跨媒体检索:概念、方法、评测与挑战(一):基础知识

An Overview of Cross-media Retrieval: Concepts, Methodologies, Benchmarks and Challenges
来源:Peng Y, Huang X, Zhao Y. An Overview of Cross-media Retrieval: Concepts, Methodologies, Benchmarks and Challenges[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2017, PP(99):1-1.
本章主要是整体上介绍论文中概念、方法和挑战,翻译理解有偏差,具体请参考上述论文。
概念:
跨媒体检索的目标是计算不同媒体数据间的相似度,对于给定的查询样例,检索出与查询样例相关的不同媒体数据。关键挑战在于不同媒体的表示形式不一致,难以进行直接的相似性度量,即“媒体鸿沟”问题。两种主要的跨媒体检索方法:共同空间学习方法和跨媒体相似性度量方法。
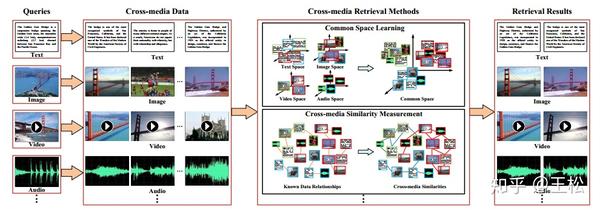

共同空间学习方法通过为不同媒体数据学习一个统一的共同空间,使得跨媒体相似性可以在该空间中直接度量,主要包括传统的统计关联分析方法、基于深度学习的方法、基于图规约的方法、度量学习方法、排序学习方法、字典学习方法、跨媒体哈希方法等。跨媒体相似性度量方法并不学习共同空间,而是直接计算跨媒体的相似性,主要包括基于图的方法和近邻分析方法等。此外还有一些其他的跨媒体检索方法,如相关反馈分析方法、多模态主题模型方法等。


目前,跨媒体检索中多媒体类型主要包括图像、文本、语音、视频和3D图形。现在大多数跨媒体检索方法主要是限制在用图像和文本,还有少量语音和视频等其他两种类型的结合。一方面是包含这五种媒体类型的数据库几乎没有(作者提出了一种这样的数据库XMediaNet),另一方面不同媒体类型的异构形式,存在着“语义鸿沟”。
异构鸿沟问题是跨媒体检索面临的一个核心挑战:不同媒体的数据具有不同的特征表示形式,它们的相似性难以直接度量。为解决上述问题,一种直观的方法是跨媒体统一表征,即把不同媒体数据从各自独立的表示空间映射到一个第三方的公共空间中,使得彼此可以度量相似性。近年来,随着深度学习的快速发展与广泛应用,基于深度学习的统一表征方法已经成为了研究的热点与主流。
方法:
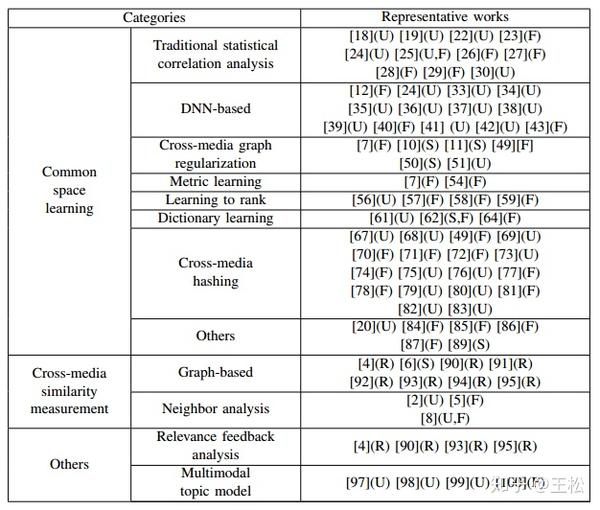
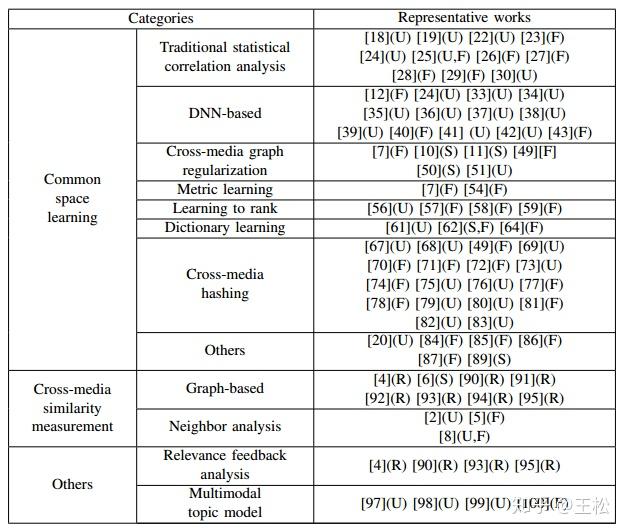
- U:无监督方法,
- S:半监督方法,
- F:完全监督的方法,
- R:用于涉及相关性反馈的方法,并且不能通过监督设置轻松分类。
A. Common Space Learning(共同空间学习方法):
- Traditional Statistical Correlation Analysis Methods(传统统计关联分析方法)
- DNN-based Methods(基于深度学习方法)
- Cross-media Graph Regularization Methods(基于图规约方法)
- Metric Learning Methods(度量学习方法)
- Learning to Rank Methods(排序学习方法)
- Dictionary Learning Methods(字典学习方法)
- Cross-media Hashing Methods(跨媒体哈希方法)
- Other Methods
B. Cross-media Similarity Measurement(跨媒体相似性度量方法):
- Graph-based Methods(基于图的方法)
- Neighbor Analysis Methods(近邻分析方法)
C. Other Methods for Cross-media Retrieval:
- Relevance Feedback Analysis(相关反馈方法)
- Multimodal Topic Model(多模态主题模型方法)
挑战:
1. 数据库构建和基准标准化
存在问题:数据量小、类型数量少、数据存在语义重叠和混乱。
2. 精度和效率提升
- 精度需要被提升。基于图的跨媒体像实行度量方法可使用更多的上下文信息来进行有效的图形构建,如链接关系。单媒体特征的区别力也很重要,最先经的方法通常采用地位特征(如128-d BoVW histogram features for image and 10-d LDA features for text),如果CNN特征用于图像,检索精度可以提升。
- 效率作为评估和应用可以一个人重要的因素。现有的数据库小,且限制在媒体类型数目上,效率的提升缺少关注。XMediaNet的出现,可使人们关注效率提升和促进跨媒体检索实际应用的发展。
3. 深度神经网络应用
DNN用来处理不同媒体类型的相关性,因此值得去尝试利用DNN来消除“语义鸿沟”。现有方法主要将单媒体特征作为输入,因此它们很大程度上取决于特征的有效性。设计端到端的结构(用原始的媒体实力作为输入,如原始的图像、文本等)用于跨媒体检索,再用DNN获得检索结果。某些特定的媒体类型的特殊网络(用于对象区域检测的R-CNN)也可以纳入跨媒体检索 的统一框架中。
现有方法被设计主要只使用两种媒体类型(如 图像和文本)。研究者们可专注于共同分析两种以上的媒体类型,这将使DNN在跨媒体检索中的应用更加灵活和有效。
4. 利用上下文关联信息
跨媒体检索的主要挑战是不同媒体类型的异构形式。跨媒体相关性通常和上下文信息有关,很多现有方法(CCA,CFA,JRL)只将共存关系和语义类别标签作为训练信息,但忽略丰富的上下文信息。
5. 跨媒体检索的实际应用
effectiveness & efficiency
