
AdaShare: 高效的深度多任务学习

原文:AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning
作者: Ximeng Sun1 Rameswar Panda2
论文发表时间: 2020年11月
代码:GitHub - sunxm2357/AdaShare: AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning
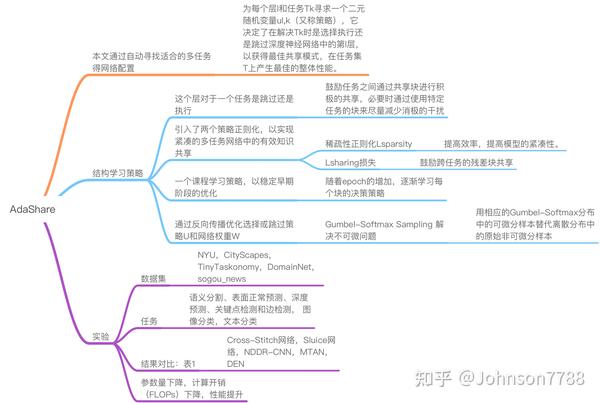

一、简介
二、相关工作
三、提议的方法
四、实验
五、总结
一、简介
多任务学习是计算机视觉中的一个开放性和挑战性问题。用深度神经网络进行多任务学习的典型方式是通过人工筛选的方案,共享所有的初始层并在一个临时点上进行分支,或者通过单独的特定任务网络与额外的特征共享/融合机制。与现有的方法不同,我们提出了一种自适应的共享方法,称为AdaShare,它决定在哪些任务中共享什么,以达到最佳的识别精度,同时考虑到资源效率。具体来说,我们的主要想法是通过一个特定任务的策略来学习共享模式,该策略有选择地选择在多任务网络中为一个特定的任务执行哪些层。我们使用标准的反向传播法对特定任务的策略和网络权重进行了有效优化。在几个具有挑战性和多样性的基准数据集上进行的实验表明,我们的方法比最先进的方法有效。项目页面:https://cs-people.bu.edu/sunxm/AdaShare/project.html。
多任务学习(MTL)专注于同时解决多个相关的任务,近年来引起了广泛的关注。与单任务学习相比,它可以大大减少训练和推理时间,同时通过学习相关任务的共享表示来提高泛化性能和预测精度[7, 56]。然而,MTL的一个基本挑战是决定在哪些任务中共享哪些参数,以实现多任务的高效学习。大多数先前的工作依赖于手工设计的架构,通常由共享的初始层组成,之后所有的任务在网络中的一个特设点同时分支(硬参数共享)[23, 29, 43, 5, 26, 12]。然而,有大量可能的选项来调整这样的架构,事实上,太大,无法手动调整一个最佳配置,特别是对于有数百或数千层的深度神经网络。当任务的数量增加时,就更加困难了,在不相关的任务之间不适当的共享方案可能会导致 "负迁移",这是多任务学习中的一个严重问题[52, 27]。此外,据经验观察,不同的共享模式往往对不同的任务组合效果最好[39]。
最近,我们看到深度多任务学习范式的转变,一组特定任务的网络与特征共享/融合相结合,用于更灵活的多任务学习(软参数共享)[39, 16, 48, 33, 49] 。虽然这项工作在常用的基准数据集上获得了合理的准确性,但它在计算或内存上并不高效,因为模型的大小与任务的数量成比例增长。
在本文中,我们认为一个最佳的MTL算法不仅要在所有的任务上实现高精确度,而且要随着任务数量的增加尽可能地限制新的网络参数的数量。这对于许多资源有限的应用来说是极其重要的,如自动驾驶汽车和移动平台,它们将从多任务学习中受益。受此启发,我们希望通过探索跨多个任务的有效知识共享来获得单个网络的最佳利用率。具体来说,我们提出以下问题。我们能否确定网络中的哪些层应该在哪些任务中共享,哪些层应该是特定任务的,以实现可扩展和高效的多任务学习的最佳精度/内存占用的权衡?
为此,我们提出了AdaShare,一种新颖的、可区分的高效多任务学习方法,它可以学习特征共享模式,以达到最佳的识别精度,同时尽可能地限制内存占用。我们的主要想法是通过一个特定任务的策略来学习共享模式,该策略有选择地选择在多任务网络中为一个特定的任务执行哪些层。换句话说,我们的目标是获得一个用于多任务学习的单一网络,支持不同任务的单独执行路径,如图1所示。由于形成这些特定任务执行路径的决策是离散的和不可微分的,我们依靠Gumbel Softmax采样[25, 35],通过标准的反向传播与网络参数共同学习,而不使用强化学习(RL)[46, 62]或任何额外的策略网络[1, 17]。我们设计的损失既能达到多任务学习所需的竞争性能,又能达到资源效率。此外,我们还提出了一个简单而有效的训练策略,其灵感来自于课程学习的理念[4],以促进特定任务策略和网络权重的联合优化。我们的结果表明,AdaShare优于最先进的方法,同时具有更高的参数效率,因此随着任务数量的增加,其扩展性也更加优雅。
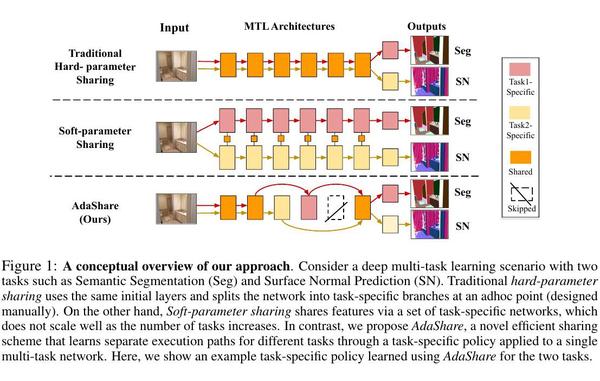

图1: 我们方法的概念性概述。考虑一个有两个任务的深度多任务学习场景,如语义分割(Seg)和表面正常预测(SN)。传统的硬参数共享使用相同的初始层,并在一个临时点(手动设计)将网络分割成特定的任务分支。另一方面,软参数共享通过一组特定任务的网络来共享特征,随着任务数量的增加,这种方式不能很好地扩展。相比之下,我们提出了AdaShare,这是一种新颖的高效共享方案,通过应用于单一多任务网络的特定任务策略,为不同的任务学习单独的执行路径。这里,我们展示了一个使用AdaShare为两个任务学习的特定任务策略的例子。
我们工作的主要贡献如下。
- 我们提出了一种新颖的、可区分的方法,用于在深度多任务学习中自适应地确定跨多任务的特征共享模式(在哪些任务中共享哪些层)。
- 我们通过Gumbel Softmax采样,使用标准的反向传播法,与网络权重共同学习特征共享模式,使其具有很高的效率。我们还引入了两个新的损失项,用于学习一个紧凑的多任务网络,在不同的任务间进行有效的知识共享,并采用课程学习策略以利于优化。
- 我们在几个MTL基准(NYU v2[40]、CityScapes[11]、Tiny-Taskonomy[68]、DomainNet[42]和文本分类数据集[8])上进行了广泛的实验,以证明我们提出的方法比最先进的方法优越。
二、相关工作
多任务学习。多任务学习已经从多个角度进行了研究[7, 56, 47]。早期的方法是利用浅层分类模型研究任务间的特征共享[30, 24, 66, 69, 41]。在深度神经网络的背景下,它通常是通过隐藏层的硬参数或软参数共享来进行[47]。硬参数共享通常依赖于手工设计的架构,该架构由所有任务共享的隐藏层和学习特定任务特征的专门分支组成[23, 29, 43, 5, 26, 12]。只有少数方法试图学习多分支网络架构,使用基于任务亲和力措施的贪婪优化[34, 57]或卷积滤波器分组[6, 54]。相比之下,我们的方法允许学习超越树状结构的更灵活的架构,这在多任务学习中已被证明是有效的[38],并且依赖于更有效的端到端学习方法,而不是基于任务亲和力措施的贪婪搜索。同时,软参数共享方法,如Cross-stitch[39]、Sluice[48]和NDDR[16],由每个任务的网络列组成,并定义了一个列间的特征共享机制。相比之下,我们的方法实现了卓越的准确性,同时需要的参数量明显较少。基于注意力的方法,例如MTAN[33]和Attentive Single-Tasking[37],为每个任务引入了一个与共享主干配对的特定任务注意力分支。我们的方法没有引入额外的注意力机制,而是采用了自适应计算,不仅鼓励通过共享块在任务之间进行积极的共享,而且在必要时通过使用特定任务的块来最小化消极的干扰。最近,Deep Elastic Network(DEN)[1]通过使用复杂的RL策略梯度学习一个额外的策略网络,指定每个网络过滤器用于或不用于每个任务[1]。另外,我们提出了一个更简单但有效的方法,通过直接梯度下降学习确定每个任务的每个网络层的执行,而不需要任何额外的网络。我们在后面的实验中包括与Deep Elastic Network [1]的综合比较。
神经结构搜索。神经结构搜索(NAS),旨在自动设计网络结构[15],已经使用不同的策略进行了研究,包括强化学习[70,71],进化计算[53,45,44],和基于梯度的优化[61,32,65]。受NAS的启发,在这项工作中,我们直接学习单个网络中的共享模式,以实现可扩展和高效的多任务学习。最近的一些工作[8, 31],在NLP和字符识别中,也试图通过RL或进化计算来学习多任务共享。RL策略梯度通常很复杂,训练起来不方便,并且需要技术来减少训练过程中的方差,以及精心选择的奖励函数。相比之下,AdaShare利用基于梯度的优化,速度极快,计算效率比[8, 31]更高。
自适应计算。最近提出了许多自适应计算方法,以提高计算效率为目标,在神经网络中动态地传递信息[2, 3, 62, 51, 58, 60, 17, 46, 58, 1]。BlockDrop[62]通过学习动态选择推理过程中每个样本要执行的层,有效地减少了推理时间,利用了ResNets的行为像相对较浅的网络的集成[59]的事实。路由网络[46]也被提出来,使用由强化学习(RL)训练的递归策略网络对非线性函数进行自适应选择。在迁移学习中,SpotTune[17]学习通过微调或预训练的层来适应性地路由信息。虽然我们的方法受到这些方法的启发,但在本文中,我们重点关注的是在多任务学习中使用一种有效的方法来适应性地决定共享哪些层,该方法联合优化了网络权重和策略分布参数,而没有使用RL算法[62, 46, 1]或像[62, 17, 46, 1]中的任何额外策略网络。
三、提议的方法
给定一组K任务T={T1, T2, · ·, TK},定义在一个数据集上,我们的目标是寻求一种自适应的特征共享机制,决定哪些网络层应该在哪些任务中共享,哪些层应该是特定的任务,以提高准确性,同时考虑到资源效率,实现可扩展的多任务学习。
方法概述。图2说明了我们提出的方法的概况。一般来说,我们为每个层l和任务Tk寻求一个二元随机变量ul,k(又称策略),它决定了在解决Tk时是选择执行还是跳过深度神经网络中的第l层,以获得最佳共享模式,在任务集T上产生最佳的整体性能。
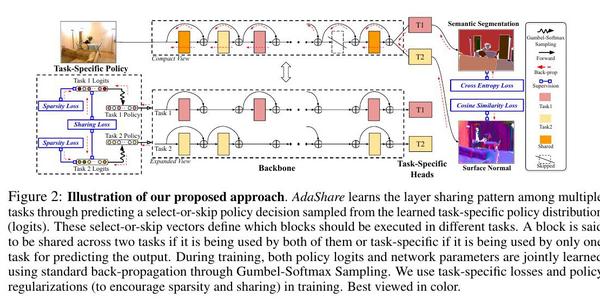

图2: 我们提出的方法的说明。AdaShare通过预测从所学的特定任务策略分布(logits)中抽样的选择或跳过策略决定来学习多个任务之间的层共享模式。这些选择或跳过的向量定义了哪些块应该在不同的任务中执行。如果一个区块被两个任务使用,则被称为两个任务共享;如果一个区块只被一个任务用于预测输出,则被称为特定任务。在训练过程中,通过Gumbel-Softmax采样,使用标准的反向传播法共同学习策略逻辑和网络参数。我们在训练中使用特定任务的损失和策略正则化(以鼓励稀疏性和共享)。最好以彩色方式观看。
近来的网络结构(如ResNet[18]、ResNeXt[64]和DenseNet[21])中广泛使用了捷径连接,并在许多识别任务中取得了强大的性能。这些连接使这些架构对删除层有弹性[59],这有利于我们的方法。在本文中,我们考虑使用具有L个残差块的ResNets[18]。特别是,如果一个残差块被两个任务使用,那么它就被称为跨两个任务共享,如果它只被一个任务用于预测输出,那么它就被称为特定任务。这样,所有区块和任务(U = {ul,k}l≤L,k≤K)的选择或跳过策略决定了在给定任务集T上的自适应特征共享机制。
由于U的潜在配置数量为2L×K,随着区块和任务数量的增加而呈指数级增长,因此在多任务学习中,手动寻找这样的U以获得最佳特征共享模式变得难以实现。我们采用GumbelSoftmax Sampling[25]来优化U,并通过标准的反向传播来优化网络参数W,而不是人工筛选这个策略。此外,我们引入了两个策略正则化,以实现紧凑的多任务网络中的有效知识共享,以及一个课程学习策略,以稳定早期阶段的优化。训练结束后,我们从ul,k中为每个区块l抽出二元决策ul,k,决定在任务Tk中选择或跳过哪些区块。具体来说,在选择或跳过决策的帮助下,我们为MTL参数共享形成了一个新颖而非琐碎的网络架构,并以灵活有效的方式在所有任务中共享不同层次的知识。在测试时,当一个新的输入被提交给多任务网络时,最优策略被遵循,有选择地选择每个任务的计算块。我们提出的方法不仅鼓励任务之间通过共享块进行积极的共享,而且在必要时通过使用特定任务的块来尽量减少消极的干扰。
学习特定任务的策略。在AdaShare中,我们通过标准的反向传播法,从我们设计的损失函数中共同学习选择或跳过策略U和网络权重W。然而,每个选择或删除策略ul,k都是离散的和不可微的,这使得直接优化变得困难。因此,我们采用Gumbel-Softmax Sampling[25]来解决这种不可微,并使用反向传播对离散策略ul,k进行直接优化。
Gumbel-Softmax取样。Gumbel-Softmax技巧[25, 36]是一种简单有效的方法,可以用相应的Gumbel-Softmax分布中的可微分样本替代离散分布中的原始非可微分样本。我们让πl,k=[1-αl,k, αl,k]是我们要优化的二元随机变量ul,k的分布向量,其中对数αl,k代表第l块被选择在任务T.k中执行的概率。
在Gumbel-Softmax抽样中,我们不是从任务Tk中的第l个区块的分布πl,k中直接抽出一个选择或跳过的决策ul,k,而是将其生成为。
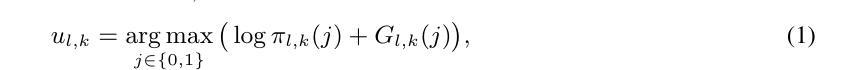

其中Gl,k = - log(- log Ul,k)是一个标准的Gumbel分布,Ul,k是从一个均匀的i.i.d.分布Unif(0, 1)中采样的。为了消除公式1中的无差别argmax运算,Gumbel Softmax技巧将one-hot(ul,k)∈{0, 1}2(ul,k的one-hot编码)放宽为vl,k∈R2(Tk中第l块的软选择或跳过决策),并采用重新参数化技巧[25]。
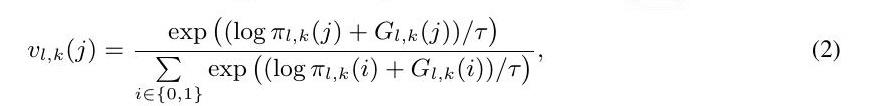

其中j∈{0,1},τ是softmax的温度。显然,当τ>0时,Gumbel-Softmax分布pτ(vl,k)是平滑的,所以πl,k(或αl,k)可以通过梯度下降直接优化,而当τ接近0时,软决策vl,k变得与one-hot(ul,k)相同,相应的Gumbel-Softmax分布pτ(vl,k)变得与离散分布πl,k相同。
按照[17, 61],我们一次性优化离散策略ul,k,∀ l ≤ L, k ≤ K。在训练过程中,我们在前向和反向都使用由公式2给出的软特定任务决策vl,k[61]。同时,我们将τ=5设置为初始值,并在训练过程中逐渐退火至0,如文献[17,61]所述。在学习了策略分布后,我们通过从所学的策略分布p(U)中取样得到离散的特定任务决策U。
损失函数。特定任务的损失只对准确性进行了优化,而没有考虑到效率。然而,我们更倾向于为每个单一任务形成一个紧凑的子模型,在这个模型中,在不降低预测精度的情况下,尽可能地省略掉一些块。为此,我们提出了一个稀疏性正则化Lsparsity,通过最小化一个区块被执行的概率的对数可能性,来提高模型的紧凑性。
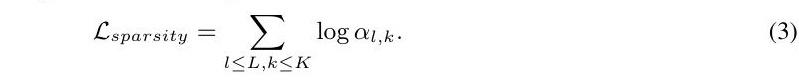

此外,我们引入了一个损失Lsharing,鼓励跨任务的残差块共享,以避免整个网络被任务分割,而这些任务之间的知识共享很少。鼓励共享减少了单独保存在相关任务的特定块中的知识的冗余,从而形成了一个更有效的共享方案,更好地利用残差块。具体来说,我们最小化不同任务的策略对数之间的L1距离的加权和,重点是鼓励共享包含低级知识的底部块。更形式上说,我们将Lsharing定义为
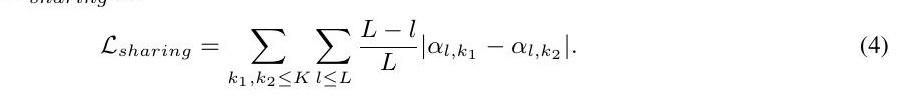

最后,总体损失L被定义为:
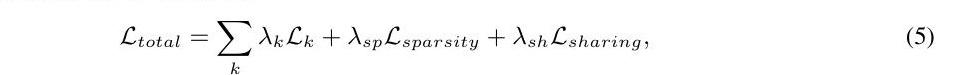

λsp和λsh分别是Lsparsity和Lsharing的平衡参数。额外的损失推动策略学习自动归纳资源效率,同时保持不同任务的识别精度。
训练策略。按照文献[61, 65],我们在不同的训练片段中交替优化网络权重和策略分布参数。为了鼓励更好的收敛,我们通过在任务间共享所有的块来 "预热 "网络权重(即困难参数共享),以提供一个良好的策略学习起点。此外,在早期训练阶段,我们没有对整个决策空间进行优化,而是受课程学习[4]的启发,制定了一个简单而有效的策略,逐步扩大决策空间,形成一套从易到难的学习任务。具体来说,对于第l个(l<L)epoch,我们只学习最后l个区块的策略分布。然后,随着l的增加,我们逐渐学习其他区块的分布参数,并在L个epoch后学习所有区块的联合分布。在策略分布参数得到充分训练后,我们从最佳策略中抽出一个选择或跳过的决策,即特征共享模式,以形成一个新的网络,并使用完整的训练集进行优化。
参数复杂度。请注意,与[8, 17]不同,我们直接对整体选择或跳过策略U的对数A=αl,kl≤L,k≤K进行优化,而不是从语义任务嵌入或图像输入中学习一个策略网络。因此,除了原始网络外,我们对任何新任务都只占用L个额外的参数,这使得参数量的增加在网络参数总数中可以忽略不计。与最近的深度多任务学习方法[16, 33]相比,我们的模型的参数量也明显减少(在学习两个任务时减少约50%)。因此,在内存方面,我们的模型在更多的任务一起学习的情况下具有很好的扩展性。
四、实验
在这一节中,我们进行了广泛的实验,表明我们的模型优于许多强大的基线,并大大减少了高效多任务学习的参数和计算的数量(表1-4)。有趣的是,我们发现,与硬参数共享模型不同,我们的学习策略往往更倾向于在ResNet的conv3_x层而不是最后几层设置特定的任务块(图3:(a))。此外,我们还表明,合理的任务相关性可以从我们学到的特定任务的策略逻辑中得到(图3:(b),图4)。
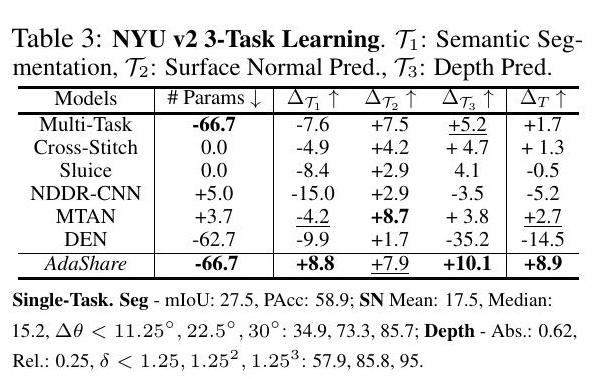

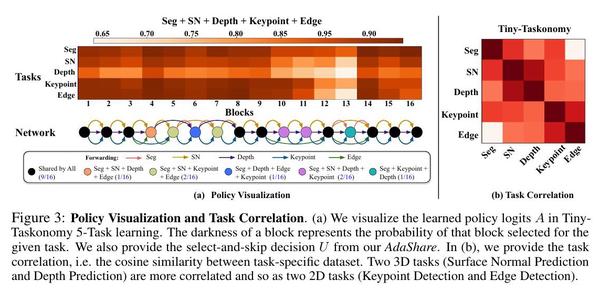

图3:策略的可视化和任务的关联性。(a) 我们将TinyTaskonomy 5-Task学习中的学习策略logits A可视化。一个区块的黑度代表了该区块在给定任务中被选中的概率。我们还提供了我们的AdaShare中的选择和跳过的决定U。在(b)中,我们提供了任务相关性,即特定任务数据集之间的余弦相似度。两个三维任务(表面法线预测和深度预测)更相关,两个二维任务(关键点检测和边检测)也是如此。

数据集和任务。我们使用几个标准数据集来评估我们方法的性能,即NYU v2 [40](用于联合语义分割和表面正常预测,如[39, 16],以及这两个任务与深度预测一起,如[33]),CityScapes [11]。和TinyTaskonomy[68],其中有5个抽样的表示性任务(语义分割、表面正常预测、深度预测、关键点检测和边检测),如[52]中的考虑联合语义分割[9, 55, 20, 19]和深度预测。我们还通过在不同的数据域中执行相同的任务来测试AdaShare,例如在DomainNet[42]的6个域中进行图像分类,在[8]的10个公开可用的数据集上进行文本分类。关于数据集和任务的更多细节包括在补充材料中。
基线。我们将我们的方法与以下基线进行比较。首先,我们考虑一个单任务基线,在这个基线中,我们使用一个特定任务的骨干网和一个特定任务的头来单独训练每个任务。其次,我们使用流行的多任务基线,其中所有任务共享骨干网络,但在最后有单独的特定任务头。最后,我们将我们的方法与最先进的多任务学习方法进行比较,包括Cross-Stitch网络[39](CVPR'16)、Sluice网络[48](AAAI'19)和NDDR-CNN[16](CVPR'19),这些方法在特定任务骨干之间采用了几个特征融合层。MTAN[33](CVPR'19),它在共享主干上引入了特定任务的注意力模块,以及DEN[1](ICCV'19),它使用一个额外的网络为每个任务学习具有RL的通道明智策略。为了进行公平的比较,我们对所有的方法(包括我们提出的方法)使用相同的主干网和特定任务的头。
评估指标。在NYU v2和CityScapes中,语义分割是通过平均相交于联合(mIoU)和像素精度(Pixel Acc)进行评估的。对于表面正常预测,我们使用所有像素的预测和ground truth之间的平均和中位角距离(越低越好)。我们还计算了预测与Ground Truth的角度在11.25◦、22.5◦和30◦之内的像素的比例[13](越高越好)。对于深度预测,我们计算绝对误差和相对误差作为评估指标(越低越好),并通过δ=max{ y pred gt , ypred gt }在阈值1.25、1.252和1.253内的比例来衡量预测和ground truth之间的相对y差异[14](越高越好)。在Tiny-Taskonomy中,我们在测试图像上计算特定任务的损失,作为给定任务的性能测量,如[68, 52]。对于图像分类和文本识别,我们报告每个领域/数据集的分类精度。我们没有用每个任务Ti的多个指标来报告绝对的任务性能,而是遵循[37],并报告相对于单任务基线的单一相对性能∆Ti,以清楚地显示不同基线中的正/负迁移。


其中lj=1,如果较低的值代表指标Mj更好,否则为0。最后,我们对所有任务进行平均,得到总体性能 \Delta_{T}=\frac{1}{|T|} \sum_{i=1}^{K} \Delta_{\mathcal{T}_{i}} 。
实验设置。我们使用Deeplab-ResNet[9]与atrous convolution(一种用于像素预测任务的流行架构)作为主干,使用ASPP[9]架构作为特定任务的头。我们在大多数情况下采用ResNet-34(16块),在NYU v2数据集上的简单2个任务情况下使用ResNet-18(8块)。对于DomainNet,我们使用原始的ResNet-34作为骨干,并采用VD-CNN[10]进行文本分类。按照[61],我们使用Adam[28]来更新策略分布参数,使用SGD来更新网络参数。在策略训练结束时,我们从策略分布中抽取选择或跳过的决定,从头开始训练。具体来说,我们从学到的策略中抽出8个不同的网络结构,并将最佳的再训练性能作为我们的结果报告。我们对语义分割以及分类任务使用交叉熵损失,对表面正常预测使用归一化预测和ground truth之间的余弦相似度的倒数。L1损失被用于所有其他任务。预训练取决于任务,我们观察到,在NYUv2的3个任务学习中,预训练将AdaShare的整体性能提高了11.3%。然而,为了摆脱不同的预训练模型带来的不公平,我们从头开始在所有的实验中对不同的方法进行公平比较。
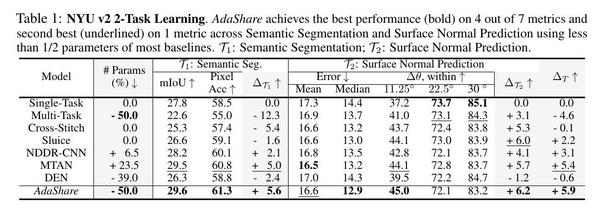
定量结果。表1-4显示了四个不同学习场景下的任务表现,即NYU-v2 2-任务学习、CityScapes 2-任务学习、NYU-v2 3-任务学习和TinyTaskonomy 5-任务学习。我们报告了NYU-v2 2-Task Learning的所有指标和两个任务的相对性能(见表1),并报告了单任务基线的所有指标和其他方法的相对性能,由于其他情况下空间有限(见表2-4)。我们建议读者参考补充材料,了解所有指标的完整比较。

在NYU v2双任务学习中,AdaShare在7个指标中的4个指标上优于所有基线,在1个指标上取得了第二名的成绩(见表1)。与Single-task、Cross-Stitch、Sluice和NDDR-CNN相比,我们的方法以不到一半的参数量获得了卓越的任务性能。此外,AdaShare在参数量上也超过了原始的多任务基线和DEN[1],这是最具竞争力的方法,表明它能够在不使用任何额外策略网络的情况下,以相同的网络参数量挑选出共享和特定任务知识的最佳组合。
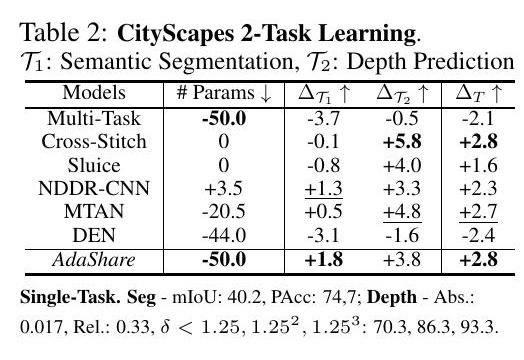
同样,对于其他学习场景(表2-4),AdaShare在整体相对性能上明显优于所有基线,同时与大多数基线相比,至少节省了50%,最多80%的参数。AdaShare在参数使用上也优于多任务基线和DEN。具体来说,对于NYU-v2 3任务学习中的语义分割,我们观察到所有基线的性能都比单任务基线差,这表明为了提高语义分割的性能,应该仔细选择来自表面正常预测和深度预测的知识。相比之下,我们的方法仍然能够提高分割性能,而不是受到其他两个任务的负面干扰。在Tiny-Taskonomy 5任务学习中的表面正常预测中也观察到同样的负面迁移的减少。然而,我们提出的方法AdaShare仍然使用大多数基线的不到1/5的参数表现最好(表4)。


此外,我们提出的AdaShare在不同领域的同一任务中也取得了更好的整体性能。对于DomainNet[42]上的图像分类,AdaShare在6个不同的视觉领域比多任务基线提高了4.6%(62.2% vs. 57.6%),其中在快画领域的提高幅度最大,达到16%。对于文本分类任务,AdaShare在10个不同的NLP数据集上比多任务基线平均提高了7.2%(76.1% vs. 68.9%)[8],在sogou_news数据集上最大提高了27.8%。
策略可视化和任务相关性。在图3:(a)中,我们将我们学到的策略分布(通过对数)和Tiny-Taskonomy 5-Task Learning中的特征共享策略可视化(更多的可视化内容包括在补充材料中)。我们还采用了特定任务策略对数之间的余弦相似性作为任务相关性的有效表示(图3:(b),图4)。我们有以下的关键观察。(a) 每个区块对任务k的执行概率表明,并非所有区块对任务的贡献是相同的,它允许AdaShare在任务之间进行调解,并决定特定任务的区块对给定的任务集进行适应。(b) 我们学习到的策略倾向于只在ResNet的conv3_x层中的任务子组中共享更多的块,在这里,中/高层特征,也就是更多的任务特征,开始被捕获。通过让子任务组共享区块,AdaShare鼓励正向迁移,缓解负向迁移的影响,从而获得更好的整体性能。(c) 我们清楚地观察到,表面法线预测和深度预测,这两个不同的三维任务,是比较相关的,而关键点预测和边检测。
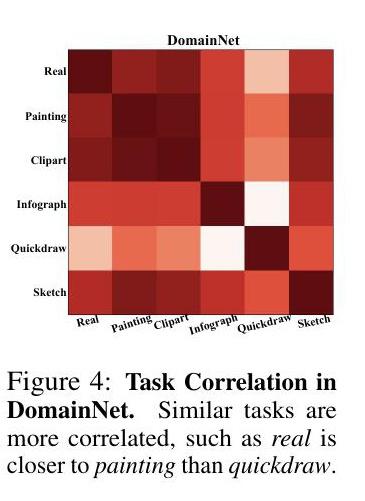
两个不同的二维任务更加相关(见图3:(b))。同样地,图4显示,在DomainNet中,domain real比quickdraw更接近于绘画。这两个结果都遵循这样的直觉:类似的任务应该有类似的执行分布,以分享知识。请注意,余弦相似度纯粹是衡量不同任务的归一化执行概率之间的相关性,它不受不同任务的不同优化不确定性的影响。
计算开销(FLOPs)。与现有的MTL方法相比,AdaShare需要的计算量(FLOPs)要少很多。例如,在Cityscapes 2任务中,Cross-stitch/Sluice、NDDR、MTAN、DEN和AdaShare分别使用了37.06G、38.32G、44.31G、39.18G和33.35G的FLOPs;在NYU v2 3任务中,它们分别使用了55.59G、57.21G、58.43G、57.71G和50.13G的FLOPs。总的来说,与最先进的方法相比,AdaShare在所有的任务中平均节省了7.67%-18.71%的计算量,同时以大约50%-80%的参数实现了更好的识别精度。
消融研究。我们在NYU-v2 3-Task学习中提出了四组消融研究,以测试我们学到的策略,不同的训练损失和优化方法的有效性(表5)。
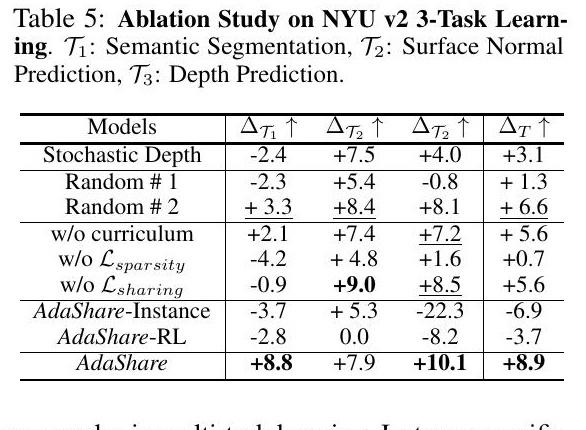

与随机深度的比较。随机深度[22]在训练过程中随机丢弃区块作为正则,并在推理中使用完整模型。我们将AdaShare与随机深度在我们的多任务设置中进行了比较,并观察到AdaShare获得了更多的改进(在表5中总体改进了5.8%),这使AdaShare区别于正则化技术。
与随机策略的比较。我们进行了两个不同的实验,如 "随机1号 "实验,即对所有任务保持相同数量的跳过区块,并随机化它们的位置;"随机2号",即进一步强制每个任务的跳过区块的数量与AdaShare相同。我们报告了每个实验中八个样本的最佳性能。在表5中,两个随机实验都通过在模型中加入共享块和特定任务的块来提高多任务基线的性能。另外,随机2号比随机1号效果更好,这表明分配给每个任务的块的数量实际上很重要,我们的方法对它进行了很好的预测。我们的模型仍然优于随机2号,表明AdaShare正确地预测了那些跳过的块的位置,这形成了我们方法中的最终共享模式。
训练损失和策略的消融。我们进行了实验,以显示课程学习、稀疏性正则化Lsparsity和共享损失Lsharing在我们模型中的有效性。在所有组件都工作的情况下,我们的方法在所有三个任务中都是最好的(见表5),这表明三个组件有利于策略学习。
与特定实例策略的比较。我们采用相同的策略网络[1]来计算每个任务[58, 62]的每个测试图像的选择和跳过决策。AdaShare的特定任务策略优于特定实例策略(见表5),因为其差异
在多任务学习中,任务间的差异比样本间的差异更重要。针对具体实例的方法往往会引入额外的优化难度,并导致更差的收敛性。
与AdaShare-RL的比较。我们用REINFORCE代替Gumbel-Softmax Sampling来优化选择或跳过策略,而其他部分没有变化。表5显示AdaShare在每个任务和整体性能上都优于AdaShare-RL,与[63]中的比较一致。
扩展到其他架构。除了ResNets之外,我们还使用Wide ResNets(WRN)[67]和MobileNet-v2[50]实现AdaShare。AdaShare在NYU-v2 2-Task中使用WRN和MobileNet分别比多任务基线高出5.8%和3.2%(表6)。我们也观察到CityScapes 2-Task学习的类似趋势。这显示了我们提出的方法在不同的网络结构中的有效性。

五、总结
在本文中,我们提出了一种在深度多任务学习中自适应确定多个任务的特征共享策略的新方法。我们使用标准的反向传播法联合学习特征共享策略和网络权重,而不增加任何数量的参数。我们还引入了两个资源感知的正则,以更少的参数学习一个紧凑的多任务网络,同时在多个任务中实现最佳的整体性能。我们在五个标准数据集上展示了我们提出的方法的有效性,超过了一些竞争性的方法。展望未来,我们希望使用更高的任务与层的比率来探索AdaShare,这可能需要增加网络容量,以将所有的任务叠加到一个单一的多任务网络中。此外,我们将对AdaShare进行扩展,以找到一个细粒度的通道共享模式,而不是跨任务的层级策略,从而实现更高效的深度多任务学习。
更广泛的影响
我们的研究提高了深度神经网络的能力,以更有效的方式同时解决许多任务。它能够使用较小的网络来支持更多的任务,同时在相关任务之间进行知识迁移以提高其准确性。例如,我们表明,我们提出的方法可以用少80%的参数解决五个计算机视觉任务(语义分割、表面法线预测、深度预测、关键点检测和边估计),同时取得与标准方法相同的性能。
因此,我们的方法可以对需要多种任务的应用产生积极影响,如机器人的计算机视觉。潜在的应用可能是在辅助机器人、自主导航、机器人分拣和包装、救援和应急机器人以及AR/VR系统。我们的研究可以减少这类系统的内存和功耗,使它们能够部署更长的时间,变得更小、更灵活。随着人工智能系统的普及,减少的功耗可能对环境产生很大的影响。
我们的研究的负面影响很难预测,然而,它与深度学习模型相关的许多缺陷是一样的。其中包括容易受到对抗性攻击和数据中毒,数据集的偏差,以及缺乏可解释性。与部署计算机视觉系统相关的其他风险包括:在未经同意的情况下捕获图像,或用于跟踪个人以获取利润,或增加自动化导致工作岗位流失,从而侵犯隐私。虽然我们认为这些问题应该得到缓解,但它们超出了本文的范围。此外,我们应该谨慎对待系统失败的结果,这可能会影响到我们研究中所依赖的高级人工智能系统的性能/用户体验。