
【知识星球】剪枝量化初完结,蒸馏学习又上场

欢迎大家来到《知识星球》专栏,这里是网络结构1000变小专题,模型压缩是当前工业界的核心技术,我们这一个月一直在更新相关的内容,刚刚更新完了一批剪枝和量化相关的文章,最近又开始更新蒸馏学习相关的内容。
作者&编辑 | 言有三
1 剪枝
剪枝是一项古老的技术,从上个世纪传承至今,在学术界和工业界相关的研究工作都是很活跃的。剪枝根据不同的粒度有很多种,小到一个卷积参数,大到一个网络层。
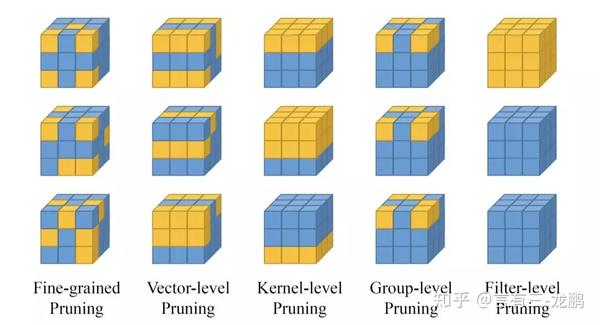

下面是Google关于剪枝的一个典型研究。


本文探讨了具有同样大小的稀疏大模型和稠密小模型的性能对比,在图像和语音任务上表明稀疏大模型普遍有更好的性能。
模型剪枝是一项重要的模型压缩技术,它给网络参数带来了稀疏性,在开源框架中可以通过和权重矩阵大小相等的掩膜来实现。
那么,剪枝到底对性能会有什么影响呢?首先看Inception V3模型的实验,在稀疏性分别为0%,50%,75%,87.5%时的结果,此时模型中非零参数分别是原始模型的1,0.5,0.25,0.128倍,即实现了1,2,4,8倍的压缩。
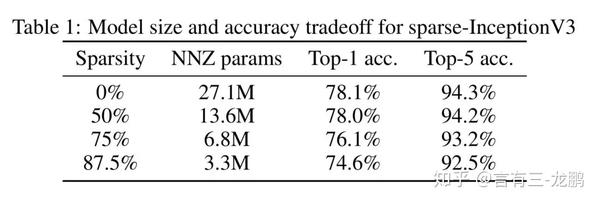

可以看到,在稀疏性为50%,性能几乎不变。稀疏性为87.5%时,指标下降为2%。
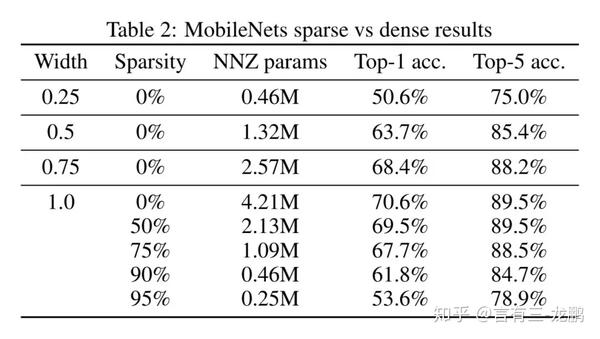

上表展示了MobileNet的实验结果,分别比较更窄的MobileNet和更加稀疏的MobileNet的结果,可以发现稀疏的MobileNet性能明显优于稠密的MobileNet。
75%的Sparse Model比0.5倍宽的Dense Model在top-
1指标上超出了4%,而且模型更小。90%的Sparse Model比0.25倍宽的Dense Model在top-1指标上超出了10%,模型大小相当。
从这里可以看出剪枝真的是一个非常有前途的课题,值得研究。
[1] Zhu M, Gupta S. To prune, or not to prune: exploring the efficacy of pruning for model compression[J]. arXiv preprint arXiv:1710.01878, 2017.
其他相关的内容如果感兴趣可以移步有三AI知识星球。




2 量化
量化是深度学习模型在各大硬件平台落地的重要基础技术,从全精度到8bit及以下的相关研究和实践都非常多。早期的研究关注在训练后模型的权重量化,而现在更多的研究已经集中在训练过程中同时完成量化,并且并不仅仅限制在模型的权重,而是从权重到激活,甚至是误差和梯度,并且开始关注混合精度量化,下面是一个典型的研究。


HAQ(Hardware-Aware Automated Quantization with Mixed Precision)是一个自动化的混合精度量化框架,使用增强学习让每一层都学习到了适合该层的量化位宽。
不同的网络层有不同的冗余性,因此对于精度的要求也不同,当前已经有许多的芯片开始支持混合精度。通常来说,浅层特征提取需要更高的精度,卷积层比全连接层需要更高的精度。如果手动的去搜索每一层的位宽肯定是不现实的,因此需要采用自动搜索策略。
另一方面,一般大家使用FLOPS,模型大小等指标来评估模型压缩的好坏,然后不同的平台表现出来的差异可能很大,因此本文使用了新的指标,即芯片的延迟和功耗。
搜索的学习过程是代理Agent接收到层配置和统计信息作为观察,然后输出动作行为即权值和激活的位宽。其中一些概念如下:
(1) 观测值-状态空间,一个10维变量,如下:
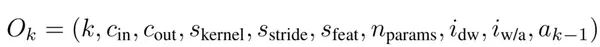

(2) 动作空间,使用了连续函数来决定位宽,离散的位宽如下:
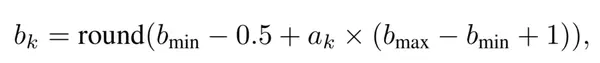

(3) 反馈,利用硬件加速器来获取延迟和能量作为反馈信号,以指导Agent满足资源约束。
(4) 量化,直接使用线性量化方法,其中s是缩放因子,clamp是截断函数。


c的选择是计算原始分布和量化后分布的KL散度,这也是很多框架中的做法。


(5) 奖励函数,在所有层被量化过后,再进行1个epoch的微调,并将重训练后的验证精度作为奖励信号。
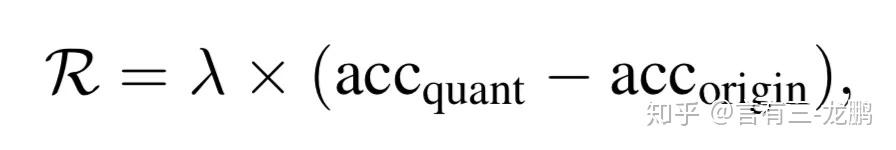

(6)代理,使用了深度确定性策略梯度(DDPG)方法。
下面我们看实验结果,这是延迟约束量化下的结果。
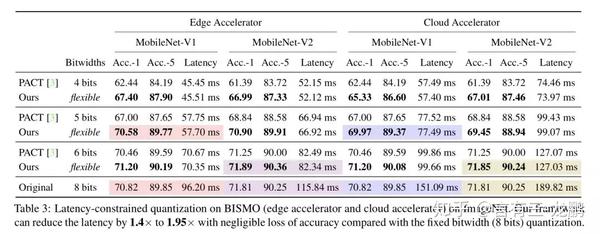

上图是MobileNet-V1/V2模型在边缘端和云端设备上的实验结果,与固定的8bit量化方法相比,分别取得了1.4倍到1.95倍的加速。
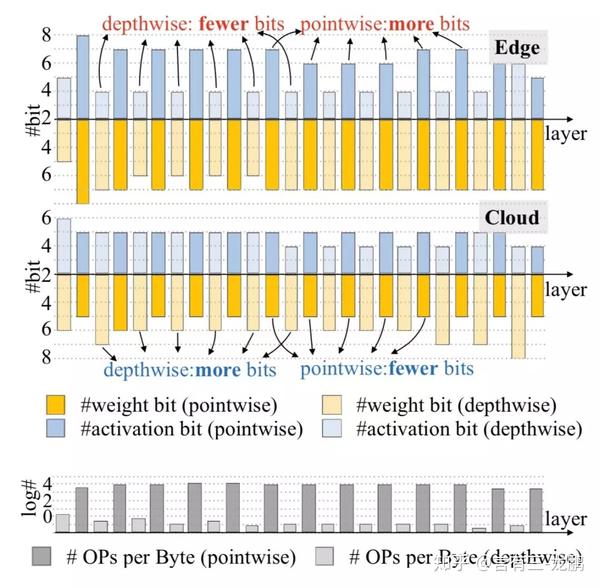

上图分别是边缘端和云端设备上MobileNet-V1各个网络层的量化特点,可以发现在边缘端设备上depthwise卷积有更少的bits,pointwise有更多,在云端则是完全相反。这是因为云设备具有更大的内存带宽和更高的并行性,而depthwise就是内存受限的操作,pointwise则是计算受限的操作,MobileNet-V2上能观察到同样的特点。
另外还有能量约束和模型大小约束的结果,读者可以读原始论文获取细节。
[1] Wang K, Liu Z, Lin Y, et al. HAQ: Hardware-Aware Automated Quantization with Mixed Precision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 8612-8620.
更多相关内容感兴趣请移步有三AI知识星球。


3 蒸馏学习
人类学习都需要一个经验更加丰富的老师引导,这一思想也可以更自然地迁移到深度学习模型的训练上,即知识蒸馏(Knowledge Distilling)技术,由此引发了很多的相关研究,大佬云集。下面是Hinton研究组最早期的经典方法。
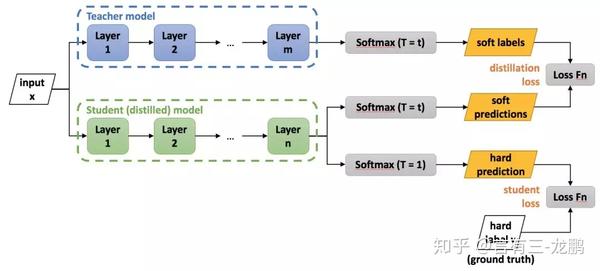

知识蒸馏(Knowledge Distilling)是一项重要的模型压缩技术,它将Teacher模型的知识迁移到了Student模型上,有着很广泛的应用。
知识蒸馏法包含了一个大模型,也被称为teacher模型,一个小模型,也被称为student模型,teacher模型和student模型的训练是同时进行的。
Hinton最早在文章“Distilling the knowledge in a neural network”中提出了这个概念,核心思想是一旦复杂网络模型训练完成,便可以用另一种训练方法从复杂模型中提取出来更小的模型。
“蒸馏”的难点在于如何缩减网络结构但保留有效信息,文中以softmax分类为例子,T就是一个常量参数:
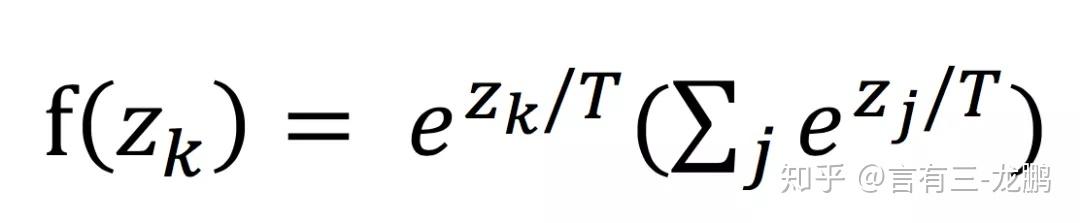

当T=1时,这就是softmax的定义,当T>1,称之为soft softmax,T越大,因为Zk产生的概率差异就会越小。
文中提出这个方法用于生成软标签,然后将软标签和硬标签同时用于新网络的学习。当训练好一个模型之后,模型为所有的误标签都分配了很小的概率。然而实际上对于不同的错误标签,其被分配的概率仍然可能存在数个量级的悬殊差距。这个差距,在softmax中直接就被忽略了,但这其实是一部分有用的信息。文章的做法是先利用softmax loss训练获得一个大模型,然后基于大模型的softmax输出结果获取每一类的概率,将这个概率,作为小模型训练时的标签,网络结构如上图。真实的损失函数包含了硬标签(hard label)和软标签(soft label)两部分。
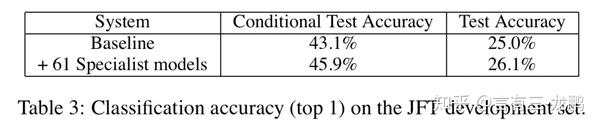
MNIST和JAT数据集上的结果都验证了该方法的有消性,如下图:



[1] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
更多蒸馏学习相关的内容请移步有三AI知识星球,火热更新中。


4 关于有三AI知识星球
有三AI知识星球是我们继公众号之后重点打造的原创知识学习社区,有需要的同学可以阅读下文了解生态。
大家可以预览一些内容如下,添加有三微信Longlongtogo加入可以优惠。












以上所有内容
加入有三AI知识星球即可获取
来日方长
点击加入
不见不散
更多精彩
每日更新


