

消息队列学习(一)
消息队列学习(一)
前言:
本文是学习和参考李玥老师的消息队列高手课,一方面帮助自己学习记录,另一方面作为分享
1,为什么使用消息队列?
1.1,进程间通信
消息队列设计之初就是为了解决进程间的通讯问题,只不过现在它更多的是用来做服务解耦和异步处理等场景。由于不同的进程处于不用的内存空间上,所以无法直接进行通讯,必须通过其他方式完成,比如:管道、共享内存、消息队列等。
1.2,异步处理
一个简单场景,在电商系统中,当用户成功下单并且付款完成后,需要减去库存,发送短信给用户,业务流程如图:

其中,每一个环节都是同步执行,如果每个环节操作都需要50ms,那么一整套流程下来需要4 * 50 = 200 ms,但是上述环节中,减库存和发短信之间互不影响,互不依赖,所以异步进行,这个时候我们就需要使用消息队列完成,那么业务流程就变成如下图:
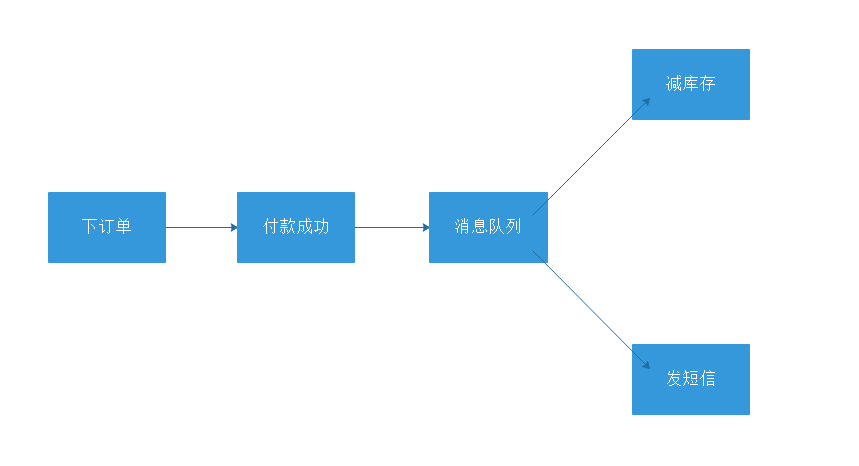
因为减库存和发短信是异步执行,所以总的执行时间就变成了3 * 50ms = 150 ms,如此一来减少了50ms时间,更何况真实的项目中肯定不止减库存和发短信这两种业务可以异步。所以说,利用消息队列可以大大减少业务的执行时间从而提高系统的响应效率。
1.3,流量控制
联想一下秒杀的场景,短时间内,海量的请求服务端,后端服务器很可能因为过载而奔溃掉,虽然说我们可以水平扩容添加机器,但是一味加机器不是解决办法,你需要考虑到机器成本、服务器成本、运维成本,再者说老板还有个愿意不愿意,所以提高我们服务自身的健壮性才是我们需要关注的。而自身的健壮性就需要保证我们的服务在自身可以承受的范围内尽可能的去处理更多的请求,处理不了的可以拒绝,但是往往现实中的程序会因为各种原因,并没有好的这么健壮性,虽然说我们可以通直接返回错误信息给客户,但是这种方式对客户来说体验非常差,所以我们需要设计出一套足够健壮的架构来保证我们服务端程序。
使用消息队列,秒杀场景的请求流程如下:
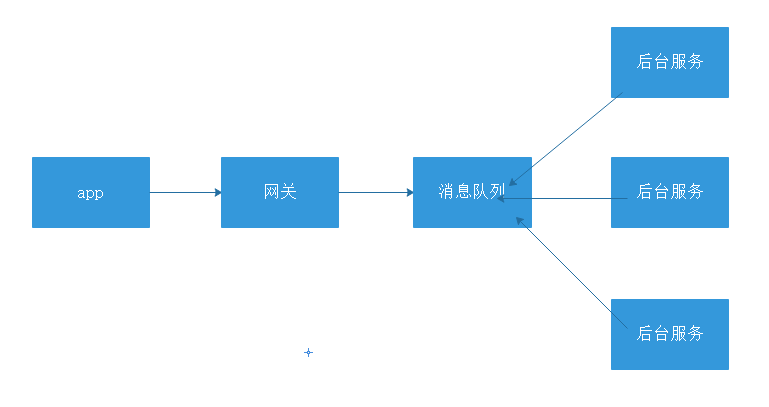
海量的请求从app发出到达网关,这么多的请求并不会直接冲击后台服务,而是先堆积的消息队列里,多个后台服务根据自己的处理能力去消费队列里面的请求,对于超时的消息直接丢弃,app段对于超时的请求直接响应秒杀失败。因为网关没有复杂的业务,所以处理能力是远远大于后端服务的,所以不需要担心网关扛不住,如果真的网关扛不住,那么还有别的措施去处理,但是这个处理措施的代价是远远小于服务端扛不住的处理措施的。但是上述的架构设计也是有利有弊,优点是可以根据后台的处理能力自动调节流量,但是缺点就是:
- 增加了业务的调用链,响应时间变长
- 增加了系统复杂度,上下游系统都需要将同步调用改成异步调用
所以可以如果预先能够估计出后台服务处理请求能力,就可以做如下改造:
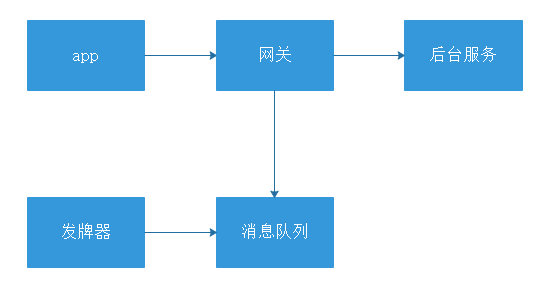
网关在放行请求先,先去消息队列获取一个token,如果获取到则放行,获取不到则拒绝请求,这样一来能保证放行的请求和可控的范围内,发牌器原理也比较简单,就是单位时间内生成指定个数的令牌放入到消息队列中,从而达到控制流量的目的,而优点是不破坏原有的同步调用方式。
1.4,服务解耦
假设A服务被B和C服务以及D服务所依赖,如果A服务发生变动,则需要去和B,C,D三个服务同时做调试,以保证服务正常,这样一来代价是非常大的,如果采用消息队列,就很简单了,B,C,D服务不直接和A服务产生关系,而是依赖于消息队列,A服务在做该改动后,只需要给消息队列发送一条消息即可,这种设计就很类似于观察者模式,尽可能的降低系统与系统之间的耦合性。
2,如何选择消息队列?
2.1,出发点
选择开源框架我们应该从以下几点考虑出发:
- 开源性,如果选择的框架没有开源,或者开源了很少的一部分,那如此一来,如果日后我们在使用中出现重大bug,因为不知道源码,那我们将束手无策,只能被动的等待带作者的修改,而这个时间是不确定的。
- 活跃性,如果该框架比较冷门,社区活跃度底,那么在使用中你很可能会遇到各种BUG,而且网上基本有很少的资料供你参考。
- 兼容性,如果你选择的框架兼容性很差,那么导致的问题就是日后你再想在使用这个框架的基础上添加一些新的东西将会变得很难
而对于消息队列来说,除了以上几点,还有其他方面我们需要考虑:
- 消息传递的可靠性
- 支持集群,因为现在的项目基本上并发量很大,所以需要支持集群来负载均衡
- 性能好,感觉我好像说了一句废话 -v-。
2.2,常见的消息队列
正确的选择使用那种消息队列是该根据自己的业务场景和市面上流行的不同的消息队列的特性而定,下面就在上述原则上简单总结一下市面上流行的消息队列的优缺点和使用场景(从流行程度划分梯队)
第一梯队:
RabbitMQ
老牌消息队列,由Erlang语言开发,社区活跃度高,支持AQMP协议。
优点:
- 社区活跃度高,基本上使用中所碰到的问题,网上都可以找到答案
- 语言兼容性好,有大多数语言的客户端
- 开箱即用,轻量级,容易部署何使用
- 支持灵活的路由配置
缺点:
- 对消息堆积支持不好,消息队列会影响性能
- 性能不是很高,每秒处理几万到十几万,是常见消息队列中性能最差的
- 开发语言冷门,熟悉容易精通难,而且Erlang学习路线陡峭
RocketMQ
国产优秀的开源消息队列框架,由阿里巴巴设计研发,经历过双11的洗礼,性能和稳定性以及可靠性值得信赖,慢慢被国内大厂所引用
优点:
国产开源,所以社区有很多中文的资料
性能好,高出RabbitMQ一个量级,大概每秒是几十万
Java语言开发,国人写的,所以源码学习起来相对容易,所以进行二次开发比较容易
响应时延低,可以做到毫秒级
经历过双11的洗礼,性能和稳定性以及可靠性有保证,且具备现代消息队列所有的功能和特性
缺点:
- 因为是国产,诞生时间也不是很长,所以在国际上不是那么流行,所以兼容性不是很好
Kafka
最初的设计目的是用于处理海量的日志,但是Kafka给人的第一印象不好,比如不保证消息的可靠性,可能会丢失消息,也不支持集群,功能上也比较简陋,但这些在Kafka的设计之初是被容许的,因为追求极致的性能,因为最开始它就只是为了处理海量日志而生,而这些问题在处理日志时,是可以被接受的,但是慢慢的Kafka这些问题都被慢慢完善。
优点:
- 性能高,Kafka采用Java和Scala开发,采用大量批量和异步的思想,所以性能是最好的
- 兼容性好,特别是对接大数据和流计算
缺点:
- 因为是异步和批量,当有消息来后,Kafka并不是立即发送出去,而是攒一批一发,所以同步收发消息的时延高,不适合做有在线业务的场景
第二梯队:
ActiveMQ
最老牌的开源消息队列,是十年前唯一可供选择的开源消息队列,基本上不建议使用,因为已经进入老年区,社区活跃度很低
ZeroMQ
严格来说 ZeroMQ 并不能称之为一个消息队列,而是一个基于消息队列的多线程网络库,如果你的需求是将消息队列的功能集成到你的系统进程中,可以考虑使用 ZeroMQ。
最后说一下 Pulsar,很多人可能都没听说过这个产品,Pulsar 是一个新兴的开源消息队列产品,最早是由 Yahoo 开发,目前处于成长期,流行度和成熟度相对没有那么高。与其他消息队列最大的不同是,Pulsar 采用存储和计算分离的设计,我个人非常喜欢这种设计,它有可能会引领未来消息队列的一个发展方向,建议你持续关注这个项目。
3,消息队列中的队列和主题是什么?
队列,就是我们理解的那个队列,没什么不一样的,FIFO模式,缺点就是队列里的同一个消息只能被一个消费者消费一次
主题,为了解决消息多次消费的问题,引入主题,消息队列架构便成了发布-订阅的模式,如图:

不同的消费者订阅不同的主题,每个消费者能获得每个主题的所有消息,从而实现一个消息给多个消费者消费。
RabbitMQ的架构设计模型:
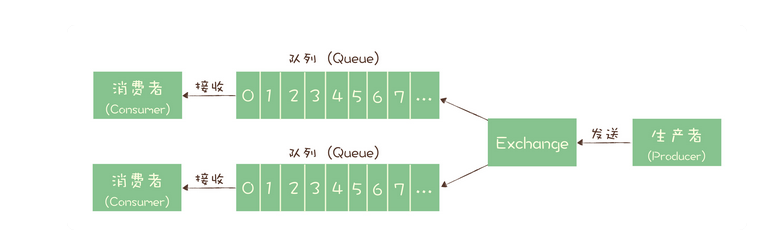
RabbitMQ并没有使用发布-订阅模式,而依然采用队列设计,但是使用交换机Exchange来实现消息被多次消费,消息的生产者不管消息会被发送到哪里,只需要将消息丢给交换机,通过交换机消息便会被路由到响应的队列中。
RocketMQ 的架构设计模型:
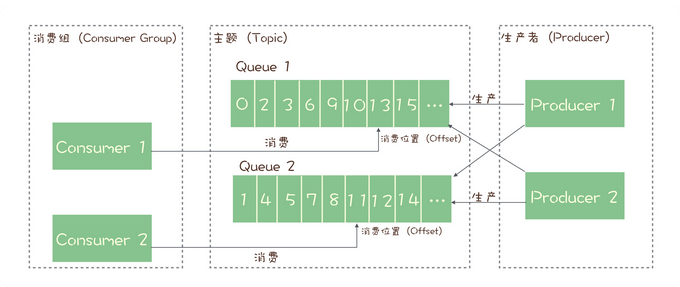
RocketMQ 采用的是标准的发布-订阅模式,而RocketMQ 做了改良,在主题层面引入了队列这个概念,这么做的原因是解决消息阻塞的问题。为了保证消息的可靠性,大多数消息队列都采用了消费-确认机制,这就表明,在前面一个消费没有被正常消费前,消息队列的Broker是不会再推送消息的,换句话说就是同一时刻是由一条消息被消费,这显然会很影响性能,所以RocketMQ引入了队列的概念,相同性质的消费者被划分成一个消费组,每个消费组消费Bocker里面的N个队列,每个消费组获取的队列里的数据都是相同的,都是同一个主题下的所有消息,换句话说,多个消费组之间,消息是共享的,而组内,每个消费者都是竞争关系,组内队列的消息只能被消费一次。因为同一个消息被多个消费组的队列共享,所以需要在每个消费组内维护每个队列的当前消费位置,当消息被消费,位置加1,该位置之前的消息就是已经被消费的消息,之后的就是为消费的,如果同一个消息在每个队列的位置都处于已消费位置,则Broker就可以删除这条消息。Kafka于RocketMQ架构相同,只不过队列在Kafka的模型中叫做分区。
总结一下,为什么RocketMQ和Kafka快?回想RBMQ,每个消费者对应一个队列,为了保证顺序性和消息不丢失,所以每个消费者都是串行消费队列上的消息,所以说两个消息不能被一个消费者同时消费,而RCMQ这种模式,一个消费者可以消费消费组所能消费的所有队列里面的消息,而且是可以并行消费不同的的队列的消息的,所以性能是比较高的,不同队列中的消息可以同时被消费,并且消费组的线程也可以并发的消费不同的消息。再一个,因为消费位置游标的存在,每个消费者线程之间不需要等待彼此的通知,等到消息在所有消费组都消费过后被删除。还有一个可优化点,同一个队列上面的消息无法被并发消费,如何优化,策略如下:
- 在同一个消费组内,维护一个全局的下标,采用CAS机制改变
- 建立一个重试队列,等到消息被消费后,消费了几次移动几次下标,如果消息失败就丢进重试队列
4,消息队列常见问题?
4.1,消息堆积怎么办?
先分析一下,消息堆积的原因是什么,首先,如果单位时间内,生产者生产10个消息,消费者消费10个消息,那这样是不会产生堆积问题的,那么产生堆积问题很可能就是生产力过大,消费能力过小引起的。而避免这种问题就需要注意在程序设计之初消费端如何设计,我们需要尽可能的保证消费端的处理能力大于生产者。当然,这个往往在我们发现已经出现消息堆积都已经很难改善,所以此时我们能做的就是检查服务端的代码,能优化尽量优化,可以使用异步就是用异步,最后可以水品扩容服务端,提高消费能力。而在服务生产段,在发生消息堆积时,我们可以适当的调整一下系统,做做服务降低,关闭掉一部分可以关闭的服务,减少生产者的数量进而减少消息数量。
当然,对于生产者生产力慢的问题,我们可以采用批量和增加并发的方式处理。
4.2,消息怎么保证不丢失?
消息从生产到消费一共会经历如下图几个阶段:

- 生产者在生产阶段采用ack机制,确保消息正确存储到Broker,
- 存储阶段,需要防止宕机或者进程被终止,所以可以调整Broker参数,将消息存储到磁盘上,或者搭建集群
- 消费阶段,当消费者业务正常处理完成后,再应答,而不是一接到消息就应答
总的来说,可以通过给每个消息添加序号来检测和处理消息丢失的问题
4.3,怎么保证消息重复消费?
先考虑一下,这种情况能不能避免,但是很可惜,在现有的消息队列中,基本上是避免不了了的,在消息队列遥测传输协议MQTT种固定了3种消息发送的服务质量标准:
- At most once: 至多一次。消息在传递时,最多会被送达一次。换一个说法就是,没什么消息可靠性保证,允许丢消息。一般都是一些对消息可靠性要求不太高的监控场景使用,比如每分钟上报一次机房温度数据,可以接受数据少量丢失。
- At least once: 至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
- Exactly once:恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级。
而市面上大多的消息队列采用的都是至少一次这种标准(Kafka另说),也就是说消息队列肯定会重复,这样想想其实也正常,宁愿重复也不要少,那么我们就应该想想怎么避免这种消息重复消费的问题,常见的如下:
- 保证消费端服务的幂等性,而保证幂等性手段有很多,比如利用数据库主键唯一性机制、乐观锁等。
- 利用redis判断,消费者生产的每一条消息都生成一个全局ID(雪花算法),最好可以自增,并插入到redis,消费者消费后,吧redis里面的记录删除掉,每次消费者消费消息前,先去redis里面查询一下这条消息的有效性
4.4,如何严格保证消息顺序性
- 单一队列,单一消费者,单一生产者
- 采用一致性hash,用消息的某个可以做唯一校验的属性的hash值来保证每次都进入相同的队列中或者不考虑扩容,采用队列数量取模

