SentiLARE:带有语言知识的情感感知预训练模型

论文: SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge
作者: Pei Ke∗, Haozhe Ji∗
论文地址: https://arxiv.org/pdf/1911.02493.pdf
代码: https://github.com/thu-coai/SentiLARE
指示函数: 在集合论中,指示函数是定义在某集合X上的函数,表示其中有哪些元素属于某一子集A。 indicator function or a characteristic function, 如果元素A在集合X中,那么指示函数的值为1,否则为0。
1. 遗憾的是截至目前,预训练的代码尚未放出。
2. 考虑语言知识,这里是词性的单词级别的情感倾向,更有助于理解句子整体的情感。
表17表明文本相似度计算方面, SentiLARE比GloVe的词向量略好,但是GloVe的词向量相似度计算效率更高。
3. SentiLARE预训练模型叫做标签感知Mask语言模型,分2个阶段Early Fusion早期融合和Late Supervision后期监督,它们的主要区别是早期融合阶段是把句子情感也作为输入,后期监督是把句子情感作为预测标签,监督训练句子情感。
4. 早期融合和后期监督的目的是让模型能够理解句子级情感和单词级情感和词性之间的内在联系。
5. 每个词的注意力权重是对词的出现的频率的倒数乘以句子和单词的余弦相似度之后进行softmax,如公式1。
6. 早期融合比后期监督的损失函数不同在于是否加入了句子的情感和句子的情感标签作为损失。
7. 早期融合和后期监督的数据比是8:2,并且Mask正负向情感的单词的概率由通用的15%上升到30%。
8. 模型对句子级情感分类,aspect词语抽取,aspect词语情感分类, aspect类别检测, aspect类别情感
9. 表10对比,结合对于RoBERTa作为预训练模型的初始化参数效果比BERT和Albert效果要好。
10. 模型不仅对情感分析任务有提升,还对故事结局预测,文本内容和语义文本相似性等任务性能有提升。
- 一、简介
- 二、相关工作
- 三、模型
- ---- 3.1 任务定义和模型概述
- ---- 3.2 语言知识获取
- ---- 3.3 预训练任务
- ------------ 3.3.1 早期融合
- ------------ 3.3.2 后期监督
- 四、实验
- ---- 4.1 预训练数据集和实施
- ---- 4.2 微调设置
- ---- 4.3 基线
- 一般预训练模型:
- ---- 4.4 sentence-level的情感分类
- ---- 4.5 aspect-level的情感分析
- ---- 4.6 消融测试
- ---- 4.7 知识获取分析
- ---- 4.8 知识集成分析
- ---- 4.9 泛化能力的分析
- 五、结论
- 附录
- ---- A 实验细节
- ------------ A.1 超参数设置
- ------------ A.2 验证集的结果
- ------------ A.3 运行环境
- ---- B 案例研究
- ---- C 知识获取中的文本相似度分析
一、简介
大多数现有的预训练语言表示模型都忽略了考虑文本的语言知识,这可以促进NLP任务中的语言理解。 为了在情感分析中受益于下游任务,我们提出了一种称为SentiLARE的新型语言表示模型,该模型将词级语言知识(包括词性label和情感倾向(从SentiWordNet推理得出))引入了预训练的模型中。 我们首先提出一种上下文感知的情感注意力机制,通过查询SentiWordNet来获取每个单词及其词性label的情感倾向。 然后,我们设计了一个新的预训练任务,称为标签感知的mask语言模型,以构造知识感知的语言表示。 实验表明,SentiLARE在各种情感分析任务上均获得了最新的性能。
最近,诸如GPT(Radford等人,2018,2019),ELMo(Peters等人,2018)和BERT(Devlin等人,2019)等预训练语言表示模型在NLP任务中取得了可喜的成果, 包括情感分析(Xu等,2019,2020; Yin等,2020)。 这些模型通过精心设计的预训练任务从大型语料库中获取上下文信息。 文献通常报道预训练模型可以用作有效的特征提取器,并在各种下游任务上实现最新的性能(Wang等人,2019a)。
尽管预训练模型取得了巨大的成功,但现有的预训练任务(如masked语言模型和下一句预测)(Devlin等人,2019)却忽略了考虑语言知识。 这些知识对于某些NLP任务特别是情感分析非常重要。 例如,现有工作表明,语言知识包括词性标签(Qian等人,2015; Huang等人,2017)和单词级情感(Qian等人,2017)是和长篇文章的情感相仅的。 我们认为,经过丰富了单词的语言知识的预训练模型,将有助于理解整个文本的情感,从而在情感分析上获得更好的表现。
构建知识感知的预训练语言表示模型存在两个主要挑战,知识感知可以促进情感分析中的下游任务:1)跨不同上下文的知识获取。现有的大多数工作都采用静态情感词典作为语言资源(Qian等人,2017;Chen等人,2019),并为每个词在不同上下文中配置了固定的情感倾向。但是,由于词性和词义的多样性,同一词在不同的上下文中可能扮演不同的情感字符。 2)将知识集成到预训练的模型中。由于引入的word-level语言知识只能反映每个词在局部所扮演的情感,因此重要的是将知识深度集成到预训练的模型中,以构建sentence-level语言表示形式,来自局部信息的句子从而可以得出整体的整体情感。如何建立sentence-level语言表达和单词级语言知识之间的联系。
在本文中,我们提出了一种称为SentiLARE的新型预训练语言表示模型来应对这些挑战。首先,为了获得每个单词的语言知识,我们用单词的词性标签标记该单词,并通过上下文感知的情感注意力机制在SentiWordNet中获得情感倾向(Baccianella等, 2010)。然后,为了将语言知识集成到预训练的模型中,我们设计了一种新颖的预训练任务,称为label感知masking语言模型。该任务涉及两个子任务:1)在给定sentence-level的情感label的情况下,预测单词,词性tag和masked位置的情感倾向; 2)同时预测sentence-level的label,被masked的单词及其语言知识,包括词性tag和情感倾向。由于情感label预先集成为输入嵌入,因此我们将第一个子任务称为早期融合,而在第二个子任务中,将label用作对输出层模型的后期监督。这两个子任务将在sentence-level表示和word-level语言知识之间建立联系,这可以在情感分析中受益于下游任务。我们的贡献包括三个方面:
• 我们研究了将语言知识集成到预训练语言表示模型中的有效性,并揭示了通过预训练任务注入这样的知识可以有益于情感分析中的各种下游任务。
• 我们提出了一种称为SentiLARE的新型预训练语言表示模型。 该模型使用SentiWordNet得出每个单词的上下文感知情感倾向,并采用名为label aware masked 语言模型的预训练任务来构建情感感知的语言表示形式。
•我们对sentence-level和aspect-level的情感分析(包括提取和分类)进行了广泛的实验。 结果表明,SentiLARE在各种情感分析任务上均获得了最新的性能。
二、相关工作
通用的预训练语言模型
最近预训练语言表示模型包括ELMo(Peters等人,2018),GPT(Radford等人,2018,2019)和BERT(Devlin等人) .,2019)变得普遍。 这些模型使用LSTM(Hochreiter和Schmidhuber,1997)或Transformer(Vaswani等人,2017)作为编码器来获取上下文语言表示,并探索各种预训练任务,包括masking语言模型和下一句预测(Devlin等人。 ,2019)。
由于BERT在各种NLP任务上都取得了巨大成功,因此提出了BERT的许多变体,主要包括以下四个方面:
1)知识增强:ERNIE-Tsinghua(Zhang et al.,2019)/ KnowBERT( Peters等人,2019)明确向BERT引入了知识图/知识库,而ERNIE-Baidu(Sun等人,2019b)在预训练期间设计了特定实体的masking策略。
2)可迁移性:TransBERT(Li等,2019)对具有迁移任务的预训练BERT进行有监督的后训练,以更好地初始化目标任务。
3)超参数: RoBERTa(Liu et al.,2019)测量关键超参数对改善训练不足的BERT的影响。
4)预训练任务:SpanBERT(Joshi等,2020)随机masked连续跨度而不是单个token,而XLNet(Yang等,2019)设计了结合重建和自回归语言模型的训练目标。
情感分析的预训练模型
另一项工作旨在通过对任务数据进行后训练来建立特定任务的预训练模型(Gururangan等,2020)。 对于情感分析,BERT-PT(Xu et al.,2019)对语料库进行后训练,该语料库属于下游任务的同一领域,以受益于aspect-level的情感分析。 DomBERT(Xu et al.,2020)在预训练阶段增加了来自相关领域的训练样本,以增强目标领域的方面层面情感分析的性能。 SentiBERT(Yin et al.,2020)在BERT表示的基础上设计了一种两级注意力机制来捕获短语级组合语义。
与现有的用于情感分析的预训练模型相比,我们的工作将来自SentiWordNet的与情感相关的语言知识(Baccianella等,2010)集成到预训练模型中,以构建知识感知的语言表示形式,从而可以广泛地受益情感分析中的下游任务。
用于情感分析的语言知识
诸如词性和word-level的情感倾向之类的语言知识通常用作情感分析的外部特征。 词性可以简化文本的句法结构(Socher等,2013)。 也可以将其作为标签嵌入并集成到RNN的所有层中(Qian等,2015)。 Huang et al(2017)表明,词性可以帮助学习对情感有利的表述。
word-level情感倾向主要来自情感词典(Hu and Liu,2004; Wilson等,2005)。 Guerini等人(2013年)通过对SentiWordNet中所有单词的情感得分进行加权来获得先验的情感倾向(Esuli和Sebastiani,2006; Baccianella等人,2010)。 Teng等人(2016)提出了一种基于上下文感知词典的加权模型,该模型对情感词的先验情感分数进行加权,以得出整个句子的情感label。 Qian等人(2017)通过语言正则化方法对LSTM的训练目标中的情感,否定词和强度词的语言作用进行了建模。
三、模型
3.1 任务定义和模型概述
我们的任务定义如下:给定长度为n的文本序列 X=\left(x_{1}, x_{2}, \cdots, x_{n}\right) ,我们的目标是获取整个序列的表示 H=\left(h_{1}, h_{2}, \cdots, h_{n}\right)^{\top} \in \mathbb{R}^{n \times d} ,代表捕获上下文信息和语言知识,其中d表示表示向量的维度。
图1显示了我们模型的概述,该模型包括两步:1)获取每个单词的词性tag和情感倾向; 2)通过标签感知的mask语言模型进行预训练,该模型包含两个预训练子任务,即早期融合和后期监督。 与现有的BERT-style预训练模型相比,我们的模型通过其语言知识(包括词性tag和情感倾向)丰富了输入序列,并利用标签感知的masked语言模型来捕获sentence-level语言表示与word-level语言知识之间的关系。
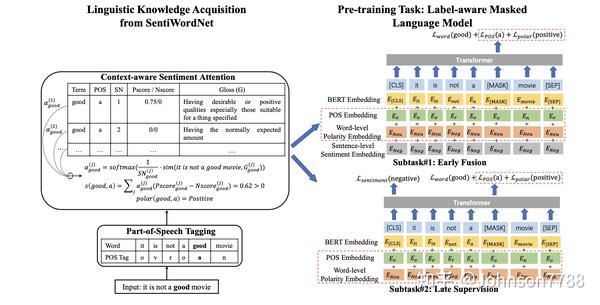

图1:SentiLARE概述. 该模型首先用词性tag标注每个单词,然后使用单词和tag来匹配SentiWordNet中的相应含义。 每个单词的情感倾向是通过使用上下文感知的情感注意力对匹配的含义加权来获得的。 在预训练期间,该模型基于标签感知的mask语言模型进行训练,包括早期融合和后期监督。 红色虚线框表示在输入嵌入或预训练损失函数中使用了语言知识。
3.2 语言知识获取
该模块获取每个单词的词性标签和情感倾向。 该模块的输入是文本序列 X=\left(x_{1}, x_{2}, \cdots, x_{n}\right) ,其中xi(1≤i≤n)表示单词表中的单词。 首先,我们的模型通过Stanford Log-Linear词性Tagger获取每个单词xi的词性标签posi。 为简单起见,我们仅考虑五个POS标记,包括动词(v),名词(n),形容词(a),副词(r)和其他(o)。
然后,我们从SentiWordNet获取每对单词(xi,posi)的word-level情感倾向Polari。 在SentiWordNet中,我们可以为该对(xi,posi)找到m种不同的含义,每个含义都包含一个含义编号,一个正/负分数, 一个连贯性gloss,例如 \left(S N_{i}^{(j)}, \text { Pscore }_{i}^{(j)}, N \text { score }_{i}^{(j)}, G_{i}^{(j)}\right) 1<=j<=m,其中SN表示不同含义的编号,P score/N score是SentiWordNet分配的正/负得分,而G表示每种含义的定义。 受SentiWordNet(Guerini等,2013)推理word-level先验倾向的现有工作,和无监督的词义消歧(Basile等人,2014)的启发,我们提出了一种上下文感知注意力机制,该机制同时考虑了词义等级, 以及上下文光连贯性来确定每种词义的注意力权重:
\alpha_{i}^{(j)}=\operatorname{softmax}\left(\frac{1}{S N_{i}^{(j)}} \cdot \operatorname{sim}\left(X, G_{i}^{(j)}\right)\right) \tag{1}
其中 \frac{1}{S N_{i}^{(j)}} 近似于词义频率的影响,因为较小的词义序号表示该词义在自然语言中的使用频率更高(Guerini等人,2013),而 sim(X,Gi^{(j)}) 表示上下文和每种词义的连贯度,通常用作无监督词义消歧的重要特征(Basile等人,2014)。 为了计算X和G(j)之间的相似度,我们使用Sentence-BERT(SBERT)(Reimers和Gurevych,2019)对它们进行编码,从而实现了语义文本相似度任务的最新性能,并获得了向量之间的余弦相似度:
\operatorname{sim}\left(X, G_{i}^{(j)}\right)=\cos \left(\operatorname{SBERT}(X), \operatorname{SBERT}\left(G_{i}^{(j)}\right)\right) \tag{2}
一旦获得了每种词义的注意力权重,我们就可以通过简单地加权所有词义的得分来计算每对情感指数 (x_i,pos_i) :
s\left(x_{i}, p o s_{i}\right)=\sum_{j=1}^{m} \alpha_{i}^{(j)}\left(Pscore_{i}^{(j)}-Nscore_{i}^{(j)}\right) \tag{3}
最后,当 s(x_i,pos_i) 为正/负/零时,可以为该对 (x_i,pos_i) 的word-level情感倾向分配正/负/中性。 请注意,如果我们无法在SentiWordNet中找到 (x_i,pos_i) 的任何意义,则Polari被分配为Neutral。
3.3 预训练任务
给定知识增强的文本序列 X_{k}=\left\{\left(x_{i}, \text { pos }_{i}, \text { polar }_{i}\right)_{i=1}^{n}\right\} ,预训练任务的目的是构建知识感知的表示向量 H =(h1,...,hn)^T ,可以促进情感分析中的下游任务。 我们设计了一个新的有监督的预训练任务,称为标签感知masked语言模型(LA-MLM),该模型将sentence-level情感标签 l 引入了预训练阶段,以捕获sentence-level语言表示与单个单词之间的依赖性。它包含两个单独的子任务:早期融合和后期监督。
3.3.1 早期融合
早期融合的目标是恢复以语句级label为条件的mask序列,如图1所示。假设 \hat{X}_{k} 表示带有一些mask label的知识增强文本序列,我们可以使用 \hat{X}_{k} 的输入和sentence-level的情感label l 获得表示向量:
\left(h_{c l s}^{E F}, h_{1}^{E F}, \ldots, h_{n}^{E F}, h_{s e p}^{E F}\right)=\operatorname{Transformer}\left(\hat{X}_{k}, l\right) \tag{4}
其中 h_{c l s}^{E F} 和 h_{sep}^{E F} 是特殊token [CLS]和[SEP]的隐藏状态。 \hat{X}_{k} 的输入嵌入包含BERT(Devlin et al.,2019)中使用的嵌入,词性(POS)嵌入和word-level倾向嵌入。 另外,将sentence-level情感label l 的嵌入提前添加到输入的嵌入中。 需要该模型来分别预测masking位置处的单词,词性tag和word-level倾向,因此损失函数的设计如下:
\begin{aligned} \mathcal{L}_{E F} &=-\sum_{t=1}^{n} m_{t} \cdot\left[\log P\left(x_{t} \mid \hat{X}_{k}, l\right)+\right.\\ &\left.\log P\left(\operatorname{pos}_{t} \mid \hat{X}_{k}, l\right)+\log P\left(\text { polar }_{t} \mid \hat{X}_{k}, l\right)\right] \end{aligned} \tag{5}
其中mt是指标函数,等于1表明xt是masked。 基于隐藏状态hEF计算预测概率 P(xt|\hat{X}k,l) , P(pos_t|\hat{X}k,l) 和 P(polar_t|\hat{X}k,l) 。此子任务明确地对单词和单词的语言知识施加了全局情感label的影响,从而增强了我们的模型探索它们之间复杂联系的能力。
3.3.2 后期监督
后期监督子任务旨在分别基于[CLS]和masked位置的隐藏状态来预测sentence-level的label和单词信息,如图1所示。 输入 \hat{X}_{k} 的向量可按以下方式获得:
\left(h_{c l s}^{L S}, h_{1}^{L S}, \ldots, h_{n}^{L S}, h_{s e p}^{L S}\right)=\text { Transformer }\left(\hat{X}_{k}\right) \tag{6}
在该子任务中,情感label l 用作后期监督信号。 因此,同时预测sentence-level的情感label,单词和单词的语言知识的损失函数如下所示:
\begin{aligned} \mathcal{L}_{L S}=&-\log P\left(l \mid \hat{X}_{k}\right)-\sum_{t=1}^{n} m_{t} \cdot\left[\log P\left(x_{t} \mid \hat{X}_{k}\right)+\right.\\ &\left.\log P\left(\operatorname{pos}_{t} \mid \hat{X}_{k}\right)+\log P\left(\text { polar }_{t} \mid \hat{X}_{k}\right)\right] \end{aligned} \tag{7}
其中基于隐藏状态 h_{c l s}^{LS} 计算句子级别的分类概率 P(l|\hat{X}k) 。 此子任务使我们的模型能够捕获[CLS]处的句子级表示形式与Masked位置处的单word-level语言知识之间的隐式关系。
由于这两个子任务是分开的,因此我们根据经验将为后期监督子任务提供的预训练数据的比例设置为20%,将早期融合子任务的比例设置为80%。 至于masking策略,我们将masked具有正/负情感倾向的单词的概率从BERT设置中的15%增加到30%,因为它们更可能影响整个文本的情感。
四、实验
4.1 预训练数据集和实施
我们采用Yelp数据集挑战赛2019作为我们的预训练数据集。 该数据集包含6,685,900条带有5个类别评论级别情感label的评论。 每个评论平均包含127.8个字。
由于我们的方法可以适应所有BERT-style的预训练模型,因此本文以RoBERTa(Liu等人,2019)为基础框架构建了Transformer块,并讨论了对其他预训练模型的泛化能力例如BERT(Devlin et al.,2019)。由于计算能力有限,因此将Transformer模块的超参数设置为与RoBERTa-Base相同。考虑到从头开始训练的高昂开销,我们利用了预训练的RoBERTa4的参数来初始化我们的模型。我们还跟随RoBERTa使用大小为50,265的字节对编码单词表(Radford et al.,2019)。预训练阶段的最大序列长度为128,而批次大小为400。我们以Adam(Kingma and Ba,2015)为优化器,并将学习率设置为5e-5。预热比为0.1。 SentiLARE在2019年Yelp数据集挑战赛上使用1个epoch的标签感知的mask语言模型的预训练,在4个NVIDIA RTX 2080 Ti GPU上花费了大约20个小时。
4.2 微调设置
在我们的实验中,我们将SentiLARE微调至下游任务,包括句子级情感分类,aspect级情感分析和常规文本匹配任务。 我们在现有工作中采用了微调设置(Devlin等,2019; Xu等,2019),并在表1中显示了每个任务的输入格式和输出隐藏状态。请注意,输入嵌入在所有下游任务仅包含BERT嵌入,词性嵌入和word-level倾向嵌入。 附录中报告了不同数据集上微调的超参数。


4.3 基线
我们将SentiLARE与一般预训练模型,特定任务的预训练模型和不进行预训练的特定任务模型进行了比较。
一般预训练模型:
我们采用BERT(Devlin等人,2019),XLNet(Yang等人,2019)和RoBERTa(Liu等人,2019)作为一般预训练基线。 这些模型可在各种NLP任务上实现最先进的性能。
特定任务的预训练模型:
我们使用BERT-PT(Xu等人,2019),TransBERT(Li等人,2019)和SentiBERT(Yin等人,2020)作为特定任务的预训练模型基线。 由于TransBERT最初并不是为处理情感分析任务而设计的,因此我们选择在Yelp Dataset Challenge 2019上进行评论级别的情感分类作为迁移任务,并选择情感分析中的下游任务作为目标任务。
没有预训练的特定任务模型:
我们还选择了一些没有预训练的特定任务基准来处理相应的任务,包括SCSNN(Chen等,2019),DRNN(Wang,2018),ML(Sachan) 等人(2019)等人的sentence-level情感分类,DE-CNN(Xu等人,2018)aspect的词语提取,CDT(Sun等人,2019a)aspect的词语情感分类,TAN(Movahedi等人(2019年)进行aspect类别检测,使用ASCapsules(Wang等人,2019b)进行aspect类别情感分类。
我们根据原始论文提供的代码和模型参数评估了所有预训练的基线。 为了公平地比较,所有预训练的模型都设置为base版本,该base版本具有相似数量的参数(大约110M)。 实验结果以5次运行的平均值表示。 至于没有预训练的特定任务基准,我们使用在参考文献的相应基准上的结果。
4.4 sentence-level的情感分类
我们首先在sentence-level的情感分类基准上评估了我们的模型,包括斯坦福情感树库(SST)(Socher等,2013),电影评论(MR)(Pang and Lee,2005), IMDB(Maas等,2011)和Yelp-2/5(Zhang等,2015),它们是在不同规模广泛使用的数据集。 这些数据集的详细统计信息显示在表2中,其中包含训练/验证/测试集的数量,平均长度和类数。 由于MR,IMDB和Yelp-2/5没有验证集,因此我们从训练集中随机抽取了子集作为验证集,并使用相同的数据划分评估了所有经过训练的模型。
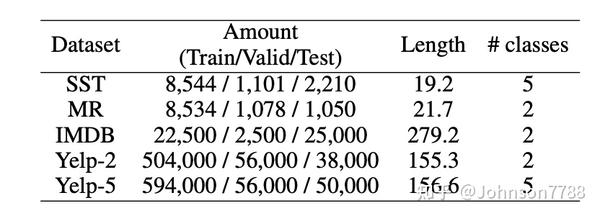

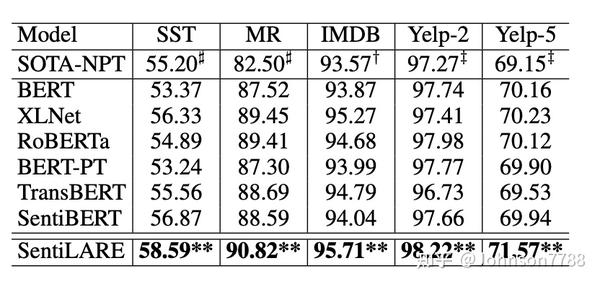
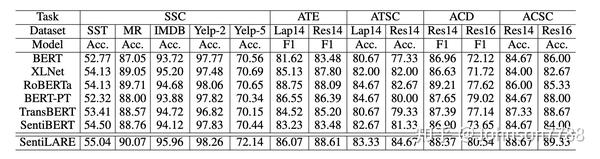
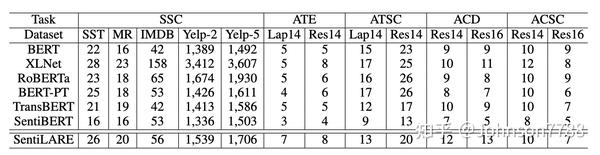
结果显示在表3中。我们可以观察到SentiLARE在sentence-level情感分类数据集上的表现优于基线,从而表明我们的知识感知表示在情感理解中的有效性。 与最原始的RoBERTa相比,SentiLARE显着提高了所有数据集的性能。 这表明对于情感分析任务,可以通过精心设计的预训练任务来使用语言知识来增强最新的预训练模型。

4.5 aspect-level的情感分析
aspect-level的情感分析包括aspect术语的提取,aspect术语的情感分类,aspect类别检测和aspect类别的情感分类。 对于aspect术语的基本任务,我们选择针对laptop(Lap14)和restaurant(Res14)域(Pontiki等人,2014)的SemEval2014 Task 4作为基准,而对于aspect类别的任务,我们在restaurant域使用SemEval2014 Task 4( Res14)和SemEval2016 Task 5 for restaurant domain(Res16)(Pontiki et al.,2016)。 这些数据集的统计数据报告在表4中。我们遵循现有工作(Xu et al.,2019),从训练集中留下150个样本进行验证。 由于带有冲突情感label的样本数量很少,因此我们采用与现有工作相同的设置(Tang等人,2016; Xu等人,2019),并在aspect术语/类别情感分类任务中丢弃。


我们在表5中提供了aspect-level的情感分析的结果。我们可以看到,在所有四个任务上SentiLARE的性能均优于基线,并且大多数改进幅度都非常可观。 有趣的是,除了aspect的情感分类外,我们的模型在aspect术语提取和aspect类别检测方面也表现出色。 由于aspect词主要是名词,因此词性标签可以为提取任务提供其他知识。另外,可以通过相邻的情感词来检测aspect术语。 这可以解释为什么我们的知识感知表示可以帮助提取(检测)aspect术语(类别)。
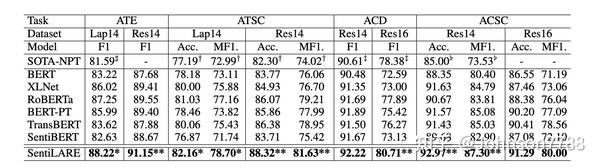

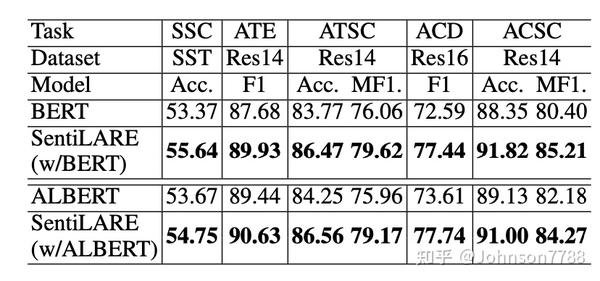
表5:关于四个aspect-level的情感分析任务的F1,准确性(Acc。)和macro-F1(MF1。),包括aspect术语提取(ATE),aspect术语情感分类(ATSC),aspect类别检测(ACD)和aspect类别情感分类(ACSC)(%)。 SOTA-NPT是指无需预训练即可从基线获得的最新性能,其中标记为#,†,‡和b的结果是从Xu等复制的( 2018),Sun等(2019a),Movahedi等(2019)和Wang等(2019b)。 -表示结果未在参考文献中报告。 表示我们的模型明显优于相应数据集上最佳的预训练基线(t-test, p-value< 0.05),而*表示p值<0.01。
4.6 消融测试
为研究语言知识和label感知的mask语言模型的效果,我们进行了消融测试并将结果显示在表6中。由于两个子任务是分开的,因此-EF的设置/-LS表示将预训练数据全部馈入后期监督/早期融合子任务,-EF-LS表示将预训练任务从标签感知的masking语言模型更改为最原始的masking语言模型,而输入的嵌入仍然包括词性和word-level倾向嵌入。 -POS/-POL设置意味着我们分别除去了输入嵌入中以及两个子任务的监视信号中的词性/word-level情感倾向。 -POS-POL表示语言知识已被完全删除。
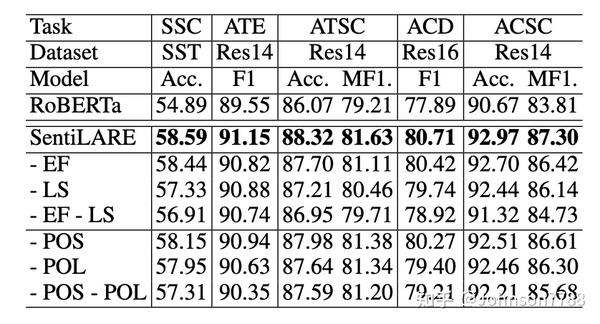

表6中的结果表明,预训练任务和语言知识都比RoBERTa有所改善。 与早期融合相比,后期监督子任务在分类任务中起着更重要的作用,而分类任务取决于输入序列的整体表示,例如SSC,ATSC,ACD和ACSC。 直观上,后期监督子任务可以通过同时预测sentence-level的情感label和单词知识来在[CLS]学习有意义的全局表示。 因此,它为这些分类任务的性能做出了更大的贡献。
至于语言知识的影响,在去除单word-level情感倾向的设置中,SentiLARE的性能会进一步下降。 这意味着word-level倾向可以帮助预训练模型更多地在分类任务中驱动全局情感,并在提取任务中使用相邻的aspect给出信息。
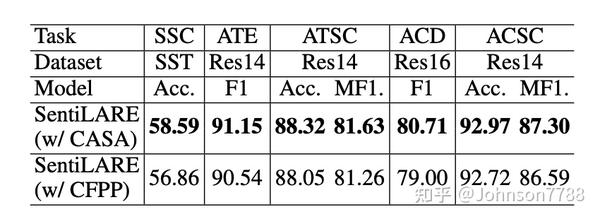
4.7 知识获取分析
为了调查我们提出的上下文感知知识获取方法是否可以帮助构建知识感知语言表示,我们将第3.2节中描述的上下文感知情感注意力与无上下文先验倾向获取算法进行了比较 (Guerini et al.,2013)。 该算法通过使用词义编号的倒数对每个词义的情感得分进行加权,从而简单地获取带有词性标签的每个单词的固定情感倾向,而与上下文的变化无关。 为了比较这两种知识获取方法,SentiLARE的所有其他部分保持不变。
表7中的结果表明,我们的上下文感知方法在所有任务上均表现更好。 这表明我们的上下文感知注意力机制可以帮助SentiLARE,对不同上下文中单词的情感进行建模,从而带来更好的知识增强的语言表示。

4.8 知识集成分析
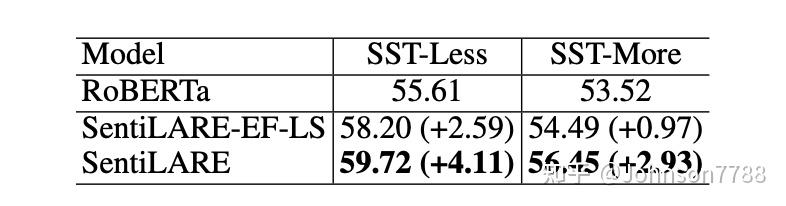
为了进一步证明标签感知的masked语言模型的重要性,将语言知识深度集成到了预训练的模型中,我们根据情感词的数量(包括以及由语言知识决定的肯定词和否定词)将SST的测试集分为两个子集。 由于SST的测试集句子中平均有6.48个情感词,因此我们将测试集分为两个子集:SST-Less包含不超过7个情感词的句子,SST-More包含其他句子。 凭直觉和推测,具有更多情感词的句子可能包含更复杂的情感表达。我们比较了三种模型:不使用语言知识的RoBERTa,如4.6中所述通过语言知识简单地增加输入嵌入的SentiLARE-EF-LS和通过预训练任务深度集成语言知识的SentiLARE。
表8中的结果表明,通过简单地使用语言知识来增强输入特征,SentiLARE-EF-LS在SSTLess上已经明显优于RoBERTa。 但是,在SST-More上,SentiLARE-EF-LS仅比RoBERTa略有改善。 对于我们的模型,SentiLARE可以始终胜过RoBERTa和SentiLARE-EF-LS,并且SST-More上SentiLARE和SentiLARE-EF-LS之间的余量更加明显。 这表明我们的预训练任务可以帮助将word-level语言知识所反映的局部情感信息集成到全局语言表示中,并有助于理解复杂的情感表达。

4.9 泛化能力的分析
对其他预训练模型的泛化:
为了研究引入的语言知识和提议的预训练任务是否可以提高RoBERTa以外的其他预训练模型的性能,我们选择了BERT(Devlin等人,2019)和ALBERT(Lan等人,2020)作为评估的基本框架。 实验设置与基于RoBERTa的SentiLARE相同。
表9中的结果表明,基于BERT / ALBERT的SentiLARE在所有任务的数据集上均胜过普通BERT / ALBERT,这表明我们提出的方法可以适应不同的BERT-style的预训练模型,从而在情感分析中受益。

泛化为其他NLP任务:
由于情感是改善文本匹配任务的共同特征(Cai等,2017; Li et al.,2019),我们选择了三种文本匹配任务来探索我们的情感感知表示是否也可以为这些任务带来好处,包括故事结局预测,文本内容和语义文本相似性。 我们分别在SCT(Mostafazadeh等人,2016),SICK(Marelli等人,2014)和STSb(Cer等人,2017)的数据集上针对这三个任务评估了RoBERTa和SentiLARE。 这些数据集的统计数据记录在表10中。我们按照现有工作(Li等,2019)对SCT数据集进行了预处理,并直接采用了SICK和STSb数据集的正式版本。
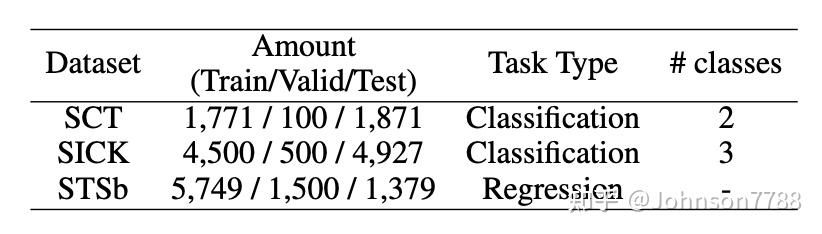

表11中的结果表明SentiLARE可以增强RoBERTa在这些文本匹配任务上的性能。 这表明与情感相关的语言知识可以成功地集成到预训练语言表示模型中,不仅可以受益于情感分析任务,而且可以泛化到其他与情感相关的NLP任务。 我们将在将来的工作中探索将模型泛化到更多NLP任务中。


五、结论
我们提出了一种用于情感分析的新型预训练模型SentiLARE,该模型引入了来自SentiWordNet的语言知识,通过上下文感知情感注意力,并采用了标签感知的masked语言模型,通过训练任务将知识深度集成到BERT-style模型中。 实验表明,在各种情感分析任务上,SentiLARE的性能均优于最新的语言表示模型,从而促进了对情感的理解。
附录
A 实验细节
A.1 超参数设置
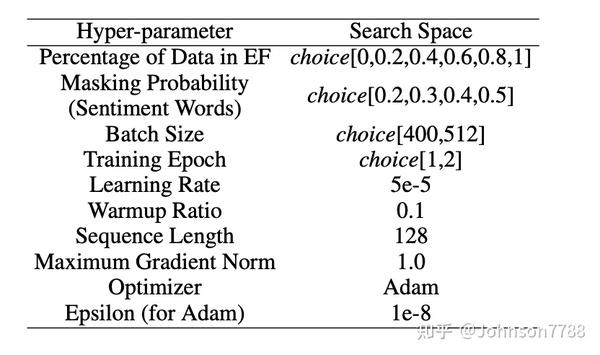
我们在表12的预训练期间提供了超参数搜索空间。网格搜索用于选择超参数,选择标准为当我们在SST上微调预训练模型时,对验证集进行分类的准确性。

我们还在情感分析数据集的微调过程中提供了超参数的详细设置,包括表13中的超参数搜索空间和表14中的最佳分配。请注意,我们使用HuggingFace的Transformers来实现我们的模型,因此我们报告的所有超参数内容与HuggingFace的transformer的代码一致。 在微调期间,我们利用手动搜索来选择最佳的超参数。 每个数据集的超参数搜索试验的数量为20。我们使用准确率作为我们选择所有情感分析任务的标准,除了aspect术语提取和aspect类别检测。 对于这两个任务,采用F1作为选择标准。




A.2 验证集的结果
除了主要论文中报告的每个数据集测试集的性能外,我们还在表15中的提供了sentence-level和aspect-level情感分析的验证集性能。 。如附录A.1所述,使用准确率和F1来选择最佳的超参数,因此我们在这些指标上报告了所有预训练模型的验证集性能。

A.3 运行环境
表16中报告了在不同情感分析数据集上进行微调的运行环境。我们在4个NVIDIA RTX 2080 Ti GPU上测试了所有预训练的模型。

B 案例研究
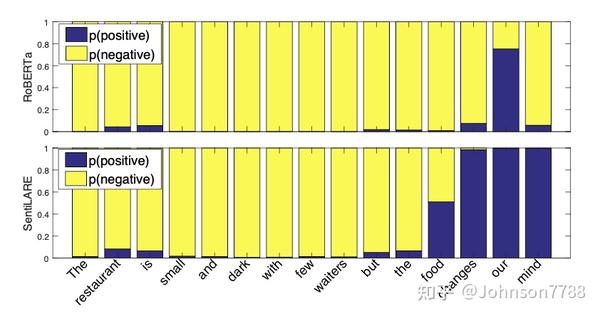
为了直观地表明SentiLARE可以将语言知识集成到经过预训练的模型中以促进情感分析,我们提供了一个案例,并可视化了图2中每个位置被截断的所有前缀子序列的分类概率。 例如,通过RoBERTa/SentiLARE通过输入“[CLS]The restaurant is small [SEP]”获得的[CLS]的隐藏状态, 来预测small位置的类别概率。 RoBERTa和SentiLARE都在Yelp-2数据集上进行了微调。
图2:在Yelp-2上微调的RoBERTa和SentiLARE分类概率的可视化。 条形图指示RoBERTa和SentiLARE的输出分布以及每个位置的前缀子序列的输入。
与RoBERTa相比,我们的模型在word-level语言知识的基础上得到了增强,可以成功捕获该句子中单词变化引起的情感变化,从而确定正确的sentence-level情感label。
C 知识获取中的文本相似度分析
由于Sentence-BERT计算上下文和修饰语之间的文本相似度开销很高,因此我们将其与另一种轻量级的文本相似度算法(Basile等人,2014年)进行了比较,该算法通过平均它们的组成词嵌入向量来计算句子的表达向量。我们使用300维GloVe6作为单词向量以获得文本相似度。
表17中的结果表明,Sentence-BERT在所有任务上的表现都更好。 尽管如此,静态单词向量在语言知识获取aspect的计算效率更高,并且性能下降可以接受。