
学习笔记-浅析集成学习

硕士阶段,周边有同学在用集成学习研究风控问题,并以此发表了2-3篇论文。基于其为数不多的课题组分享,我脑补了集成学习的概念:多种算法混装在一个“箱子中”,通过一定手段将其集成。虽然老师说这种方法多么多么好,当时的我却不以为然,认为这跟“乱试大法”并没有本质区别:我们尝试多种不同的算法,尝试多种不同的组合方式,并从中选择一种较好的组合作为我们模型的学习算法。我们虽然用了集成学习,却对其内在原理并不了解。例如:我们为什么要用集成学习,我们应该选择哪些弱学习器作为集成学习的组成单元?我们的论文并没有对这些问题作出解答。
因为博士阶段需要研究数据驱动的优化决策,因此,我购买并阅读了周志华老师的《机器学习》(西瓜书)。在阅读此书后,自我感觉对集成学习有了更深入的理解。俗话说想想会不一定真的掌握,如果能通过讲解使其他同学会了那才是真的掌握。因此,谨以此文记录我的学习状态,欢迎大家友善地进行沟通交流,共同进步。
首先,是我认为的集成学习定义:与我硕士阶段理解的概念相似,我认为集成学习即是某个模型结合了多种算法,多种不同的算法基于数据均给出了自己的运算结果,最终模型基于一定规则给出最终结果。在我的理解中,多种算法的合作,不是指一个数据-算法-算法-...-结果的串行合作(即某个算法的输出是另一个算法的输入)。也不是指通过某个启发式优化算法调节确定某个单一学习算法的最合适的参数的过程。
接着,是我对之前提出的几个问题的解答。
Q:为什么要研究集成学习?A:一般来讲集成学习的效果会比最好的单一学习差,比最差的单一学习好,有种类似于平均的概念。提出集成学习的初衷,基于我浅薄的知识,我认为应当是为了避免单一学习带来的泛化能力的不足(内阁制的出现是为了一定程度上避免帝王专制带来的弊端)。
Q:集成学习的效果是否一定优于单一学习?A:这个答案显然是“否”。周老师的西瓜书给出了一种合理解释,如下图所示,不再进行赘述。此处集成学习的模型通过类似于投票法确定最终的输出。(原始表格位于周老师的西瓜书,此处表格复制于@者也的专栏:机器学习笔记--Bagging和随机森林https://zhuanlan.zhihu.com/p/72506850)
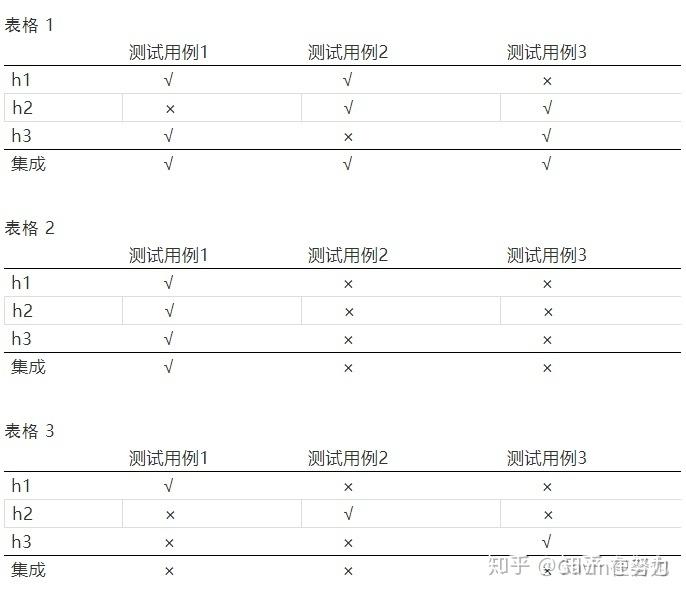

Q:我们应当如何选择构成集成学习的单一学习器?A:一般来讲,我们应当选择这样的单一学习器构成集成学习:首先,这些学习器的性能不能太差,一般应有大于50%的正确率(对于二分类问题,50%为随机猜测准确的概率)。其次,这些学习器之间应当具有较大的差异性,即要保证学习器之间一定的多样性。不过这里有一个问题,就是当学习器的准确率较高时,它们之间的多样性会降低。
Q:有哪些方法可以构建集成学习?即设计多个具有一定准确率和多样性的单一学习器?A:这其实就是集成学习研究的核心。根据周老师西瓜书中的介绍,可以通过两种方式研究集成学习。其一为“串行”思路,即学习器不断对数据进行学习,并且下一轮迭代时把学习错误的样本赋予更高的权重,直至生成的学习器不能满足约束(例如准确率低于某一阈值),或者运行至预设迭代次数,则算法停止,训练得到的模型即为最终的集成学习模型,代表算法为:boosting。其二为“并行”思路,即设计多个学习器对样本数据进行学习,并通过一定方式综合各单一学习器的输出结果,例如通过投票法(离散),加权平均(连续)等(当然也存在加权投票。。。),代表算法是bagging和随机森林。现在借用周老师的内容,大致介绍一下这两种不同的思路。以下为西瓜书原文(周志华, 机器学习[M], 北京, 清华大学出版社, 2016年1月, 171-196.):
“Boosting是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器,如此重复进行,直至满足停止约束。”
“Bagging是并行式集成学习方法最著名的代表,通过有放回的随机抽样生成样本,通常采用投票法确定结果。”
“随机森林是bagging的一个扩展。在以决策树为基学习器构建bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择。简单地说,随机森林与决策树的不同之处在于其每次先随机选择k个属性,再从这k个属性中选择最优的一个属性进行分支。当k等于全部属性时,随机森林的决策树与普通决策树一致。”
周老师还给出了许多数学证明,我一时还不能融会贯通,待日后再进行记录。
综上所述,我认为集成学习的目的是通过构建若干单一学习器,使得集成多个学习器后的学习模型能够具有更强的泛化能力。为达到这样的目的,选择的单一学习器必须具备这样的性质:1.每个单一学习器具有一定的准确率,即使不对其进行集成依然能够较为准确地对数据进行分类预测等。2.学习器之间应当具有一定的差异性,这样才能做到优势互补,如上文表格1。
我认为可以通过如下方式设计学习器。1.通过不同的采样方法,获得不同的训练样本,从而获得具有较大差异的学习器。2.通过迭代运算,每次重点关注分类错误的样本,生成不同的学习器,最终对这些学习器进行集成。至于这些学习器是属于同一类型学习器还是不同类型学习器则无关紧要。
写完此文,我觉得理解集成学习并不难,只要有一定的概率论和统计的基础就能理解它,使用它。难的是知道我们为什么要设计这样的集成方法,其内在数学原理是什么。路漫漫其修远兮,我也是初学机器学习,如有理解偏颇之处,还望不吝赐教。
PS:在看到西瓜书第13章时,其中有一部分内容我觉得和集成学习较为相似,即“基于分歧的方法研究大部分标记缺失的数据的分类预测问题”。基于分歧的方法中提到了协同训练。这一方法也是通过设计不同的算法,对不同视图(角度)的数据进行分析,多种算法之间相互协同共同进步。