Multi-behavioral Sequential Prediction with Recurrent Log-bilinear Model阅读笔记

论文:Multi-behavioral Sequential Prediction with Recurrent Log-bilinear Model
发表会议:TKDE 2017
作者:Qiang Liu, Shu Wu, Liang Wang
本文作者:梅朗
链接:Multi-behavioral Sequential Prediction with Recurrent Log-bilinear Model
前言:
在本文中提出了一种循环对数双线性(RLBL)模型。它可以用行为特定的转换矩阵的历史序列来建模多种类型的行为。RLBL应用循环结构来建模长期上下文。它在每个隐藏层中建模几个项目,并采用位置特定的转换矩阵来建模短期上下文。此外,考虑行为历史的连续时差是动态预测的关键因素,本文进一步扩展RLBL,并用时间特定的转移矩阵替换位置特定的转移矩阵,因此提出了一种时间层面的TA-RLBL模型。实验结果表明,提出的RLBL模型和TA-RLBL模型在三个数据集上的竞争比较方法(即Movielens-1M数据集,全球恐怖袭击数据库和具有不同行为类型的Tmall数据集)产生了显着的改进。
写作动机:
协同过滤的顺序预测已经成为一个新兴和关键的任务。鉴于特定用户的行为历史,预测他或她的下一个选择在改进各种online服务中起着关键作用。同时,有越来越多的行为类型的场景,但是现有工作主要研究对象是具有单一类型行为的序列。作为广泛使用的方法,基于马尔可夫链模型的前提是基于多个影响因素之间的独立性假设,这也是问题的来源之一。作为用于建模序列的两种经典神经网络方法,RNN不能很好地建模短期语境,因为其往往假定依赖性由序列位置的变化而单调变化,即当前位置比前一个对预测结果更为重要和相关,对于行为预测任务,这一假设并不能证实复杂的实际情况,特别是对历史序列中最近的元素,而LBL模型不适合长期语境,因为其序列最大长度往往被设定,而在真实情境中,行为序列是不固定的。因此本文将探索RNN与LBL模型的方法结合起来,使得其在长短期上下文中都可以取得良好效果。
主要工作:
1. 将RNN与LBL模型结合起来,加入位置特定的转换矩阵与循环神经网络,扩展成为针对单一行为类型序列的RLBL模型
2. 将行为特定的转换矩阵包括到上述RLBL模型中表示多类型行为的影响,以求对多类型行为序列建模。
3. 考虑连续的时间差异信息,吸收时间差特定的转换矩阵,进一步扩展RLBL模型至TA-RLBL模型,同时继续加入行为特定的转换矩阵,来建模多类型行为。
4. 将RLBL,TA-RLBL同其他主流的baseline在Movielens-1M数据集,全球恐怖袭击数据库和具有不同行为类型的Tmall数据集进行评估指标上的实验测试,比较结果与性能。
一、模型构建
1. RLBL( RECURRENT LOG-BILINEAR MODEL)
首先引入RNN模型和LBL模型,然后分别构建单一类型行为的RLBL的架构和多种类型行为的RLBL模型架构。
1.1 Recurrent Neural Networks
RNN的架构如图所示。它由输入层,输出单元,多个隐藏层以及内部权重矩阵组成:
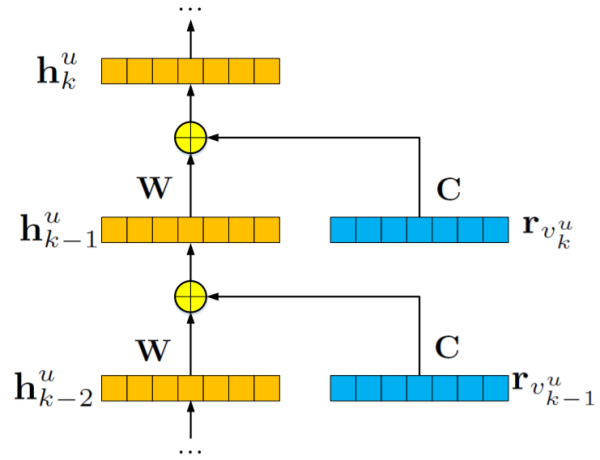
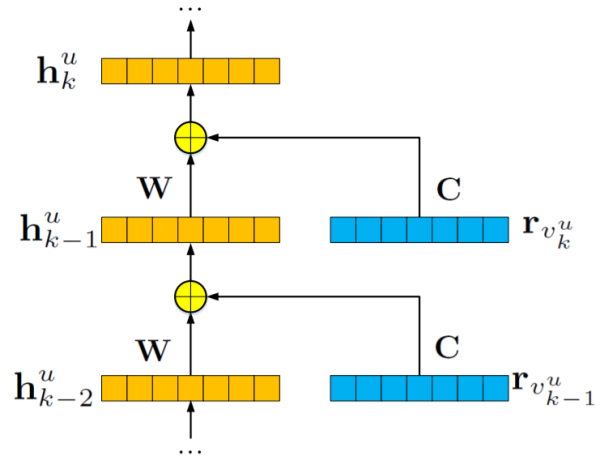
隐藏层的计算为:
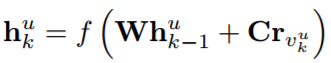
其中,h_{k}^{u} 代表了用户u在序列中位置k的隐藏表示,r_{v_{k}^{u}} 表示用户u的第k个输入项,W,C为d*d矩阵,分别表示当前和先前状态的转移矩阵。W可以传播顺序信号,C可以捕获用户的当前行为。 可以迭代地重复该过程,然后可以计算序列中每个位置处的状态。
1.2 Log-bilinear Model
LBL模型是具有单个线性隐藏层的前馈神经网络。LBL基于每个位置的输入项和转移矩阵来生成序列的最终预测表示。如图所示:
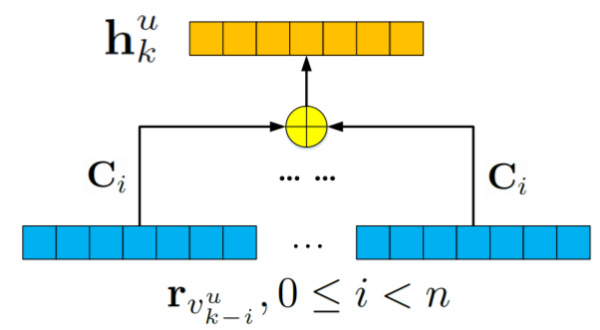
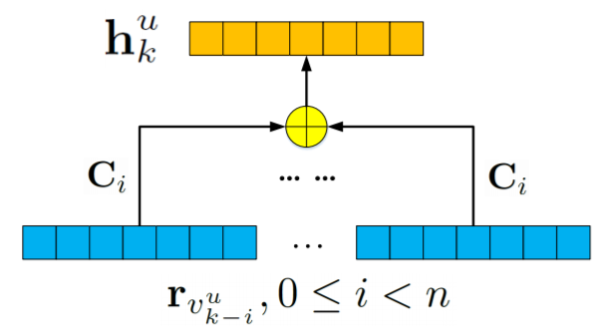
在LBL模型中,下一个位置的表示是线性预测:
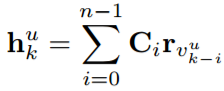
Ci表示序列中对应位置的转移矩阵,n是序列中建模的元素的数量。
1.3 单一行为类型的RLBL
如前几节所述,虽然RNN和LBL都取得了令人满意的成果,但它们仍然有自己的缺点。为了同时捕捉历史序列中的短期和长期上下文,而不是仅对RNN中每个隐藏层中的一个元素进行建模,我们在每个隐藏层中建立几个元素,并将位置特定矩阵并入循环结构。 如图所示:
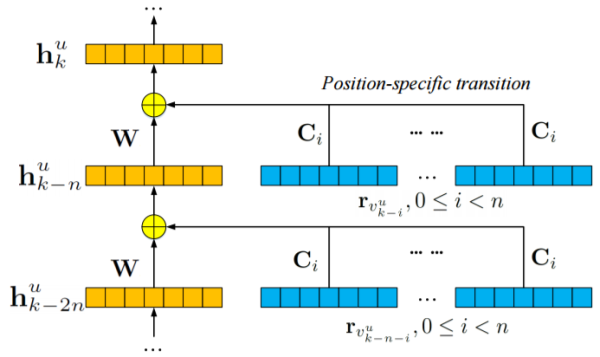
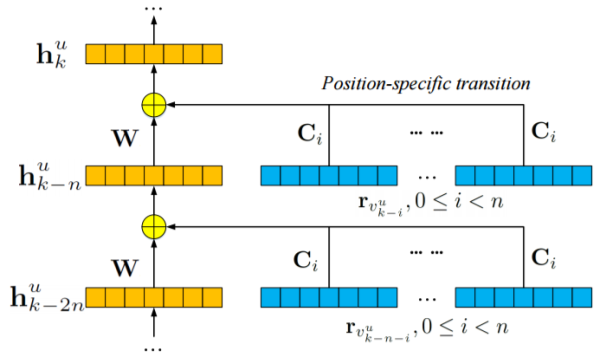
给定用户u,在序列中的位置k处的用户的隐藏表示可以被计算为:
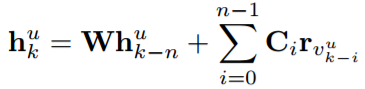
Ci为位置特定的转换矩阵,捕获短期语境(即第一项RLBL中的第i项)对用户行为的影响。
1.4 多类型行为的RLBL
本文提出,我们可以简单地忽略不同类型的行为,结合行为特定的矩阵来捕获多种类型的行为的属性。 那么,位置k处的用户u的表示可以被计算为:


M_{b_{i}^{u} } 表示对用户u的第i个项目上的相应行为建模的行为特定转换矩阵。
通过计算内积,可以将用户u是否在顺序位置k + 1处对项目v做出行为b的预测结果为:
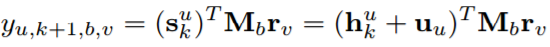

2. TA-RLBL(TIME-AWARE RLBL MODEL)
顺序模型通常忽略输入元素之间的连续时间差。时间差信息对于预测而言很重要,因为与较长的时间差相比较,较短的时间差异通常会对未来产生更大的影响。使用时差信息来扩展RLBL模型,并引入TA-RLBL模型。
2.1 提出模型
我们用特定于时间的转换矩阵替换位置特定的转移矩阵,并提出一个时间感知的RLBL模型。 如图所示:
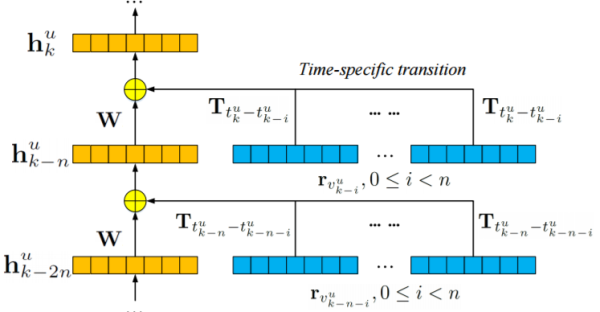

给定用户u,在位置k的表示可以计算为:
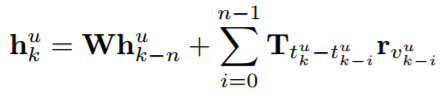

其中t_{k}^{u} 表示当前时间戳,T_{t_{k}^{u}-t_{k-i}^{u} } 表示时间差t_{k}^{u}-t_{k-i}^{u}的时间特定转移矩阵,可以捕捉最近行为历史的时间影响。为了模拟多种类型的行为,行为特定的转换矩阵也应用于TA-RLBL模型中:
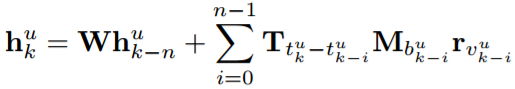

类似于RLBL,用户u是否可以在顺序位置k + 1处对项目v执行行为b的预测可以被计算为:
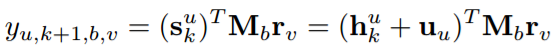

2.2 用于训练转换矩阵的线性插值法
本文我们将所有可能的时间差值的范围同样地分割成离散的分区。模型中只需要估计时区的上限和下限的转换矩阵。对于时间段中的时间差值,可以通过线性插值来计算其转换矩阵。 数学上,时间差td的时间特定转移矩阵可以计算为: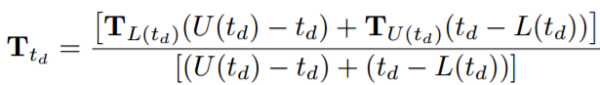

其中U(td)与L(td)分别为时间间隔的上界与下界。这种线性插值方法可以解决连续时间差学习时间特定的转换矩阵的问题。
二. 参数训练
在本节中我们介绍采用BPR和BPTT算法的RLBL和TA-RLBL模型的训练过程。
1. RLBL的训练
BPR被用于在行为预测任务中学习基于RNN的模型的目标函数。我们需要最大化以下概率:
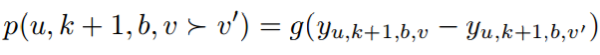

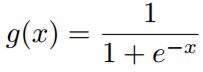
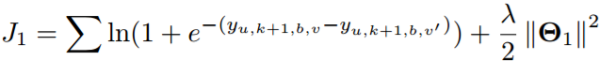

其中\Theta _{1}={U, R,W, C,M},即需要训练的参数,λ是控制正则化的参数,J1对参数的推导可以计算为:
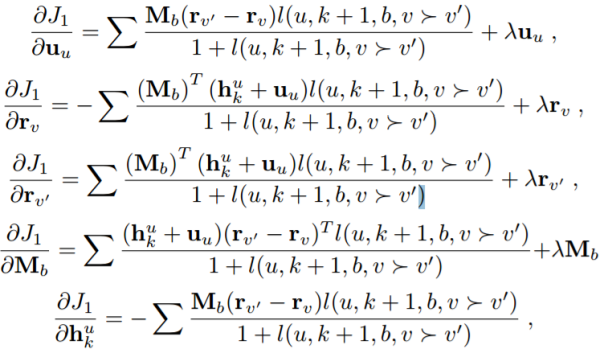
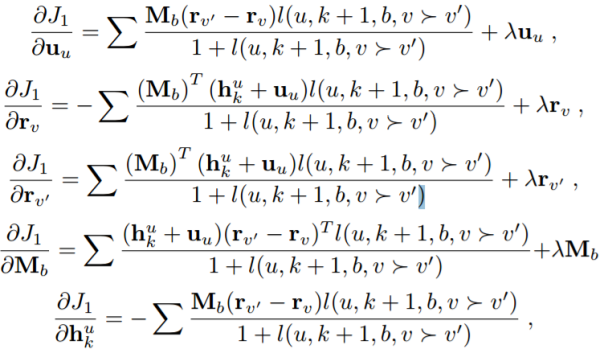
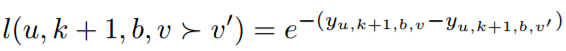

已经计算了输出层的推导。类似于传统的RNN模型,RLBL可以使用BPTT进行训练。对于用户u,给定在连续位置k处的表示,隐藏层处的相应参数梯度可以计算为:
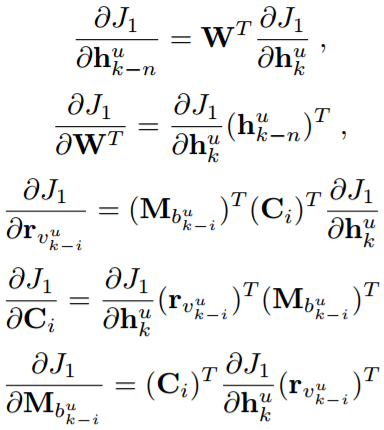
2. TA-RLBL的训练
对于TA-RLBL的训练,使用BPR,类似的,我们需要最小化以下目标函数:
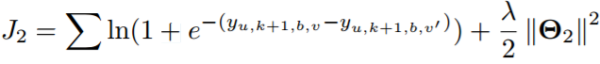

其中\Theta_{2} = {U, R,W, T, M},即需要被训练的参数。
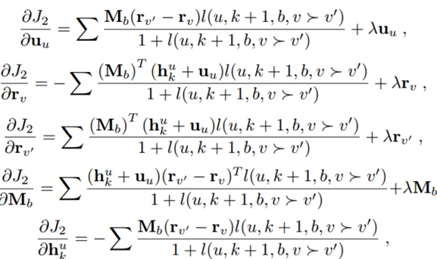

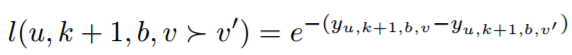

与RLBL相似,采用BPTT进行训练。隐藏层处的相应参数梯度可以计算为:
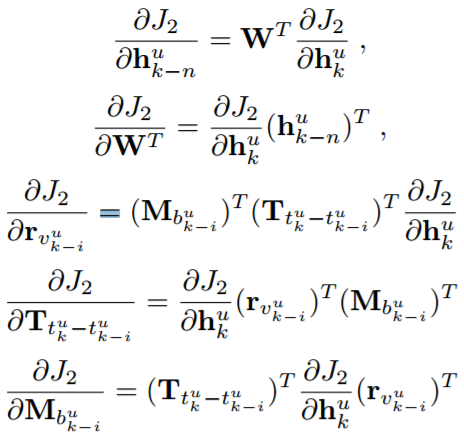

三、实验
如表所示,文本对不同行为类型的三种场景进行实验。首先介绍实验设置。然后我们进行实验比较不同窗口宽度的RLBL和TA-RLBL,并对实验结果进行比较,比较单行为和多行为的性能。此外还比较了模型和一些具有不同维度的最先进的方法。然后研究不同行为历史的模型的表现。最后分析了方法的计算时间和收敛性。
数据集:Movielens-1M,Global Terrorism Database,Tmall


对于这三个数据集的每个行为序列,使用序列中的前70%进行训练,将10%数据作为调整参数的验证集,保留20%进行测试。正则化参数设置为λ= 0.01,使用线搜索来选择每次迭代中的学习率。
用于比较的baseline : POP,MF,MC,TF,FPMC,HRM,RNN
评估指标:Recall@k,F1-score@k,Mean Average Precision (MAP)
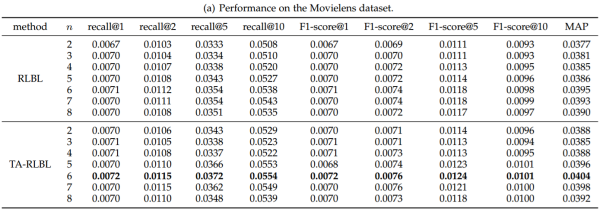
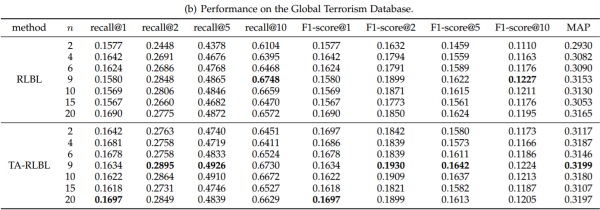
1. RLBL vs TA-RLBL
为了比较RLBL和TA-RLBL的性能,并研究不同窗口尺寸的性能,我们对具有不同窗口大小n的三个数据集进行实验。Recall,F1-scores和MAP评估的结果如表所示。


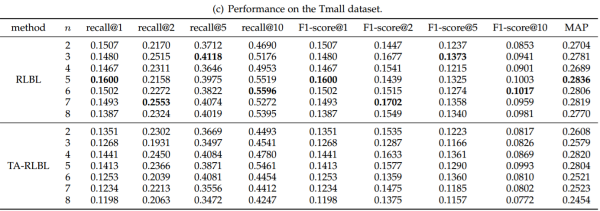

结果分析:
在大多数情况下,TA-RLBL表现更好。
在Movielens上,TA-RLBL通过所有窗口宽度明显地达到了所有度量评估的更好的性能,两个模型之间的性能差异是稳定的。
在Global Terrorism Database中,TA-RLBL主要表现优于RLBL,特别是MAP进行的评估。但是在窗口宽度为n = 9的情况下,RLBL模型在recall@10,F1-scores@10取得了更好效果。
这些观察结果清楚地表明,当存在明确的时间信息时,用时间特异性转换替换位置特异性转换可以实现更好的性能。
在Tmall数据集上,RLBL在大多数情况下表现优于TA-RLBL。原因可能是天猫数据集中的时间信息详细到天级别。对于同一天发生的这些行为,只存在项目行为的顺序信息,但没有更详细的时间信息。因此,一天中行为的时间特异性转换矩阵将变得相同,并且其中的顺序将被丢弃。因此,TA-RLBL的时间特异性转换在Tmall数据集上带来了轻微的性能下降。
因此,需要根据在数据集中是否存在足够详细的时间信息,在RLBL和TA-RLBL之间选择合适的模型。对于TA-RLBL结合时差信息,当数据集具有详细的时间信息时,TA-RLBL将表现更好。否则,RLBL将是一个更好的选择。
实验结果为RLBL和TARLBL选择最佳窗口宽度n提供了一些提示。Movielens数据集的表现在n = 6时显然达到最好的表现。
在Tmall和Global Terrorism Database中,不同指标的表现不太稳定。我们可以根据MAP指标选择最佳参数。Global Terrorism Database的最佳窗口宽度为n = 9,Tmall的最佳窗口宽度为n = 5。
2. 单一类型行为 vs 多类型行为
通过recall,F1-scores和MAP对三个数据集进行评估的多行为和单一行为建模的性能比较如表所示。
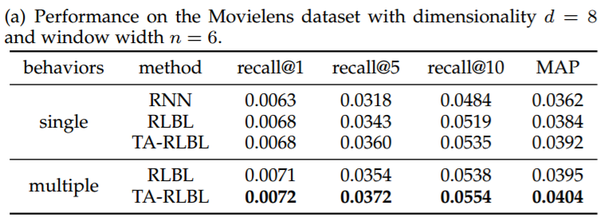
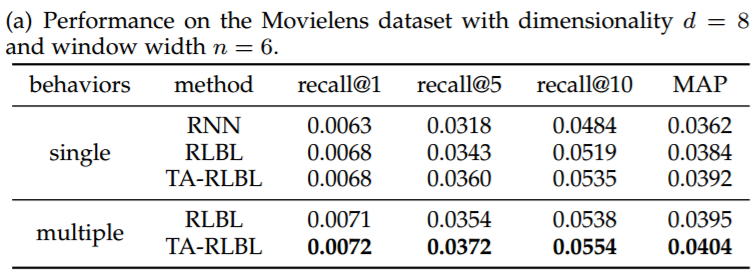
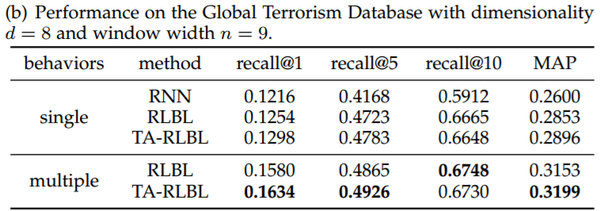

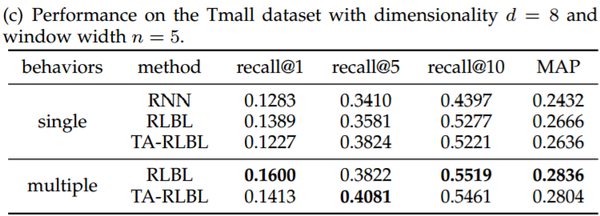

结果分析:
我们可以清楚地观察到对多种类型行为序列进行建模带来的重大改进。与建模单一类型行为相比,三种数据集的RLBL建模多种行为的MAP改善分别为2.92%,10.52%和6.41%。而针对TA-RLBL建模多种行为,与建模单一行为相比,MAP改善率分别为2.96%,10.46%和6.42%,与之前相似。
此外,我们还可以看到,即使忽略多种类型的行为,RLBL和TA-RLBL仍然可以优于RNN,具有相对显著的优势,这表明了位置特定和时间特定转换的有效性。同时,将RLBL和TA-RLBL的结果与RNN的结果进行比较,即使没有最佳窗口宽度,RLBL和TA-RLBL的大部分结果仍然优于RNN的性能。这表明具有不同窗口宽度的RLBL和TA-RLBL的有效性和稳定性。
3. RLBL,TA-RLBL与不同baseline之间的比较
RLBL,TA-RLBL与不同baseline在Movielens-1M,Global Terrorism Database,Tmall数据集上的结果分别如图所示:
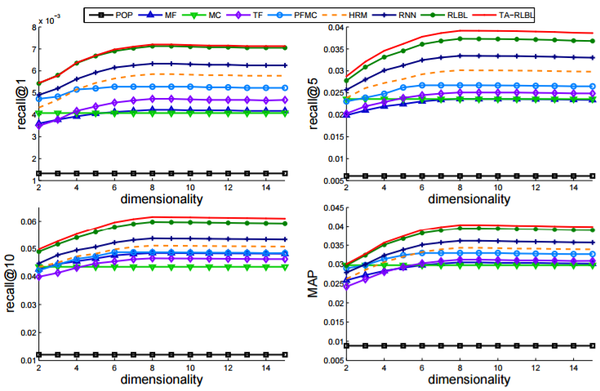

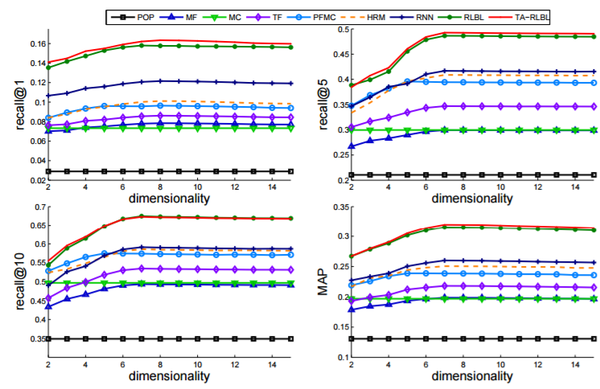

结果分析:
与POP的表现相比,MF,MC和TF的表现在三个数据集上有非常相似的改善。
与这三种方法相比,FPMC共同建模顺序信息和协同信息。学习近期行为的潜在表现,提高了FPMC的绩效。
RNN对三个数据集进行了较大的改进,是所有baseline方法中最好的。
可以观察到提出的RLBL模型和TA-RLBL模型在所有三个数据集上都达到最佳性能。使用每种方法最佳维度的表现,与RNN相比,Movielens-1M,Global Terrorism Database,Tmall数据集中RLBL的MAP改进分别为9.18%,21.27%和16.64,TA-RLBL的MAP改善分别为11.62%,23.04%和15.31%。
4. 不同长度历史行为之间的比较
根据长度将行为序列分为三种不同类型:短,中和长,调查不同情况下模型的性能。在我们的实验中,为了大致相等地分离行为序列,我们将Movielens数据集的阈值设置为50和200,将Global Terrorism Database的阈值设置为50和200,将Tmall数据集的阈值设置为100和500。具有不同行为历史长度的FPMC,HRM,RNN,RLBL和TA-RLBL的性能比较如表所示。
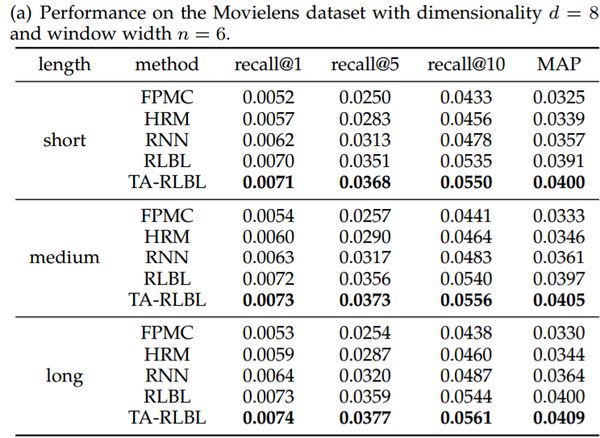

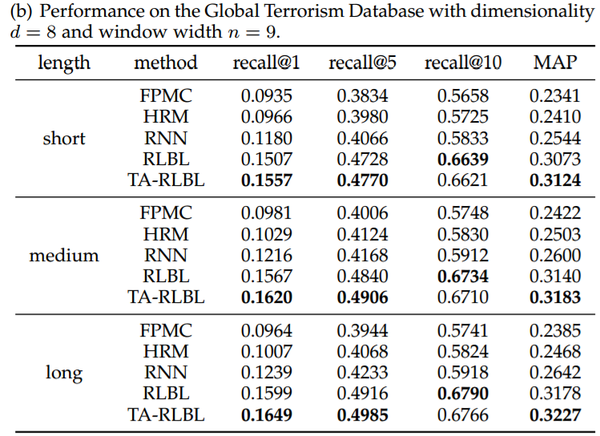

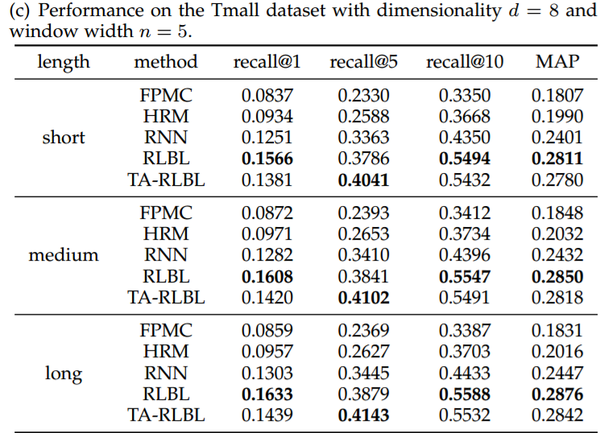
结果分析:
可以看出,RLBL和TA-RLBL比所有情况下的FPMC,HRM和RNN都有更好的性能效果。这表明提出的方法具有多种行为历史长度的灵活性。
此外,FPMC和HRM在中长度序列上具有最佳性能,其次是长序列。
对于RNN,RLBL和TARLBL,序列越长,性能越好。这可能是因为FPMC和HRM仅在进行预测时模拟最近的行为,而以前的行为只能由常量用户潜在的向量显示出来,所以行为序列越长,就会有更多的行为被忽视,而且表现也会越差。虽然具有循环结构的模型,RNN,RLBL和TA-RLBL可以考虑整个序列,因此,RLBL和TA-RLBL可以很容易地处理序列过长的情况。
5. 模型计算时间和收敛性分析
为了研究提出的方法的效率,表中结果展示了三个数据集训练过程中每次迭代中RNN,RLBL和TARLBL的计算时间:
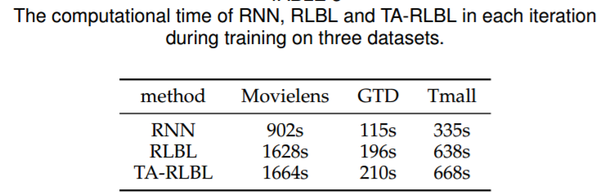

观察到我们可以在可接受的时间内对所有三种方法进行训练。RLBL比TA-RLBL快一点,表明时间特定性转换比位置特定性转换要花费更多的时间。
此外,RLBL和TA-RLBL的计算时间小于常规RNN的两倍。这意味着,RLBL和TA-RLBL带来的显着的性能改善只需要不超过两倍的计算时间。
下图分别展示了RLBL和TA-RLBL的收敛曲线。在三个数据集上计算RLBL和TA-RLBL的归一化和MAP。将recall和MAP的值归一化为[0,1],并画出相应的收敛曲线:
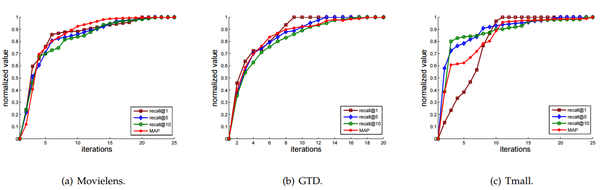

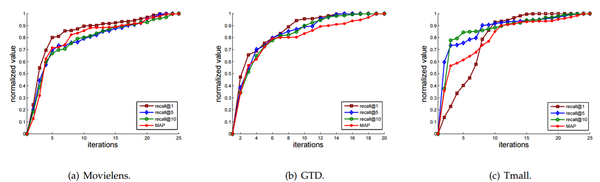

从收敛曲线可以看出,RLBL和TA-RLBL都可以在相对较少数量的迭代中实现收敛。此外,recall@1实现了比recall@5更快的收敛速度,并且recall@5实现收敛速度比recall@10快。这可能表明,在排名表中生成的项目越多,训练过程中需要的迭代越多。
四、总结
在本文中,我们提出了两种新的多行为顺序预测方法,即RLBL模型和TA-RLBL模型。我们在循环结构下建立我们的模型。RLBL在每个隐藏层中建立几个元素,并且结合位置特定的转换矩阵。有了这样的架构,RLBL可以很好地模拟历史序列中的短期和长期上下文。此外,为了在行为序列中捕获多种类型的行为,针对每种类型的行为设计并应用行为特定的转换矩阵。然后,为了在行为序列中引入时差信息,我们进一步扩展了RLBL模型,并提出了具有时间特异性转移矩阵的TA-RLBL模型。建模时差信息,TA-RLBL可以进一步提高RLBL在顺序预测中的性能。三个实际数据集的实验结果表明,RLBL和TA-RLBL都优于最先进的顺序预测模型。
