
mRASP论文研读——多语言神经网络机器翻译、预训练+微调、NTM界的BERT

[论文地址传送门:mRASP: https://arxiv.org/abs/2010.03142]
[论文代码传送门:https://github.com/linzehui/mRASP]
[论文应用传送门:火山翻译: 火山翻译 - 让翻译更简单]


mRASP是最近字节跳动AI Lab实验室在EMNLP2020上的一篇多语言翻译的工作Multilingual Random Aligned Substitution Pre-training (mRASP),它致力于实现机器翻译领域的BERT,采用预训练+微调的模型架构,其在32个语种上预训练出的统一模型在47个翻译测试集上取得了全面显著的提升。
下面我们将从Structure、Abstract、Introduction、Methodology、Experiments、Analysis、Related Works、Conclusion这几个方面对这篇工作进行详细的介绍:
1、Structure
本文主体结构如图所示,主要有摘要、引言、实验、分析、相关研究、结论以及致谢、参考文献和附录。
2、Abstract
MT: machine translation
NMT:neural machine translation
RAS:random aligned substitution
提出问题:是否可以提出一个普适的机器翻译模型?
解决方案:mRASP预训练模型
核心观点:随机对齐替换的创新性技术,使得不同语言中意思相近的词在向量空间中距离更近
模型:公开的32个语言对的数据集上预训练,然后再根据具体的语言对进行微调
实验:扩展实验到42个语言方向(例如中英和英中就是两个方向),并且数据涉及到大中小三种类型的数据集,并且转移到外来语言对( exotic language pairs)实验结果表明与在目标语言对上直接训练相比,mRASP获得了显著提升
突破性:第一次证实多语言机器翻译模型可以应用提升含有丰富语料资源的机器翻译模型;第一次在多语言神经网络机器翻译中的”zero-shot translation”概念扩展到”exotic translation”,并把它分为四种场景;mRASP甚至能够提高在预训练语料库中从未出现过的exotic language的翻译质量
3、Introduction
NLP、BERT、mRASP(multilingual Random Aligned Substitution Pre-training)
提出问题:预训练+微调的范式在NLP任务中取得很大成就,本文主要目标就是寻找在机器翻译领域类似BERT的具有普适性的预训练模型MT领域中预训练模型局限性:
1、在fine-tune阶段,预训练模型需要复杂的技巧
2、机器翻译任务中,已有的预训练目标与下游的目标并不一致
3、已有的机器翻译预训练方法聚焦于在中小规模的数据上提升机器翻译的效果
针对以上问题,本文提出mRASP:
该模型在多语言上预训练出一个机器翻译模型,它可以作为任意两种语言的预训练基础模型,只要进行微调即可;
与在目标语言对上直接训练相比,mRASP获得了显著提升;
并且该方法保证预训练与微调共享相同的模型架构与训练目标;
考虑到许多语言词汇差异很大,语义却联系密切,我们首先在大规模多语言语料库上从不同的语言方向上进行预训练获得深度神经机器翻译模型,再在特定的翻译方向上进行微调;
为了拉近不同语言间的表示距离,本文提出了在源语言与目标语言之间的随机对齐替换的额外损失,并且替换后的句子仍然参与一样的训练过程;
广泛的实验:包括多尺度的翻译训练、以及外来语言的翻译训练,结果证明mRASP各种情况下均较为优越
多尺度:
extremely low resource (<100k)
rich resource (>10M, e.g. English-French)
四类exotic translation,假设MT任务对应语言为源语言à目标语言:
Exotic Pair:源语言与目标语言虽然都进行了预训练,不过在预训练阶段是隔开的
Exotic Source:源语言没有进行预训练,目标语言进行预训练
Exotic Target:源语言进行预训练,目标语言不进行预训练
Exotic Full:源语言与目标语言均未进行预训练
文章主要贡献:
Ø提出了一种普适性的预训练模型mRASP;该方法在多语言训练上非常有效,需要的训练集是多种双语对,数据量也大大减少;它使得预训练阶段与微调阶段具有一致的目标,这有效地提升了模型表现
Ø本文在预训练阶段提出了随机对齐替换的技巧,这种方法可以联系起不同语言间的语义空间,这大大提升了最终的翻译效果
Ø本文在不同类型的数据集上做了42对不同翻译方向的扩展实验,从而证实了mRASP在机器翻译的各种情况下的表现均提升明显;而且不同于机器翻译传统上预训练使用更多大量的单语言语料,mRASP预训练阶段用了较少的32种语言的语言对语料。
4、Methodology
4.1 mRASP
4.1.1 Architecture
采用的是标准的Transformer-large结构,即6层的编码器和6层的解码器;在16个heads上维度为1024;而且在前向神经网络中使用GeLU代替ReLU作为激活函数
4.1.2 Methodology
多语言神经机器翻译模型主要是学习一个多对多的映射函数f


4.1.3 Language Indicator
为了区分不同的翻译对,本文在语料中添加了语言标记,比如En→Fr
sentence “How are you? -> Comment vas tu? “应该表示为“
How are you? -> Comment vas tu?
4.1.4 Multilingual Pre-training via RAS
之前的跨语言信息主要是从预训练中共享的subword词得来,这样的信息有以下一些局限:
1、多数情况下词汇共享空间都比较稀疏;
2、许多语言中相同的subword词语义并不相同;
3、无法保证不同的语言中意义相同的词汇共享相同的语义空间
本文提出RAS(随机对齐替换)来消除不同语言之间的语义差,其使用的方法是非监督的词对齐方法MUSE,下图详细的展示了这种对齐方法
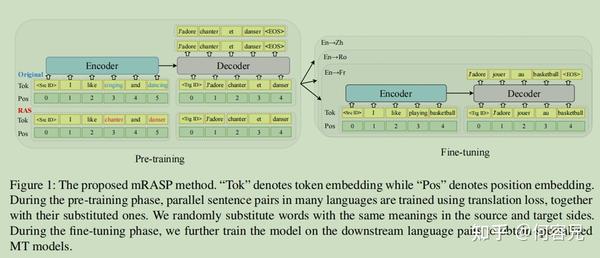

如图所示,将”I like singing and dacing”中的singing和dacing用对应的法语词chanter和danser替换,将替换前后的句子一起进行预训练,使用之前提到的预训练误差进行训练。
4.2 Pre-training Data
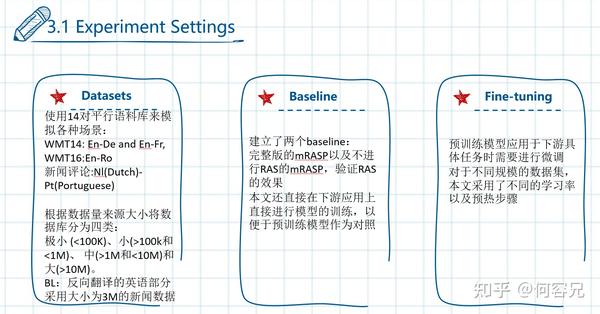
PC32(Parallel Corpus 32)包含197M个句子对,包含32类语言对,由于方向的问题可以看做64对,这些平行语料库来源广泛,主要包括:ted, wmt, europarl, paracrawl, open-subtitles, qed.
使用RAS时候,文章采用了真实的英语-X的双语字典,X代表除了英语的其它语言
4.3 Pre-training Details
采用联合词表,文章在训练集全集上学习共享BPE合并操作,并且添加单语言数据作为补充
而且以最大的语言语料库为标准,对于数据量小的语言语料库进行过采样,以平衡多语言语料库数据不平衡的情况,最后保留出现多于20次的token,最后获得64808个token。
在预训练阶段,文章使用并行语料库中全部的语言对进行模型训练,并且采用Transformer中的设定,使用Adam优化器
对于RAS,文章采用词典中top1000的词进行替换,而且只替换原语言语句中的词,而且根据双语词典,每次替换的概率只有30%;而且为了解决一词多义的情况,文章每次只随机选择一个候选词进行替换。
5、Experiments
实验部分主要展示了mRASP在各种场景下的优越性能,包括:
与已存在的预训练模型作对比
加入back-translation的思想
预训练+微调的框架
5.1 Experiment Settings

5.2 Main Results
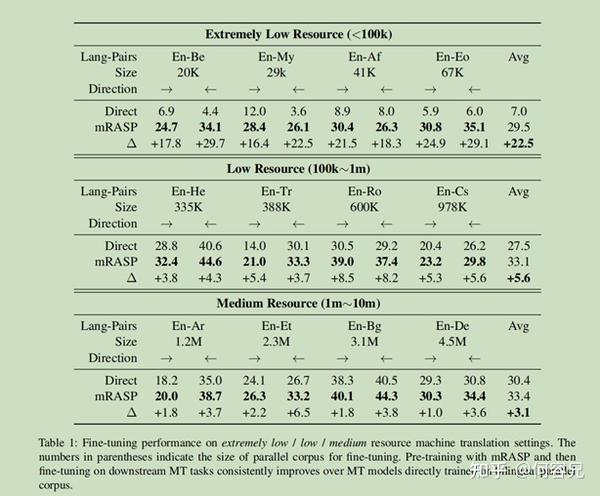

如表一所示:
在极小、小以及中等规模的各个数据库上mRASP获得了明显的提升;而且随着数据库规模的增大,随机初始化的baseline与预训练模型的差距逐渐减小。
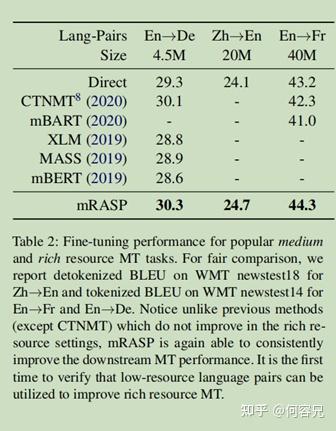
如表二所示:
在大规模的数据库上,与经典的模型相比较,mRASP预训练模型仍然有一定的提升。
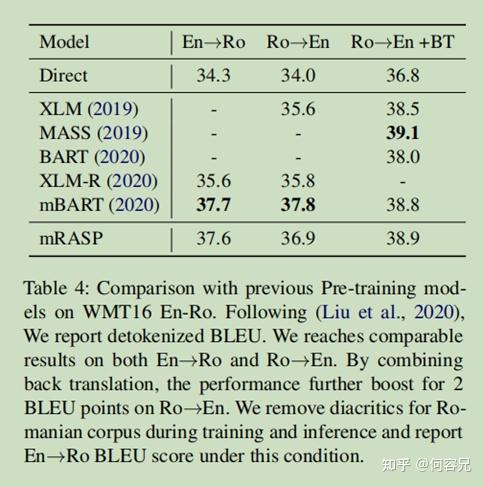

与其它预训练模型进行对比:
如表4所示,mRASP在英俄两个方向的互译表现一样好,而且加入反向翻译之后,模型的翻译性能又提升了2BLEU分数
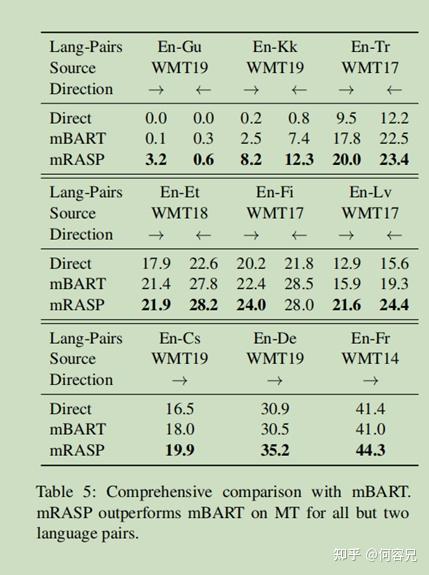

如表5所示,
mRASP在多数语言对的互译上明显领先于mBART;而且mBART在表现不如baseline时候,mRASP相比baseline却获得了一定的分数提升
5.3 Generalization to Exotic Translation
为了论证mRASP的普适性:
本文还做了一些实验,把mRASP用于翻译未在预训练中出现的语言,而且在每个类别都选择了不同规模的数据集。
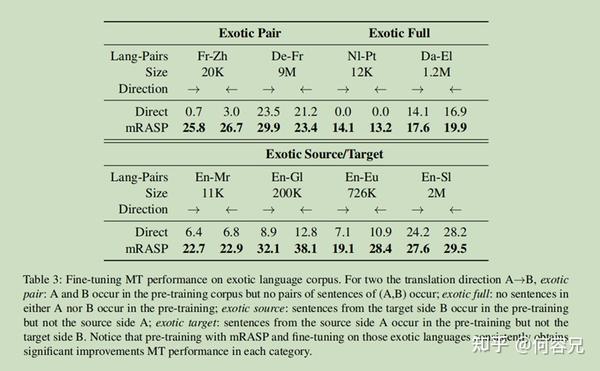

如表3所示:
mRASP在不同规模的数据集的每个类别中都有显著的收益
可以注意到,当源语言与目标语言均未出现在预训练阶段时,仅仅依靠11K的荷兰语与西班牙语的数据时,预训练模型仍能够达到较为合理的性能,而直接训练表现却很糟
这表明,预训练模型确实能够学习语言通用知识,并且可以很容易地迁移到外来语言。
6、Analysis
本部分主要是为了研究哪些因素导致了mRASP获得了很好的实验表现:
首先研究好的表现是源于预训练还是微调,使用微调与不进行微调的模型进行对比分析,结果发现模型良好表现主要源于预训练,而微调进一步提升了模型表现;
然后,我们研究带有RAS与不进行RAS的模型效果的差异,结果发现,随即对齐替换确实有助于连接不同的语言而且会带来额外的信息
最后,本文研究微调阶段的数据量对于模型的影响
6.1 The effects with fine-tuning
为了研究好的表现是源于预训练还是微调,使用微调与不进行微调的模型进行对比分析
使用不同规模的数据集:En-Af (41k) from extremely low resource, En-Ro (600k) from low resource, En-De(4.5M) from medium resource, and En-Fr (40M)from rich resource
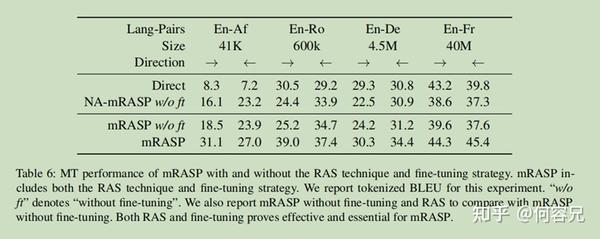

如表6所示:
不进行微调的模型在各个数据集上表现良好,而且明显优于直接训练模型,这说明预训练阶段模型已经学的足够好了,微调阶段只是进一步获得了额外加成
作者猜测,该模型主要在微调阶段调整特定语言的嵌入,同时保持其他模型参数基本不变。
如表6所示:
在预训练阶段不进行RAS的模型NA-mRASP在数据集上的效果明显不如mRASP;这意味着在预训练阶段注入随机对齐替换信息确实可以提高模型性能。
6.2 The effectiveness of RAS technique
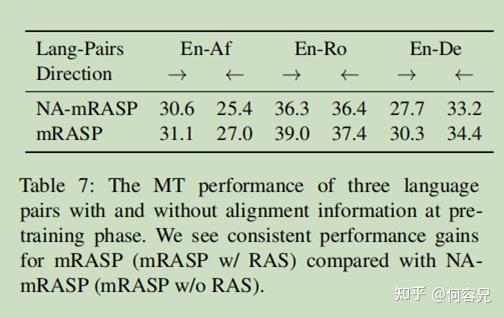

如表7所示,
在预训练阶段使用RAS在各种规模的数据集上确实提高了模型性能


如图3所示:
RAS确实使得不同语言之间的平均余弦相似度有了一定的提升,即论证了预训练阶段添加RAS使得语义空间中不同语言之间的距离拉近了。
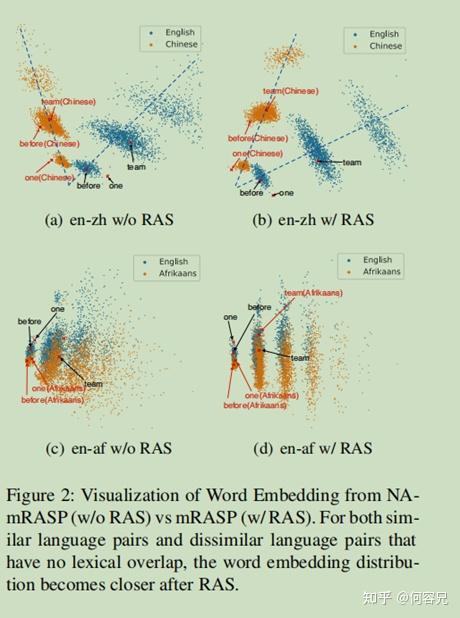

如图2所示,
为了进一步验证RAS在语义空间的影响,应用PCA方法将其映射到词嵌入空间,可以看到经过RAS处理后,词嵌入空间的分布变得更近;例如(a)和(b)中显示,RAS后虚线之间的夹角变得更加小了;(c)和(d)图则显示,英语和法语这两个相似语言之间在词嵌入空间中的重叠变得更大了
6.3 Fine-tuning Volume
为了研究数据量在微调阶段带来的影响,我们从英-德数据库(4.5M)中随机采样1K、5K、10K、50K、100K、500K、1M的数据,然后分别在这些数据上进行微调
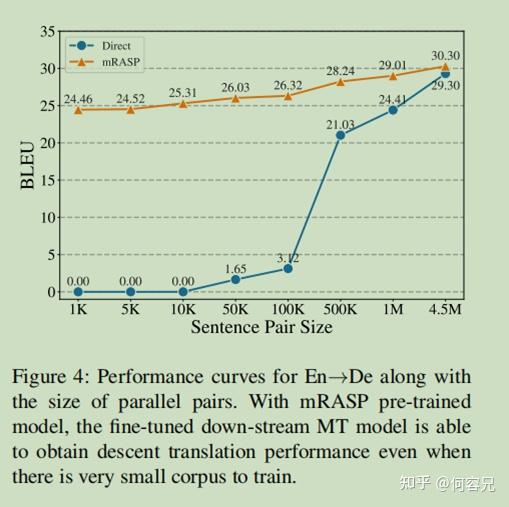

如图4所示:
在数据量较小时,预训练+微调的效果显著优于直接在数据集上训练模型的效果,而且之后随着数据量的上升效果稳步提升;而直到50K数据量之后,直接训练的模型的表现才有明显的改善。
7、Related Works
7.1 Multilingual NMT
多语言神经网络机器翻译旨在充分利用多语言数据来提升所有涉及语言的神经网络机器翻译。
前人的研究很多,我们也受到一些启发,相信来源不丰富的语言跟来源丰富的语言一起训练可以提升翻译效果;
然而,本文与他们的工作有一些不同之处,主要在:
1)本文的目标是通过多语言的预训练模型得到一对语言的最佳翻译模型;而前人往往为几十种语言对单独地训练模型,效率低下且浪费信息资源。
2)不同于多语言神经网络机器翻译,mRASP在来源丰富的语言对上也能得到较大的提升。
7.2 Unsupervised Pretraining
无监督的预训练从词嵌入、预训练的上下文表示以及时序2时序预训练显著地提升了对自然语言理解的先进水平,人们普遍认为无监督预训练成功的最重要因素之一是数据的规模,而我们的实验也验证了大规模数据确实能够显著提升模型水平。
同时,在无监督的跨语言表示方面也有许多工作。许多传统的研究表明,跨语言表征可以用来提高单语言表征的质量,后面研究者们也逐渐意识到不同语言间的词语对齐的重要性。
本文在这点做了以下突破:
1)mRASP是一个多语言序列到序列模型,这对NMT预训练更为理想
2)mRASP引入了对齐正则化来连接跨语言的句子表示。
8、Conclusion
本文提出的mRASP(multilingual
neural machine translation pre-training model)模型是一种普适性的多语言翻译预训练模型。
在预训练阶段加入了词语对齐的技术来连接不同语言之间的语义空间,显著减弱了不同语言之间在语义空间以及词嵌入空间的距离;
本文还说明了预训练阶段是提升模型表现的关键阶段,而微调阶段只是在预训练的基础上进行进一步的提升
本文采用了大量的实验来验证mRASP的优越性,在不同场景、不同来源以及外来语料库上的实验都验证了mRASP的有效性
而且本文还提出了一些猜想假设有待进一步的验证:比如采用不同的对齐方法会怎样?在更加大的语料库上进行预训练会如何?等等
