, 2017.
[11] Tom Bocklisch, Joey Faulkner, Nick Pawlowski, and Alan Nichol. Rasa: Open source language understanding and dialogue management. arXiv preprint arXiv:1712.05181, 2017.
[12] Wieland Eckert, Esther Levin, and Roberto Pieraccini. User modeling for spoken dialogue system evaluation. In Automatic Speech Recognition and Understanding, 1997. Proceedings., 1997 IEEE Workshop on, pages 80–87. IEEE, 1997.
[13] Jost Schatzmann and Steve Young. The hidden agenda user simulation model. IEEE transactions on audio, speech, and language processing, 17(4):733–747, 2009.
[14] Layla El Asri, Jing He, and Kaheer Suleman. A sequence-to-sequence model for user simulation in spoken dialogue systems. arXiv:1607.00070, 2016.
[15] Li, X., Lipton, Z. C., Dhingra, B., Li, L., Gao, J., and Chen, Y.-N. (2016d). A User Simulator for Task-Completion Dialogues. ArXiv e-prints.
[16] Dahlb¨ack, N., J¨onsson, A., Ahrenberg, L.: Wizard of Oz studies - why and how. Knowledge-Based Systems 6(4), 258–266 1993.
[17] Michael McTear, Zoraida Callejas, and David Griol. 2016. The Conversational Interface. Springer
[18] Paek T, Pieraccini R, 2008. Automating spoken dialogue management design using machine learning: an industry perspective. Speech Commun 50:716–729. doi:10.1016/j.specom.2008. 03.010
[19] G. Putois, R. Laroche, and P. Bretier, Online reinforcement learning for spoken dialogue systems: The story of a commercial deployment success, in Proceedings of SIGDIAL, Tokyo (Japan), September 2010.
[20] JD Williams. The best of both worlds: Unifying conventional dialog systems and POMDPs. In Proc Intl Conf on Speech and Language Processing (IC- SLP), Brisbane, Australia, 2008.
[21] A. Abella, J.H. Wright, and A.L. Gorin. 2004. Dialog trajectory analysis. In IEEE International Confe- rence on Acoustics, Speech and Signal Processing (ICASSP), volume 1, pages 441–444, May.