
Global Encoding for Abstractive Summarization 论文复现


Global Encoding for Abstractive Summarization (ACL 2018)
原论文代码github地址:https://github.com/lancopku/Global-Encoding 这篇论文的模型是使用了生成式文本摘要中经典的带attention的seq2seq模型来作为论文的基线模型,代码结构十分清晰,bug很少,而且使用了中文的文本摘要数据集,因此可以作为生成式摘要的代码学习的一个参考。 seq2seq模型以及本文代码的详解:
项目运行流程 :
1.项目环境配置:
Ubuntu 16.0.4 Python 3.5 Pytorch 0.4.1 pyrouge
tips:该代码不能直接在win系统上直接运行,因为代码中包含了对linux终端的命令。
服务器环境配置
使用anaconda建立虚拟环境,然后配置需要的python环境。(更多conda命令自行搜索)
conda create -n name python=3.5 #创建python版本为3.5,名字为name的虚拟环境
conda info --envs #列出所有已经存在的虚拟环境
source activate name #切换到名为name的虚拟环境 source deactivate #注销该环境
创建好虚拟环境后使用source activate name激活该虚拟环境,然后开始进行pytorch配置 该项目主要需要安装的包有:
pytorch 0.4.1 pyrouge
tips:还有一部分常用包比如matplotlib等,在运行时会提示缺失包,请自行安装。
下载地址推荐清华源,下载速度极快
链接地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/?tdsourcetag=s_pctim_aiomsg
conda config --add channels url 将该url加入conda的下载源中
下面代码可以更换pytorch的下载源 tips:Anaconda的其他包也都能替换下载源,参考该网站
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/?tdsourcetag=s_pctim_aiomsg打开conda的下载来源显示
conda config --set show_channel_urls yes一定要选择自己服务器对应的cuda版本!!! 安装pytorch0.4.1和cuda100版本的pytorch
conda install pytorch=0.4.1 cuda100 -c pytorch安装完成,除了pyrouge。 pyrouge由于是一个废弃多年的项目,安装流程极其麻烦,暂时还未成功配置,本文会先使用项目中附带的另一个评价标准Bleu。
2.处理数据
数据集: LCSTS中文数据集
其中包含大量短文本和摘要对以及部分人工评价后的摘要数据集
LCSTS数据集来源:Qingcai Chen, Baotian Hu and Fangze Zhu, LCSTS: A Large Scale Chinese Short Text Summarization Dataset, Emnlp2015.
来源为哈尔滨工业大学深圳研究生院,是开放的数据集,需要根据http://icrc.hitsz.edu.cn/Article/show/139.html该网站上的提示发送申请获取数据集。
数据大小:


数据处理流程,获取数据集后,数据格式是类似XML的数据:
<doc id=0>
<summary>
林志颖公司疑涉虚假营销无厂房无研发
</summary>
<short_text>
日前,方舟子发文直指林志颖旗下爱碧丽推销假保健品,引起哗然。调查发现,爱碧丽没有自己的生产加工厂。其胶原蛋白饮品无核心研发,全部代工生产。号称有“逆生长”功效的爱碧丽“梦幻奇迹限量组”售价高达1080元,实际成本仅为每瓶4元!
</short_text>
</doc>编写脚本提取上面文件中
摘要和短文本,分别输出到6个文件中:
train.src (训练集的输入(短文本))
train.tgt (训练集的输出(摘要))
test.src (测试集的输入(短文本))
test.tgt (测试集的输出(摘要))
vaild.src (验证集的输入(短文本))
vaild.tgt (验证集的输出(摘要))
将这6个文件放到一个文件夹中。
然后使用下面的命令处理数据 tips: 使用该命令前先进入Global-Encoding-master这个项目的根目录下
python3 preprocess.py -load_data path_to_data -save_data path_to_store_datapath_to_data: 原数据所在文件夹,即上述6个文件所在的文件夹 path_to_store_data:处理后数据输出到的文件夹位置
3.训练模型:
这里就来到了整个项目的关键点,也是除了pyrouge的配置之外最麻烦的地方了。 首先,我们需要解决以下几个问题:
1)项目文件缺失
源代码的models文件夹下缺失了loss.py文件,但是文件夹下存在.pyc文件(即loss.cpython-35.pyc),我们可以将pyc文件进行反编译得到原始的loss.py文件。(具体方法自行搜索,或者直接下载下面链接的文件)

2)lcsts.yaml配置文件设置
只需要修改前两行 数据集所在的文件夹,即2.中处理后的数据所在的文件夹的目录。
data: '/home/wu/Global-Encoding-master/data/'
运行日志应该保存在的文件夹 logF: '/home/wu/Global-Encoding-master/lcsts/'
选择评价标准
metrics: ['rouge'] 要使用Bleu则改成 metrics: ['bleu']
3)执行训练脚本
-log log_name:日志文件的文件夹地址,它会保存执行过程中的日志和保存的模型以及最后的预测的输出。
-config lcsts.yaml:将lcsts.yaml作为运行参数。 -gpus id:选择调用的gpu编号,如果使用CPU训练可以直接删除这个参数。
python3 train.py -log log_name -config lcsts.yaml -gpus id4)将模型的训练置于后台自动运行
使用nohup
nohup python3 train.py -log log0 -config lcsts.yaml > train.log 2>&1 &log文件 2>&1 & 将执行时的输出都保存在该log文件中 tail -n 5 train.log 输出log文件的最后5行,可以实时的查看当前脚本执行的输出
4.模型训练结果
.yaml文件中可以设置每训练多少次(默认是3000)自动保存checkpoint,也可以设置每训练(默认是10000)多少次自动输出valid的输出结果,同时,模型还会根据所选的评价标准,保存一个最佳的模型。 输出结果示例:
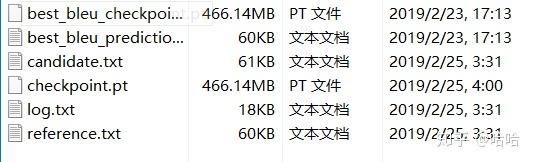

1.模型文件,.pt文件,可以使用
python3 train.py -log log_name -config config_yaml -gpus id -restore checkpoint -mode eval
2.valid验证集在最优模型下的预测结果,也就是模型生成的摘要。
3.候选集,即每1W次自动输出的预测结果。
4.checkpoint,即每3000次保存的模型。
5.log日志
6.参考集,也就是原数据提供的人工摘要。
预测结果输出后,使用Rouge程序对生成的摘要和参考摘要进行计算,得到的结果接近论文中lcsts数据集的Rouge结果,也就是30+。
5.待试验的问题
1.中文数据集的处理方式:字&词
词:使用jieba分词后,作为数据进行训练,在进行10W的数据量的预训练后,得到的摘要效果很差。但是有可能以词作为输入需要一个庞大的词表才能实现更好的效果,而且以词作为输入可能需要更长的训练时间,所以还不能排除分词后的训练效果。
字:对数据中的中文逐字隔开后,预训练后发现效果不错,然后使用全部240W的数据进行训练,得到了不错的效果。
2.数据集的特征:短文本&长文本
中文的数据集都是150字以内的短文本,生成一个更短的摘要,这个模型在中文长文本的情况下表现如何尚不清楚。
3.英文数据集
根据原论文中的结论,英文数据集在该模型的表现也很不错,但是原论文的英文数据集无法获得,暂时未进行实验。