CVPR2018 视频显著性检测论文笔记 (1)



论文题目:Flow Guided Recurrent Neural Encoder for Video Salient Object Detection
论文创新点
- 由于卷积模块不具有记忆性,因此在视频显著性检测中,直接只用卷积之后的特征整合不能表示视频中各个帧的时间连续性。本文提出了一个基于光流的循环编码神经网络框架,该框架可以很好的保证视频显著性检测中的时间连续性和对之前视频帧的特征表示。
- 我们将光流网络整合到了提出的FGRNE框架之中,光流可以对每一帧的动作进行表示,每一帧的光流图将被继续使用,来预测一些在视频中发生剧烈变形的对象的未来动作。如图中的摩托车在视频播放的过程中发生了很大的变形,从很小一个物体变成的很大的一个物体,静态的模型对这类对象的显著性预测不是很理想。


3. 在提出的FGRNE模型中,使用了ConvLSTM进行特征的提取和编码。
ConvLSTM(复习)




FGRNE框架
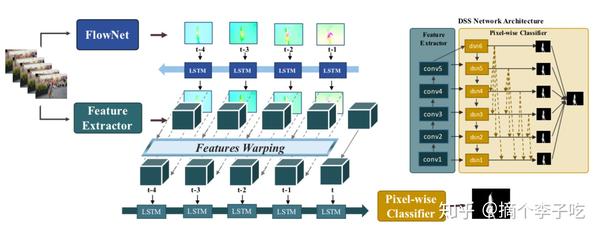

FGRNE框架一共分为三个模块:动作计算和更新模块、动作变形模块、时间连续性特征编码模块。
由于FGRNE框架可以和静态图片显著性检测网络结合,因此最后输出的特征被送进一个静态显著性检测网络中,进行最终的显著性预测,本文为DSS网络。
- 动作计算和更新模块
对于给定的k(本文k=5)张连续的帧图片,t为当前帧,t-1为上一帧,依此类推。首先使用现成的光流网络FLowNet提取当前帧t到每一帧的光流,之后将光流按照图中的倒序输入ConvLSTM网络中得到对应的输出,这个输出结果是提炼之后的光流图。光流本身就是描述动作的变化趋势,根据ConvLSTM来预测这种动作转移的趋势。


- 动作变形模块
动作变形模块是对精炼之后的光流图和对应帧的特征图进行二线性插值采样,最终可以得到变形的特征图,这些特征图带有动作的转移趋势。


- 时间连续性编码特征模块
将之前模块得到的变形的特征图,按照正序输入ConvLSTM,最后输入到当前t帧后产生的隐藏层就是最终的特征编码,将这个特征编码送入到一个静态图片显著性检测网络就可以得到最终的显著性结果。


总结反思
这篇文章提出的模型基本思路很好理解,视频和静态图片不一样,视频更加强调时间上的连续性。通过使用光流可以预测两帧之间的动作转移,而借助ConvLSTM网络又可以通过学习动作转移特征预测未来的动作转移特征。
为什么第一次的ConvLSTM和第二次的ConvLSTM输入的光流顺序不一样呢?
前者ConvLSTM强调的是学习,由近到远的学习顺序是最好的,先输入t到t-1帧的光流,之后输入t到t-2的光流依此类推。
后者ConvLSTM强调的是预测,那么有远到近的输入是最好的,t-4到t的动作转移特征最开始被输入,之后是t-3到t的动作转移特征依此类推,当输入t帧的提取特征时候,ConvLSTM就有了一个很好的积累。