
对话机器人与机器学习:手把手教你打造一个智能语音助理

对话机器人与机器学习:打造神经网络智能语音助理
您可能用过Siri,Alexa或Cortana来设置闹钟,给朋友打电话或安排会议。但是,尽管它们在常见和常规任务中很有用,但很难强迫一个智能助理去讨论通用性的,甚至是哲学性的话题。 Statsbot团队向数据科学家Dmitry Persiyanov请教,学习如何使用神经对话模型解决这个问题以及如何使用机器学习来构建聊天机器人。
通过自然语言与机器交互是通用人工智能的要求之一。人工智能在这个领域被称作对话系统,口语对话系统或聊天机器人。机器需要为您提供信息丰富的答案,保持对话的语境,并且与人类(理想情况下)无异。
实际上,最后一项要求尚未达到。但幸运的是,在它们有用处的情况下,人类已经愿意与机器人进行交谈 - 有时,它们甚至可以是有趣的交流对象。
对话系统有两种主要类型:任务型会话(即Siri,Alexa,Cortana等)和一般性会话(即Microsoft Tay bot)。前者使用自然语言帮助人们解决日常问题,而后者则尝试与人们就广泛的话题进行交流。
在这篇文章中,我将给出一个基于深度神经网络的一般会话对话系统的比较概述。我将描述主要的架构类型和提升它们的方法。此外,还会提供很多论文,教程和实现方法的链接。
我希望这篇文章能成为用机器学习创建聊天机器人的入门帖。 如果你能够读完这篇文章,你就可以动手打造自己的对话系统了。准备好了吗?
我需要涉及循环神经网络和单词嵌入(word embedding),你需要对它们的原理有个了解,以便轻松地读完这篇文章。 对于那些需要充电的小伙伴,我在本文末尾为您准备了很棒的教程。
生成模型和选择模型
一般性会话模型可以简单地分为两种主要类型:生成和选择(或排名)模型。此外,混合模型是可能的。但共同点是这样的模型会接受几个对话语境的句子,并预测在这个语境下的答案。在下图中,您可以看到此类系统的图示。


在这篇文章中,当我说“神经网络输入一系列单词”或“单词被传递给RNN”时,我的意思是单词嵌入被传递到网络,而不是单词的ID。
关于对话数据的表示方法
在深入讨论之前,我们应该讨论一下对话数据集是什么样子的。下面描述的所有模型都是成对训练(上下文,回复)。上下文(context)是在回复(reply)之前的几个句子(或者可能是一个)。句子只是出现在词汇表(vocabulary)中的标记序列(tokens)。
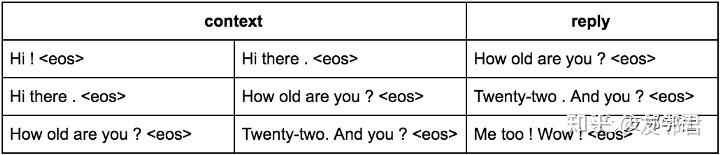

为了更好地理解,请查看表格。从两个人之间的原始对话中提取了一批次的三个样本:
- Hi!
- How old are you?
- Me too! Wow!
- Twenty-two. And you?
- Hi there.
请注意批处理中每个句子末尾的<eos>(序列结尾)标记。 这个特殊标记有助于神经网络理解句子边界并明智地更新其内部状态。
某些模型可能会使用来自数据的其他元信息,例如演讲者身份,性别,情感等。
现在,我们准备继续讨论生成模型。
生成模型
我们从最简单的对话模型开始,以论文A Neural Conversational Model为蓝本。
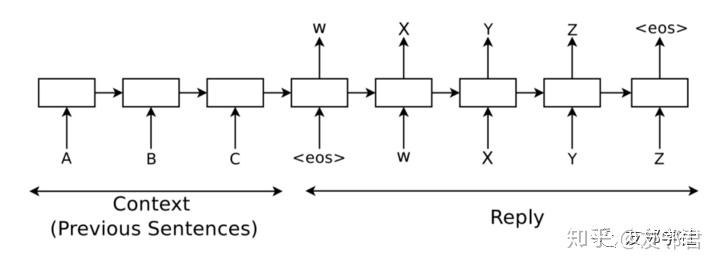
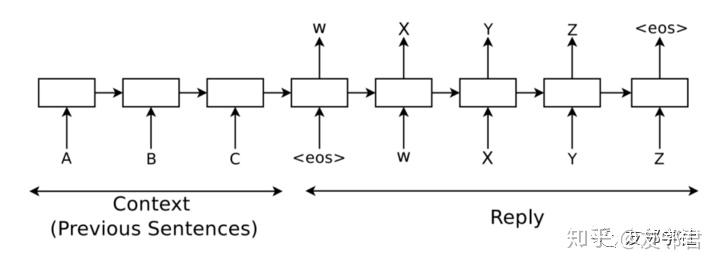
为了给对话建模,这篇论文运用了序列到序列(seq2seq)框架,该框架最早出现在机器翻译领域,并成功地运用到对话系统。 该体系结构由两个具有不同参数集的卷积神经网络(RNN)组成。 左边的一个(对应于A-B-C标记)称为编码器(encoder),而右边的一个(对应于<eos> -W-X-Y-Z标记)称为解码器(decoder)。
编码器原理
编码器卷积网络RNN每次一个地构造一系列上下文标记并更新其隐藏状态。 在处理整个上下文序列之后,它产生最终隐藏状态,其结合了上下文时态并用于生成答案。
解码器原理
解码器的目标是从编码器获取上下文表示并生成答案。 为此目的,解码器RNN中需要维持一个在词汇之上的softmax层。 在每个时间步,该层获取解码器隐藏状态并输出其词汇表中所有单词的概率分布。
以下是生成回复的工作原理:
- 使用最终编码器隐藏状态(h_0)初始化解码器隐藏状态。
- 将<eos>标记作为第一个输入传递给解码器并更新隐藏状态(h_1)
- 从softmax层(使用h_1)采样(或取最大概率的那个)作为第一个单词(w_1)。
- 将此单词作为输入传递,更新隐藏状态(h_1 - > h_2),并生成一个新单词(w_2)。
- 重复步骤4,直到生成<eos>标记或超出最大答案长度。


以上是解码器中的回复生成,适用于那些喜欢公式而不是单词的人。 这里,wt是时间步长t的采样字; 表示解码器参数; 表示密集层参数; g表示致密层; 是在时间步t处的词汇的概率分布。
在生成回复时使用argmax,当使用相同的上下文时,将始终得到相同的答案(argmax是确定性的,而采样是随机的)。
我上面描述的过程只是模型推理部分,模型训练的部分以稍微不同的方式工作。 在每个解码步骤中,使用正确的单词yt而非生成的单层wt。 换句话说,在训练时,解码器输入正确的回复序列,但删除了最后一个标记并且<eos>标记被预先添加。
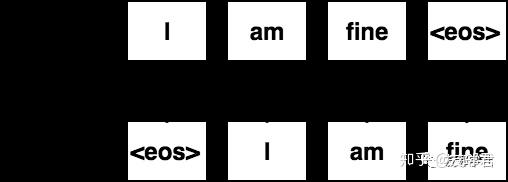

解码器推理环节图示。上一时间步的输出被作为当前时间步的输入
目标是最大化每个时间步上正确的得出下一个单词的概率。 更简单地说,我们通过为它提供正确的前缀来要求网络预测序列中的下一个单词。 通过最大似然训练进行训练,这引出经典的交叉熵损失:
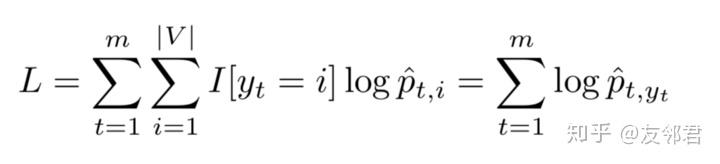

在这里,yt是在第t步时的正确回复。
生成模型的调整
现在,我们对序列到序列框架有了基本的了解。我们如何为这些模型增加更多的泛化能力?有几种方法:
- 向编码器或/和解码器RNN添加更多层。
- 使用双向编码器。由于其前向生成结构,无法使解码器成双向。
- 在单词嵌入上下功夫。您可以预先初始化单词嵌入,也可以与模型一起从头开始学习它们。
- 使用更高级的回复生成过程:beamsearch。这个想法是不“贪婪地”产生回复(通过对下一个词采用argmax方法),而是考虑更长单词链的概率并在当中进行选择。
- 使您的编码器或/和解码器可卷积。 卷积神经网络可能比RNN更快,因为它们可以有效地并行化。
- 使用注意(attention)机制。注意力最初是在机器翻译论文中引入的,并且已经成为一种非常流行和强大的技术。
- 在每个时间步将最终编码器状态传递给解码器。解码器只看到一次最终编码器状态,然后可能会忘记它。一个好的办法是将其与单词嵌入一起传递给解码器。
- 使用不同编码器/解码器状态大小。我上面描述的模型要求编码器和解码器具有相同的隐藏状态大小(因为我们用最终编码器的状态初始化解码器状态)。可以通过从编码器最终状态向初始解码器状态添加投影(密集)层来消除此项定义。
- 使用字符而不是单词或字节对编码来构建词汇表。字符级别的模型值得考虑,因为它们的词汇量较小,并且能够理解词汇中没有的单词,因此它们的工作速度更快。字节对编码(BPE)是两全其美的。办法是在序列中找到最常见的标记对,并将它们合并为一个标记。
生成模型存在的问题
稍后,我会提供目前大受欢迎的实现方法的链接,你可以用它训练自己的对话模型。 但我想提前告诉你一些你或许会遇到的生成模型的常见问题。
通用回复通过最大似然训练的生成模型倾向于预测出一个高概率的一般回答,例如“好”,“不”,“是的”和“我不知道”的广泛情境。 可以通过下面的工作来解决这些问题:
- 在模型推理阶段改变目标函数。
- 引入人工指标并将其作为奖励机制,同时将seq2seq模型作为强化学习模型训练。
回复不一致以及如何合并元数据seq2seq模型的第二个主要问题是它们会给具有相同意义的释义上下文生成不一致的回复:


处理这个问题最常被提到的做法是基于角色的神经对话模型。 作者根据每个话语的说话者身份生成答案,该答案不仅取决于编码器状态而且还取决于说话者嵌入(speaker embeddings)。 说话者嵌入与模型一起从头开始学习。
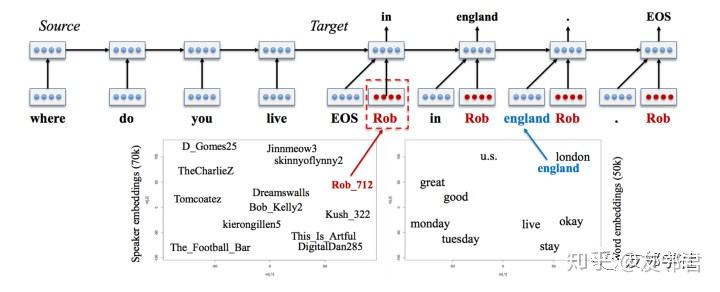

通过这个方法,你可以将所拥有的不同元数据用来扩充模型。 例如,如果知道话语的时态(过去/现在/将来),就可以在推理时以不同的时态生成回复! 你可以调整回复者的性格(性别,年龄,情绪)或回复属性(时态,情绪,问题/非问题等),如果你有这些数据来训练模型。
练习
我之间讲过要将不同框架下序列到序列的模型实现方法提供给大家,是时候放链接了。
TensorFlow
- 谷歌官方实现方法
- 另外两个实现方法 在PyTorch上更适用,序列到序列的翻译模型,同样适用于对话系统。
- 序列的序列的翻译模型 (相同的代码,把数据换成对话系统的)
- IBM的实现方法
Keras
论文和教程
- A tutorial on sequence-to-sequence chatbots
- Attention 机制
- Bahdanau’s attention
- Luong’s attention
- State-of-the-art on machine translation task using multi-head attention + feedforward networks.
- Tutorial on attention in RNNs
- Byte Pair Encoding paper
- ConvS2S paper
深入分析选择模型(Selective Models)
介绍过了生成模型,我们选择了解一下选择神经对话模型的工作原理(它们通常被称为DSSM,即深层语义相似性模型(deep semantic similarity model))。
选择模型不是估计概率p(reply|context; w),而是学习相似性函数sim(reply,context; w),其中回复是预定义的可能答案池中的一个(参见下图)。
直观地讲,神经网络将上下文和候选答案作为输入,并返回它们彼此之间的可信度(confidence)。
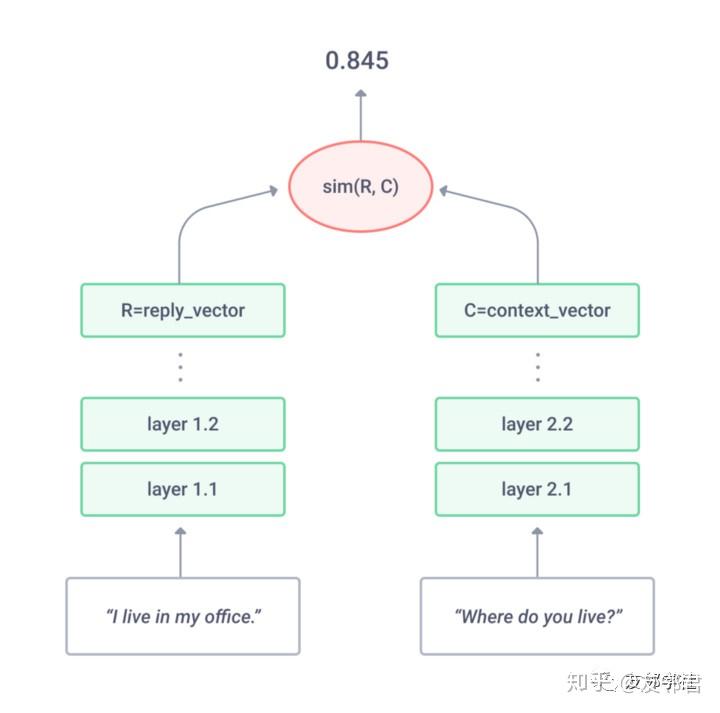

选择(或排名,或DSSM)网络由两个“塔”组成:第一个用于上下文,第二个用于回复。每座塔楼都可能拥有您想要的任何结构。塔取其输入并将其嵌入语义向量空间(图中的向量R和C)。然后,计算上下文和应答向量之间的相似性,即使用余弦相似度C ^ T * R /(|| C || * || R ||)。
在推理时,我们可以计算给定上下文和所有可能答案之间的相似性,并选择具有最大相似性的答案。
为了训练模型,我们使用三重态损失。三重态损失在三元组(context,reply_correct,reply_wrong)上定义,并且等于:
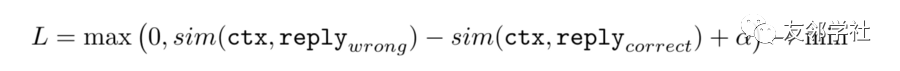

选择模型的三重态损失。非常类似于SVM中的最大边际损失
什么是reply_wrong? 它也被称为“否定”样本(reply_correct称为“肯定”),在最简单的情况下,它是来自答案池的随机答复。 通过最小化这种损失,我们以绝对值不提供信息的排序方式学习相似性函数。 但请记住,在推理阶段,我们只需要比较所有回复的分数,并选择得分最高的。
您可以在一个特别的Microsoft项目页面上深入了解DSSM。 生成模型没有很多开源实现,但是,您可以参考本教程在TensorFlow上实现一个选择性模型。
选择模型的样本策略
你可能会问,我们为什么要从数据集中随机抽样?也许使用更复杂的抽样方案是个好主意? 确实如此。 如果你仔细观察,你可能会发现三元组的数量是O(n³),所以正确地选择“否定样本”是很重要的,因为我们无法遍历所以样本(大数据,你知道的)。
例如,我们可以从答案池中随机抽样出K个否定回复,对其进行评分,并选择最高得分的作为否定样本。 这种方案被称为“hard negative” 采样。 如果您想深入探究,请阅读 Sampling Matters in Deep Embedding Learning.一文。
生成模型 vs 选择模型
此时,我们已经了解了生成模型和选择模型的工作原理。 但是你选择哪种类型? 这完全取决于您的需求。 下表是为了帮助你做出决定。
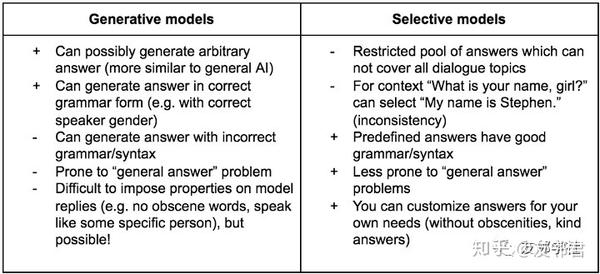

最困难的是模型评价
其中一个最重要的问题是如何评估神经网络对话模型。 有许多自动化指标用于评估机器学习聊天机器人:
- 选择模型的精密度,准确度以及回顾能力
- 生成模型的复杂度,损失值
- 机器翻译的BLEU/METEOR值
但是最近的一些研究表明,所有这些指标都与人类对特定情境的答复适当性的判断关系不大。
例如,假设在以下情景“数据机器人是否会破坏我们处理数据的方式?”,在的数据集中回复“它肯定会。”。 但是你的模型回答这个情景,用例如“这绝对是真的。”上面显示的所有指标都会给出这样一个答案的低分,但我们可以看到这个答案和数据里的答案一样好。


因此,目前最恰当的方法是使用目标指标对模型进行人工评估,然后选择最佳模型。 是的,这似乎是一个昂贵的过程(您需要使用像Amazon Mechanical Turk这样的评估模型),但目前,我们没有更好的方法。 不管怎样,在是研究界的发展方向。
我们的智能手机什么时候才能用上这样的技术
最终我们已经有办法创造一个人工智能的对话模型,通用人工智能,对吧? 如果是这样的话,拥有数千名研究人员的苹果,亚马逊和谷歌等公司应该已经在部署它们的个人助理产品。
尽管在这个领域投入了大量工作,想要神经对话系统在开放领域与人交谈,并为人类提供信息,提供有趣或者有用的答案,目前还做不到。 但对于封闭领域(例如技术支持或Q&A系统),已经有了大量成功案例。
RNN和词嵌入相关教程
这里还有一些非常实用的教程
循环神经网络(Recurrent Neural Networks)
- Definitive tutorial with illustrations and code
- One of the most cited tutorials with experiments and great explanations
词嵌入(Word Embeddings)
- Text classifier algorithms
- Great definitive guide on embeddings with illustrations
- TensorFlow’s tutorial with code examples
结论
对话模型起初可能看起来很难掌握(或者从头到尾都很难)。 我建议你阅读我给链接的资源。 此外,这里有一个合集,其中包含许多关于对话系统的基本论文。
当你准备练习时,选择一些简单的架构,选择一个流行的数据集或者自己爬取的(Twitter,Reddit或其他),并在其上训练一个对话模型。
