
译文 Learning a Single Convolutional Super-Resolution Network for Multiple Degradations


单个卷积网络处理多重退化模型的超分辨率重建SRMD
\(Kai Zhang^{1;2;3}\) , \(Wangmeng Zuo^1\) , \(Lei Zhang^2\)
\(^{1}\) School of Computer Science and Technology, Harbin Institute of Technology, Harbin, China
\(^{2}\) Dept. of Computing, The Hong Kong Polytechnic University, Hong Kong, China
\(^{3}\) DAMO Academy, Alibaba Group
cskaizhang@gmail.com, wmzuo@hit.edu.cn, cslzhang@comp.polyu.edu.hk
摘要
近年来,单幅图像超分辨率(SISR)中的深度卷积神经网络(CNN)取得了前所未有的成功。然而,现有的基于CNN的SISR方法主要假设低分辨率(LR)图像是从高分辨率(HR)图像bicubic降采样得到的,因此当真正的退化不遵循该假设时,不可避免地会导致性能较差。此外,他们缺乏学习单一模型的可扩展性,无法处理多重退化。为了解决这些问题,我们提出了一个具有维度伸缩策略的通用框架,使得单个卷积超分辨率网络能够将SISR退化过程的两个关键因素(即模糊内核和噪声水平)作为输入。因此,超分辨器可以处理多个甚至是空间变化的退化,这显着提高了实用性。在合成的和真实的LR图像的大量实验结果表明,所提出的卷积超分辨率网络不仅可以在多个退化模型上产生有利结果,而且在计算上是高效的,为实际的SISR应用提供了高效且可扩展的解决方案。
1 引言
单幅图像超分辨率(SISR)旨在通过恢复低分辨率(LR)输入得到高分辨率(HR)图像。 作为一个经典的问题,SISR在计算机视觉领域仍然是一个积极而富有挑战性的研究课题,因为它的不健全性和高实用价值[2]。 在典型的SISR框架中,将LR图像y建模为以下退化过程的输出:
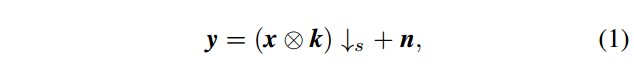

其中x⊗k表示模糊核k与潜在HR图像x之间的卷积,箭头s表示图像以比例因子s下采样,n通常是具有标准偏差(噪声水平)σ的加性高斯白噪声(AWGN)。
SISR方法可以大致分为三类,即基于插值的方法,基于模型的优化方法和区分性学习方法。基于插值的方法,如最近邻,双线性和双三次插值法简单高效,但性能非常有限。通过利用强大的图像先验(例如非局部自相似性[11,32],稀疏先验[52]和降噪先验[4,13,57]),基于模型的优化方法可以灵活地重建相对高质量HR图像,但它们通常涉及耗时的优化过程。虽然卷积神经网络(CNN)降噪器与基于模型的优化的集成可以在一定程度上提高效率,但它仍然存在基于模型的优化方法的典型缺点,例如,它不是端到端的优化方法,最终的学习方式,并涉及手工设计的参数[57]。作为一种选择,歧视性学习方法由于其有效性和效率方面的良好SISR性能而引起了相当大的关注。值得注意的是,近年来使用CNN进行SISR的戏剧性高涨。
在本文中,我们重点研究SISR的CNN方法,以便利用CNN的优点,例如并行计算的快速性,端到端训练的高精度以及训练和设计网络的巨大进步[16 ,18,21,28]。尽管几种基于区别CNN的SISR模型报告了令人印象深刻的结果,但它们存在一个共同的缺点:它们的模型专用于单一简化退化(例如双三次退化),缺乏可扩展性以通过使用单个模型处理多种退化。由于SISR的实际退化要复杂得多[40,51],当假设的退化偏离真正的退化时,学习的CNN模型的性能可能会严重恶化,使得它们在实际情况下效率较低。有人指出,模糊核对SISR方法的成功起着至关重要的作用,模糊核的失配将大大恶化最终的SISR结果[12]。然而,在如何设计CNN来解决这个关键问题方面做了很少的工作。
鉴于上述事实,提出以下问题是很自然的,这些问题是我们论文的重点:(i)我们可以学习单一模型来有效处理多个甚至是空间变化的退化问题吗? (ii)是否可以使用综合数据来训练具有较高实用性的模型?这项工作旨在首先尝试回答这两个问题。
为了回答第一个问题,我们在最大后验(MAP)框架下重新审视和分析了一般的基于模型的SISR方法。然后我们认为可以通过将LR输入,模糊核和噪声水平作为CNN的输入来解决这个问题,但是它们的维数不匹配使得设计单个卷积超分辨网络变得困难。鉴于此,我们引入了维度拉伸策略,其有助于网络处理关于模糊内核和噪声的多个甚至空间变化的劣化。据我们所知,没有试图通过训练单个CNN模型来考虑SISR的模糊核和噪声。
对于第二个问题,我们将展示使用合成数据学习一个实用的超级解析器是可能的。为此,对具有不同模糊核和噪声级组合的各种劣化进行采样以覆盖劣化空间。在实际情况下,即使退化更复杂(例如,噪声不是AWGN),我们可以选择最适合的退化模型而不是双三次退化,以产生更好的结果。事实证明,通过选择适当的退化模型,学习的SISR模型可以在真实的LR图像上产生令人信服的令人信服的结果。应该指出,我们不使用专门的网络架构,而是使用[9,41]中的普通CNN。
本文的主要贡献总结如下:
•我们为SISR提出了一个简单而有效且可扩展的深度CNN框架。所提出的模型超越了广泛使用的双三次退化假设,适用于多个甚至是空间变化的退化,从而为实际应用开发实用的基于CNN的超解析器迈出实质性的一步。
•我们提出了一种新颖的维度拉伸策略来解决LR输入图像,模糊内核和噪声水平之间的维度失配问题。虽然这个策略是针对SISR提出的,但它是一般的,可以扩展到其他任务,如去模糊。
•我们表明,从合成训练数据中学习的拟议卷积超分辨率网络不仅可以在合成LR图像上针对最先进的SISR方法产生有竞争力的结果,而且还会在真实LR图像上产生视觉上可信的结果。
2 相关工作
第一个使用CNN解决SISR的工作可以追溯到[8],其中提出了三层超分辨率网络(SRCNN)。在扩展工作[9]中,作者研究了深度对超分辨率的影响,并且凭经验证明,深度模型训练的困难阻碍了CNN超分辨器的性能改进。为了克服训练难度,Kim等人[24]提出了一种具有残差学习策略的非常深的超分辨率(VDSR)方法。有趣的是,他们表明VDSR可以处理多种尺度的超分辨率。 Zhang等人通过分析CNN和MAP推断之间的关系, [56]指出,CNN主要模拟先验信息,他们经验证明,单一模型可以处理多尺度超分辨率,图像去块和图像去噪。在获得良好性能的同时,上述方法以双三次插值LR图像为输入,不仅计算成本高,而且阻碍了接收场的有效扩展。
为了提高效率,一些研究人员采取直接操纵LR输入并在网络末端采用升级操作。 Shi等人[41]引入了一个有效的亚像素卷积层来将LR特征图提升为HR图像。董等人。 [10]在网络末端采用了一个去卷积层来执行上采样。 Lai等人[27]提出了一个拉普拉斯金字塔超分辨率网络(LapSRN),它将LR图像作为输入,并逐渐以粗到细的方式用转置卷积逐步预测子带残差。为了提高大比例因子的感知质量,Ledig等人[29]提出了一种基于生成对抗网络[16]的超分辨率(SRGAN)方法。在SRGAN的生成器网络中,使用两个亚像素卷积层来有效地将LR输入放大4倍。
尽管已经针对SISR提出了各种技术,但是上述基于CNN的方法针对广泛使用的设置的双三次退化,而忽略了它们在实际情况下的有限适用性。一个有趣的基于CNN的方法可以超越双三次退化,采用CNN降噪器通过基于模型的优化框架来解决SISR [4,34,57]。例如,[57]中提出的方法可以处理如[11]中广泛使用的高斯退化。然而,手动选择不同退化的超参数并不是一项简单的任务[39]。因此,理想的是学习一个单一的SISR模型,该模型可以处理多重退化,具有很高的实用性。
本文试图给出肯定的答案。由于空间有限,我们只能在这里讨论一些相关的作品。其他基于CNN的SISR方法可以在[6,22,23,30,37,42,44,45,46,53,58]中找到。
3.方法
3.1 退化模型
在解决SISR问题之前,重要的是要清楚地了解不局限于公式1的退化模型。 另一种实际的退化模型可以通过:
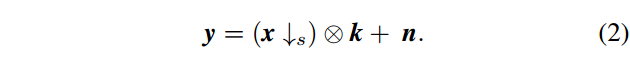

当公式中的箭头是双立方下采样器,公式(2)对应于先去模糊后使用了双三次退化的SISR问题。因此,它可以受益于现有的去模糊方法和基于双三次退化的SISR方法。由于空间有限,我们只考虑公式1中假定的更广泛的退化模型。 尽管如此,我们的方法是一般的,可以很容易地扩展到处理公式2。在下面,我们对模糊核k,噪声n和下采样器做一个简短的讨论。
模糊核 与图像去模糊不同,SISR的模糊内核设置通常很简单。最流行的选择是用标准差或内核宽度参数化的各向同性高斯模糊核[11,51]。在[38]中,也使用各向异性高斯模糊核。在实践中,可以进一步考虑用于去模糊任务的更复杂的模糊核模型,例如运动模糊[5]。经验和理论分析表明,精确模糊核的影响远大于复杂图像先验[12]。具体来说,当假定的内核比真实的内核更平滑时,恢复的图像被过度平滑。大多数SISR方法确实喜欢这种情况。另一方面,当假定的内核比真实内核更锐利时,将出现高频振铃伪像。
噪声 虽然分辨率低,但LR图像通常也有噪声。直接超分辨噪声输入而不消除噪声会放大不需要的噪声,导致视觉上不愉快的结果。要解决这个问题,直接的方法是首先执行去噪,然后再提高分辨率。然而,去噪预处理步骤倾向于丢失细节信息并且会恶化随后的超分辨率性能[43]。因此,共同执行降噪和超分辨率将是非常理想的。
下采样器 现有文献考虑了两种类型的下采样器,包括直接下采样器[11,17,36,51,55]和双三次下采样器[7,12,14,15,47,52]。在本文中,我们考虑双三次下采样器,因为当k是delta核并且噪声水平为零时,公式1变成了广泛使用的双三次退化模型。应该指出,不同于在一般退化模型中变化的模糊核和噪声,下采样器被假定为固定的。
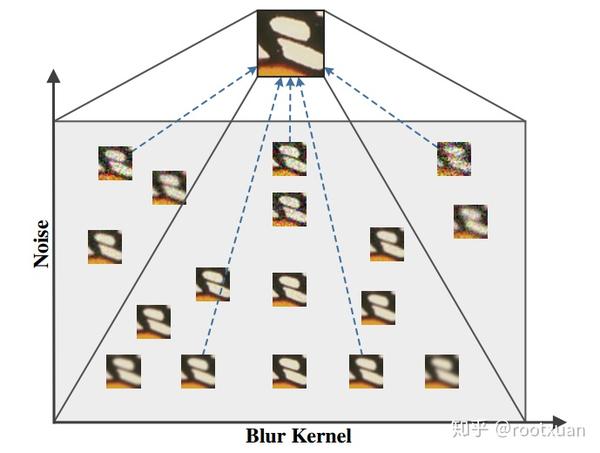

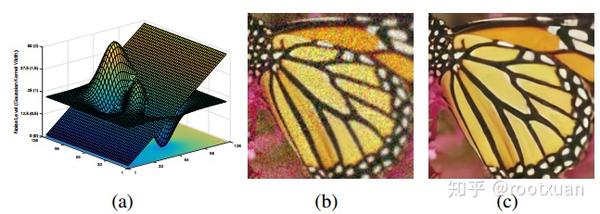
尽管模糊核和噪声已被认为是SISR成功的关键因素,并且已经提出了几种方法来考虑这两个因素,但在单个CNN框架中几乎没有办法同时考虑模糊核和噪声。这是一个具有挑战性的任务,因为关于模糊核和噪声的退化空间相当大(参见图1作为示例)。 Zhang等人完成了一项相关工作。 [57];尽管如此,它们的方法本质上是基于模型的优化方法,因此如前所述存在若干缺点。在另一项相关工作中,Riegler等人[38]将模糊核信息融合SISR模型。我们的方法在两个主要方面与[38]不同。首先,我们的方法考虑了更一般的退化模型。其次,我们的方法利用更有效的方法来参数化退化模型。
3.2 来自MAP框架的观点
虽然现有的基于CNN的SISR方法不一定是在传统MAP框架下派生的,但它们具有相同的目标。我们重新审视和分析SISR的一般MAP框架,旨在找到MAP原则和CNN工作机制之间的内在联系。因此,可以获得关于CNN架构设计的更多见解。由于SISR的病态性质,需要通过正规化来限制解决方案。在数学上,可以通过求解下面的MAP问题来估计LR图像y的对应的HR图像:
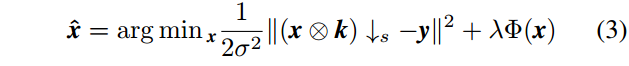

\( \frac{1}{2\mu^2}||(x \bigotimes k)\downarrow -y||^2 \) 是数据保真项, \(\Phi(x)\) 是正则化项(或先验项), \(\lambda\) 是权重系数。简单地说,公式(3)传达了两点:(i)估计的解决方案不仅应该符合退化过程,而且还具有期望的clean HR图像的性质; (ii) \(\widehat{x}\) 是LR图像y,模糊核k,噪声水平σ和折衷参数λ的函数。因此,(非盲)SISR的MAP解可以表示为
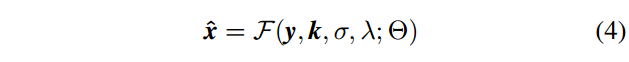

其中Θ表示MAP推断的参数。
通过将CNN作为公式4的一种有区别的学习解决方案,我们可以有以下见解。
•由于数据保真度项对应于退化过程,因此精确建模退化对SISR的成功起着关键作用。然而,现有的基于CNN的双三次退化SISR方法实际上旨在解决以下问题:
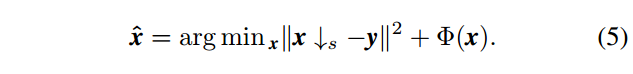

其实用性非常有限。
•要设计更实用的SISR模型,最好学习像公式4这样的映射函数。涵盖更广泛的退化。应该强调的是,由于λ可以被吸收到σ中,公式4可以被重新表述为:
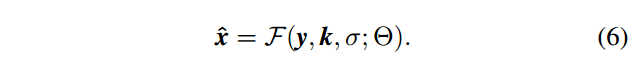

考虑到MAP框架(公式3)可以在同一图像之前进行通用图像超分辨率处理,在统一的CNN框架中共同执行去噪和SISR是直观的。此外,工作[56]表明MAP推断的参数主要模拟先验;因此,CNN有能力通过单一模式处理多种退化模型。
从MAP框架的角度,可以看到SISR的目标是学习映射函数 \(\widehat{x} = F(y, k, σ; Θ)\) 而不是 \(\widehat{x} = F(y;Θ)\) 。然而,通过CNN直接建模 \(\widehat{x} = F(y, k, σ; Θ)\) 并不是一件容易的事情。原因在于三个输入y,k和σ具有不同的维度。在下一小节中,我们将提出一个简单的维度伸缩策略来解决这个问题。
3.3 维度拉伸
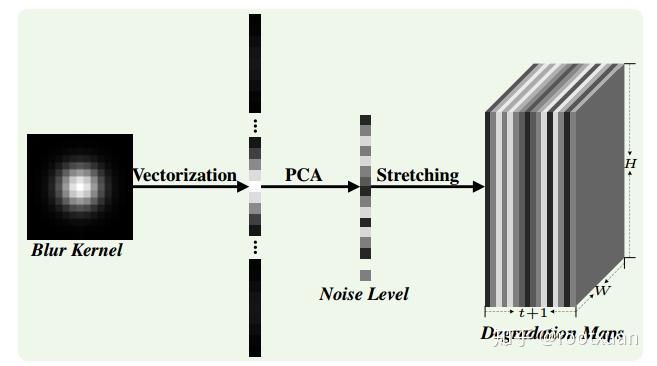
提出的维度拉伸策略在图2中被示意性地示出。假设输入包括大小为p×p的模糊核,噪声水平σ和尺寸为W×H×C的LR图像,其中C表示通道。模糊核首先被矢量化为一个大小为 \(p^2 × 1\) 的矢量,然后通过PCA(主成分分析)技术投影到t维线性空间。之后,由v表示的级联低维向量和噪声级被拉伸成尺寸为W × H ×(t + 1)的退化图M,其中第i个图的所有元素都是 \(v_i\) 。通过这样做,退化图随后可以与LR图像连接,使得CNN可以处理三个输入。考虑到退化图可能不均匀的事实,可以容易地利用这种简单的策略来处理空间变化的退化。

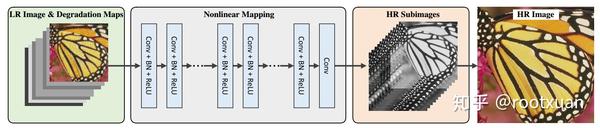
3.4 提出的网络
图3显示了用SRMD表示的多分辨率超分辨率网络,如图3所示。可以看出,SRMD的显着特点是它将级联的LR图像和退化图作为输入。为了展示维度伸展策略的有效性,我们采用普通的CNN而没有复杂的建筑工程。通常,为了超分辨比例因子为s的LR图像,SRMD首先将连接的LR图像和尺寸为W×H×(C + t + 1)的退化图作为输入。然后,类似于[24],应用级联的3×3卷积层来执行非线性映射。每一层由三种类型的操作组成,包括卷积(Conv),整流线性单元(ReLU)[26]和批量标准化(BN)[20]。具体而言,除了由单个“Conv”操作组成的最后的卷积层以外,每个卷积层都采用“Conv + BN + ReLU”。最后,子像素卷积层[41]之后是最后的卷积层,以将尺寸为 \(W × H × s^2C\) 的多个HR子图像转换为尺寸为sW × sH × C的单个HR图像。
对于所有比例因子2,3和4,卷积层的数量被设置为12,并且每层中的特征图的数量被设置为128.我们分别学习每个比例因子的模型。特别是,我们还通过去除第一卷积滤波器中噪声水平图的连接和新训练数据的微调来了解无噪声退化模型,即SRMDNF。

值得指出的是,由于以下原因,残差学习和双三次插值LR图像都不用于网络设计。首先,通过适度的网络深度和先进的CNN训练和设计,如ReLU [26],BN [20]和Adam [25],在没有残差学习策略的情况下很容易对网络进行训练。其次,由于退化涉及噪声,双三次插值的LR图像会加剧噪声的复杂性,反过来会增加训练的难度。
3.5 为什么不学盲模型?
为了提高CNN对SISR的实用性,似乎最直接的方法是通过不同退化学习具有综合训练数据的盲模型。然而,这样的盲目模型表现不如预期。首先,当模糊核模型很复杂时,例如运动模糊,性能严重恶化。这个现象可以用下面的例子来解释。给定HR图像,模糊核和相应的LR图像,将HR图像向左移动一个像素并将模糊内核向右移动一个像素将导致相同的LR图像。因此,LR图像可以对应于具有像素移位的不同HR图像。这反过来会加剧像素平均问题[29],通常导致过度平滑的结果。其次,没有特别设计的体系结构设计的盲模型泛化能力较差,在实际应用中表现较差。
相比之下,用于多重退化的非盲模型几乎不受像素平均问题的影响,并且具有更好的泛化能力。首先,退化图包含翘曲信息,因此可以使网络具有空间变换能力。为了清楚起见,可以将由模糊核和噪声水平引起的退化图作为空间变换器的输出来处理,如[21]中所述。其次,通过将模型与退化图一起锚定,非盲模型容易推广到看不见的退化,并且能够控制数据保真度术语和正则化术语之间的权衡。
4 实验
4.1 合成训练数据和网络训练
根据公式1合成LR图像之前,有必要定义模糊核和噪声水平范围,以及提供大规模clean HR图像集。
对于模糊核,我们遵循具有固定核宽度的各向同性高斯核模型,这在SISR应用中已被证明实际可行。具体来说,内核宽度范围设置为[0.2, 2],[0.2, 3]和[0.2, 4]分别对应比例因子2,3和4。我们用0.1的步幅对内核宽度进行采样。内核大小固定为15×15。为了进一步扩展退化空间,我们还考虑了一个更一般的内核假设,即各向异性高斯,其特征在于高斯概率密度函数N(0, Σ)具有零均值和变化的协方差矩阵Σ[38]。这样的高斯核的空间由Σ的特征向量的旋转角和相应特征值的缩放来确定。我们将旋转角度范围设置为[0, π]。对于特征值的缩放,对于比例因子2,3和4,其分别设置为0.5到6,8和10。
虽然我们在整篇论文中采用双三次下采样器,但直接采用直接降采样器训练模型非常简单。或者,我们还可以通过近似直接降采样器来包括退化。具体来说,给定直接下采样器 \(\downarrow^d\) 下的模糊核 \(k_d\) ,通过用数据驱动方法解决以下问题我们可以在双三次下采样器 \(\downarrow^b\) 下找到相应的模糊核 \(k_b\) :
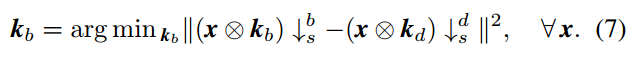

在本文中,我们还包括比例因子为3的退化模型 。
一旦模糊内核被定义好或者被学习,我们就可以对大量的内核进行统一的抽样并聚合它们来学习PCA投影矩阵。通过保留大约99.8%的能量,将核投影到维15的空间(即t = 15)。图4显示了比例因子3和一些PCA特征向量的一些典型模糊核的可视化。


对于噪声级别范围,我们将其设置为[0, 75]。因为所提出的方法在YCbCr色彩空间中对RGB信道而不是Y信道进行操作,所以我们收集包括400个BSD [33]图像,来自DIV2K数据集[1]的800个训练图像和WED数据集[31]的4744幅图像的大规模彩色图像用于训练。
然后,给出一幅HR图像,我们通过使用模糊核k对其进行模糊化来合成LR图像,并且以比例因子s对其bicubic降采样,随后添加具有噪声水平σ的AWGN。 LR patch大小设置为40×40,这意味着比例因子2,3和4的相应HR patch大小分别为80×80,120×120和160×160。
在训练阶段,每个epoch我们随机选择一个模糊核和一个噪声水平合成一个LR图像和裁剪N = 128×3000 LR / HR补丁对(以及退化图)。我们使用Adam [25]优化了以下损失函数:
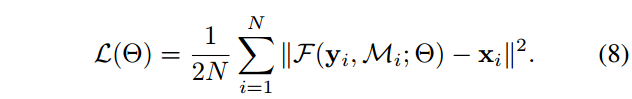

最小批量设置为128.当训练错误停止下降时,学习速率从 \(10^{-3}\) 开始并减小到 \(10^{-4}\) 。当训练误差在五个连续epoch中保持不变时,我们将每个批量归一化的参数合并到相邻的卷积滤波器中。然后,使用 \(10^{-5}\) 的小学习率再增加100个epoch来对模型进行微调。由于SRMDNF是通过微调SRMD获得的,因此其学习速率固定为 \(10^{-5}\) 并训练200个epochs。
我们使用MatConvNet软件包[48]和Nvidia Titan X Pascal GPU在Matlab(R2015b)环境中训练模型。对单个SRMD模型的训练可以在大约两天内完成。源代码可以在https://github.com/cszn/SRMD下载。
4.2 bicubic退化实验
如上所述,我们的目标是学习单一网络来处理多重退化,而不是仅处理双三次退化。然而,为了展示维度伸展策略的优点,所提出的方法还与专门为双三次退化而设计的其他基于CNN的方法进行了比较。
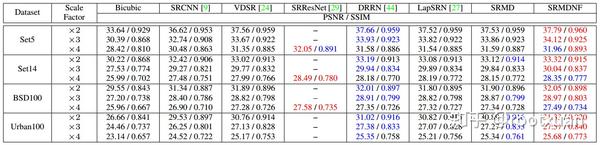
表1显示了最先进的基于CNN的SISR方法在四个广泛使用的数据集上的PSNR和SSIM [50]结果。正如人们所看到的,SRMD在小尺度因子下达到与VDSR相当的结果,并且在大尺度因子下胜过VDSR。特别是,SRMDNF实现了最好的整体定量结果。使用ImageNet数据集[26]来训练具有双三次退化的特定模型,SRResNet在比例因子4上执行比SRMDNF略好。为了与其他方法(例如VDSR)进一步比较,我们还训练了SRMDNF模型(用于比例因子3)在Y channel上操作291个训练图像。学习模型分别在Set5,Set14,BSD100和Urban100上分别达到33.97dB,29.96dB,28.95dB和27.42dB。因此,它仍然可以胜过其他竞争方式。可能的原因在于具有多个退化的SRMDNF在MAP框架中共享相同的先前,这促进了隐含的在先学习并因此有益于PSNR改进。这也可以解释为什么具有多种尺度的VDSR可以提高性能。
对于GPU运行时间,SRMD在比例因子2,3和4分别花费0.084,0.042和0.027秒来重建大小为1024x1024的HR图像。作为比较,VDSR上所有比例因子的运行时间为0.174秒。图5显示了不同方法的视觉效果。可以看出,我们提出的方法与其他方法相比具有非常有竞争力的性能。
4.3 一般退化模型的实验
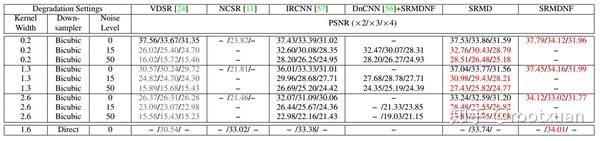
在本小节中,我们评估了所提方法在一般退化方面的性能。退化设置在表2中给出。我们只考虑各向同性高斯模糊内核以便于比较。为了进一步显示所提出的方法的可扩展性,还包括另一种广泛使用的退化[11],其涉及宽度为1.6的7×7高斯内核和具有比例因子3的直接下采样器。我们将所提出的方法与VDSR,两种基于模型的方法(即,NCSR [11]和IRCNN [57])以及级联去噪-SISR方法(即,DnCNN [56] + SRMDNF)进行比较。
表2给出了Set5中不同退化方法的定量结果,我们从中进行了如下观察和分析。首先,当假定的双三次退化偏离真实时,VDSR的性能严重恶化。其次,SRMD比NCSR和IRCNN产生更好的结果,并且胜过DnCNN + SRMDNF。特别是,SRMD在DnCNN + SRMDNF上的PSNR增益随着核宽度的增加而增加,这验证了联合去噪和超分辨率的优势。第三,通过设置适当的模糊内核,所提出的方法在用直接下采样器处理劣化方面提供了良好的性能。图6给出了视觉比较。可以看出,NCSR和IRCNN产生比VDSR更令人愉快的视觉效果,因为它们假定的退化与真实退化相匹配。但是,它们无法像SRMD和SRMDNF那样将边缘恢复得更加锐利。






4.4 空间变异性退化的实验
为了证明SRMD对于空间变异退化的有效性,我们合成了具有空间变化模糊核和噪声水平的LR图像。图7显示了提出的SRMD对空间变化退化的视觉结果。可以看出,所提出的SRMD对于恢复潜在的HR图像是有效的。请注意,模糊核被假定为各向同性高斯。


4.5 实际图像的实验
除了上述关于从具有已知模糊核的HR图像合成降采样并且已知噪声水平的AWGN破坏的LR图像的实验之外,我们还在真实LR图像上进行实验以证明所提出的SRMD的有效性。由于没有地面真实HR图像,我们只提供视觉比较。
如前所述,虽然我们也在训练中使用各向异性高斯核,但在测试中对大多数真实LR图像使用各向同性高斯是一般可行的。为了找到具有良好视觉质量的退化参数,我们使用网格搜索策略而不是采用任何模糊核或噪声水平估计方法。具体来说,内核宽度从0.1到2.4均匀采样,步幅为0.1,噪声水平为0到75,步幅为5.
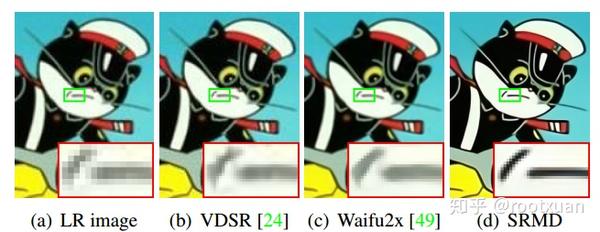
图8和图9分别说明了两个真实LR图像“Cat”和“Chip”上的SISR结果。 VDSR [24]是代表性的被用作比较的CNN方法之一。对于被压缩伪影破坏的图像“Cat”,Waifu2x [49]也用于比较。对于包含重复结构的图像“Chip”,也包括一个基于自相似性的方法SelfEx [19]用于比较。


从视觉结果可以观察到,与竞争方法相比,SRMD可以产生更多视觉上合理的HR图像。具体而言,从图8可以看出,VDSR的性能受到压缩伪像的严重影响。虽然Waifu2x可以成功删除压缩失真,但无法恢复锐利的边缘。相比之下,SRMD不仅可以去除不令人满意的伪影,还可以产生尖锐的边缘。从图9中我们可以看出,VDSR和SelfEx都倾向于产生过平滑的结果,而SRMD可以通过更好的强度和清晰图像的梯度统计恢复清晰的图像[35]。
5 结论
在本文中,我们提出了一个有效的超分辨率网络,通过单一模型处理多种退化的高可扩展性。与现有的基于CNN的SISR方法不同,所提出的超分辨器将LR图像及其退化图作为输入。具体而言,通过简化退化参数的维度拉伸(即,模糊内核和噪声水平)来获得退化图。合成LR图像的结果表明,所提出的超分辨率不仅可以产生双三次退化的最新技术结果,而且还可以有效地执行其他退化甚至空间变体退化。此外,实际LR图像的结果表明,所提出的方法可以重建视觉上合理的HR图像。总之,所提出的超分辨器为实际的基于CNN的SISR应用提供了可行的解决方案。
6 致谢
本文得到国家自然科学基金(批准号:61671182,61471146),香港研资局综合研究基金(香港理工大学152240 / 15E)和香港理工大学 - 阿里巴巴合作研究项目“监控图像和视频质量提升”的支持, 。我们非常感谢NVIDIA公司为我们提供用于本研究的Titan Xp GPU的支持。
References
[1] E. Agustsson and R. Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, volume 3, pages 126–135, July 2017. 6
[2] S. Baker and T. Kanade. Limits on super-resolution and how
to break them. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 24(9):1167–1183, 2002. 1
[3] M. Bevilacqua, A. Roumy, C. Guillemot, and M.-L. A.
Morel. Low-complexity single-image super-resolution based
on nonnegative neighbor embedding. In British Machine Vision Conference, 2012. 7
[4] S. A. Bigdeli, M. Jin, P. Favaro, and M. Zwicker. Deep meanshift priors for image restoration. In Advances in Neural Information Processing Systems, 2017. 1, 2
[5] G. Boracchi and A. Foi. Modeling the performance of image
restoration from motion blur. IEEE Transactions on Image
Processing, 21(8):3502–3517, Aug 2012. 3
[6] Y. Chen, W. Yu, and T. Pock. On learning optimized reaction diffusion processes for effective image restoration. In
IEEE Conference on Computer Vision and Pattern Recognition, pages 5261–5269, 2015. 2
[7] Z. Cui, H. Chang, S. Shan, B. Zhong, and X. Chen. Deep
network cascade for image super-resolution. In European
Conference on Computer Vision, pages 49–64, 2014. 3
[8] C. Dong, C. C. Loy, K. He, and X. Tang. Learning a deep
convolutional network for image super-resolution. In European Conference on Computer Vision, pages 184–199, 2014.
2
[9] C. Dong, C. C. Loy, K. He, and X. Tang. Image
super-resolution using deep convolutional networks. IEEE
Transactions on Pattern Analysis and Machine Intelligence,
38(2):295–307, 2016. 2, 7
[10] C. Dong, C. C. Loy, and X. Tang. Accelerating the superresolution convolutional neural network. In European Conference on Computer Vision, pages 391–407, 2016. 2
[11] W. Dong, L. Zhang, G. Shi, and X. Li. Nonlocally centralized sparse representation for image restoration. IEEE Transactions on Image Processing, 22(4):1620–1630, 2013. 1, 2,
3, 6, 7
[12] N. Efrat, D. Glasner, A. Apartsin, B. Nadler, and A. Levin.
Accurate blur models vs. image priors in single image superresolution. In IEEE International Conference on Computer
Vision, pages 2832–2839, 2013. 1, 3
[13] K. Egiazarian and V. Katkovnik. Single image superresolution via BM3D sparse coding. In European Signal
Processing Conference, pages 2849–2853, 2015. 1
[14] W. Freeman and C. Liu. Markov random fields for superresolution and texture synthesis. Advances in Markov Random Fields for Vision and Image Processing, 1:155–165,
2011. 3
[15] D. Glasner, S. Bagon, and M. Irani. Super-resolution from a
single image. In IEEE International Conference on Computer Vision, pages 349–356, 2009. 3
[16] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu,
D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information
processing systems, pages 2672–2680, 2014. 1, 2
[17] H. He and W.-C. Siu. Single image super-resolution using
Gaussian process regression. In IEEE Conference on Computer Vision and Pattern Recognition, pages 449–456, 2011.
3
[18] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning
for image recognition. In IEEE Conference on Computer
Vision and Pattern Recognition, pages 770–778, 2016. 1
[19] J.-B. Huang, A. Singh, and N. Ahuja. Single image superresolution from transformed self-exemplars. In IEEE Conference on Computer Vision and Pattern Recognition, pages
5197–5206, 2015. 7, 8
[20] S. Ioffe and C. Szegedy. Batch normalization: Accelerating
deep network training by reducing internal covariate shift. In
International Conference on Machine Learning, pages 448–
456, 2015. 4, 5
[21] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial
transformer networks. In Advances in Neural Information
Processing Systems, pages 2017–2025, 2015. 1, 5
[22] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for
real-time style transfer and super-resolution. In European
Conference on Computer Vision, pages 694–711, 2016. 2
[23] J. Kim, J. Kwon Lee, and K. Mu Lee. Deeply-recursive convolutional network for image super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition, pages
1637–1645, 2016. 2
[24] J. Kim, J. K. Lee, and K. M. Lee. Accurate image superresolution using very deep convolutional networks. In IEEE
Conference on Computer Vision and Pattern Recognition,
pages 1646–1654, 2016. 2, 4, 7, 8
[25] D. Kingma and J. Ba. Adam: A method for stochastic optimization. In International Conference for Learning Representations, 2015. 5, 6
[26] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet
classification with deep convolutional neural networks. In
Advances in Neural Information Processing Systems, pages
1097–1105, 2012. 4, 5, 6
[27] W.-S. Lai, J.-B. Huang, N. Ahuja, and M.-H. Yang. Deep
laplacian pyramid networks for fast and accurate superresolution. In IEEE Conference on Computer Vision and
Pattern Recognition, pages 624–632, July 2017. 2, 7
[28] Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. Nature,
521(7553):436–444, 2015. 1
[29] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham, ´
A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al.
Photo-realistic single image super-resolution using a generative adversarial network. In IEEE Conference on Computer Vision and Pattern Recognition, pages 4681–4690, July
2017. 2, 5, 7
[30] B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee. Enhanced
deep residual networks for single image super-resolution. In
IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 136–144, July 2017. 2
[31] K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and
L. Zhang. Waterloo exploration database: New challenges
for image quality assessment models. IEEE Transactions on
Image Processing, 26(2):1004–1016, 2017. 6
[32] J. Mairal, F. Bach, J. Ponce, G. Sapiro, and A. Zisserman.
Non-local sparse models for image restoration. In IEEE Conference on Computer Vision and Pattern Recognition, pages
2272–2279, 2009. 1
