from keras.datasets import imdb
from keras.utils.np_utils import to_categorical
import numpy as np
from keras import models
from keras import layers
import matplotlib.pyplot as plt
#one-hot编码
def vectorize_sequences(sequences,dimension = 10000):
results = np.zeros((len(sequences),dimension))
for i,sequence in enumerate(sequences):
results[i,sequence] = 1
return results
#imdb是一个二分类问题
#一共有5w条数据,2.5w用于训练,2.5w用于测试
#每条数据是一个list,list里保存的是英文单词对应的排序
#num_words=10000表示保留前1w个常出现的单词
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
#下面的代码用来解码第一条数据的内容
data = x_train[0]
#word_index是一个dict,保存的是英文单词:单词排序位置
word_index = imdb.get_word_index()
index_word = dict((index,word) for (word,index) in word_index.items())
#i-3是because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
data = ''.join(index_word.get(i-3,'?') for i in data)
######################################################
#神经网络的输入得是一个张量,使用one-hot编码处理数据
x_train = vectorize_sequences(x_train)
x_test = vectorize_sequences(x_test)
#keras的输入数据要转换为float类型,y是int类型,做一个类型转换
#构建神经网络
network = models.Sequential()
network.add(layers.Dense(16,activation='relu'))
network.add(layers.Dense(16,activation='relu'))
network.add(layers.Dense(1,activation='sigmoid'))
#选择优化器、损失函数、评估准则
network.compile('rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
#训练模型
history = network.fit(x_train,y_train,epochs=5,batch_size=512,validation_split=0.2)
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
acc = history_dict['acc']
val_acc = history_dict['val_acc']
epochs = range(1,6)
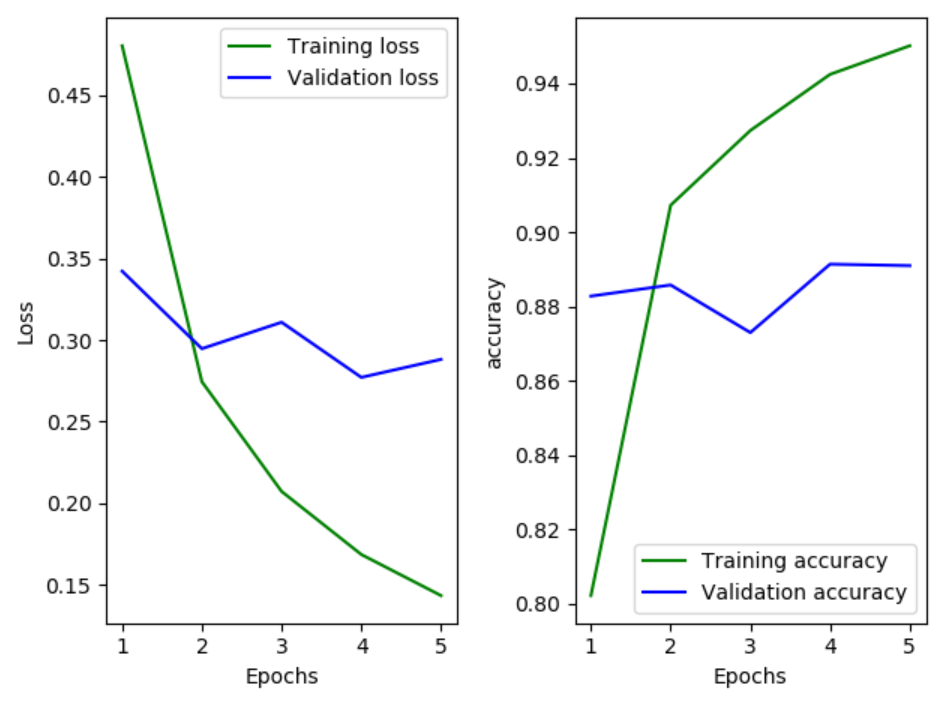
#loss的图
plt.subplot(121)
plt.plot(epochs,loss,'g',label = 'Training loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
#显示图例
plt.legend()
plt.subplot(122)
plt.plot(epochs,acc,'g',label = 'Training accuracy')
plt.plot(epochs,val_acc,'b',label = 'Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
pre = network.predict(x_test)
print(pre)
print(y_test)