
神经网络正则化(3):data augmentation & early stopping

在神经网络正则化1:L1/L2正则化和神经网络正则化(2):dropout正则化中我们介绍了两种正则化方法用来解决过拟合问题,还有其他的方法可以减少神经网络中的过拟合,本文介绍两种方法:
- data augmentation数据扩增
- early stopping
1. data augmentation
假设我们训练神经网络来完成图片分类任务,希望通过扩增训练数据来解决过拟合的问题,但是扩增数据代价很高,有时候无法扩增数据。那么我们可以通过添加这类图片来增加训练集[1],例如
- 水平翻转图片
- 裁剪图片
- 旋转、扭曲图片数字等
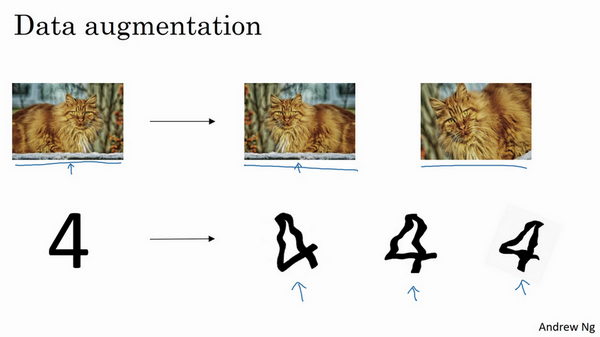

在计算机图像处理领域,由于图像输入维数非常高,导致很难找到对应那么多的图像,因此data augmentation在CV领域应用极为广泛。
2. early stopping
early stopping的思路是,在训练过程中,我们通过观察dev set的误差来判断训练过程是否逐渐过拟合。dev set error通常会先呈下降趋势,然后再某个节点处开始上升,early stopping的作用是在梯度出现上升势头的时候停止训练来放置过拟合,如下图所示。
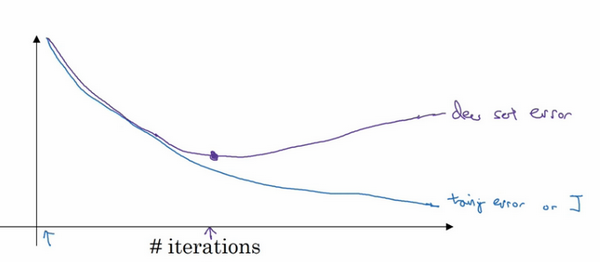

蓝色曲线表示随着训练次数增加,训练集的训练误差逐渐降低;紫色曲线表示在验证集上的误差,在中间点的时候,应该停止训练。
early stoping的缺点在于:它希望能够同时解决
- 优化代价函数 J(w,b)
- reduce overfitting
两个问题,如果过早结束训练,导致第一个问题J较大,这样用一个方法同时解决两个问题会导致相互掣肘,需要考虑的情况比较复杂。
但优点在于,只需要运行一次训练,就可以找到中间的较好的参数集合。
如果不用early stopping,另一种方法就是L2正则化,训练神经网络的时间就可能很长。我发现,这导致超级参数搜索空间更容易分解,也更容易搜索,但是缺点在于,你必须尝试很多正则化参数 \lambda 的值,这也导致搜索大量值的计算代价太高。
[1]Simard P Y, Steinkraus D, Platt J C. Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis[C]// International Conference on Document Analysis and Recognition. IEEE Computer Society, 2003:958.

